 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSADRNet: Self-Aligned Dual Face Regression Networks for Robust 3D Dense Face Alignment and Reconstruction
Paper and Code

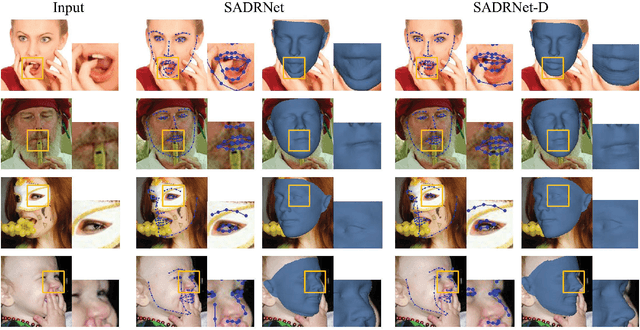

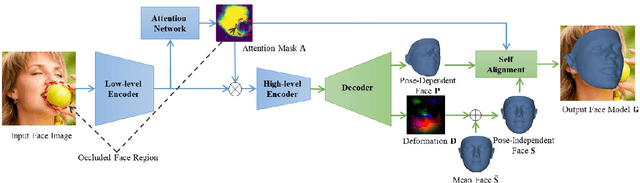
Three-dimensional face dense alignment and reconstruction in the wild is a challenging problem as partial facial information is commonly missing in occluded and large pose face images. Large head pose variations also increase the solution space and make the modeling more difficult. Our key idea is to model occlusion and pose to decompose this challenging task into several relatively more manageable subtasks. To this end, we propose an end-to-end framework, termed as Self-aligned Dual face Regression Network (SADRNet), which predicts a pose-dependent face, a pose-independent face. They are combined by an occlusion-aware self-alignment to generate the final 3D face. Extensive experiments on two popular benchmarks, AFLW2000-3D and Florence, demonstrate that the proposed method achieves significant superior performance over existing state-of-the-art methods.