 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
SADRNet: Self-Aligned Dual Face Regression Networks for Robust 3D Dense Face Alignment and Reconstruction
Jun 06, 2021

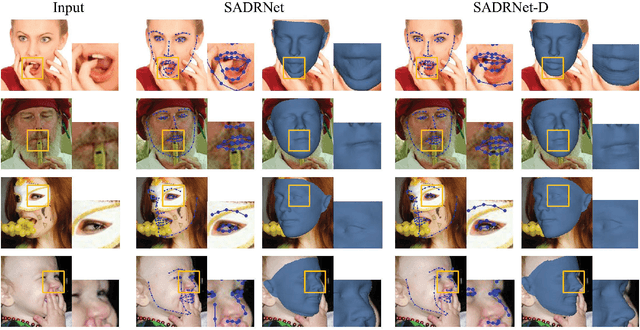

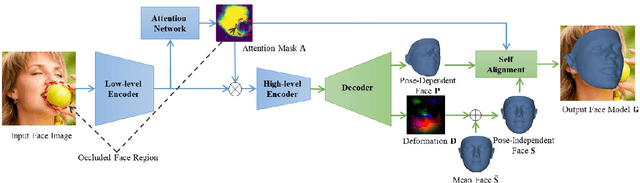
Three-dimensional face dense alignment and reconstruction in the wild is a challenging problem as partial facial information is commonly missing in occluded and large pose face images. Large head pose variations also increase the solution space and make the modeling more difficult. Our key idea is to model occlusion and pose to decompose this challenging task into several relatively more manageable subtasks. To this end, we propose an end-to-end framework, termed as Self-aligned Dual face Regression Network (SADRNet), which predicts a pose-dependent face, a pose-independent face. They are combined by an occlusion-aware self-alignment to generate the final 3D face. Extensive experiments on two popular benchmarks, AFLW2000-3D and Florence, demonstrate that the proposed method achieves significant superior performance over existing state-of-the-art methods.
Emotion Recognition for Healthcare Surveillance Systems Using Neural Networks: A Survey
Jul 13, 2021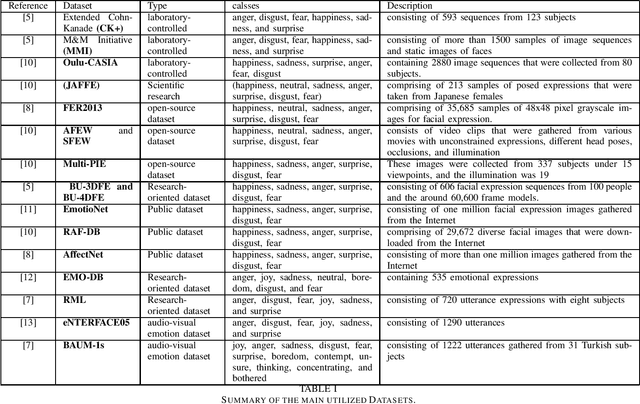

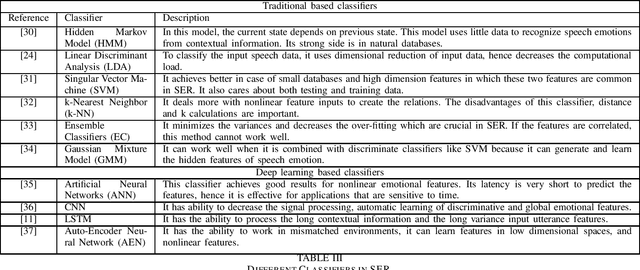

Recognizing the patient's emotions using deep learning techniques has attracted significant attention recently due to technological advancements. Automatically identifying the emotions can help build smart healthcare centers that can detect depression and stress among the patients in order to start the medication early. Using advanced technology to identify emotions is one of the most exciting topics as it defines the relationships between humans and machines. Machines learned how to predict emotions by adopting various methods. In this survey, we present recent research in the field of using neural networks to recognize emotions. We focus on studying emotions' recognition from speech, facial expressions, and audio-visual input and show the different techniques of deploying these algorithms in the real world. These three emotion recognition techniques can be used as a surveillance system in healthcare centers to monitor patients. We conclude the survey with a presentation of the challenges and the related future work to provide an insight into the applications of using emotion recognition.
Remote Heart Rate Measurement from Highly Compressed Facial Videos: an End-to-end Deep Learning Solution with Video Enhancement
Jul 27, 2019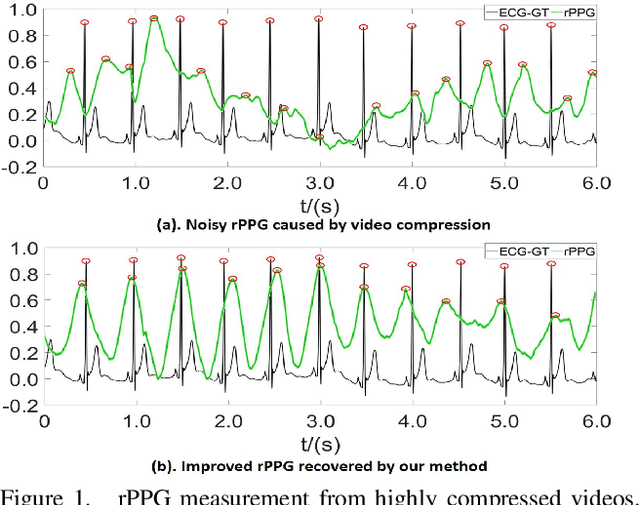

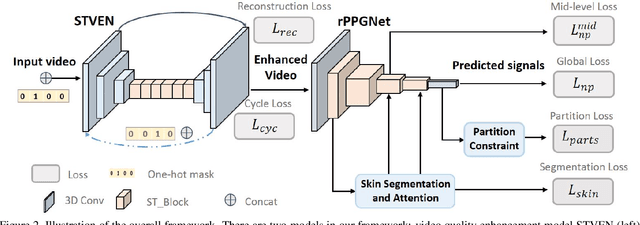
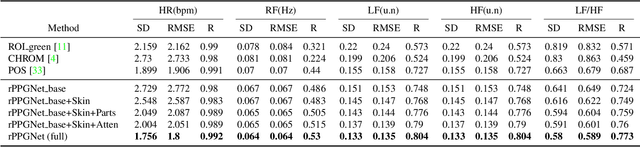
Remote photoplethysmography (rPPG), which aims at measuring heart activities without any contact, has great potential in many applications (e.g., remote healthcare). Existing rPPG approaches rely on analyzing very fine details of facial videos, which are prone to be affected by video compression. Here we propose a two-stage, end-to-end method using hidden rPPG information enhancement and attention networks, which is the first attempt to counter video compression loss and recover rPPG signals from highly compressed videos. The method includes two parts: 1) a Spatio-Temporal Video Enhancement Network (STVEN) for video enhancement, and 2) an rPPG network (rPPGNet) for rPPG signal recovery. The rPPGNet can work on its own for robust rPPG measurement, and the STVEN network can be added and jointly trained to further boost the performance especially on highly compressed videos. Comprehensive experiments are performed on two benchmark datasets to show that, 1) the proposed method not only achieves superior performance on compressed videos with high-quality videos pair, 2) it also generalizes well on novel data with only compressed videos available, which implies the promising potential for real world applications.
An Efficient Multitask Neural Network for Face Alignment, Head Pose Estimation and Face Tracking
Mar 13, 2021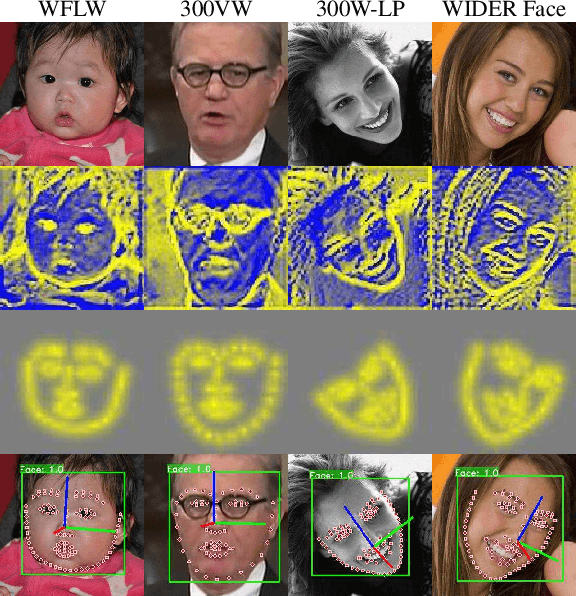
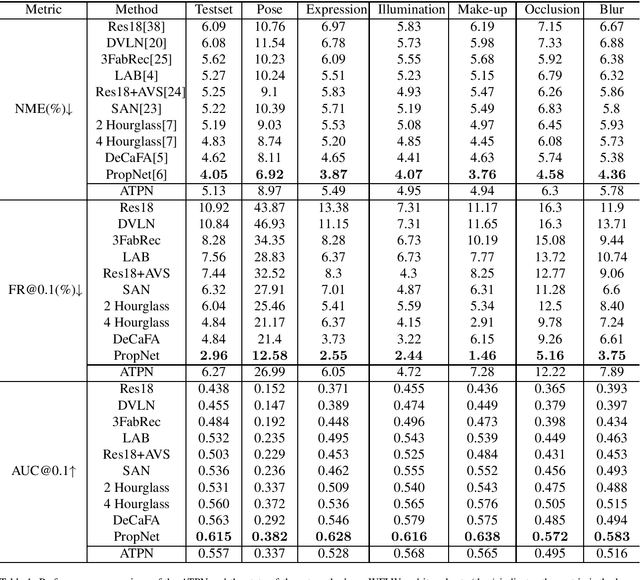
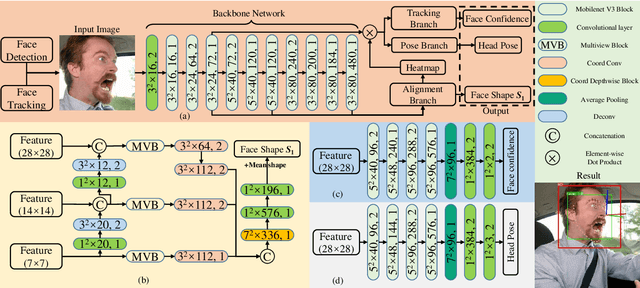
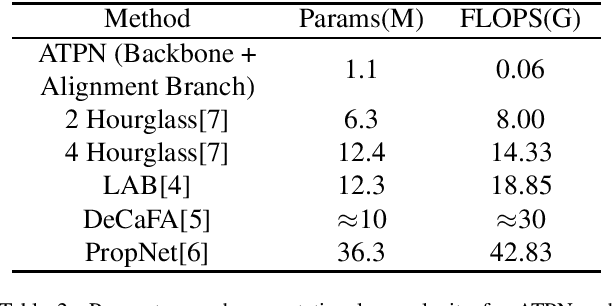
While convolutional neural networks (CNNs) have significantly boosted the performance of face related algorithms, maintaining accuracy and efficiency simultaneously in practical use remains challenging. Recent study shows that using a cascade of hourglass modules which consist of a number of bottom-up and top-down convolutional layers can extract facial structural information for face alignment to improve accuracy. However, previous studies have shown that features produced by shallow convolutional layers are highly correspond to edges. These features could be directly used to provide the structural information without addition cost. Motivated by this intuition, we propose an efficient multitask face alignment, face tracking and head pose estimation network (ATPN). Specifically, we introduce a shortcut connection between shallow-layer features and deep-layer features to provide the structural information for face alignment and apply the CoordConv to the last few layers to provide coordinate information. The predicted facial landmarks enable us to generate a cheap heatmap which contains both geometric and appearance information for head pose estimation and it also provides attention clues for face tracking. Moreover, the face tracking task saves us the face detection procedure for each frame, which is significant to boost performance for video-based tasks. The proposed framework is evaluated on four benchmark datasets, WFLW, 300VW, WIDER Face and 300W-LP. The experimental results show that the ATPN achieves improved performance compared to previous state-of-the-art methods while having less number of parameters and FLOPS.
The Effect of Wearing a Face Mask on Face Image Quality
Nov 02, 2021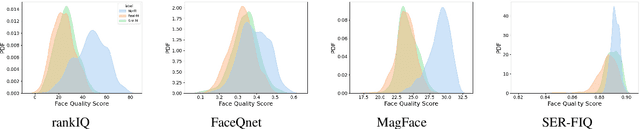

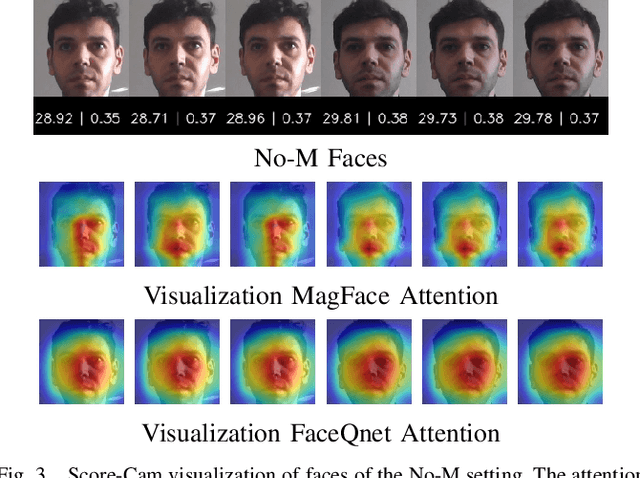
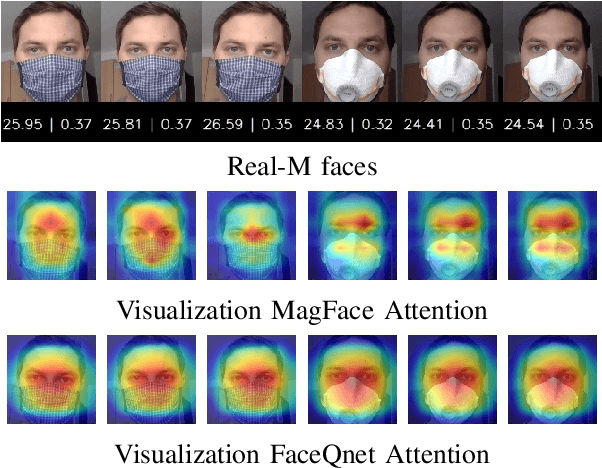
Due to the COVID-19 situation, face masks have become a main part of our daily life. Wearing mouth-and-nose protection has been made a mandate in many public places, to prevent the spread of the COVID-19 virus. However, face masks affect the performance of face recognition, since a large area of the face is covered. The effect of wearing a face mask on the different components of the face recognition system in a collaborative environment is a problem that is still to be fully studied. This work studies, for the first time, the effect of wearing a face mask on face image quality by utilising state-of-the-art face image quality assessment methods of different natures. This aims at providing better understanding on the effect of face masks on the operation of face recognition as a whole system. In addition, we further studied the effect of simulated masks on face image utility in comparison to real face masks. We discuss the correlation between the mask effect on face image quality and that on the face verification performance by automatic systems and human experts, indicating a consistent trend between both factors. The evaluation is conducted on the database containing (1) no-masked faces, (2) real face masks, and (3) simulated face masks, by synthetically generating digital facial masks on no-masked faces. Finally, a visual interpretation of the face areas contributing to the quality score of a selected set of quality assessment methods is provided to give a deeper insight into the difference of network decisions in masked and non-masked faces, among other variations.
Facial Landmarks Detection by Self-Iterative Regression based Landmarks-Attention Network
Mar 18, 2018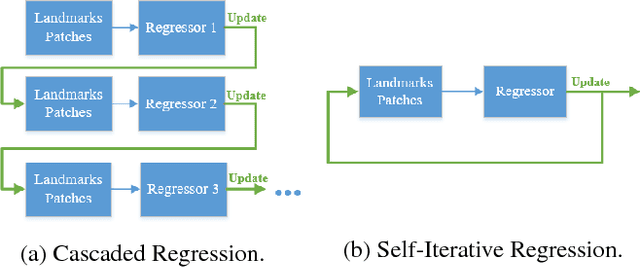
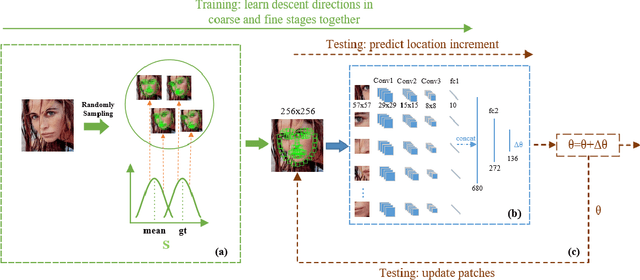
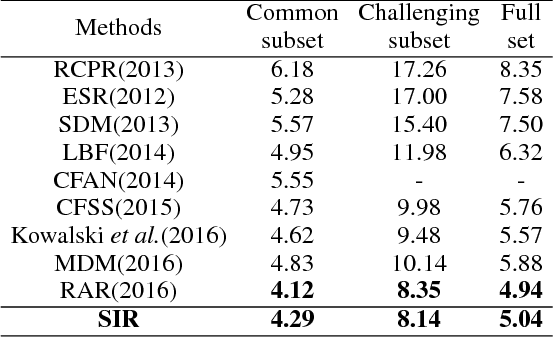
Cascaded Regression (CR) based methods have been proposed to solve facial landmarks detection problem, which learn a series of descent directions by multiple cascaded regressors separately trained in coarse and fine stages. They outperform the traditional gradient descent based methods in both accuracy and running speed. However, cascaded regression is not robust enough because each regressor's training data comes from the output of previous regressor. Moreover, training multiple regressors requires lots of computing resources, especially for deep learning based methods. In this paper, we develop a Self-Iterative Regression (SIR) framework to improve the model efficiency. Only one self-iterative regressor is trained to learn the descent directions for samples from coarse stages to fine stages, and parameters are iteratively updated by the same regressor. Specifically, we proposed Landmarks-Attention Network (LAN) as our regressor, which concurrently learns features around each landmark and obtains the holistic location increment. By doing so, not only the rest of regressors are removed to simplify the training process, but the number of model parameters is significantly decreased. The experiments demonstrate that with only 3.72M model parameters, our proposed method achieves the state-of-the-art performance.
Improving Bag-of-Visual-Words Towards Effective Facial Expressive Image Classification
Sep 30, 2018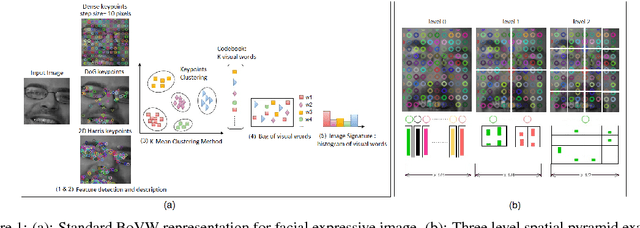
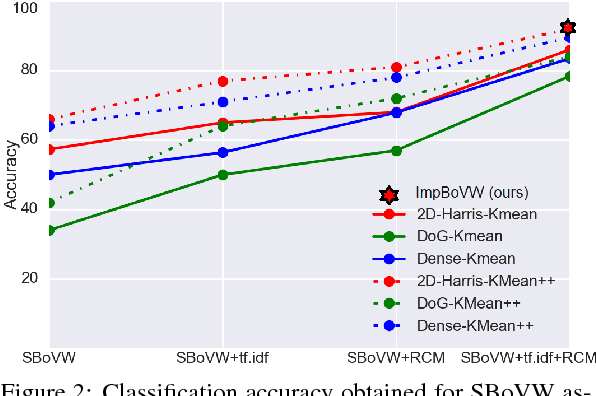
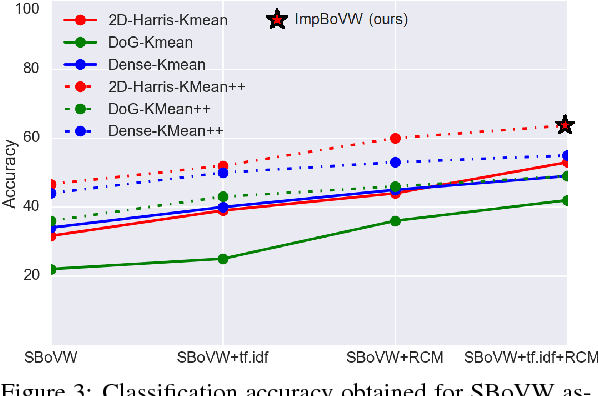
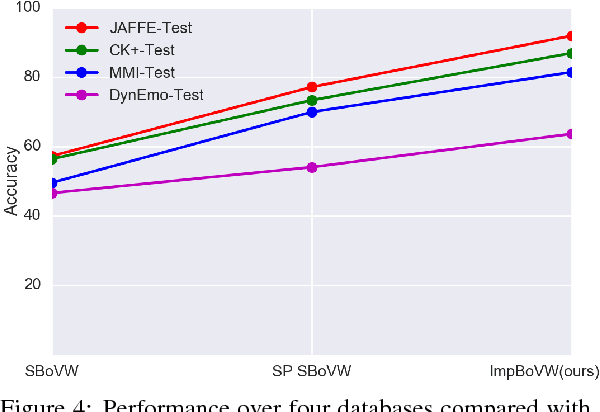
Bag-of-Visual-Words (BoVW) approach has been widely used in the recent years for image classification purposes. However, the limitations regarding optimal feature selection, clustering technique, the lack of spatial organization of the data and the weighting of visual words are crucial. These factors affect the stability of the model and reduce performance. We propose to develop an algorithm based on BoVW for facial expression analysis which goes beyond those limitations. Thus the visual codebook is built by using k-Means++ method to avoid poor clustering. To exploit reliable low level features, we search for the best feature detector that avoids locating a large number of keypoints which do not contribute to the classification process. Then, we propose to compute the relative conjunction matrix in order to preserve the spatial order of the data by coding the relationships among visual words. In addition, a weighting scheme that reflects how important a visual word is with respect to a given image is introduced. We speed up the learning process by using histogram intersection kernel by Support Vector Machine to learn a discriminative classifier. The efficiency of the proposed algorithm is compared with standard bag of visual words method and with bag of visual words method with spatial pyramid. Extensive experiments on the CK+, the MMI and the JAFFE databases show good average recognition rates. Likewise, the ability to recognize spontaneous and non-basic expressive states is investigated using the DynEmo database.
* 8 pages, 6 figures, Volume 5: VISAPPm year 2018, publisher=SciTePress, organization=INSTICC, isbn=978-989-758-290-5
Improving DeepFake Detection Using Dynamic Face Augmentation
Feb 18, 2021

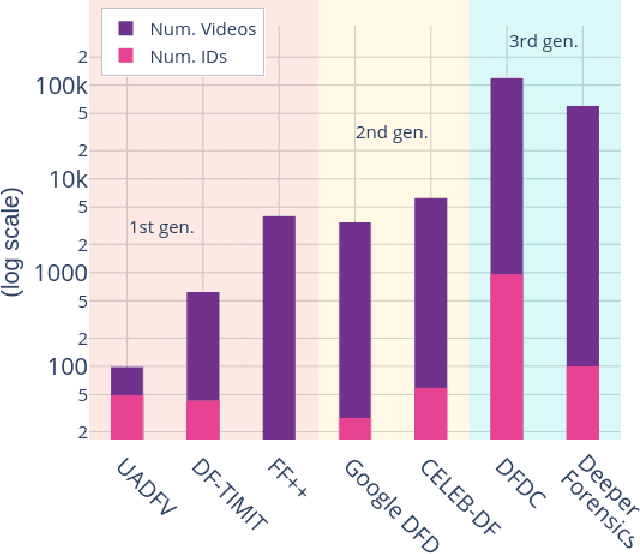
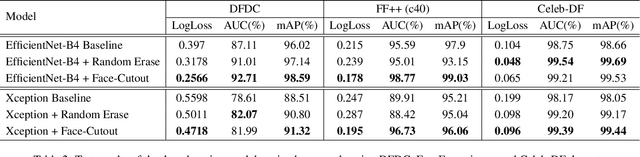
The creation of altered and manipulated faces has become more common due to the improvement of DeepFake generation methods. Simultaneously, we have seen detection models' development for differentiating between a manipulated and original face from image or video content. We have observed that most publicly available DeepFake detection datasets have limited variations, where a single face is used in many videos, resulting in an oversampled training dataset. Due to this, deep neural networks tend to overfit to the facial features instead of learning to detect manipulation features of DeepFake content. As a result, most detection architectures perform poorly when tested on unseen data. In this paper, we provide a quantitative analysis to investigate this problem and present a solution to prevent model overfitting due to the high volume of samples generated from a small number of actors. We introduce Face-Cutout, a data augmentation method for training Convolutional Neural Networks (CNN), to improve DeepFake detection. In this method, training images with various occlusions are dynamically generated using face landmark information irrespective of orientation. Unlike other general-purpose augmentation methods, it focuses on the facial information that is crucial for DeepFake detection. Our method achieves a reduction in LogLoss of 15.2% to 35.3% on different datasets, compared to other occlusion-based augmentation techniques. We show that Face-Cutout can be easily integrated with any CNN-based recognition model and improve detection performance.
OSRM-CCTV: Open-source CCTV-aware routing and navigation system for privacy, anonymity and safety (Preprint)
Aug 20, 2021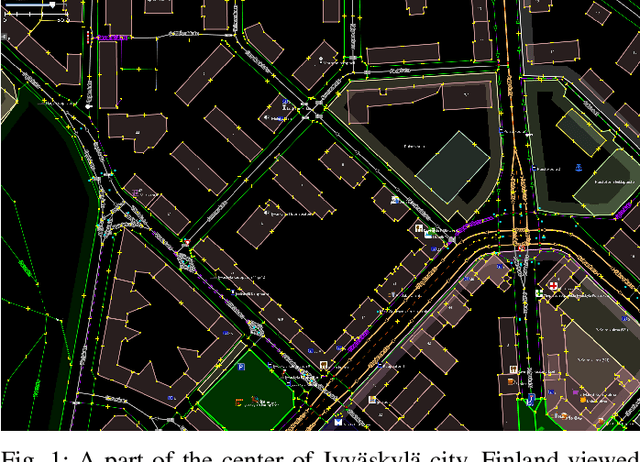
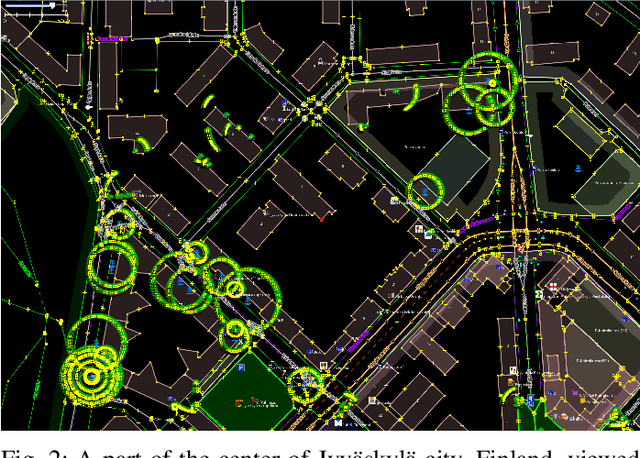
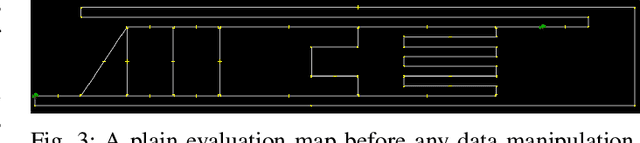
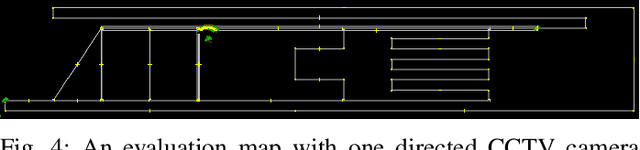
For the last several decades, the increased, widespread, unwarranted, and unaccountable use of Closed-Circuit TeleVision (CCTV) cameras globally has raised concerns about privacy risks. Additional recent features of many CCTV cameras, such as Internet of Things (IoT) connectivity and Artificial Intelligence (AI)-based facial recognition, only increase concerns among privacy advocates. Therefore, on par \emph{CCTV-aware solutions} must exist that provide privacy, safety, and cybersecurity features. We argue that an important step forward is to develop solutions addressing privacy concerns via routing and navigation systems (e.g., OpenStreetMap, Google Maps) that provide both privacy and safety options for areas where cameras are known to be present. However, at present no routing and navigation system, whether online or offline, provide corresponding CCTV-aware functionality. In this paper we introduce OSRM-CCTV -- the first and only CCTV-aware routing and navigation system designed and built for privacy, anonymity and safety applications. We validate and demonstrate the effectiveness and usability of the system on a handful of synthetic and real-world examples. To help validate our work as well as to further encourage the development and wide adoption of the system, we release OSRM-CCTV as open-source.
Multilinear Biased Discriminant Analysis: A Novel Method for Facial Action Unit Representation
Apr 04, 2010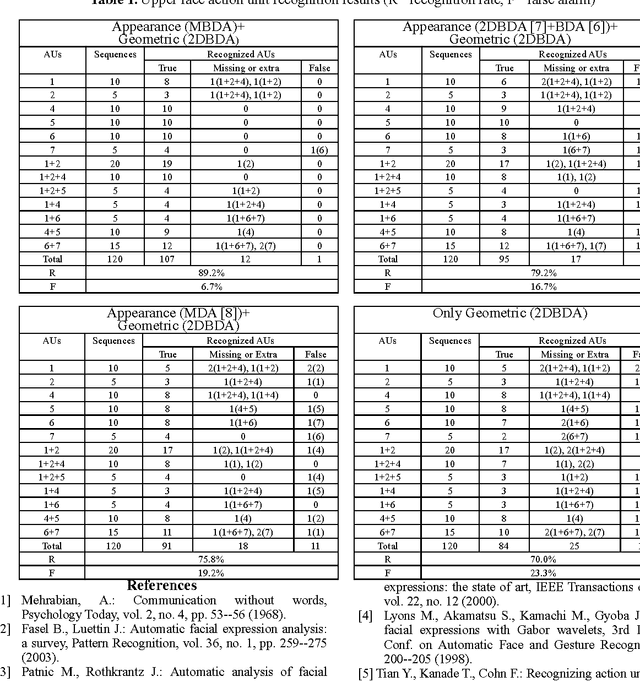
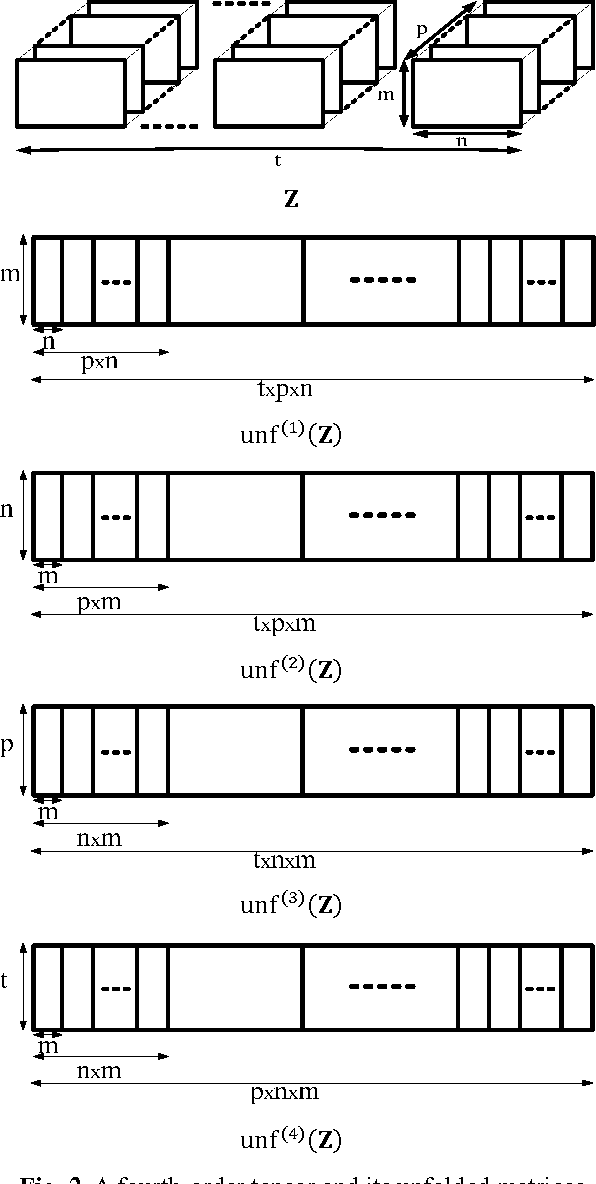
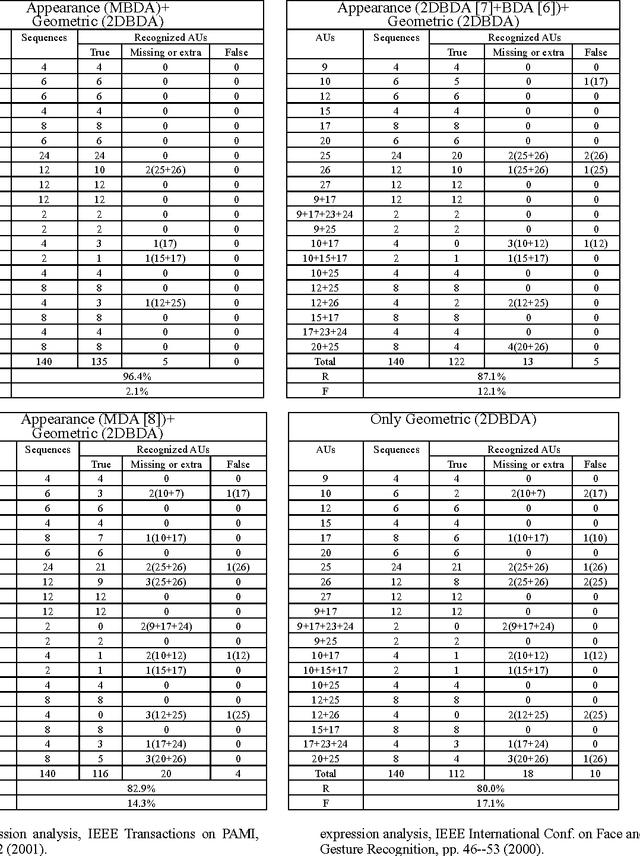

In this paper a novel efficient method for representation of facial action units by encoding an image sequence as a fourth-order tensor is presented. The multilinear tensor-based extension of the biased discriminant analysis (BDA) algorithm, called multilinear biased discriminant analysis (MBDA), is first proposed. Then, we apply the MBDA and two-dimensional BDA (2DBDA) algorithms, as the dimensionality reduction techniques, to Gabor representations and the geometric features of the input image sequence respectively. The proposed scheme can deal with the asymmetry between positive and negative samples as well as curse of dimensionality dilemma. Extensive experiments on Cohn-Kanade database show the superiority of the proposed method for representation of the subtle changes and the temporal information involved in formation of the facial expressions. As an accurate tool, this representation can be applied to many areas such as recognition of spontaneous and deliberate facial expressions, multi modal/media human computer interaction and lie detection efforts.