 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
SAFA: Structure Aware Face Animation
Nov 09, 2021
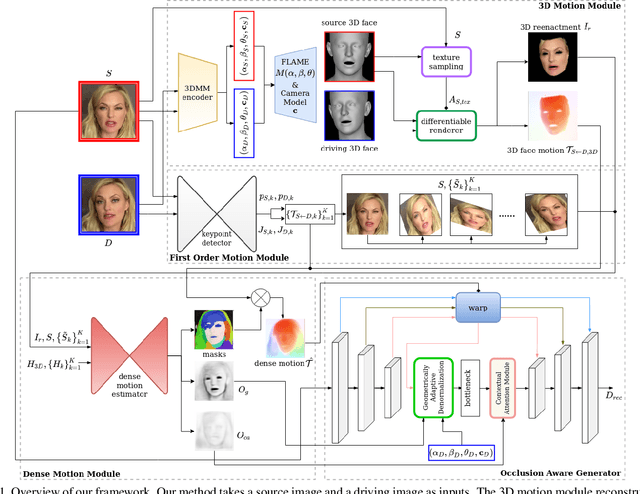
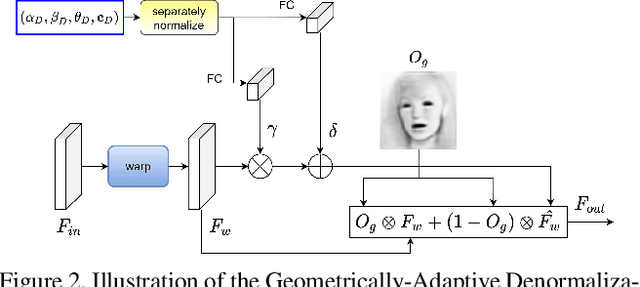
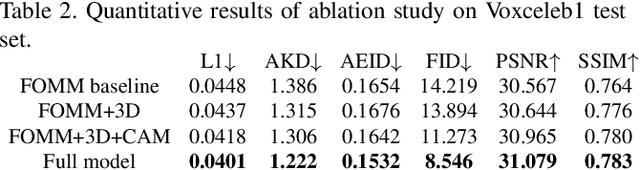
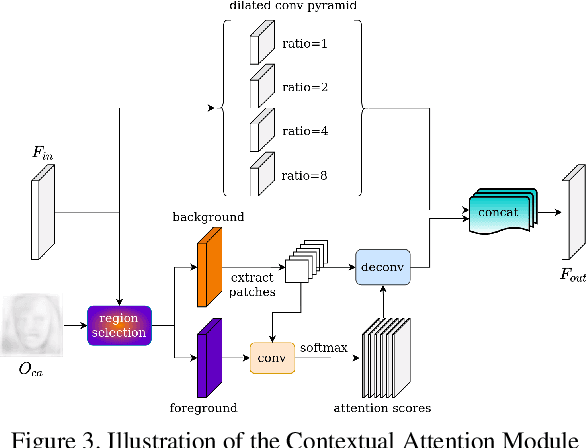
Recent success of generative adversarial networks (GAN) has made great progress on the face animation task. However, the complex scene structure of a face image still makes it a challenge to generate videos with face poses significantly deviating from the source image. On one hand, without knowing the facial geometric structure, generated face images might be improperly distorted. On the other hand, some area of the generated image might be occluded in the source image, which makes it difficult for GAN to generate realistic appearance. To address these problems, we propose a structure aware face animation (SAFA) method which constructs specific geometric structures to model different components of a face image. Following the well recognized motion based face animation technique, we use a 3D morphable model (3DMM) to model the face, multiple affine transforms to model the other foreground components like hair and beard, and an identity transform to model the background. The 3DMM geometric embedding not only helps generate realistic structure for the driving scene, but also contributes to better perception of occluded area in the generated image. Besides, we further propose to exploit the widely studied inpainting technique to faithfully recover the occluded image area. Both quantitative and qualitative experiment results have shown the superiority of our method. Code is available at https://github.com/Qiulin-W/SAFA.
Geometrically Adaptive Dictionary Attack on Face Recognition
Nov 08, 2021CNN-based face recognition models have brought remarkable performance improvement, but they are vulnerable to adversarial perturbations. Recent studies have shown that adversaries can fool the models even if they can only access the models' hard-label output. However, since many queries are needed to find imperceptible adversarial noise, reducing the number of queries is crucial for these attacks. In this paper, we point out two limitations of existing decision-based black-box attacks. We observe that they waste queries for background noise optimization, and they do not take advantage of adversarial perturbations generated for other images. We exploit 3D face alignment to overcome these limitations and propose a general strategy for query-efficient black-box attacks on face recognition named Geometrically Adaptive Dictionary Attack (GADA). Our core idea is to create an adversarial perturbation in the UV texture map and project it onto the face in the image. It greatly improves query efficiency by limiting the perturbation search space to the facial area and effectively recycling previous perturbations. We apply the GADA strategy to two existing attack methods and show overwhelming performance improvement in the experiments on the LFW and CPLFW datasets. Furthermore, we also present a novel attack strategy that can circumvent query similarity-based stateful detection that identifies the process of query-based black-box attacks.
Performance analysis of weighted low rank model with sparse image histograms for face recognition under lowlevel illumination and occlusion
Jul 24, 2020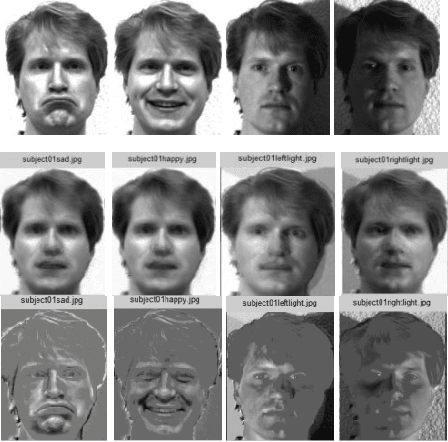
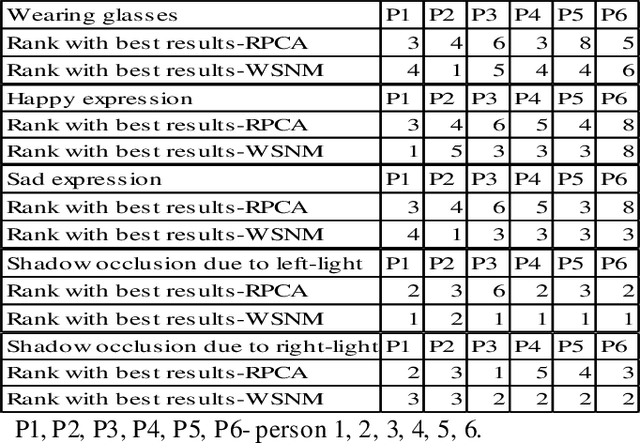
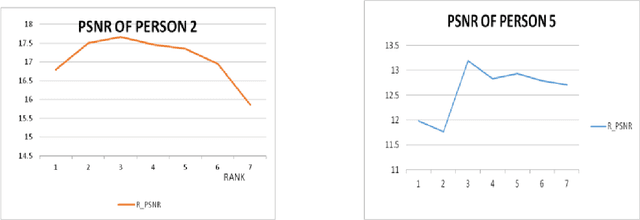
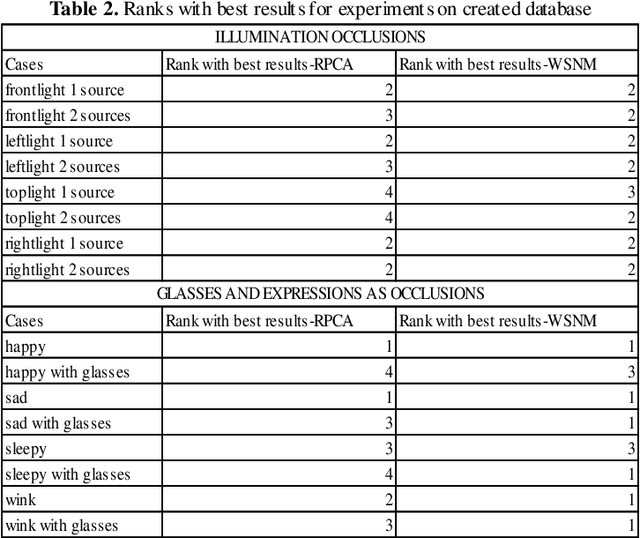
In a broad range of computer vision applications, the purpose of Low-rank matrix approximation (LRMA) models is to recover the underlying low-rank matrix from its degraded observation. The latest LRMA methods - Robust Principal Component Analysis (RPCA) resort to using the nuclear norm minimization (NNM) as a convex relaxation of the non-convex rank minimization. However, NNM tends to over-shrink the rank components and treats the different rank components equally, limiting its flexibility in practical applications. We use a more flexible model, namely the Weighted Schatten p-Norm Minimization (WSNM), to generalize the NNM to the Schatten p-norm minimization with weights assigned to different singular values. The proposed WSNM not only gives a better approximation to the original low-rank assumption but also considers the importance of different rank components. In this paper, a comparison of the low-rank recovery performance of two LRMA algorithms- RPCA and WSNM is brought out on occluded human facial images. The analysis is performed on facial images from the Yale database and over own database , where different facial expressions, spectacles, varying illumination account for the facial occlusions. The paper also discusses the prominent trends observed from the experimental results performed through the application of these algorithms. As low-rank images sometimes might fail to capture the details of a face adequately, we further propose a novel method to use the image-histogram of the sparse images thus obtained to identify the individual in any given image. Extensive experimental results show, both qualitatively and quantitatively, that WSNM surpasses RPCA in its performance more effectively by removing facial occlusions, thus giving recovered low-rank images of higher PSNR and SSIM.
Unobtrusive Pain Monitoring in Older Adults with Dementia using Pairwise and Contrastive Training
Jan 08, 2021
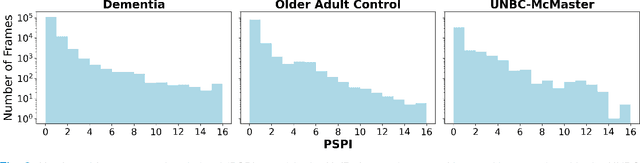
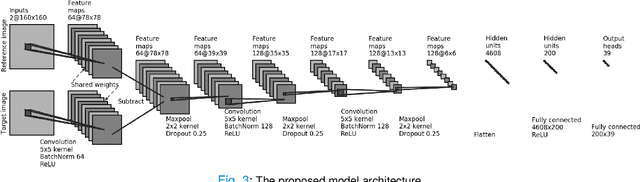
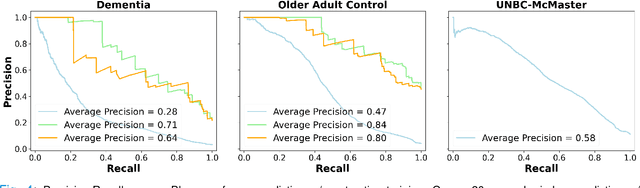
Although pain is frequent in old age, older adults are often undertreated for pain. This is especially the case for long-term care residents with moderate to severe dementia who cannot report their pain because of cognitive impairments that accompany dementia. Nursing staff acknowledge the challenges of effectively recognizing and managing pain in long-term care facilities due to lack of human resources and, sometimes, expertise to use validated pain assessment approaches on a regular basis. Vision-based ambient monitoring will allow for frequent automated assessments so care staff could be automatically notified when signs of pain are displayed. However, existing computer vision techniques for pain detection are not validated on faces of older adults or people with dementia, and this population is not represented in existing facial expression datasets of pain. We present the first fully automated vision-based technique validated on a dementia cohort. Our contributions are threefold. First, we develop a deep learning-based computer vision system for detecting painful facial expressions on a video dataset that is collected unobtrusively from older adult participants with and without dementia. Second, we introduce a pairwise comparative inference method that calibrates to each person and is sensitive to changes in facial expression while using training data more efficiently than sequence models. Third, we introduce a fast contrastive training method that improves cross-dataset performance. Our pain estimation model outperforms baselines by a wide margin, especially when evaluated on faces of people with dementia. Pre-trained model and demo code available at https://github.com/TaatiTeam/pain_detection_demo
Learning Emotional-Blinded Face Representations
Sep 18, 2020
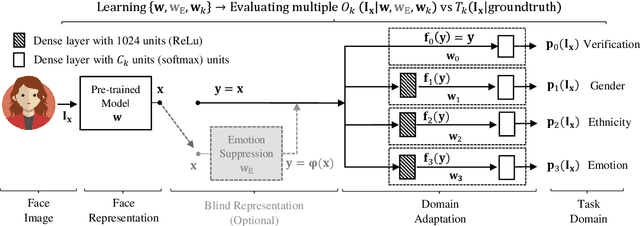
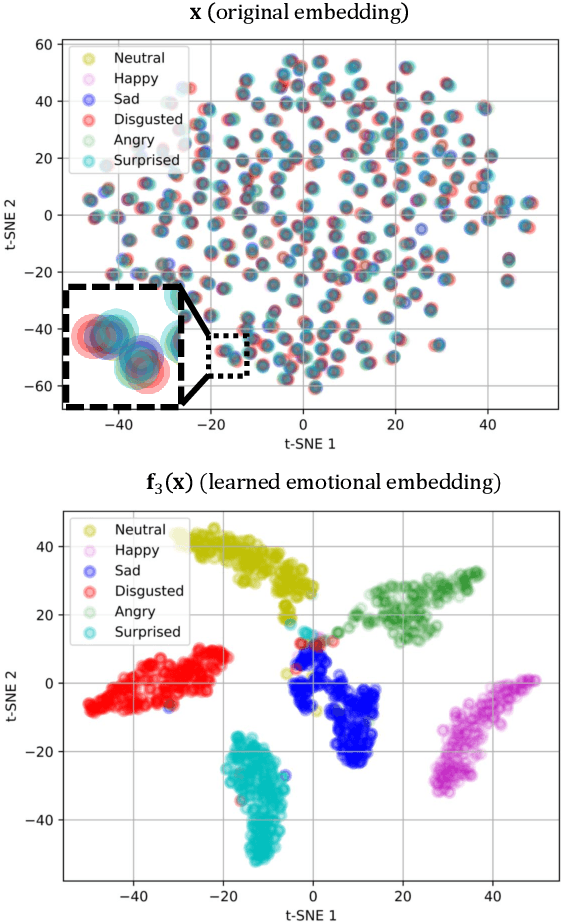
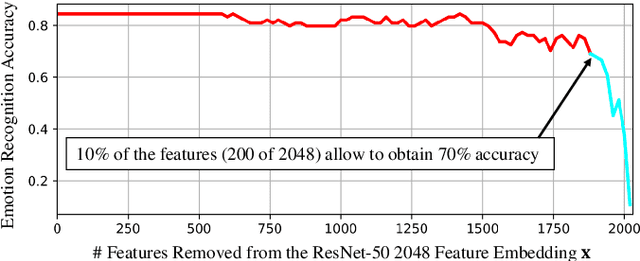
We propose two face representations that are blind to facial expressions associated to emotional responses. This work is in part motivated by new international regulations for personal data protection, which enforce data controllers to protect any kind of sensitive information involved in automatic processes. The advances in Affective Computing have contributed to improve human-machine interfaces but, at the same time, the capacity to monitorize emotional responses triggers potential risks for humans, both in terms of fairness and privacy. We propose two different methods to learn these expression-blinded facial features. We show that it is possible to eliminate information related to emotion recognition tasks, while the performance of subject verification, gender recognition, and ethnicity classification are just slightly affected. We also present an application to train fairer classifiers in a case study of attractiveness classification with respect to a protected facial expression attribute. The results demonstrate that it is possible to reduce emotional information in the face representation while retaining competitive performance in other face-based artificial intelligence tasks.
Fawkes: Protecting Personal Privacy against Unauthorized Deep Learning Models
Feb 19, 2020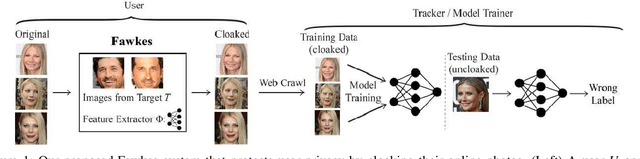

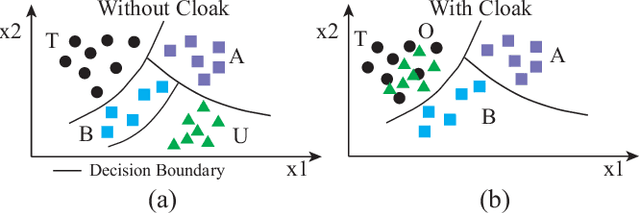
Today's proliferation of powerful facial recognition models poses a real threat to personal privacy. As Clearview.ai demonstrated, anyone can canvas the Internet for data, and train highly accurate facial recognition models of us without our knowledge. We need tools to protect ourselves from unauthorized facial recognition systems and their numerous potential misuses. Unfortunately, work in related areas are limited in practicality and effectiveness. In this paper, we propose Fawkes, a system that allow individuals to inoculate themselves against unauthorized facial recognition models. Fawkes achieves this by helping users adding imperceptible pixel-level changes (we call them "cloaks") to their own photos before publishing them online. When collected by a third-party "tracker" and used to train facial recognition models, these "cloaked" images produce functional models that consistently misidentify the user. We experimentally prove that Fawkes provides 95+% protection against user recognition regardless of how trackers train their models. Even when clean, uncloaked images are "leaked" to the tracker and used for training, Fawkes can still maintain a 80+% protection success rate. In fact, we perform real experiments against today's state-of-the-art facial recognition services and achieve 100% success. Finally, we show that Fawkes is robust against a variety of countermeasures that try to detect or disrupt cloaks.
DeepFake Detection with Inconsistent Head Poses: Reproducibility and Analysis
Aug 28, 2021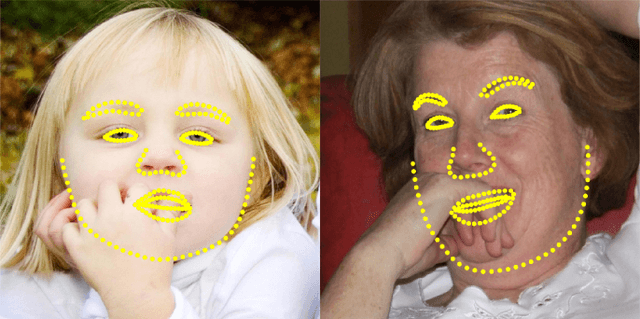
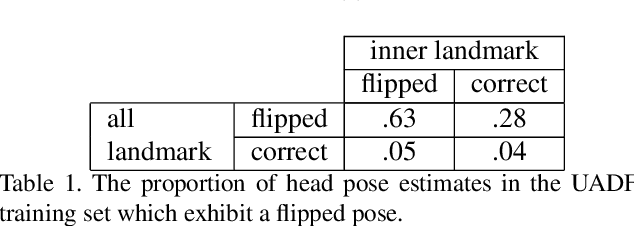

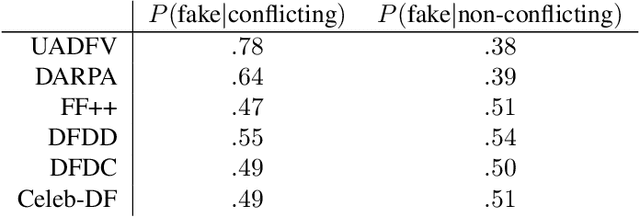
Applications of deep learning to synthetic media generation allow the creation of convincing forgeries, called DeepFakes, with limited technical expertise. DeepFake detection is an increasingly active research area. In this paper, we analyze an existing DeepFake detection technique based on head pose estimation, which can be applied when fake images are generated with an autoencoder-based face swap. Existing literature suggests that this method is an effective DeepFake detector, and its motivating principles are attractively simple. With an eye towards using these principles to develop new DeepFake detectors, we conduct a reproducibility study of the existing method. We conclude that its merits are dramatically overstated, despite its celebrated status. By investigating this discrepancy we uncover a number of important and generalizable insights related to facial landmark detection, identity-agnostic head pose estimation, and algorithmic bias in DeepFake detectors. Our results correct the current literature's perception of state of the art performance for DeepFake detection.
PoseFace: Pose-Invariant Features and Pose-Adaptive Loss for Face Recognition
Jul 25, 2021
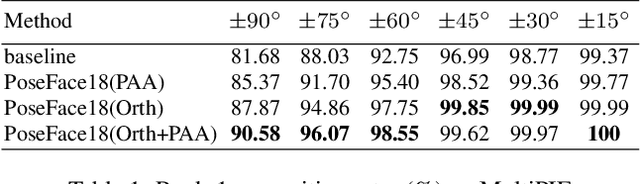
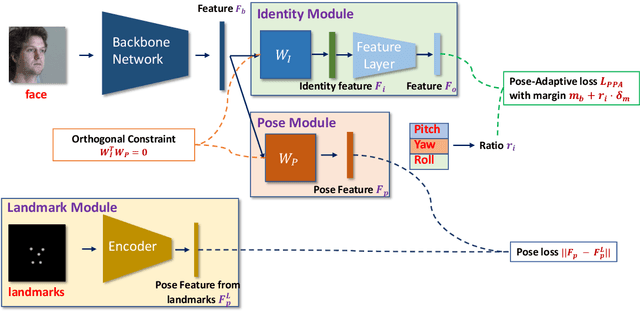
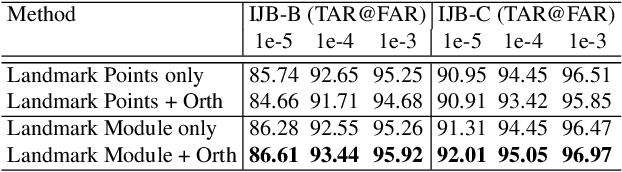
Despite the great success achieved by deep learning methods in face recognition, severe performance drops are observed for large pose variations in unconstrained environments (e.g., in cases of surveillance and photo-tagging). To address it, current methods either deploy pose-specific models or frontalize faces by additional modules. Still, they ignore the fact that identity information should be consistent across poses and are not realizing the data imbalance between frontal and profile face images during training. In this paper, we propose an efficient PoseFace framework which utilizes the facial landmarks to disentangle the pose-invariant features and exploits a pose-adaptive loss to handle the imbalance issue adaptively. Extensive experimental results on the benchmarks of Multi-PIE, CFP, CPLFW and IJB have demonstrated the superiority of our method over the state-of-the-arts.
PIRenderer: Controllable Portrait Image Generation via Semantic Neural Rendering
Sep 17, 2021
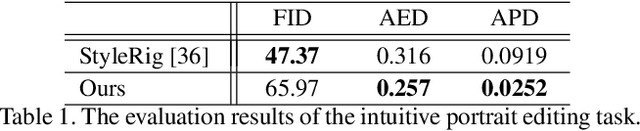
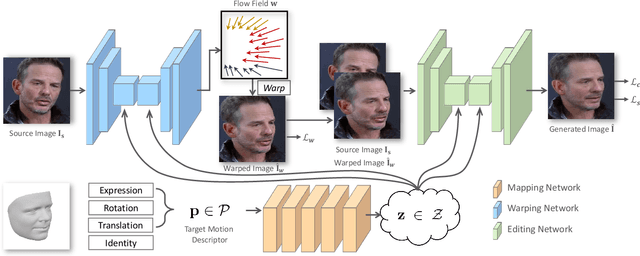

Generating portrait images by controlling the motions of existing faces is an important task of great consequence to social media industries. For easy use and intuitive control, semantically meaningful and fully disentangled parameters should be used as modifications. However, many existing techniques do not provide such fine-grained controls or use indirect editing methods i.e. mimic motions of other individuals. In this paper, a Portrait Image Neural Renderer (PIRenderer) is proposed to control the face motions with the parameters of three-dimensional morphable face models (3DMMs). The proposed model can generate photo-realistic portrait images with accurate movements according to intuitive modifications. Experiments on both direct and indirect editing tasks demonstrate the superiority of this model. Meanwhile, we further extend this model to tackle the audio-driven facial reenactment task by extracting sequential motions from audio inputs. We show that our model can generate coherent videos with convincing movements from only a single reference image and a driving audio stream. Our source code is available at https://github.com/RenYurui/PIRender.
Transferring Knowledge with Attention Distillation for Multi-Domain Image-to-Image Translation
Aug 17, 2021



Gradient-based attention modeling has been used widely as a way to visualize and understand convolutional neural networks. However, exploiting these visual explanations during the training of generative adversarial networks (GANs) is an unexplored area in computer vision research. Indeed, we argue that this kind of information can be used to influence GANs training in a positive way. For this reason, in this paper, it is shown how gradient based attentions can be used as knowledge to be conveyed in a teacher-student paradigm for multi-domain image-to-image translation tasks in order to improve the results of the student architecture. Further, it is demonstrated how "pseudo"-attentions can also be employed during training when teacher and student networks are trained on different domains which share some similarities. The approach is validated on multi-domain facial attributes transfer and human expression synthesis showing both qualitative and quantitative results.