 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
MU-GAN: Facial Attribute Editing based on Multi-attention Mechanism
Sep 09, 2020

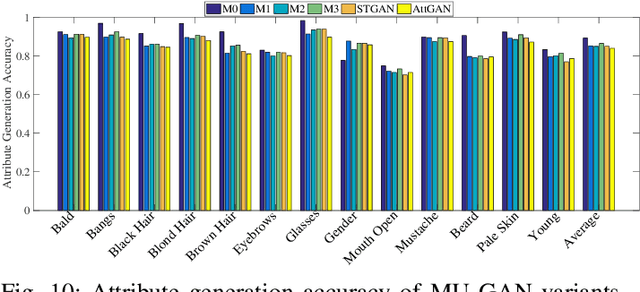
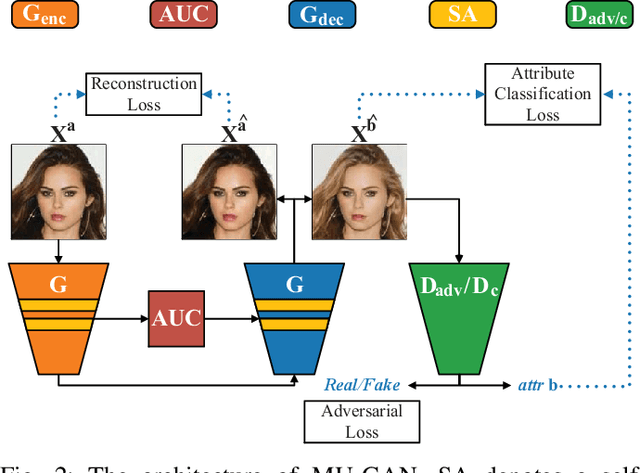
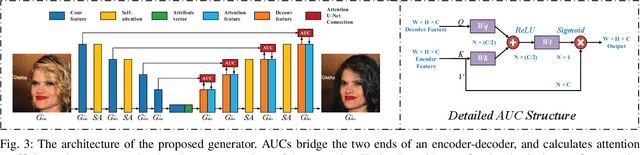
Facial attribute editing has mainly two objectives: 1) translating image from a source domain to a target one, and 2) only changing the facial regions related to a target attribute and preserving the attribute-excluding details. In this work, we propose a Multi-attention U-Net-based Generative Adversarial Network (MU-GAN). First, we replace a classic convolutional encoder-decoder with a symmetric U-Net-like structure in a generator, and then apply an additive attention mechanism to build attention-based U-Net connections for adaptively transferring encoder representations to complement a decoder with attribute-excluding detail and enhance attribute editing ability. Second, a self-attention mechanism is incorporated into convolutional layers for modeling long-range and multi-level dependencies across image regions. experimental results indicate that our method is capable of balancing attribute editing ability and details preservation ability, and can decouple the correlation among attributes. It outperforms the state-of-the-art methods in terms of attribute manipulation accuracy and image quality.
Visual Saliency Maps Can Apply to Facial Expression Recognition
Nov 12, 2018



Human eyes concentrate different facial regions during distinct cognitive activities. We study utilising facial visual saliency maps to classify different facial expressions into different emotions. Our results show that our novel method of merely using facial saliency maps can achieve a descent accuracy of 65\%, much higher than the chance level of $1/7$. Furthermore, our approach is of semi-supervision, i.e., our facial saliency maps are generated from a general saliency prediction algorithm that is not explicitly designed for face images. We also discovered that the classification accuracies of each emotional class using saliency maps demonstrate a strong positive correlation with the accuracies produced by face images. Our work implies that humans may look at different facial areas in order to perceive different emotions.
A Facial Affect Analysis System for Autism Spectrum Disorder
Apr 07, 2019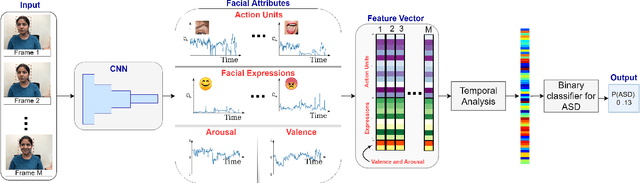
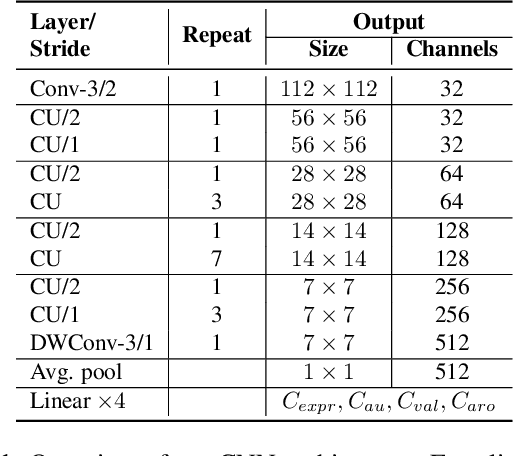

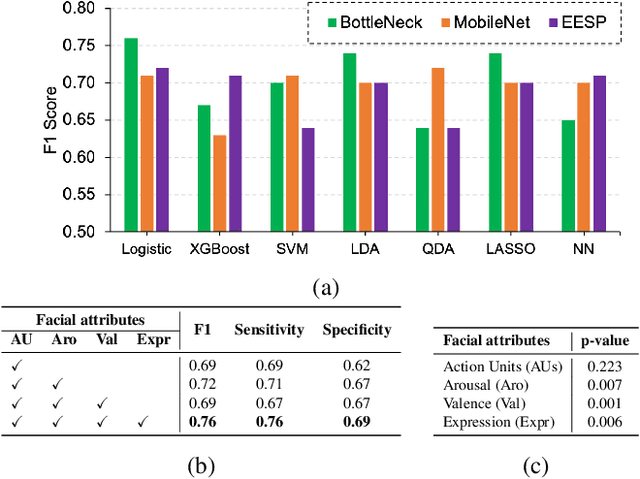
In this paper, we introduce an end-to-end machine learning-based system for classifying autism spectrum disorder (ASD) using facial attributes such as expressions, action units, arousal, and valence. Our system classifies ASD using representations of different facial attributes from convolutional neural networks, which are trained on images in the wild. Our experimental results show that different facial attributes used in our system are statistically significant and improve sensitivity, specificity, and F1 score of ASD classification by a large margin. In particular, the addition of different facial attributes improves the performance of ASD classification by about 7% which achieves a F1 score of 76%.
MaSS: Multi-attribute Selective Suppression
Oct 18, 2022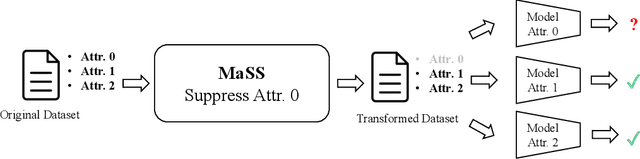

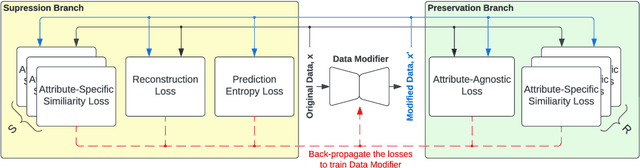
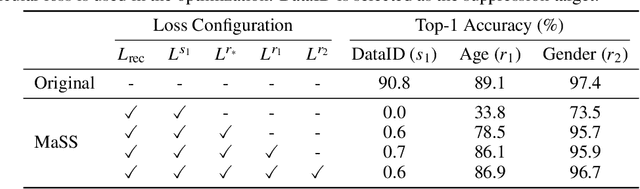
The recent rapid advances in machine learning technologies largely depend on the vast richness of data available today, in terms of both the quantity and the rich content contained within. For example, biometric data such as images and voices could reveal people's attributes like age, gender, sentiment, and origin, whereas location/motion data could be used to infer people's activity levels, transportation modes, and life habits. Along with the new services and applications enabled by such technological advances, various governmental policies are put in place to regulate such data usage and protect people's privacy and rights. As a result, data owners often opt for simple data obfuscation (e.g., blur people's faces in images) or withholding data altogether, which leads to severe data quality degradation and greatly limits the data's potential utility. Aiming for a sophisticated mechanism which gives data owners fine-grained control while retaining the maximal degree of data utility, we propose Multi-attribute Selective Suppression, or MaSS, a general framework for performing precisely targeted data surgery to simultaneously suppress any selected set of attributes while preserving the rest for downstream machine learning tasks. MaSS learns a data modifier through adversarial games between two sets of networks, where one is aimed at suppressing selected attributes, and the other ensures the retention of the rest of the attributes via general contrastive loss as well as explicit classification metrics. We carried out an extensive evaluation of our proposed method using multiple datasets from different domains including facial images, voice audio, and video clips, and obtained promising results in MaSS' generalizability and capability of suppressing targeted attributes without negatively affecting the data's usability in other downstream ML tasks.
VToonify: Controllable High-Resolution Portrait Video Style Transfer
Sep 30, 2022


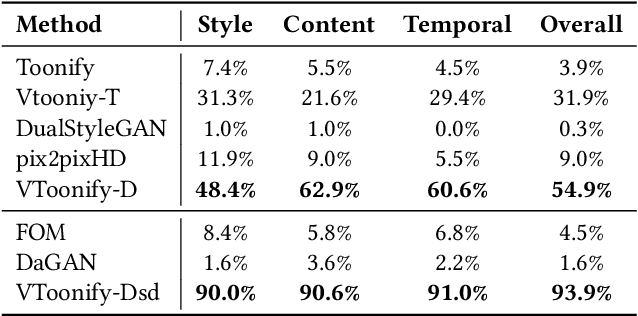
Generating high-quality artistic portrait videos is an important and desirable task in computer graphics and vision. Although a series of successful portrait image toonification models built upon the powerful StyleGAN have been proposed, these image-oriented methods have obvious limitations when applied to videos, such as the fixed frame size, the requirement of face alignment, missing non-facial details and temporal inconsistency. In this work, we investigate the challenging controllable high-resolution portrait video style transfer by introducing a novel VToonify framework. Specifically, VToonify leverages the mid- and high-resolution layers of StyleGAN to render high-quality artistic portraits based on the multi-scale content features extracted by an encoder to better preserve the frame details. The resulting fully convolutional architecture accepts non-aligned faces in videos of variable size as input, contributing to complete face regions with natural motions in the output. Our framework is compatible with existing StyleGAN-based image toonification models to extend them to video toonification, and inherits appealing features of these models for flexible style control on color and intensity. This work presents two instantiations of VToonify built upon Toonify and DualStyleGAN for collection-based and exemplar-based portrait video style transfer, respectively. Extensive experimental results demonstrate the effectiveness of our proposed VToonify framework over existing methods in generating high-quality and temporally-coherent artistic portrait videos with flexible style controls.
What is the relationship between face alignment and facial expression recognition?
May 26, 2019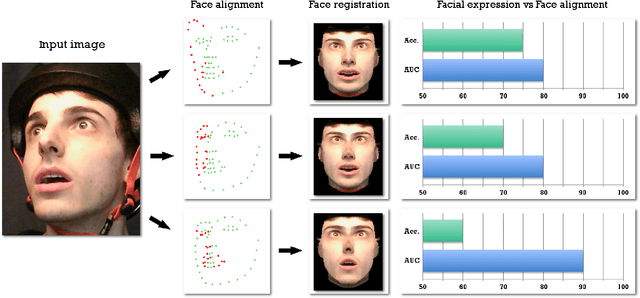
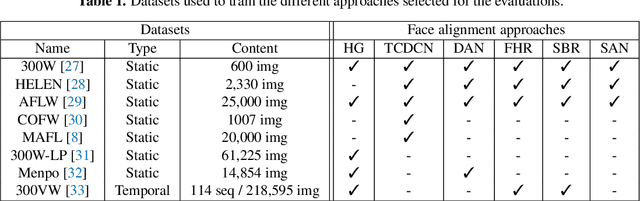

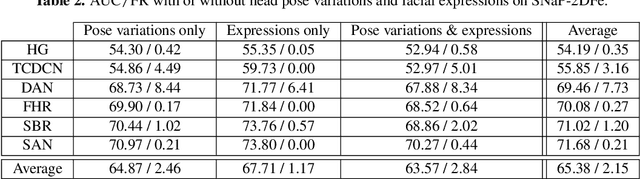
Face expression recognition is still a complex task, particularly due to the presence of head pose variations. Although face alignment approaches are becoming increasingly accurate for characterizing facial regions, it is important to consider the impact of these approaches when they are used for other related tasks such as head pose registration or facial expression recognition. In this paper, we compare the performance of recent face alignment approaches to highlight the most appropriate techniques for preserving facial geometry when correcting the head pose variation. Also, we highlight the most suitable techniques that locate facial landmarks in the presence of head pose variations and facial expressions.
Semantic Neighborhood-Aware Deep Facial Expression Recognition
Apr 27, 2020
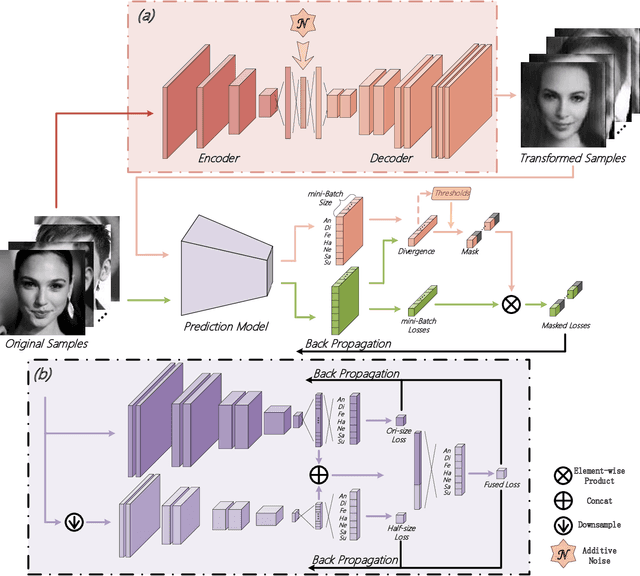

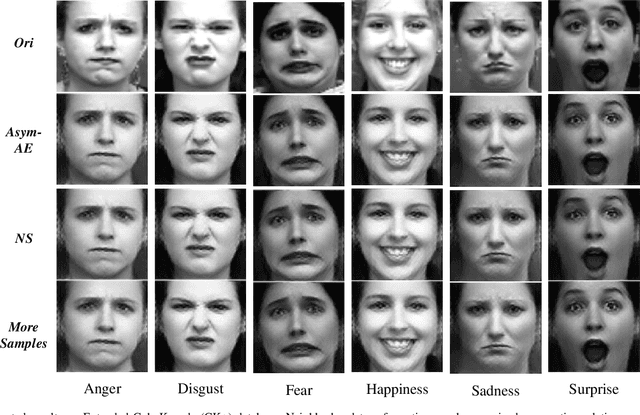
Different from many other attributes, facial expression can change in a continuous way, and therefore, a slight semantic change of input should also lead to the output fluctuation limited in a small scale. This consistency is important. However, current Facial Expression Recognition (FER) datasets may have the extreme imbalance problem, as well as the lack of data and the excessive amounts of noise, hindering this consistency and leading to a performance decreasing when testing. In this paper, we not only consider the prediction accuracy on sample points, but also take the neighborhood smoothness of them into consideration, focusing on the stability of the output with respect to slight semantic perturbations of the input. A novel method is proposed to formulate semantic perturbation and select unreliable samples during training, reducing the bad effect of them. Experiments show the effectiveness of the proposed method and state-of-the-art results are reported, getting closer to an upper limit than the state-of-the-art methods by a factor of 30\% in AffectNet, the largest in-the-wild FER database by now.
Gemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022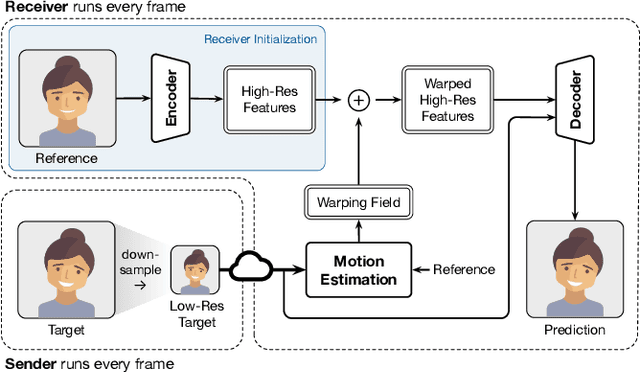
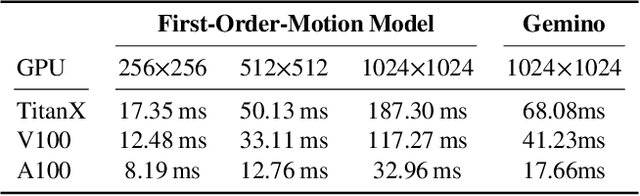


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.
Facial Behavior Analysis using 4D Curvature Statistics for Presentation Attack Detection
Nov 05, 2019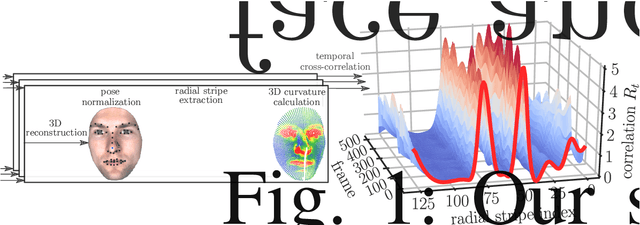


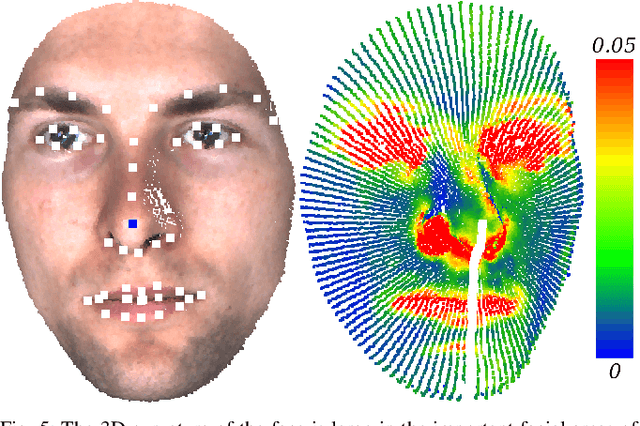
The uniqueness, complexity, and diversity of facial shapes and expressions led to success of facial biometric systems. Regardless of the accuracy of current facial recognition methods, most of them are vulnerable against the presentation of sophisticated masks. In the highly monitored application scenario at airports and banks, fraudsters probably do not wear masks. However, a deception will become more probable due to the increase of unsupervised authentication using kiosks, eGates and mobile phones in self-service. To robustly detect elastic 3D masks, one of the ultimate goals is to automatically analyze the plausibility of the facial behavior based on a sequence of 3D face scans. Most importantly, such a method would also detect all less advanced presentation attacks using static 3D masks, bent photographs with eyeholes, and replay attacks using monitors. Our proposed method achieves this goal by comparing the temporal curvature change between presentation attacks and genuine faces. For evaluation purposes, we recorded a challenging database containing replay attacks, static and elastic 3D masks using a high-quality 3D sensor. Based on the proposed representation, we found a clear separation between the low facial expressiveness of presentation attacks and the plausible behavior of genuine faces.
PTSD in the Wild: A Video Database for Studying Post-Traumatic Stress Disorder Recognition in Unconstrained Environments
Sep 28, 2022
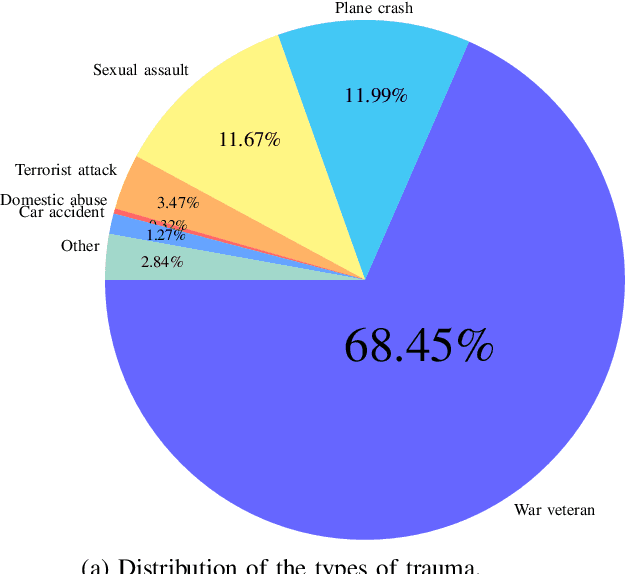
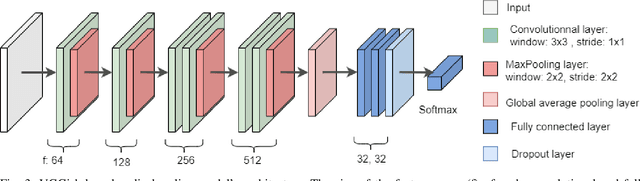
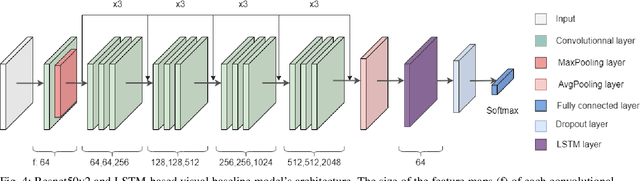
POST-traumatic stress disorder (PTSD) is a chronic and debilitating mental condition that is developed in response to catastrophic life events, such as military combat, sexual assault, and natural disasters. PTSD is characterized by flashbacks of past traumatic events, intrusive thoughts, nightmares, hypervigilance, and sleep disturbance, all of which affect a person's life and lead to considerable social, occupational, and interpersonal dysfunction. The diagnosis of PTSD is done by medical professionals using self-assessment questionnaire of PTSD symptoms as defined in the Diagnostic and Statistical Manual of Mental Disorders (DSM). In this paper, and for the first time, we collected, annotated, and prepared for public distribution a new video database for automatic PTSD diagnosis, called PTSD in the wild dataset. The database exhibits "natural" and big variability in acquisition conditions with different pose, facial expression, lighting, focus, resolution, age, gender, race, occlusions and background. In addition to describing the details of the dataset collection, we provide a benchmark for evaluating computer vision and machine learning based approaches on PTSD in the wild dataset. In addition, we propose and we evaluate a deep learning based approach for PTSD detection in respect to the given benchmark. The proposed approach shows very promising results. Interested researcher can download a copy of PTSD-in-the wild dataset from: http://www.lissi.fr/PTSD-Dataset/