 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Neighborhood-Aware Deep Facial Expression Recognition
Paper and Code
Apr 27, 2020
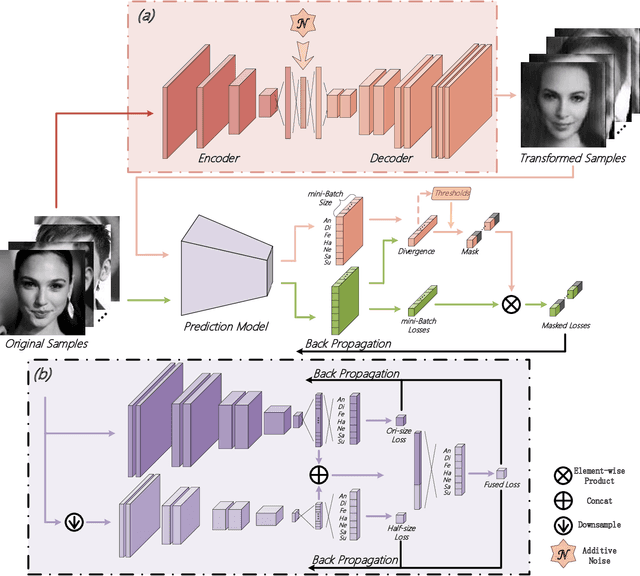

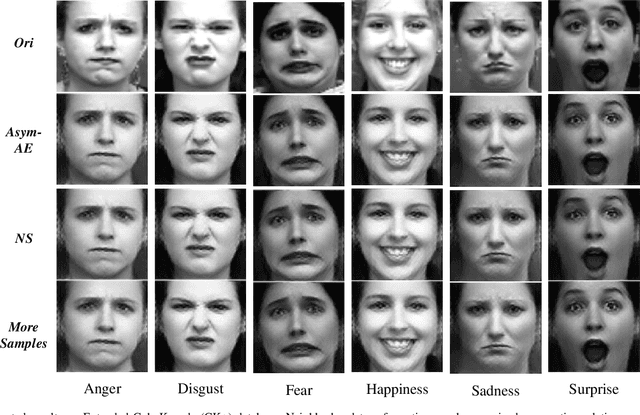
Different from many other attributes, facial expression can change in a continuous way, and therefore, a slight semantic change of input should also lead to the output fluctuation limited in a small scale. This consistency is important. However, current Facial Expression Recognition (FER) datasets may have the extreme imbalance problem, as well as the lack of data and the excessive amounts of noise, hindering this consistency and leading to a performance decreasing when testing. In this paper, we not only consider the prediction accuracy on sample points, but also take the neighborhood smoothness of them into consideration, focusing on the stability of the output with respect to slight semantic perturbations of the input. A novel method is proposed to formulate semantic perturbation and select unreliable samples during training, reducing the bad effect of them. Experiments show the effectiveness of the proposed method and state-of-the-art results are reported, getting closer to an upper limit than the state-of-the-art methods by a factor of 30\% in AffectNet, the largest in-the-wild FER database by now.