 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Does RL Help Medical VLMs? Disentangling Vision, SFT, and RL Gains
Mar 01, 2026Reinforcement learning (RL) is increasingly used to post-train medical Vision-Language Models (VLMs), yet it remains unclear whether RL improves medical visual reasoning or mainly sharpens behaviors already induced by supervised fine-tuning (SFT). We present a controlled study that disentangles these effects along three axes: vision, SFT, and RL. Using MedMNIST as a multi-modality testbed, we probe visual perception by benchmarking VLM vision towers against vision-only baselines, quantify reasoning support and sampling efficiency via Accuracy@1 versus Pass@K, and evaluate when RL closes the support gap and how gains transfer across modalities. We find that RL is most effective when the model already has non-trivial support (high Pass@K): it primarily sharpens the output distribution, improving Acc@1 and sampling efficiency, while SFT expands support and makes RL effective. Based on these findings, we propose a boundary-aware recipe and instantiate it by RL post-training an OctoMed-initialized model on a small, balanced subset of PMC multiple-choice VQA, achieving strong average performance across six medical VQA benchmarks.
3D Reasoning for Unsupervised Anomaly Detection in Pediatric WbMRI
Mar 24, 2021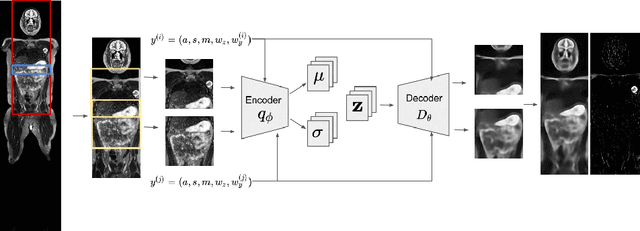
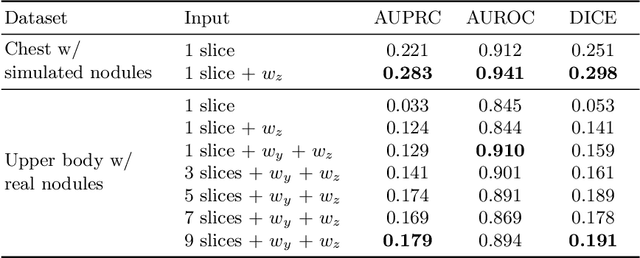

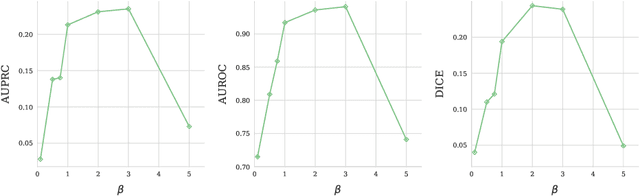
Modern deep unsupervised learning methods have shown great promise for detecting diseases across a variety of medical imaging modalities. While previous generative modeling approaches successfully perform anomaly detection by learning the distribution of healthy 2D image slices, they process such slices independently and ignore the fact that they are correlated, all being sampled from a 3D volume. We show that incorporating the 3D context and processing whole-body MRI volumes is beneficial to distinguishing anomalies from their benign counterparts. In our work, we introduce a multi-channel sliding window generative model to perform lesion detection in whole-body MRI (wbMRI). Our experiments demonstrate that our proposed method significantly outperforms processing individual images in isolation and our ablations clearly show the importance of 3D reasoning. Moreover, our work also shows that it is beneficial to include additional patient-specific features to further improve anomaly detection in pediatric scans.
Unobtrusive Pain Monitoring in Older Adults with Dementia using Pairwise and Contrastive Training
Jan 08, 2021
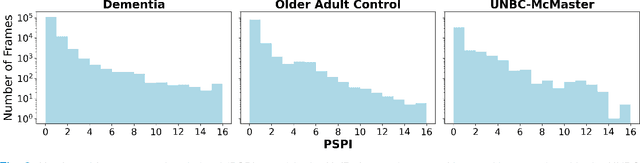
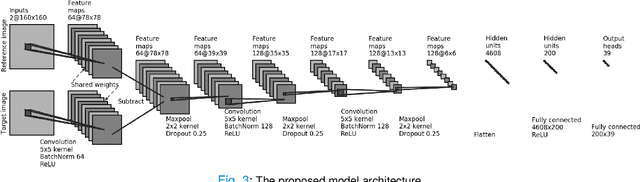
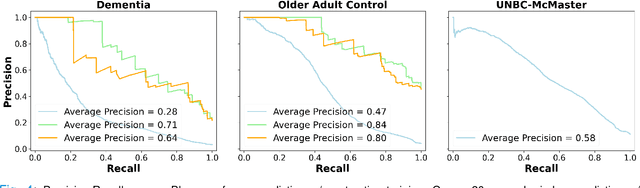
Although pain is frequent in old age, older adults are often undertreated for pain. This is especially the case for long-term care residents with moderate to severe dementia who cannot report their pain because of cognitive impairments that accompany dementia. Nursing staff acknowledge the challenges of effectively recognizing and managing pain in long-term care facilities due to lack of human resources and, sometimes, expertise to use validated pain assessment approaches on a regular basis. Vision-based ambient monitoring will allow for frequent automated assessments so care staff could be automatically notified when signs of pain are displayed. However, existing computer vision techniques for pain detection are not validated on faces of older adults or people with dementia, and this population is not represented in existing facial expression datasets of pain. We present the first fully automated vision-based technique validated on a dementia cohort. Our contributions are threefold. First, we develop a deep learning-based computer vision system for detecting painful facial expressions on a video dataset that is collected unobtrusively from older adult participants with and without dementia. Second, we introduce a pairwise comparative inference method that calibrates to each person and is sensitive to changes in facial expression while using training data more efficiently than sequence models. Third, we introduce a fast contrastive training method that improves cross-dataset performance. Our pain estimation model outperforms baselines by a wide margin, especially when evaluated on faces of people with dementia. Pre-trained model and demo code available at https://github.com/TaatiTeam/pain_detection_demo
Using Generative Models for Pediatric wbMRI
Jun 01, 2020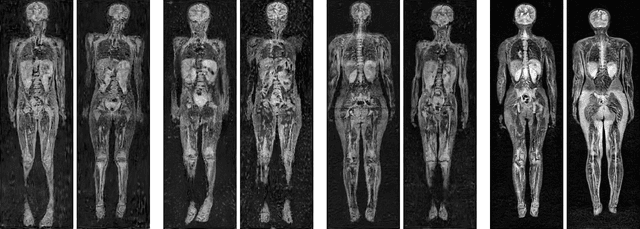
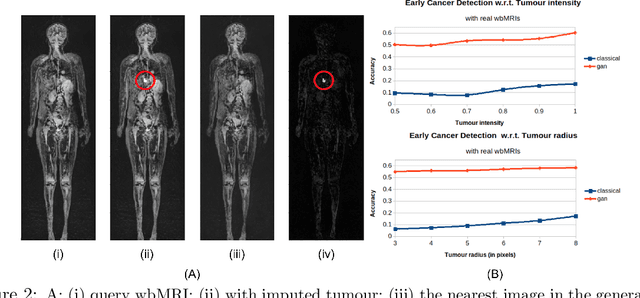
Early detection of cancer is key to a good prognosis and requires frequent testing, especially in pediatrics. Whole-body magnetic resonance imaging (wbMRI) is an essential part of several well-established screening protocols, with screening starting in early childhood. To date, machine learning (ML) has been used on wbMRI images to stage adult cancer patients. It is not possible to use such tools in pediatrics due to the changing bone signal throughout growth, the difficulty of obtaining these images in young children due to movement and limited compliance, and the rarity of positive cases. We evaluate the quality of wbMRI images generated using generative adversarial networks (GANs) trained on wbMRI data from The Hospital for Sick Children in Toronto. We use the Frchet Inception Distance (FID) metric, Domain Frchet Distance (DFD), and blind tests with a radiology fellow for evaluation. We demonstrate that StyleGAN2 provides the best performance in generating wbMRI images with respect to all three metrics.