 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
A Fusion-based Gender Recognition Method Using Facial Images
Nov 17, 2017
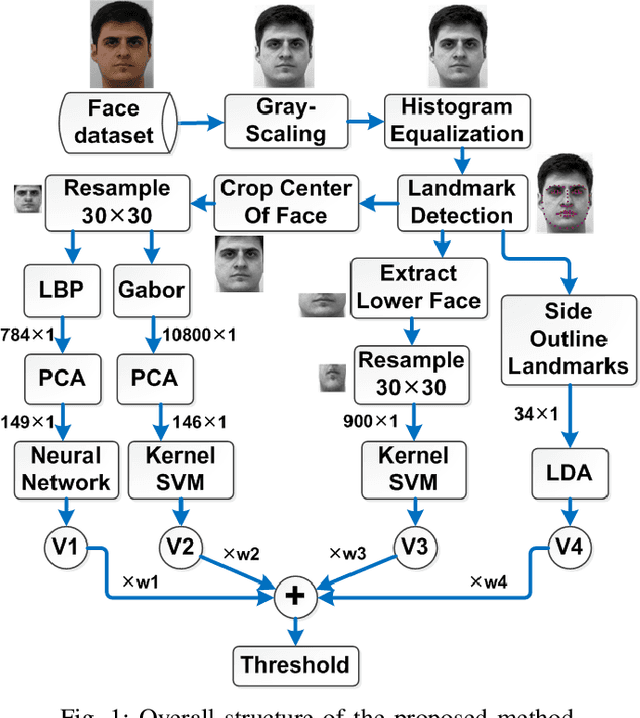


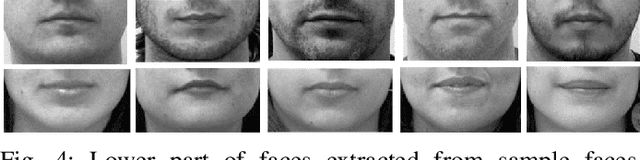
This paper proposes a fusion-based gender recognition method which uses facial images as input. Firstly, this paper utilizes pre-processing and a landmark detection method in order to find the important landmarks of faces. Thereafter, four different frameworks are proposed which are inspired by state-of-the-art gender recognition systems. The first framework extracts features using Local Binary Pattern (LBP) and Principal Component Analysis (PCA) and uses back propagation neural network. The second framework uses Gabor filters, PCA, and kernel Support Vector Machine (SVM). The third framework uses lower part of faces as input and classifies them using kernel SVM. The fourth framework uses Linear Discriminant Analysis (LDA) in order to classify the side outline landmarks of faces. Finally, the four decisions of frameworks are fused using weighted voting. This paper takes advantage of both texture and geometrical information, the two dominant types of information in facial gender recognition. Experimental results show the power and effectiveness of the proposed method. This method obtains recognition rate of 94% for neutral faces of FEI face dataset, which is equal to state-of-the-art rate for this dataset.
Reliable Detection of Doppelgängers based on Deep Face Representations
Jan 21, 2022
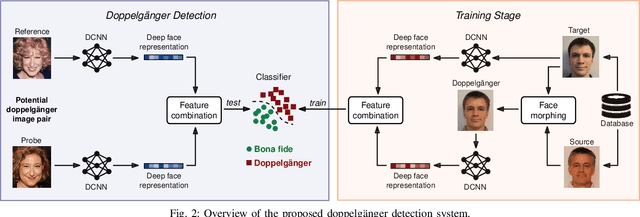


Doppelg\"angers (or lookalikes) usually yield an increased probability of false matches in a facial recognition system, as opposed to random face image pairs selected for non-mated comparison trials. In this work, we assess the impact of doppelg\"angers on the HDA Doppelg\"anger and Disguised Faces in The Wild databases using a state-of-the-art face recognition system. It is found that doppelg\"anger image pairs yield very high similarity scores resulting in a significant increase of false match rates. Further, we propose a doppelg\"anger detection method which distinguishes doppelg\"angers from mated comparison trials by analysing differences in deep representations obtained from face image pairs. The proposed detection system employs a machine learning-based classifier, which is trained with generated doppelg\"anger image pairs utilising face morphing techniques. Experimental evaluations conducted on the HDA Doppelg\"anger and Look-Alike Face databases reveal a detection equal error rate of approximately 2.7% for the task of separating mated authentication attempts from doppelg\"angers.
Emotion recognition techniques with rule based and machine learning approaches
Feb 28, 2021
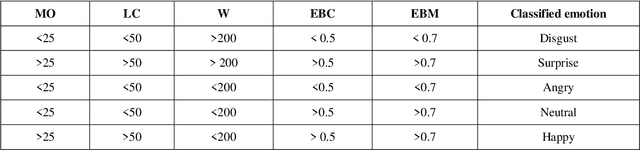
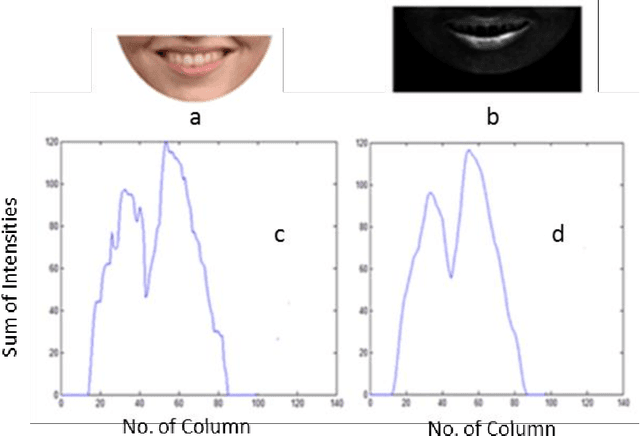
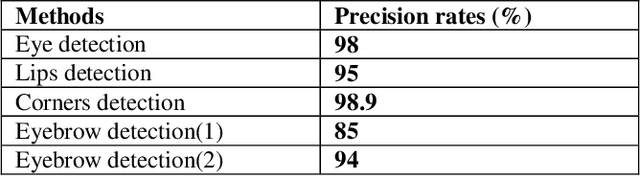
Emotion recognition using digital image processing is a multifarious task because facial emotions depend on warped facial features as well as on gender, age, and culture. Furthermore, there are several factors such as varied illumination and intricate settings that increase complexity in facial emotion recognition. In this paper, we used four salient facial features, Eyebrows, Mouth opening, Mouth corners, and Forehead wrinkles to identifying emotions from normal, occluded and partially-occluded images. We have employed rule-based approach and developed new methods to extract aforementioned facial features similar to local bit patterns using novel techniques. We propose new methods to detect eye location, eyebrow contraction, and mouth corners. For eye detection, the proposed methods are Enhancement of Cr Red (ECrR) and Suppression of Cr Blue (SCrB) which results in 98% accuracy. Additionally, for eyebrow contraction detection, we propose two techniques (1) Morphological Gradient Image Intensity (MGII) and (2) Degree of Curvature Line (DCL). Additionally, we present a new method for mouth corners detection. For classification purpose, we use an individual classifier, majority voting (MV) and weighted majority voting (WMV) methods which mimic Human Emotions Sensitivity (HES). These methods are straightforward to implement, improve the accuracy of results, and work best for emotion recognition using partially occluded images. It is ascertained from the results that our method outperforms previous approaches. Overall accuracy rates are around 94%. The processing time on one image using processor core i5 is ~0.12 sec.
Sejong Face Database: A Multi-Modal Disguise Face Database
Jun 14, 2021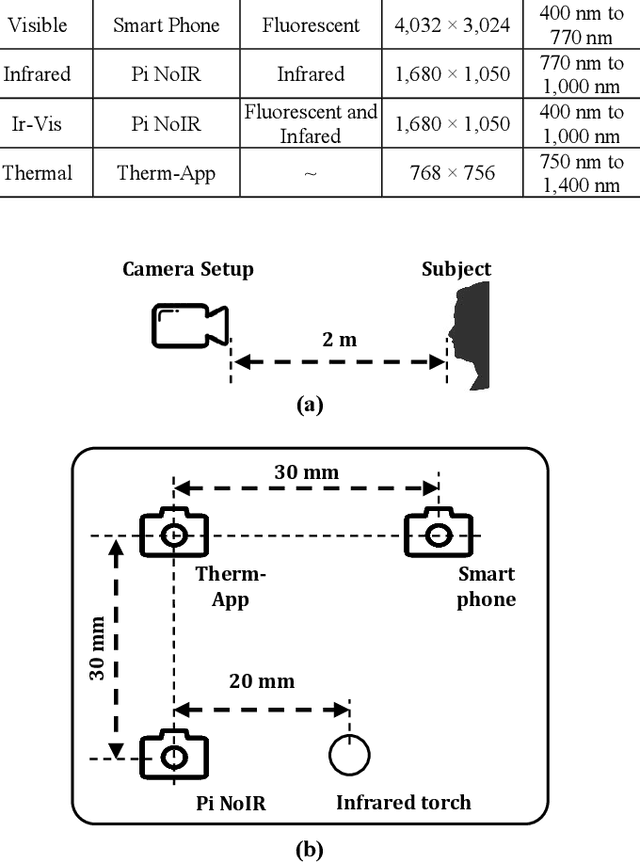
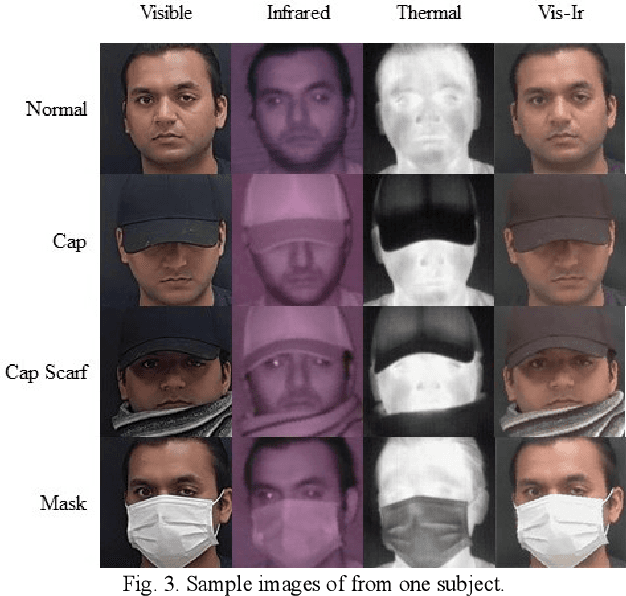
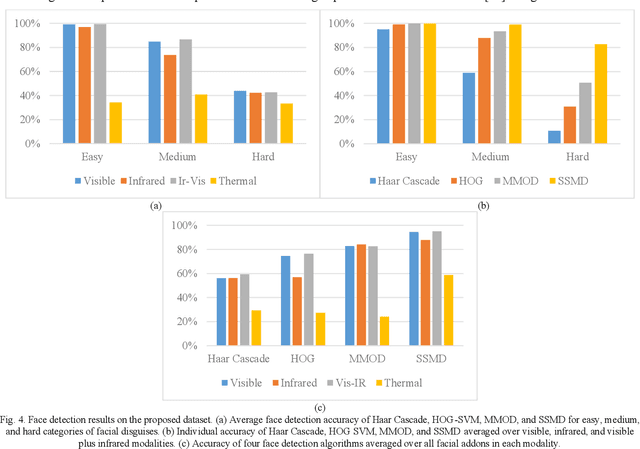

Commercial application of facial recognition demands robustness to a variety of challenges such as illumination, occlusion, spoofing, disguise, etc. Disguised face recognition is one of the emerging issues for access control systems, such as security checkpoints at the borders. However, the lack of availability of face databases with a variety of disguise addons limits the development of academic research in the area. In this paper, we present a multimodal disguised face dataset to facilitate the disguised face recognition research. The presented database contains 8 facial add-ons and 7 additional combinations of these add-ons to create a variety of disguised face images. Each facial image is captured in visible, visible plus infrared, infrared, and thermal spectra. Specifically, the database contains 100 subjects divided into subset-A (30 subjects, 1 image per modality) and subset-B (70 subjects, 5 plus images per modality). We also present baseline face detection results performed on the proposed database to provide reference results and compare the performance in different modalities. Qualitative and quantitative analysis is performed to evaluate the challenging nature of disguise addons. The dataset will be publicly available with the acceptance of the research article. The database is available at: https://github.com/usmancheema89/SejongFaceDatabase.
* Database Access Link: https://github.com/usmancheema89/SejongFaceDatabase
Learning Graph Representation of Person-specific Cognitive Processes from Audio-visual Behaviours for Automatic Personality Recognition
Oct 27, 2021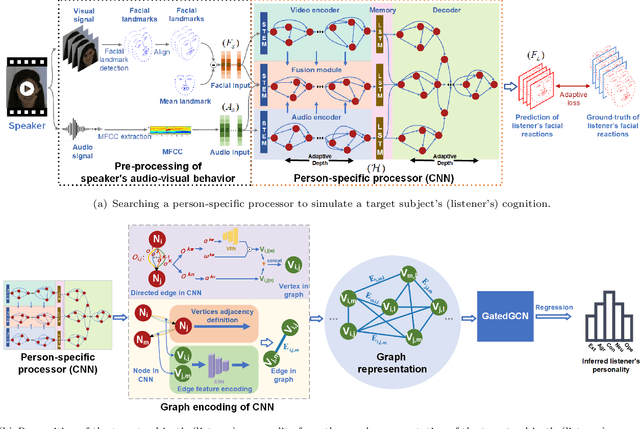
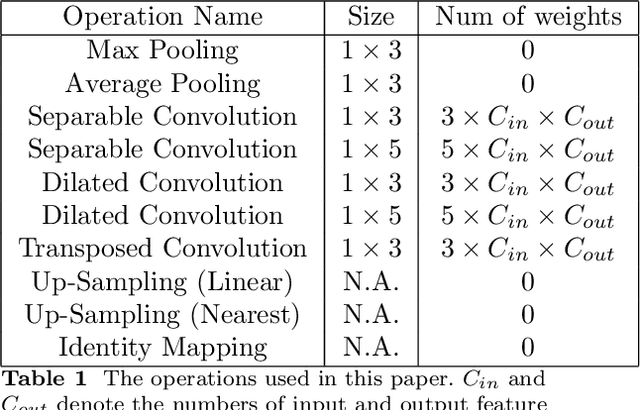
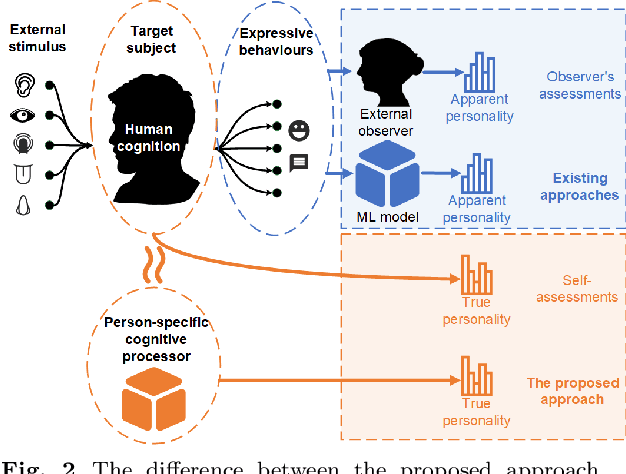
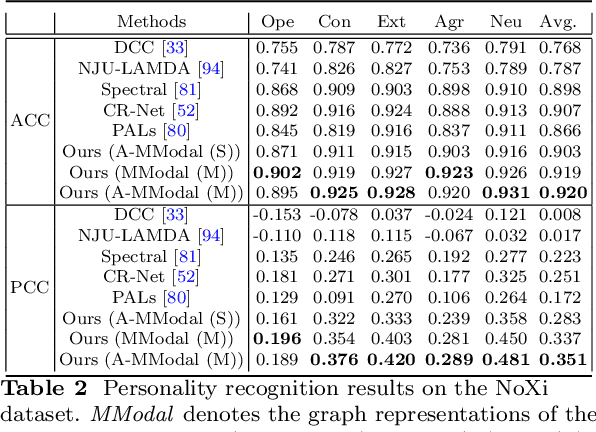
This approach builds on two following findings in cognitive science: (i) human cognition partially determines expressed behaviour and is directly linked to true personality traits; and (ii) in dyadic interactions individuals' nonverbal behaviours are influenced by their conversational partner behaviours. In this context, we hypothesise that during a dyadic interaction, a target subject's facial reactions are driven by two main factors, i.e. their internal (person-specific) cognitive process, and the externalised nonverbal behaviours of their conversational partner. Consequently, we propose to represent the target subjects (defined as the listener) person-specific cognition in the form of a person-specific CNN architecture that has unique architectural parameters and depth, which takes audio-visual non-verbal cues displayed by the conversational partner (defined as the speaker) as input, and is able to reproduce the target subject's facial reactions. Each person-specific CNN is explored by the Neural Architecture Search (NAS) and a novel adaptive loss function, which is then represented as a graph representation for recognising the target subject's true personality. Experimental results not only show that the produced graph representations are well associated with target subjects' personality traits in both human-human and human-machine interaction scenarios, and outperform the existing approaches with significant advantages, but also demonstrate that the proposed novel strategies such as adaptive loss, and the end-to-end vertices/edges feature learning, help the proposed approach in learning more reliable personality representations.
Self-Supervised Learning Framework for Remote Heart Rate Estimation Using Spatiotemporal Augmentation
Jul 16, 2021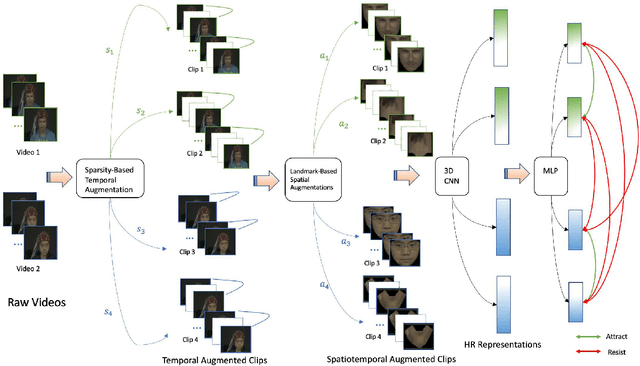
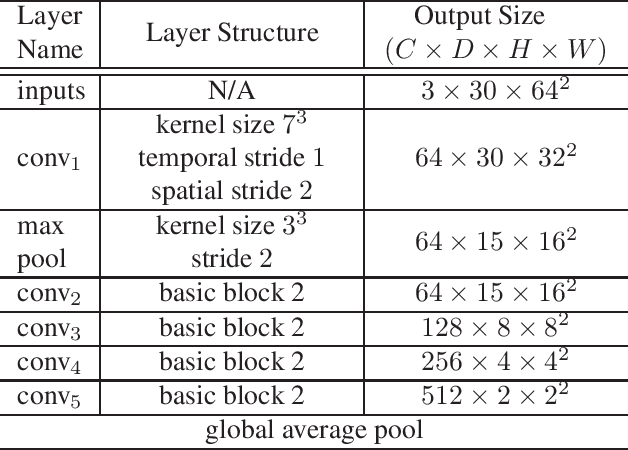
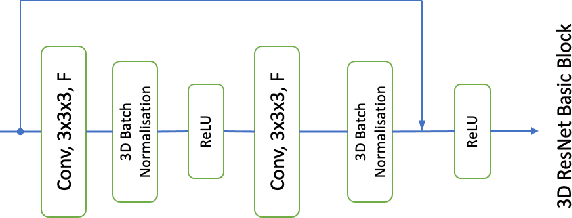
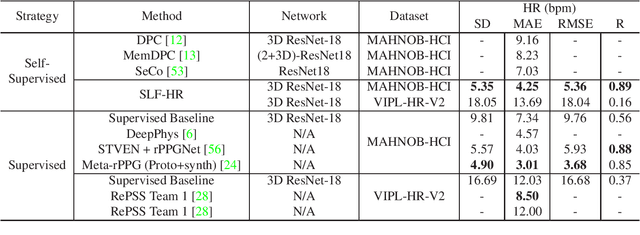
Recent supervised deep learning methods have shown that heart rate can be measured remotely using facial videos. However, the performance of these supervised method are dependent on the availability of large-scale labelled data and they have been limited to 2D deep learning architectures that do not fully exploit the 3D spatiotemporal information. To solve this problem, we present a novel 3D self-supervised spatiotemporal learning framework for remote HR estimation on facial videos. Concretely, we propose a landmark-based spatial augmentation which splits the face into several informative parts based on the Shafer's dichromatic reflection model and a novel sparsity-based temporal augmentation exploiting Nyquist-Shannon sampling theorem to enhance the signal modelling ability. We evaluated our method on 3 public datasets and outperformed other self-supervised methods and achieved competitive accuracy with the state-of-the-art supervised methods.
Supervision-by-Registration: An Unsupervised Approach to Improve the Precision of Facial Landmark Detectors
Jul 04, 2018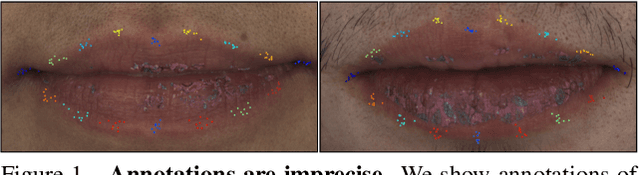
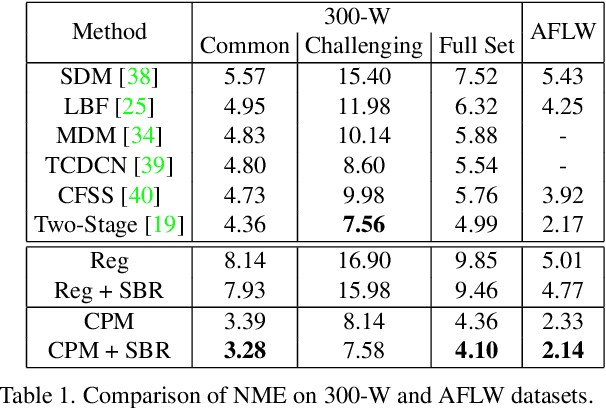
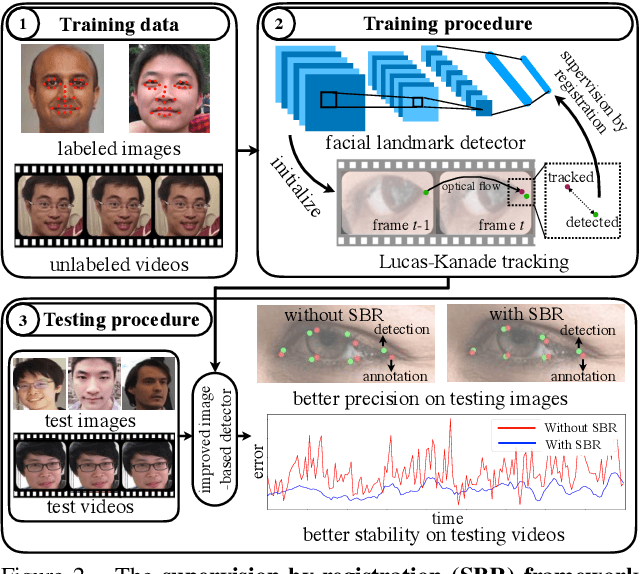
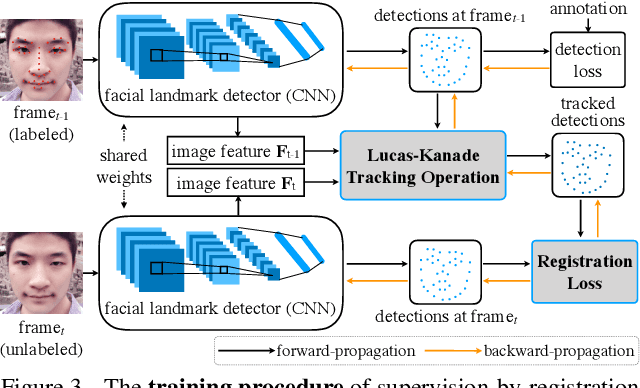
In this paper, we present supervision-by-registration, an unsupervised approach to improve the precision of facial landmark detectors on both images and video. Our key observation is that the detections of the same landmark in adjacent frames should be coherent with registration, i.e., optical flow. Interestingly, the coherency of optical flow is a source of supervision that does not require manual labeling, and can be leveraged during detector training. For example, we can enforce in the training loss function that a detected landmark at frame$_{t-1}$ followed by optical flow tracking from frame$_{t-1}$ to frame$_t$ should coincide with the location of the detection at frame$_t$. Essentially, supervision-by-registration augments the training loss function with a registration loss, thus training the detector to have output that is not only close to the annotations in labeled images, but also consistent with registration on large amounts of unlabeled videos. End-to-end training with the registration loss is made possible by a differentiable Lucas-Kanade operation, which computes optical flow registration in the forward pass, and back-propagates gradients that encourage temporal coherency in the detector. The output of our method is a more precise image-based facial landmark detector, which can be applied to single images or video. With supervision-by-registration, we demonstrate (1) improvements in facial landmark detection on both images (300W, ALFW) and video (300VW, Youtube-Celebrities), and (2) significant reduction of jittering in video detections.
KappaFace: Adaptive Additive Angular Margin Loss for Deep Face Recognition
Jan 19, 2022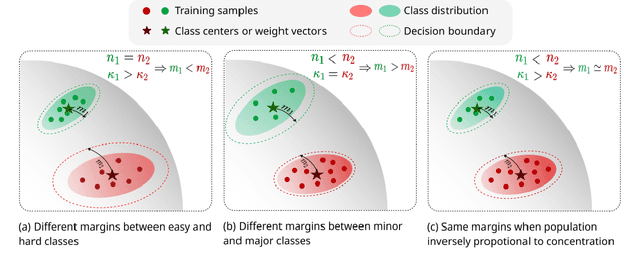
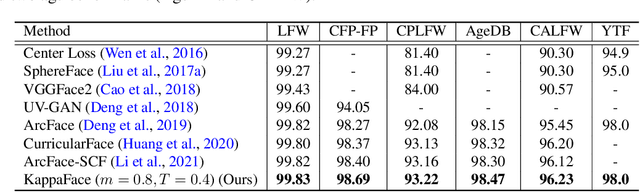
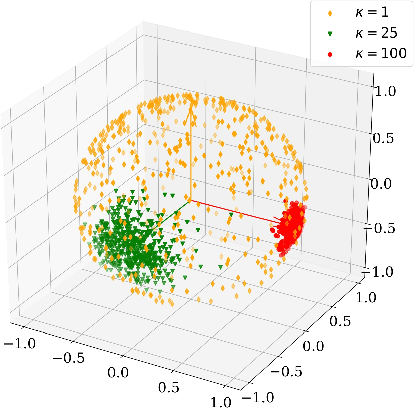
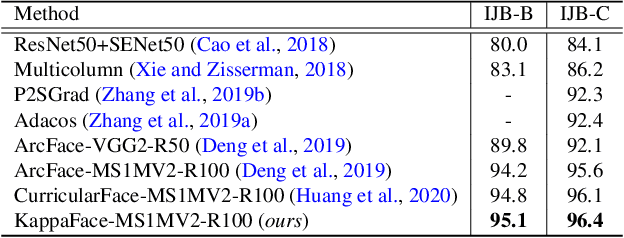
Feature learning is a widely used method employed for large-scale face recognition. Recently, large-margin softmax loss methods have demonstrated significant enhancements on deep face recognition. These methods propose fixed positive margins in order to enforce intra-class compactness and inter-class diversity. However, the majority of the proposed methods do not consider the class imbalance issue, which is a major challenge in practice for developing deep face recognition models. We hypothesize that it significantly affects the generalization ability of the deep face models. Inspired by this observation, we introduce a novel adaptive strategy, called KappaFace, to modulate the relative importance based on class difficultness and imbalance. With the support of the von Mises-Fisher distribution, our proposed KappaFace loss can intensify the margin's magnitude for hard learning or low concentration classes while relaxing it for counter classes. Experiments conducted on popular facial benchmarks demonstrate that our proposed method achieves superior performance to the state-of-the-art.
Detection of GAN-synthesized street videos
Sep 10, 2021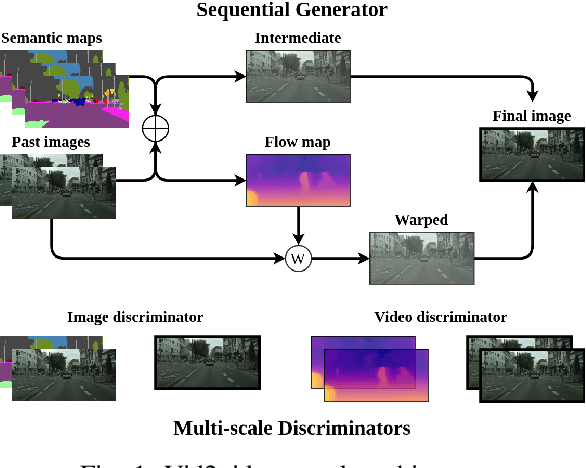

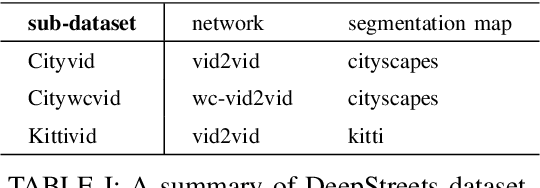
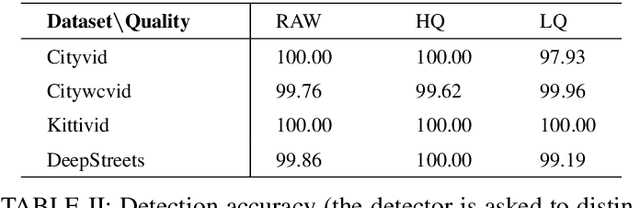
Research on the detection of AI-generated videos has focused almost exclusively on face videos, usually referred to as deepfakes. Manipulations like face swapping, face reenactment and expression manipulation have been the subject of an intense research with the development of a number of efficient tools to distinguish artificial videos from genuine ones. Much less attention has been paid to the detection of artificial non-facial videos. Yet, new tools for the generation of such kind of videos are being developed at a fast pace and will soon reach the quality level of deepfake videos. The goal of this paper is to investigate the detectability of a new kind of AI-generated videos framing driving street sequences (here referred to as DeepStreets videos), which, by their nature, can not be analysed with the same tools used for facial deepfakes. Specifically, we present a simple frame-based detector, achieving very good performance on state-of-the-art DeepStreets videos generated by the Vid2vid architecture. Noticeably, the detector retains very good performance on compressed videos, even when the compression level used during training does not match that used for the test videos.
Web-based visualisation of head pose and facial expressions changes: monitoring human activity using depth data
Mar 16, 2017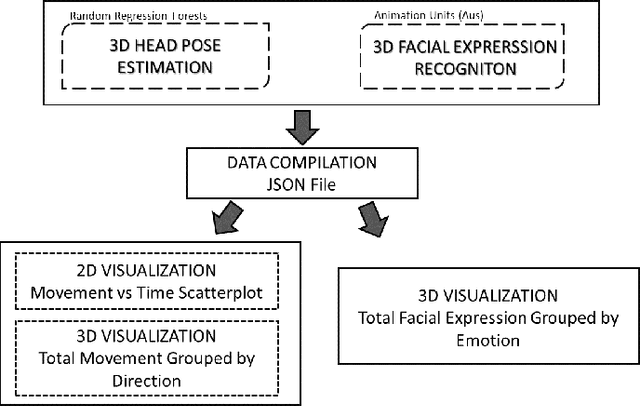


Despite significant recent advances in the field of head pose estimation and facial expression recognition, raising the cognitive level when analysing human activity presents serious challenges to current concepts. Motivated by the need of generating comprehensible visual representations from different sets of data, we introduce a system capable of monitoring human activity through head pose and facial expression changes, utilising an affordable 3D sensing technology (Microsoft Kinect sensor). An approach build on discriminative random regression forests was selected in order to rapidly and accurately estimate head pose changes in unconstrained environment. In order to complete the secondary process of recognising four universal dominant facial expressions (happiness, anger, sadness and surprise), emotion recognition via facial expressions (ERFE) was adopted. After that, a lightweight data exchange format (JavaScript Object Notation-JSON) is employed, in order to manipulate the data extracted from the two aforementioned settings. Such mechanism can yield a platform for objective and effortless assessment of human activity within the context of serious gaming and human-computer interaction.