 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
ExpNet: Landmark-Free, Deep, 3D Facial Expressions
Feb 02, 2018

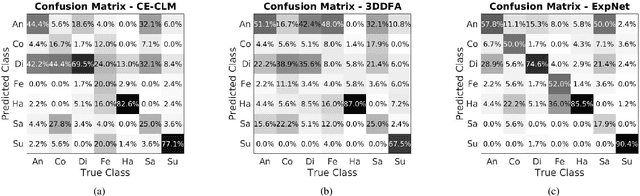
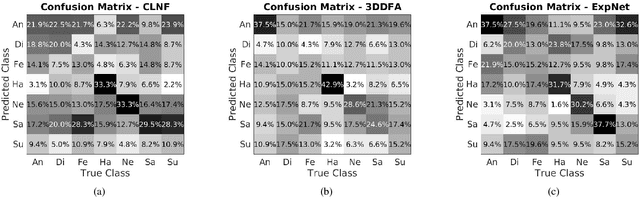
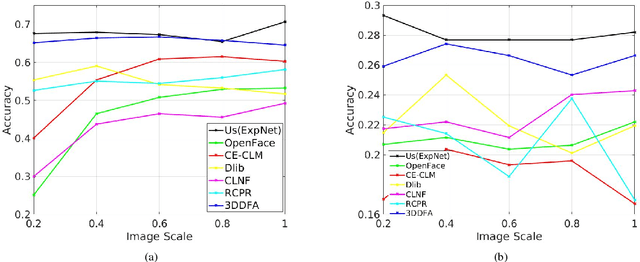
We describe a deep learning based method for estimating 3D facial expression coefficients. Unlike previous work, our process does not relay on facial landmark detection methods as a proxy step. Recent methods have shown that a CNN can be trained to regress accurate and discriminative 3D morphable model (3DMM) representations, directly from image intensities. By foregoing facial landmark detection, these methods were able to estimate shapes for occluded faces appearing in unprecedented in-the-wild viewing conditions. We build on those methods by showing that facial expressions can also be estimated by a robust, deep, landmark-free approach. Our ExpNet CNN is applied directly to the intensities of a face image and regresses a 29D vector of 3D expression coefficients. We propose a unique method for collecting data to train this network, leveraging on the robustness of deep networks to training label noise. We further offer a novel means of evaluating the accuracy of estimated expression coefficients: by measuring how well they capture facial emotions on the CK+ and EmotiW-17 emotion recognition benchmarks. We show that our ExpNet produces expression coefficients which better discriminate between facial emotions than those obtained using state of the art, facial landmark detection techniques. Moreover, this advantage grows as image scales drop, demonstrating that our ExpNet is more robust to scale changes than landmark detection methods. Finally, at the same level of accuracy, our ExpNet is orders of magnitude faster than its alternatives.
Hand-Assisted Expression Recognition Method from Synthetic Images at the Fourth ABAW Challenge
Jul 20, 2022
Learning from synthetic images plays an important role in facial expression recognition task due to the difficulties of labeling the real images, and it is challenging because of the gap between the synthetic images and real images. The fourth Affective Behavior Analysis in-the-wild Competition raises the challenge and provides the synthetic images generated from Aff-Wild2 dataset. In this paper, we propose a hand-assisted expression recognition method to reduce the gap between the synthetic data and real data. Our method consists of two parts: expression recognition module and hand prediction module. Expression recognition module extracts expression information and hand prediction module predicts whether the image contains hands. Decision mode is used to combine the results of two modules, and post-pruning is used to improve the result. F1 score is used to verify the effectiveness of our method.
Facial Synthesis from Visual Attributes via Sketch using Multi-Scale Generators
Dec 17, 2019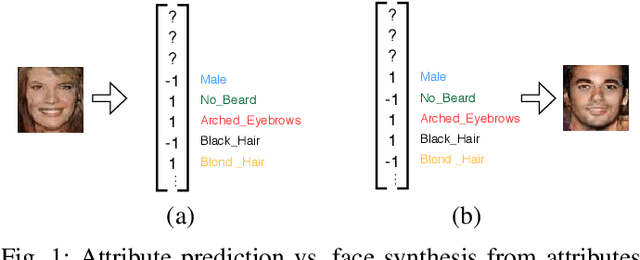
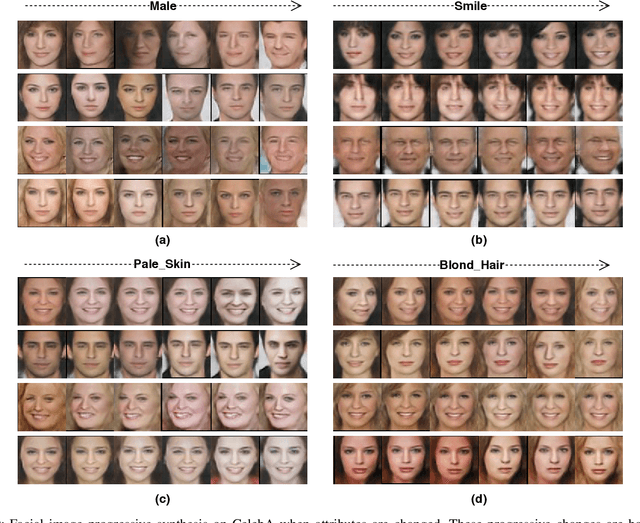

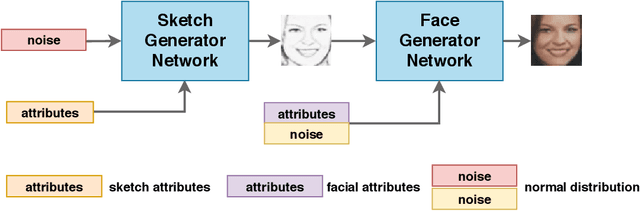
Automatic synthesis of faces from visual attributes is an important problem in computer vision and has wide applications in law enforcement and entertainment. With the advent of deep generative convolutional neural networks (CNNs), attempts have been made to synthesize face images from attributes and text descriptions. In this paper, we take a different approach, where we formulate the original problem as a stage-wise learning problem. We first synthesize the facial sketch corresponding to the visual attributes and then we generate the face image based on the synthesized sketch. The proposed framework, is based on a combination of two different Generative Adversarial Networks (GANs) - (1) a sketch generator network which synthesizes realistic sketch from the input attributes, and (2) a face generator network which synthesizes facial images from the synthesized sketch images with the help of facial attributes. Extensive experiments and comparison with recent methods are performed to verify the effectiveness of the proposed attribute-based two-stage face synthesis method.
Photorealistic Facial Synthesis in the Dimensional Affect Space
Nov 11, 2018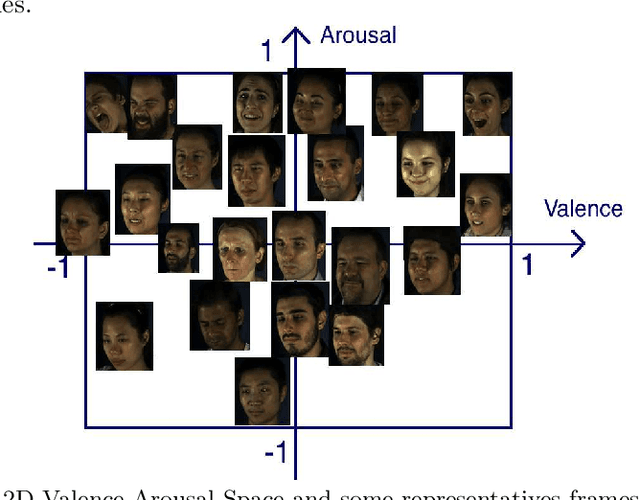
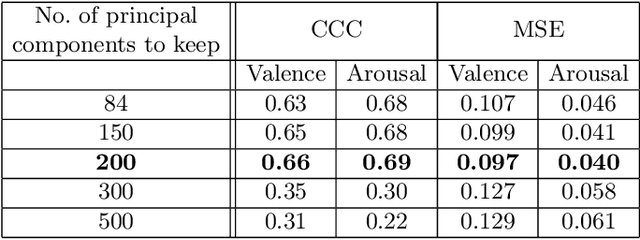
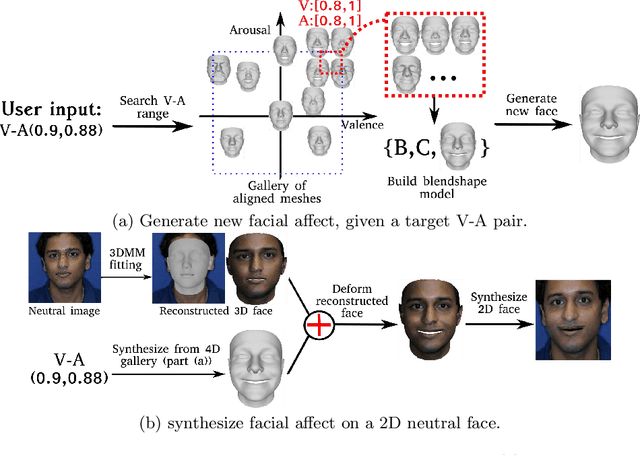

This paper presents a novel approach for synthesizing facial affect, which is based on our annotating 600,000 frames of the 4DFAB database in terms of valence and arousal. The input of this approach is a pair of these emotional state descriptors and a neutral 2D image of a person to whom the corresponding affect will be synthesized. Given this target pair, a set of 3D facial meshes is selected, which is used to build a blendshape model and generate the new facial affect. To synthesize the affect on the 2D neutral image, 3DMM fitting is performed and the reconstructed face is deformed to generate the target facial expressions. Last, the new face is rendered into the original image. Both qualitative and quantitative experimental studies illustrate the generation of realistic images, when the neutral image is sampled from a variety of well known databases, such as the Aff-Wild, AFEW, Multi-PIE, AFEW-VA, BU-3DFE, Bosphorus.
Bridging Unpaired Facial Photos And Sketches By Line-drawings
Feb 03, 2021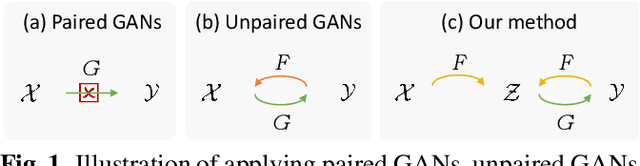
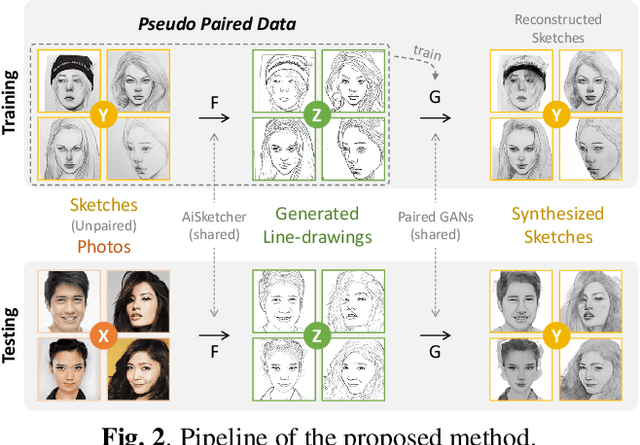
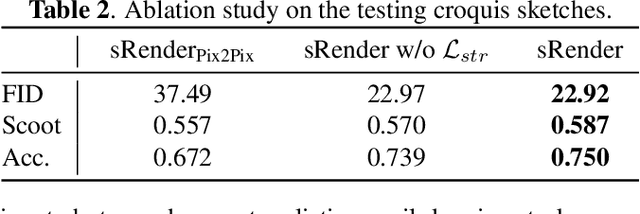
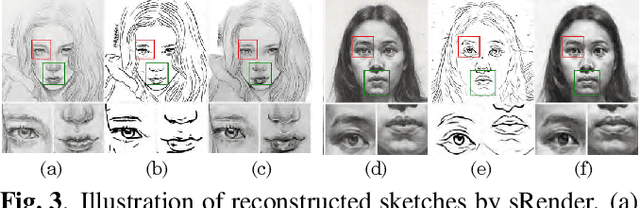
In this paper, we propose a novel method to learn face sketch synthesis models by using unpaired data. Our main idea is bridging the photo domain $\mathcal{X}$ and the sketch domain $Y$ by using the line-drawing domain $\mathcal{Z}$. Specially, we map both photos and sketches to line-drawings by using a neural style transfer method, i.e. $F: \mathcal{X}/\mathcal{Y} \mapsto \mathcal{Z}$. Consequently, we obtain \textit{pseudo paired data} $(\mathcal{Z}, \mathcal{Y})$, and can learn the mapping $G:\mathcal{Z} \mapsto \mathcal{Y}$ in a supervised learning manner. In the inference stage, given a facial photo, we can first transfer it to a line-drawing and then to a sketch by $G \circ F$. Additionally, we propose a novel stroke loss for generating different types of strokes. Our method, termed sRender, accords well with human artists' rendering process. Experimental results demonstrate that sRender can generate multi-style sketches, and significantly outperforms existing unpaired image-to-image translation methods.
Audio Input Generates Continuous Frames to Synthesize Facial Video Using Generative Adiversarial Networks
Jul 18, 2022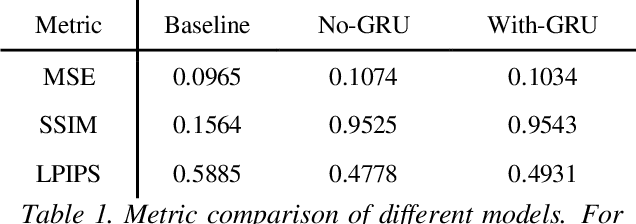
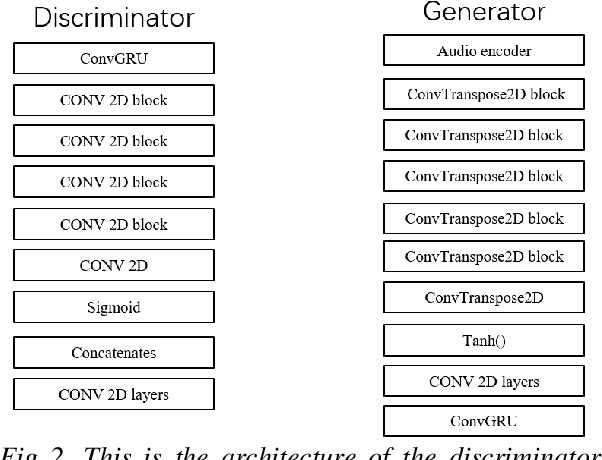

This paper presents a simple method for speech videos generation based on audio: given a piece of audio, we can generate a video of the target face speaking this audio. We propose Generative Adversarial Networks (GAN) with cut speech audio input as condition and use Convolutional Gate Recurrent Unit (GRU) in generator and discriminator. Our model is trained by exploiting the short audio and the frames in this duration. For training, we cut the audio and extract the face in the corresponding frames. We designed a simple encoder and compare the generated frames using GAN with and without GRU. We use GRU for temporally coherent frames and the results show that short audio can produce relatively realistic output results.
Semantic Relationships Guided Representation Learning for Facial Action Unit Recognition
Apr 22, 2019
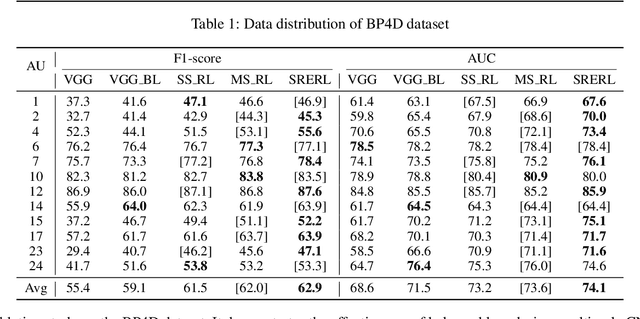
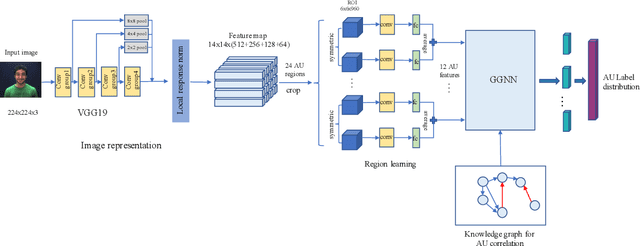
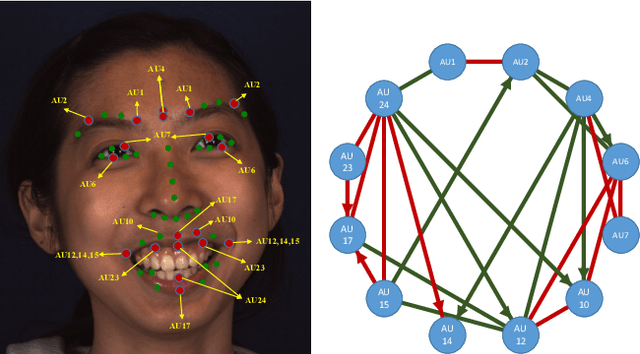
Facial action unit (AU) recognition is a crucial task for facial expressions analysis and has attracted extensive attention in the field of artificial intelligence and computer vision. Existing works have either focused on designing or learning complex regional feature representations, or delved into various types of AU relationship modeling. Albeit with varying degrees of progress, it is still arduous for existing methods to handle complex situations. In this paper, we investigate how to integrate the semantic relationship propagation between AUs in a deep neural network framework to enhance the feature representation of facial regions, and propose an AU semantic relationship embedded representation learning (SRERL) framework. Specifically, by analyzing the symbiosis and mutual exclusion of AUs in various facial expressions, we organize the facial AUs in the form of structured knowledge-graph and integrate a Gated Graph Neural Network (GGNN) in a multi-scale CNN framework to propagate node information through the graph for generating enhanced AU representation. As the learned feature involves both the appearance characteristics and the AU relationship reasoning, the proposed model is more robust and can cope with more challenging cases, e.g., illumination change and partial occlusion. Extensive experiments on the two public benchmarks demonstrate that our method outperforms the previous work and achieves state of the art performance.
Soft-ranking Label Encoding for Robust Facial Age Estimation
Jun 09, 2019
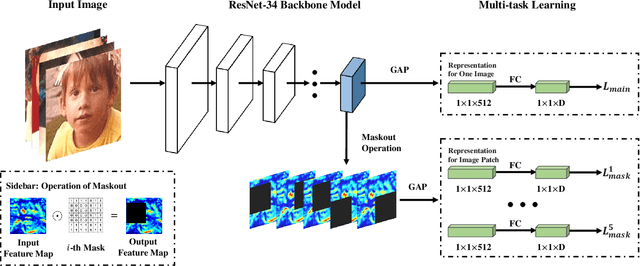
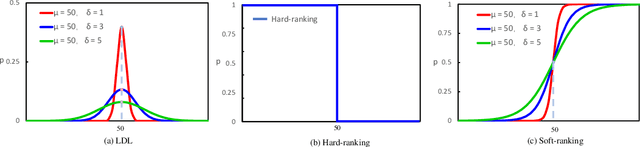
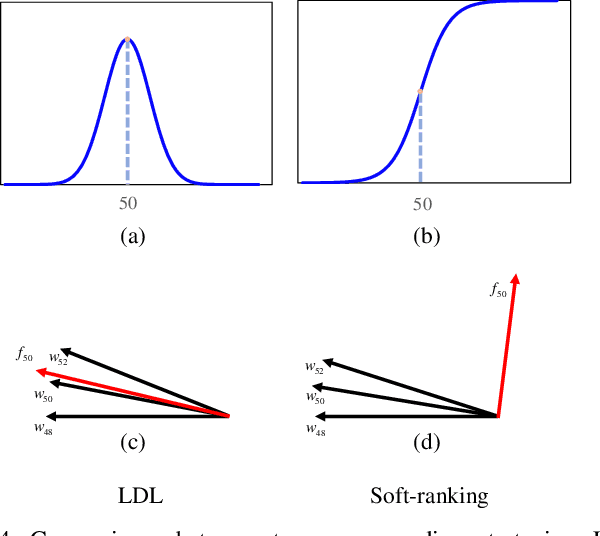
Automatic facial age estimation can be used in a wide range of real-world applications. However, this process is challenging due to the randomness and slowness of the aging process. Accordingly, in this paper, we propose a comprehensive framework aimed at overcoming the challenges associated with facial age estimation. First, we propose a novel age encoding method, referred to as 'Soft-ranking', which encodes two important properties of facial age, i.e., the ordinal property and the correlation between adjacent ages. Therefore, Soft-ranking provides a richer supervision signal for training deep models. Moreover, we also carefully analyze existing evaluation protocols for age estimation, finding that the overlap in identity between the training and testing sets affects the relative performance of different age encoding methods. Finally, since existing face databases for age estimation are generally small, deep models tend to suffer from an overfitting problem. To address this issue, we propose a novel regularization strategy to encourage deep models to learn more robust features from facial parts for age estimation purposes. Extensive experiments indicate that the proposed techniques improve the age estimation performance; moreover, we achieve state-of-the-art performance on the three most popular age databases, $i.e.$, Morph II, CLAP2015, and CLAP2016.
Does lossy image compression affect racial bias within face recognition?
Aug 16, 2022
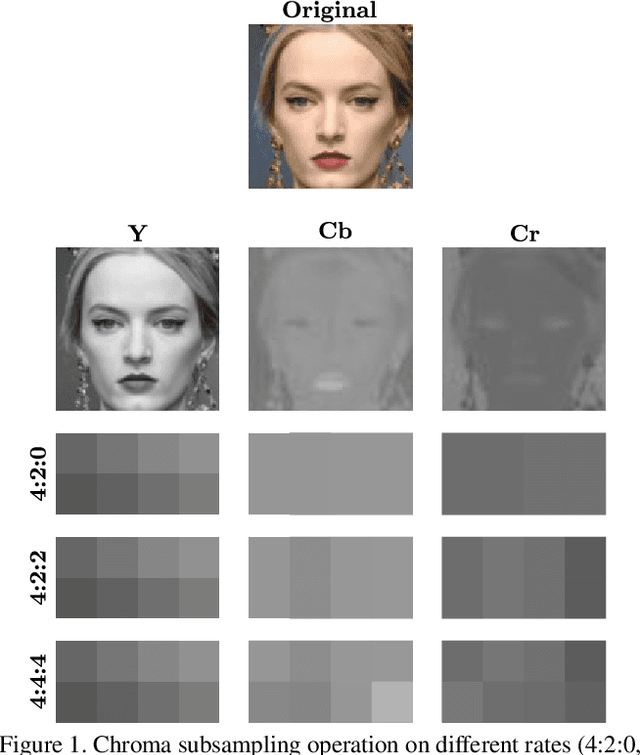
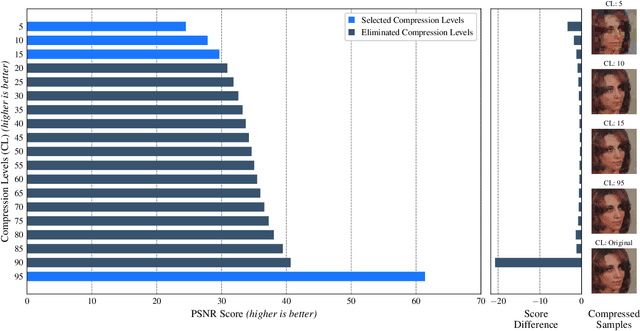
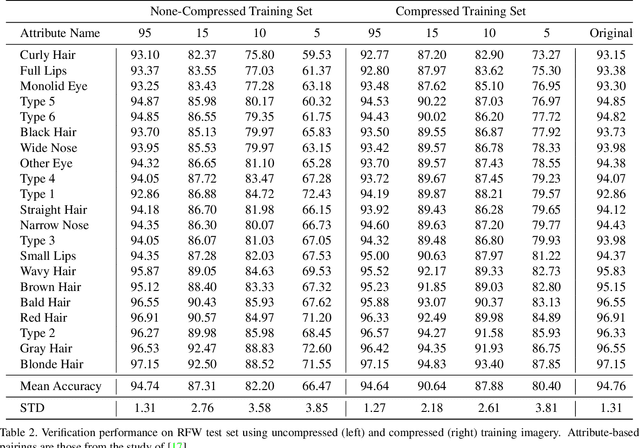
Yes - This study investigates the impact of commonplace lossy image compression on face recognition algorithms with regard to the racial characteristics of the subject. We adopt a recently proposed racial phenotype-based bias analysis methodology to measure the effect of varying levels of lossy compression across racial phenotype categories. Additionally, we determine the relationship between chroma-subsampling and race-related phenotypes for recognition performance. Prior work investigates the impact of lossy JPEG compression algorithm on contemporary face recognition performance. However, there is a gap in how this impact varies with different race-related inter-sectional groups and the cause of this impact. Via an extensive experimental setup, we demonstrate that common lossy image compression approaches have a more pronounced negative impact on facial recognition performance for specific racial phenotype categories such as darker skin tones (by up to 34.55\%). Furthermore, removing chroma-subsampling during compression improves the false matching rate (up to 15.95\%) across all phenotype categories affected by the compression, including darker skin tones, wide noses, big lips, and monolid eye categories. In addition, we outline the characteristics that may be attributable as the underlying cause of such phenomenon for lossy compression algorithms such as JPEG.