 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
FIVA: Facial Image and Video Anonymization and Anonymization Defense
Sep 08, 2023
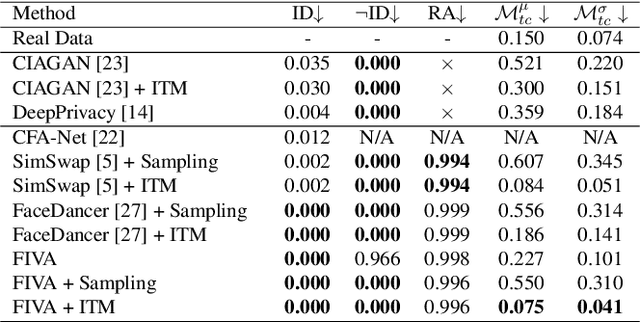
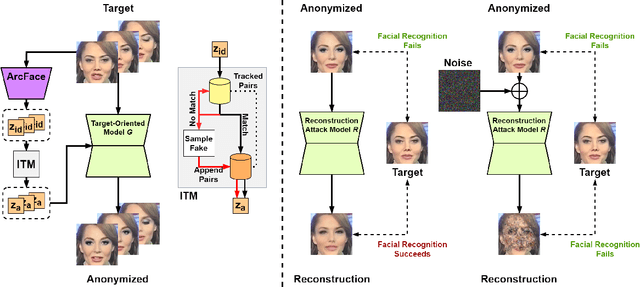
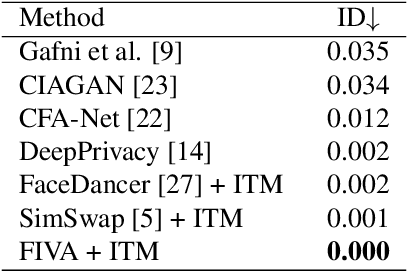
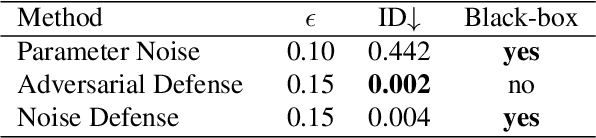
In this paper, we present a new approach for facial anonymization in images and videos, abbreviated as FIVA. Our proposed method is able to maintain the same face anonymization consistently over frames with our suggested identity-tracking and guarantees a strong difference from the original face. FIVA allows for 0 true positives for a false acceptance rate of 0.001. Our work considers the important security issue of reconstruction attacks and investigates adversarial noise, uniform noise, and parameter noise to disrupt reconstruction attacks. In this regard, we apply different defense and protection methods against these privacy threats to demonstrate the scalability of FIVA. On top of this, we also show that reconstruction attack models can be used for detection of deep fakes. Last but not least, we provide experimental results showing how FIVA can even enable face swapping, which is purely trained on a single target image.
Facial Landmark Detection Evaluation on MOBIO Database
Jul 06, 2023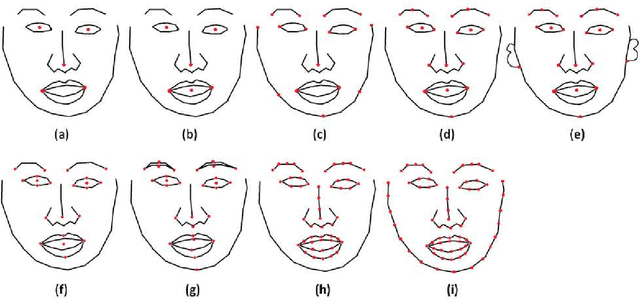
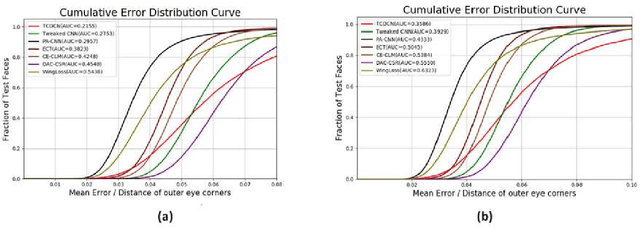
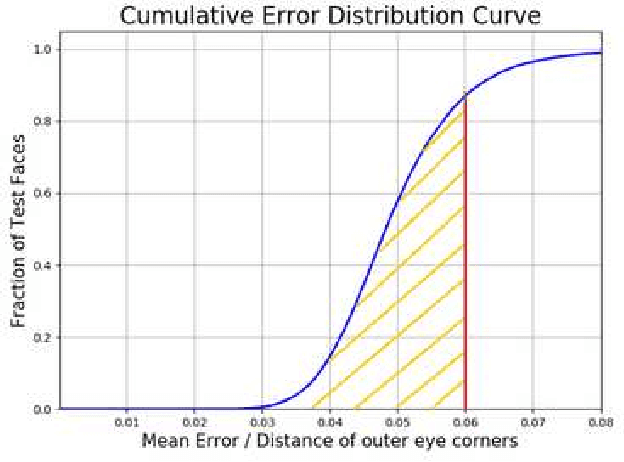
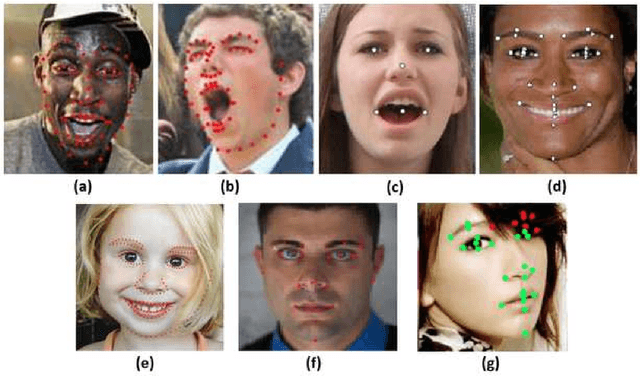
MOBIO is a bi-modal database that was captured almost exclusively on mobile phones. It aims to improve research into deploying biometric techniques to mobile devices. Research has been shown that face and speaker recognition can be performed in a mobile environment. Facial landmark localization aims at finding the coordinates of a set of pre-defined key points for 2D face images. A facial landmark usually has specific semantic meaning, e.g. nose tip or eye centre, which provides rich geometric information for other face analysis tasks such as face recognition, emotion estimation and 3D face reconstruction. Pretty much facial landmark detection methods adopt still face databases, such as 300W, AFW, AFLW, or COFW, for evaluation, but seldomly use mobile data. Our work is first to perform facial landmark detection evaluation on the mobile still data, i.e., face images from MOBIO database. About 20,600 face images have been extracted from this audio-visual database and manually labeled with 22 landmarks as the groundtruth. Several state-of-the-art facial landmark detection methods are adopted to evaluate their performance on these data. The result shows that the data from MOBIO database is pretty challenging. This database can be a new challenging one for facial landmark detection evaluation.
Learning Motion Refinement for Unsupervised Face Animation
Oct 21, 2023Unsupervised face animation aims to generate a human face video based on the appearance of a source image, mimicking the motion from a driving video. Existing methods typically adopted a prior-based motion model (e.g., the local affine motion model or the local thin-plate-spline motion model). While it is able to capture the coarse facial motion, artifacts can often be observed around the tiny motion in local areas (e.g., lips and eyes), due to the limited ability of these methods to model the finer facial motions. In this work, we design a new unsupervised face animation approach to learn simultaneously the coarse and finer motions. In particular, while exploiting the local affine motion model to learn the global coarse facial motion, we design a novel motion refinement module to compensate for the local affine motion model for modeling finer face motions in local areas. The motion refinement is learned from the dense correlation between the source and driving images. Specifically, we first construct a structure correlation volume based on the keypoint features of the source and driving images. Then, we train a model to generate the tiny facial motions iteratively from low to high resolution. The learned motion refinements are combined with the coarse motion to generate the new image. Extensive experiments on widely used benchmarks demonstrate that our method achieves the best results among state-of-the-art baselines.
Explaining with Attribute-based and Relational Near Misses: An Interpretable Approach to Distinguishing Facial Expressions of Pain and Disgust
Aug 27, 2023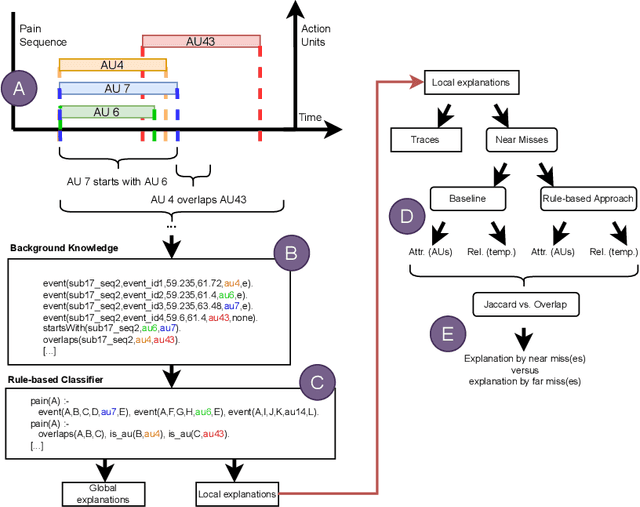

Explaining concepts by contrasting examples is an efficient and convenient way of giving insights into the reasons behind a classification decision. This is of particular interest in decision-critical domains, such as medical diagnostics. One particular challenging use case is to distinguish facial expressions of pain and other states, such as disgust, due to high similarity of manifestation. In this paper, we present an approach for generating contrastive explanations to explain facial expressions of pain and disgust shown in video sequences. We implement and compare two approaches for contrastive explanation generation. The first approach explains a specific pain instance in contrast to the most similar disgust instance(s) based on the occurrence of facial expressions (attributes). The second approach takes into account which temporal relations hold between intervals of facial expressions within a sequence (relations). The input to our explanation generation approach is the output of an interpretable rule-based classifier for pain and disgust.We utilize two different similarity metrics to determine near misses and far misses as contrasting instances. Our results show that near miss explanations are shorter than far miss explanations, independent from the applied similarity metric. The outcome of our evaluation indicates that pain and disgust can be distinguished with the help of temporal relations. We currently plan experiments to evaluate how the explanations help in teaching concepts and how they could be enhanced by further modalities and interaction.
NOFA: NeRF-based One-shot Facial Avatar Reconstruction
Jul 07, 2023
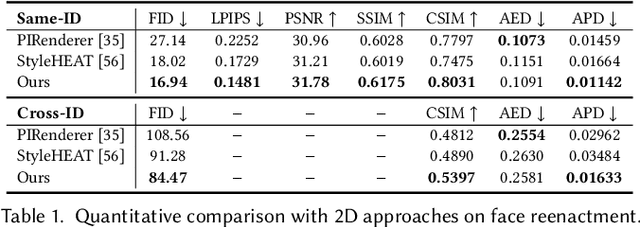
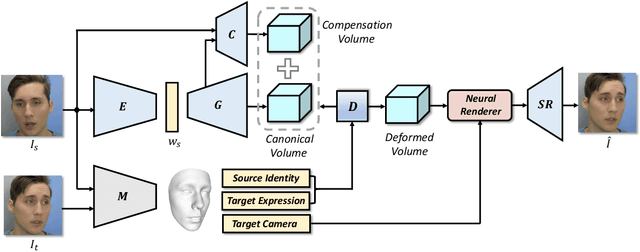
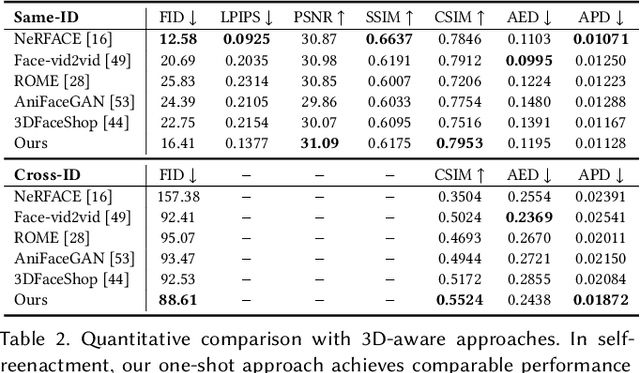
3D facial avatar reconstruction has been a significant research topic in computer graphics and computer vision, where photo-realistic rendering and flexible controls over poses and expressions are necessary for many related applications. Recently, its performance has been greatly improved with the development of neural radiance fields (NeRF). However, most existing NeRF-based facial avatars focus on subject-specific reconstruction and reenactment, requiring multi-shot images containing different views of the specific subject for training, and the learned model cannot generalize to new identities, limiting its further applications. In this work, we propose a one-shot 3D facial avatar reconstruction framework that only requires a single source image to reconstruct a high-fidelity 3D facial avatar. For the challenges of lacking generalization ability and missing multi-view information, we leverage the generative prior of 3D GAN and develop an efficient encoder-decoder network to reconstruct the canonical neural volume of the source image, and further propose a compensation network to complement facial details. To enable fine-grained control over facial dynamics, we propose a deformation field to warp the canonical volume into driven expressions. Through extensive experimental comparisons, we achieve superior synthesis results compared to several state-of-the-art methods.
DF-TransFusion: Multimodal Deepfake Detection via Lip-Audio Cross-Attention and Facial Self-Attention
Sep 12, 2023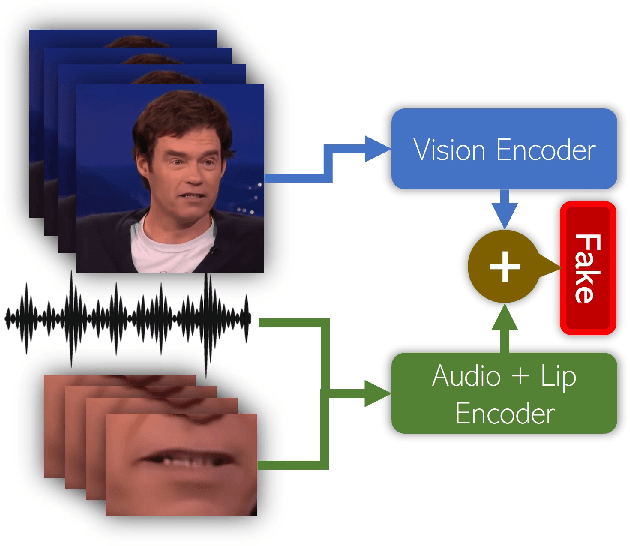
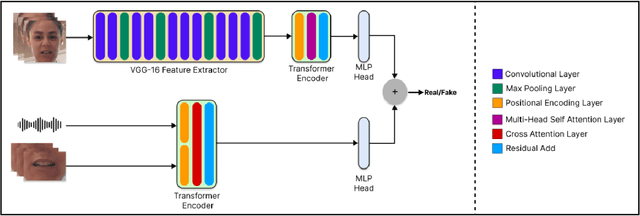
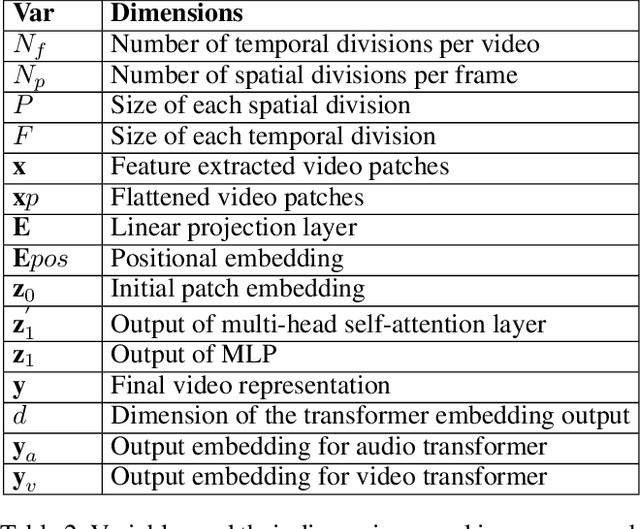
With the rise in manipulated media, deepfake detection has become an imperative task for preserving the authenticity of digital content. In this paper, we present a novel multi-modal audio-video framework designed to concurrently process audio and video inputs for deepfake detection tasks. Our model capitalizes on lip synchronization with input audio through a cross-attention mechanism while extracting visual cues via a fine-tuned VGG-16 network. Subsequently, a transformer encoder network is employed to perform facial self-attention. We conduct multiple ablation studies highlighting different strengths of our approach. Our multi-modal methodology outperforms state-of-the-art multi-modal deepfake detection techniques in terms of F-1 and per-video AUC scores.
PrivacyGAN: robust generative image privacy
Oct 19, 2023Classical techniques for protecting facial image privacy typically fall into two categories: data-poisoning methods, exemplified by Fawkes, which introduce subtle perturbations to images, or anonymization methods that generate images resembling the original only in several characteristics, such as gender, ethnicity, or facial expression.In this study, we introduce a novel approach, PrivacyGAN, that uses the power of image generation techniques, such as VQGAN and StyleGAN, to safeguard privacy while maintaining image usability, particularly for social media applications. Drawing inspiration from Fawkes, our method entails shifting the original image within the embedding space towards a decoy image.We evaluate our approach using privacy metrics on traditional and novel facial image datasets. Additionally, we propose new criteria for evaluating the robustness of privacy-protection methods against unknown image recognition techniques, and we demonstrate that our approach is effective even in unknown embedding transfer scenarios. We also provide a human evaluation that further proves that the modified image preserves its utility as it remains recognisable as an image of the same person by friends and family.
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems
Nov 20, 2023Artificial Intelligence (AI) systems such as autonomous vehicles, facial recognition, and speech recognition systems are increasingly integrated into our daily lives. However, despite their utility, these AI systems are vulnerable to a wide range of attacks such as adversarial, backdoor, data poisoning, membership inference, model inversion, and model stealing attacks. In particular, numerous attacks are designed to target a particular model or system, yet their effects can spread to additional targets, referred to as transferable attacks. Although considerable efforts have been directed toward developing transferable attacks, a holistic understanding of the advancements in transferable attacks remains elusive. In this paper, we comprehensively explore learning-based attacks from the perspective of transferability, particularly within the context of cyber-physical security. We delve into different domains -- the image, text, graph, audio, and video domains -- to highlight the ubiquitous and pervasive nature of transferable attacks. This paper categorizes and reviews the architecture of existing attacks from various viewpoints: data, process, model, and system. We further examine the implications of transferable attacks in practical scenarios such as autonomous driving, speech recognition, and large language models (LLMs). Additionally, we outline the potential research directions to encourage efforts in exploring the landscape of transferable attacks. This survey offers a holistic understanding of the prevailing transferable attacks and their impacts across different domains.
SAFER: Situation Aware Facial Emotion Recognition
Jun 14, 2023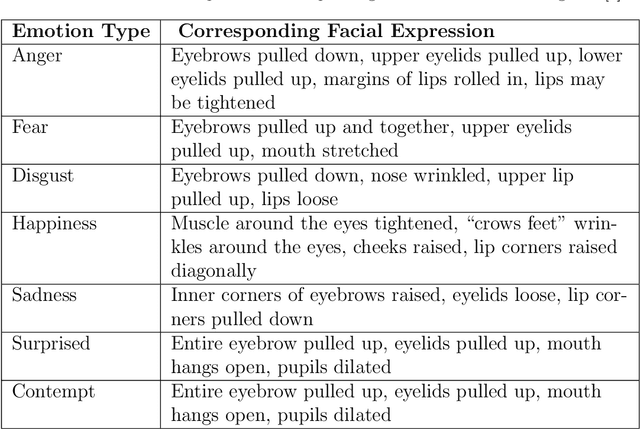


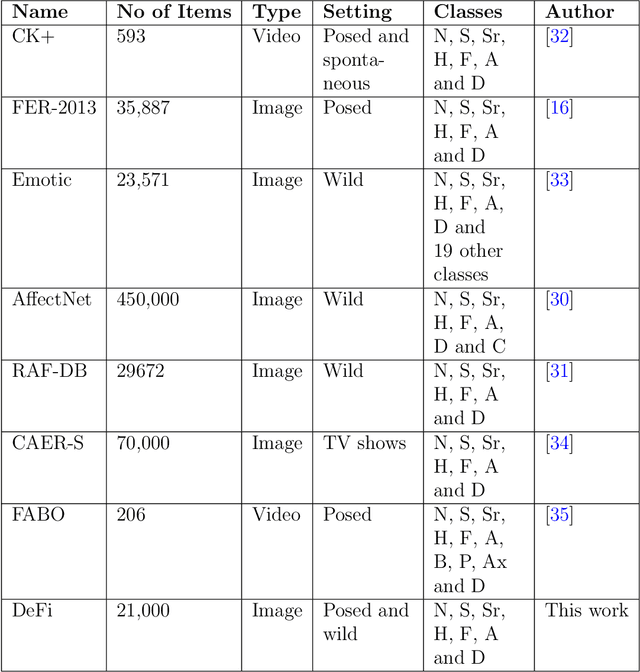
In this paper, we present SAFER, a novel system for emotion recognition from facial expressions. It employs state-of-the-art deep learning techniques to extract various features from facial images and incorporates contextual information, such as background and location type, to enhance its performance. The system has been designed to operate in an open-world setting, meaning it can adapt to unseen and varied facial expressions, making it suitable for real-world applications. An extensive evaluation of SAFER against existing works in the field demonstrates improved performance, achieving an accuracy of 91.4% on the CAER-S dataset. Additionally, the study investigates the effect of novelty such as face masks during the Covid-19 pandemic on facial emotion recognition and critically examines the limitations of mainstream facial expressions datasets. To address these limitations, a novel dataset for facial emotion recognition is proposed. The proposed dataset and the system are expected to be useful for various applications such as human-computer interaction, security, and surveillance.
Occlusion Aware Student Emotion Recognition based on Facial Action Unit Detection
Jul 18, 2023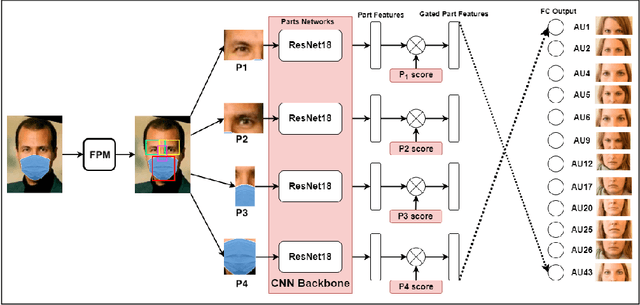
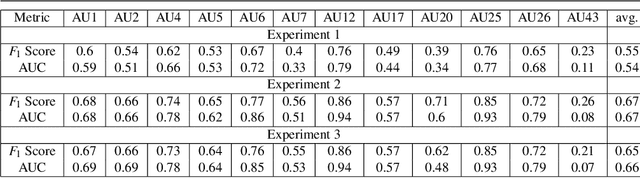

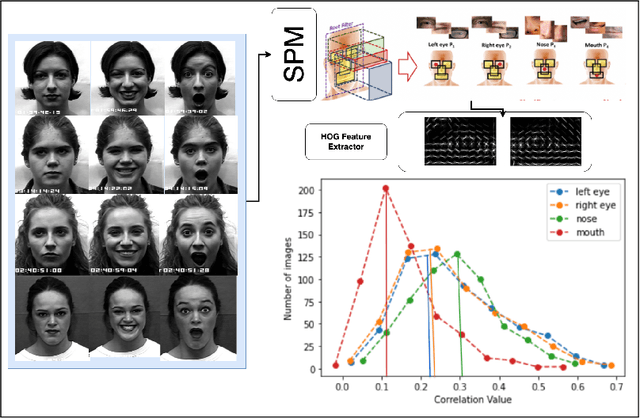
Given that approximately half of science, technology, engineering, and mathematics (STEM) undergraduate students in U.S. colleges and universities leave by the end of the first year [15], it is crucial to improve the quality of classroom environments. This study focuses on monitoring students' emotions in the classroom as an indicator of their engagement and proposes an approach to address this issue. The impact of different facial parts on the performance of an emotional recognition model is evaluated through experimentation. To test the proposed model under partial occlusion, an artificially occluded dataset is introduced. The novelty of this work lies in the proposal of an occlusion-aware architecture for facial action units (AUs) extraction, which employs attention mechanism and adaptive feature learning. The AUs can be used later to classify facial expressions in classroom settings. This research paper's findings provide valuable insights into handling occlusion in analyzing facial images for emotional engagement analysis. The proposed experiments demonstrate the significance of considering occlusion and enhancing the reliability of facial analysis models in classroom environments. These findings can also be extended to other settings where occlusions are prevalent.