 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Beholder-GAN: Generation and Beautification of Facial Images with Conditioning on Their Beauty Level
Feb 10, 2019

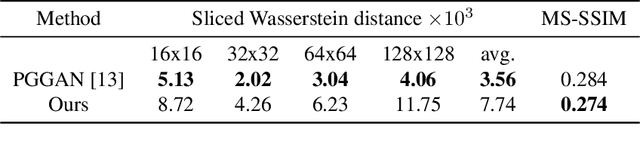

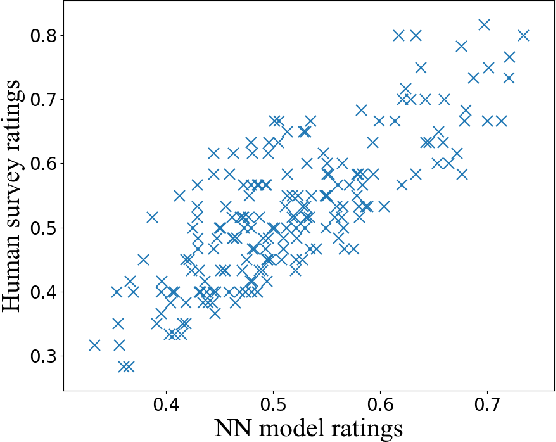
Beauty is in the eye of the beholder. This maxim, emphasizing the subjectivity of the perception of beauty, has enjoyed a wide consensus since ancient times. In the digitalera, data-driven methods have been shown to be able to predict human-assigned beauty scores for facial images. In this work, we augment this ability and train a generative model that generates faces conditioned on a requested beauty score. In addition, we show how this trained generator can be used to beautify an input face image. By doing so, we achieve an unsupervised beautification model, in the sense that it relies on no ground truth target images.
A Study of Local Binary Pattern Method for Facial Expression Detection
Feb 04, 2014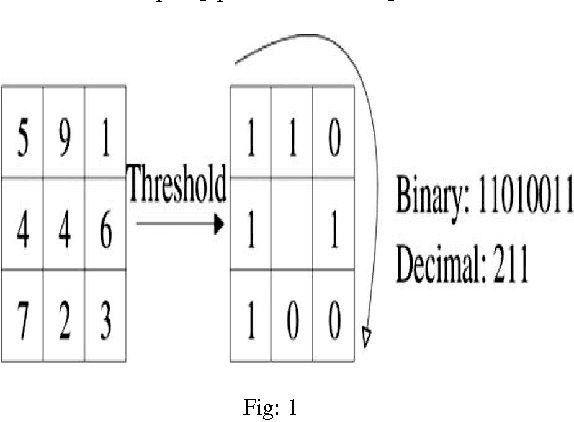
Face detection is a basic task for expression recognition. The reliability of face detection & face recognition approach has a major role on the performance and usability of the entire system. There are several ways to undergo face detection & recognition. We can use Image Processing Operations, various classifiers, filters or virtual machines for the former. Various strategies are being available for Facial Expression Detection. The field of facial expression detection can have various applications along with its importance & can be interacted between human being & computer. Many few options are available to identify a face in an image in accurate & efficient manner. Local Binary Pattern (LBP) based texture algorithms have gained popularity in these years. LBP is an effective approach to have facial expression recognition & is a feature-based approach.
* 3 pages, 2 images, International Journal of Computer Trends and Technology (IJCTT)
2^B3^C: 2 Box 3 Crop of Facial Image for Gender Classification with Convolutional Networks
Mar 05, 2018
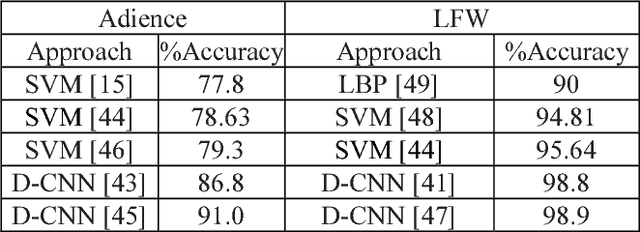
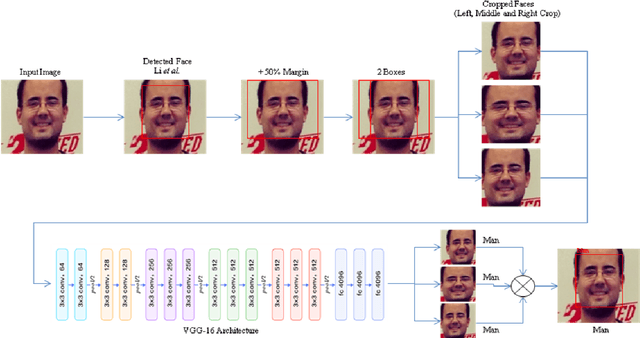
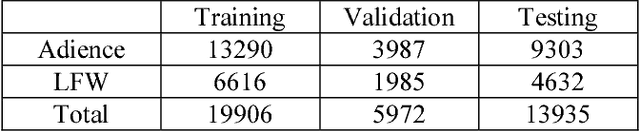
In this paper, we tackle the classification of gender in facial images with deep learning. Our convolutional neural networks (CNN) use the VGG-16 architecture [1] and are pretrained on ImageNet for image classification. Our proposed method (2^B3^C) first detects the face in the facial image, increases the margin of a detected face by 50%, cropping the face with two boxes three crop schemes (Left, Middle, and Right crop) and extracts the CNN predictions on the cropped schemes. The CNNs of our method is fine-tuned on the Adience and LFW with gender annotations. We show the effectiveness of our method by achieving 90.8% classification on Adience and achieving competitive 95.3% classification accuracy on LFW dataset. In addition, to check the true ability of our method, our gender classification system has a frame rate of 7-10 fps (frames per seconds) on a GPU considering real-time scenarios.
Towards Realistic Visual Dubbing with Heterogeneous Sources
Jan 17, 2022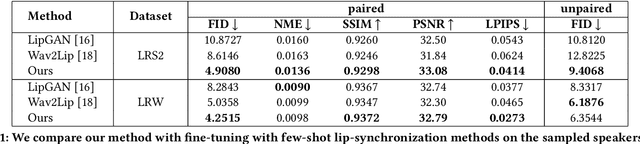
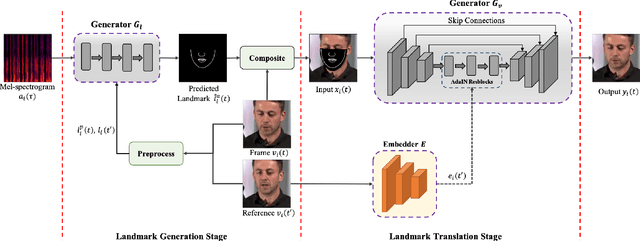
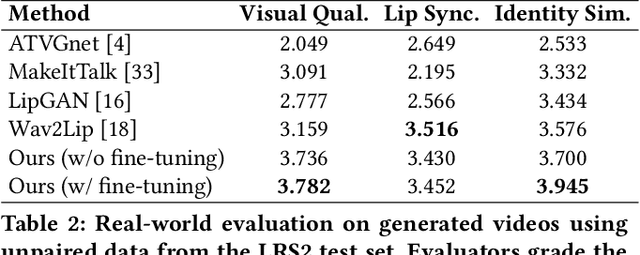
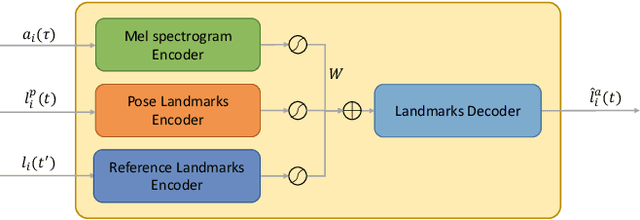
The task of few-shot visual dubbing focuses on synchronizing the lip movements with arbitrary speech input for any talking head video. Albeit moderate improvements in current approaches, they commonly require high-quality homologous data sources of videos and audios, thus causing the failure to leverage heterogeneous data sufficiently. In practice, it may be intractable to collect the perfect homologous data in some cases, for example, audio-corrupted or picture-blurry videos. To explore this kind of data and support high-fidelity few-shot visual dubbing, in this paper, we novelly propose a simple yet efficient two-stage framework with a higher flexibility of mining heterogeneous data. Specifically, our two-stage paradigm employs facial landmarks as intermediate prior of latent representations and disentangles the lip movements prediction from the core task of realistic talking head generation. By this means, our method makes it possible to independently utilize the training corpus for two-stage sub-networks using more available heterogeneous data easily acquired. Besides, thanks to the disentanglement, our framework allows a further fine-tuning for a given talking head, thereby leading to better speaker-identity preserving in the final synthesized results. Moreover, the proposed method can also transfer appearance features from others to the target speaker. Extensive experimental results demonstrate the superiority of our proposed method in generating highly realistic videos synchronized with the speech over the state-of-the-art.
Towards Measuring Fairness in Speech Recognition: Casual Conversations Dataset Transcriptions
Nov 18, 2021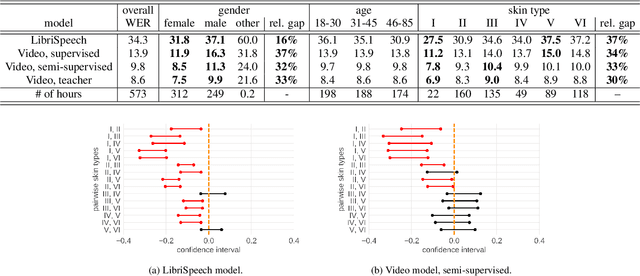

It is well known that many machine learning systems demonstrate bias towards specific groups of individuals. This problem has been studied extensively in the Facial Recognition area, but much less so in Automatic Speech Recognition (ASR). This paper presents initial Speech Recognition results on "Casual Conversations" -- a publicly released 846 hour corpus designed to help researchers evaluate their computer vision and audio models for accuracy across a diverse set of metadata, including age, gender, and skin tone. The entire corpus has been manually transcribed, allowing for detailed ASR evaluations across these metadata. Multiple ASR models are evaluated, including models trained on LibriSpeech, 14,000 hour transcribed, and over 2 million hour untranscribed social media videos. Significant differences in word error rate across gender and skin tone are observed at times for all models. We are releasing human transcripts from the Casual Conversations dataset to encourage the community to develop a variety of techniques to reduce these statistical biases.
Spontaneous Subtle Expression Detection and Recognition based on Facial Strain
Jun 09, 2016
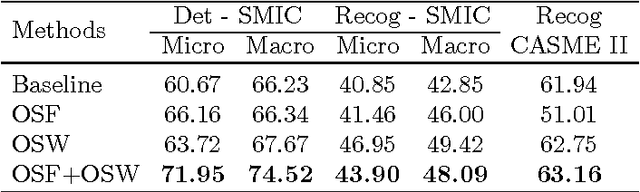
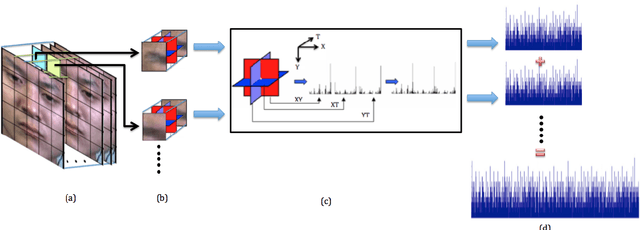
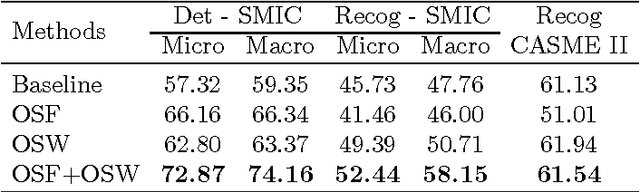
Optical strain is an extension of optical flow that is capable of quantifying subtle changes on faces and representing the minute facial motion intensities at the pixel level. This is computationally essential for the relatively new field of spontaneous micro-expression, where subtle expressions can be technically challenging to pinpoint. In this paper, we present a novel method for detecting and recognizing micro-expressions by utilizing facial optical strain magnitudes to construct optical strain features and optical strain weighted features. The two sets of features are then concatenated to form the resultant feature histogram. Experiments were performed on the CASME II and SMIC databases. We demonstrate on both databases, the usefulness of optical strain information and more importantly, that our best approaches are able to outperform the original baseline results for both detection and recognition tasks. A comparison of the proposed method with other existing spatio-temporal feature extraction approaches is also presented.
* 21 pages (including references), single column format, accepted to Signal Processing: Image Communication journal
Pooling Facial Segments to Face: The Shallow and Deep Ends
Jan 29, 2017
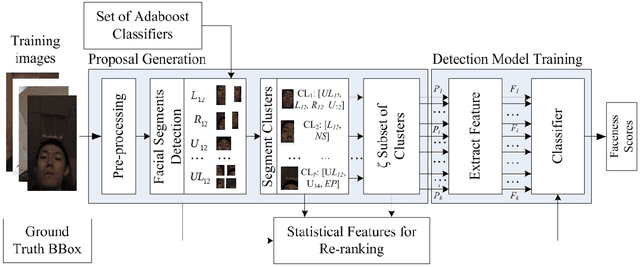
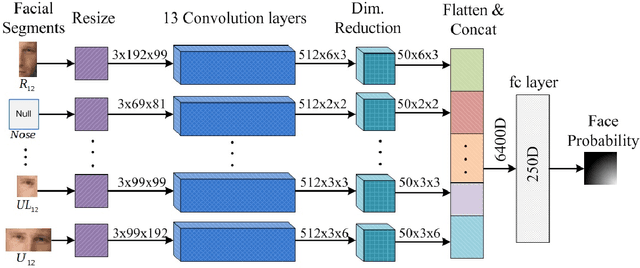

Generic face detection algorithms do not perform very well in the mobile domain due to significant presence of occluded and partially visible faces. One promising technique to handle the challenge of partial faces is to design face detectors based on facial segments. In this paper two such face detectors namely, SegFace and DeepSegFace, are proposed that detect the presence of a face given arbitrary combinations of certain face segments. Both methods use proposals from facial segments as input that are found using weak boosted classifiers. SegFace is a shallow and fast algorithm using traditional features, tailored for situations where real time constraints must be satisfied. On the other hand, DeepSegFace is a more powerful algorithm based on a deep convolutional neutral network (DCNN) architecture. DeepSegFace offers certain advantages over other DCNN-based face detectors as it requires relatively little amount of data to train by utilizing a novel data augmentation scheme and is very robust to occlusion by design. Extensive experiments show the superiority of the proposed methods, specially DeepSegFace, over other state-of-the-art face detectors in terms of precision-recall and ROC curve on two mobile face datasets.
* 8 pages, 7 figures, 3 tables, accepted for publication in FG2017
EmotioNet Challenge: Recognition of facial expressions of emotion in the wild
Mar 03, 2017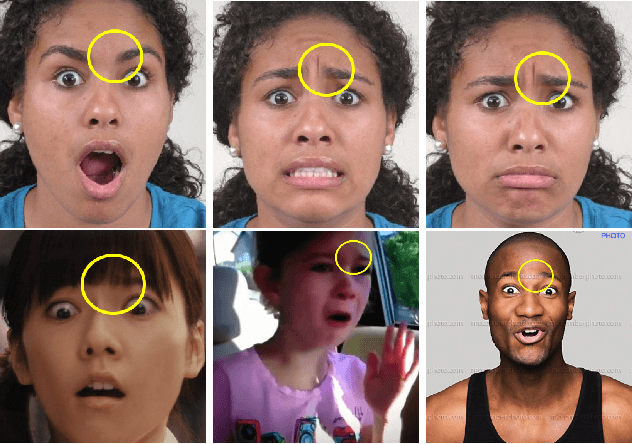
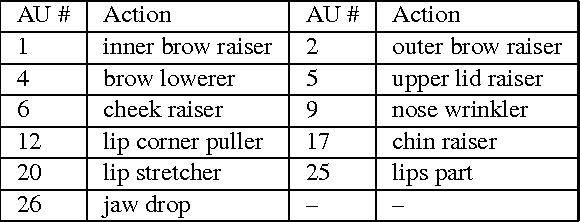
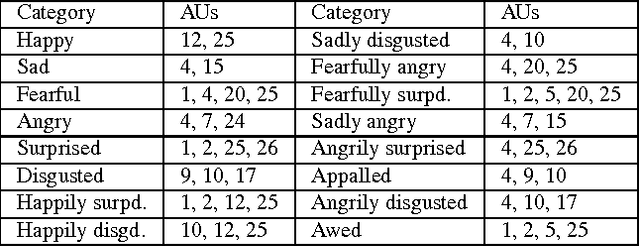

This paper details the methodology and results of the EmotioNet challenge. This challenge is the first to test the ability of computer vision algorithms in the automatic analysis of a large number of images of facial expressions of emotion in the wild. The challenge was divided into two tracks. The first track tested the ability of current computer vision algorithms in the automatic detection of action units (AUs). Specifically, we tested the detection of 11 AUs. The second track tested the algorithms' ability to recognize emotion categories in images of facial expressions. Specifically, we tested the recognition of 16 basic and compound emotion categories. The results of the challenge suggest that current computer vision and machine learning algorithms are unable to reliably solve these two tasks. The limitations of current algorithms are more apparent when trying to recognize emotion. We also show that current algorithms are not affected by mild resolution changes, small occluders, gender or age, but that 3D pose is a major limiting factor on performance. We provide an in-depth discussion of the points that need special attention moving forward.
3rd Place Solution for Short-video Face Parsing Challenge
Jun 14, 2021
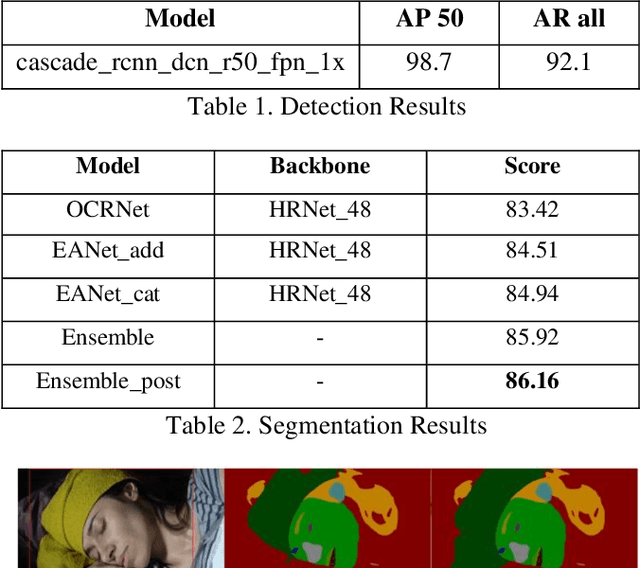
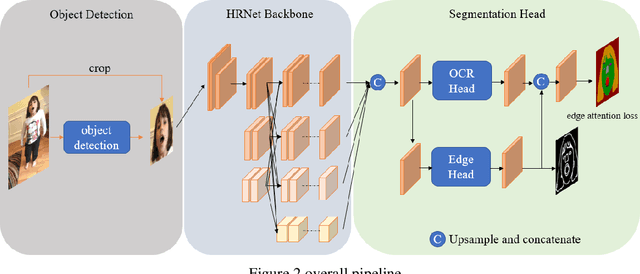
Short videos have many applications on fashion trends, hot spots, street interviews, public education, and creative advertising. We propose an Edge-Aware Network(EANet) that uses edge information to refine the segmentation edge. And experiments show our proposed EANet boots up the facial parsing results. We also use post-process like grab cut to refine and merge the parsing results.