 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Coherence and Persistence in Agentic AI for System Optimization
Mar 22, 2026Designing high-performance system heuristics is a creative, iterative process requiring experts to form hypotheses and execute multi-step conceptual shifts. While Large Language Models (LLMs) show promise in automating this loop, they struggle with complex system problems due to two critical failure modes: evolutionary neighborhood bias and the coherence ceiling. Evolutionary methods often remain trapped in local optima by relying on scalar benchmark scores, failing when coordinated multi-step changes are required. Conversely, existing agentic frameworks suffer from context degradation over long horizons or fail to accumulate knowledge across independent runs. We present Engram, an agentic researcher architecture that addresses these limitations by decoupling long-horizon exploration from the constraints of a single context window. Engram organizes exploration into a sequence of agents that iteratively design, test, and analyze mechanisms. At the conclusion of each run, an agent stores code snapshots, logs, and results in a persistent Archive and distills high-level modeling insights into a compact, persistent Research Digest. Subsequent agents then begin with a fresh context window, reading the Research Digest to build on prior discoveries. We find that Engram exhibits superior performance across diverse domains including multi-cloud multicast, LLM inference request routing, and optimizing KV cache reuse in databases with natural language queries.
Glia: A Human-Inspired AI for Automated Systems Design and Optimization
Oct 31, 2025Can an AI autonomously design mechanisms for computer systems on par with the creativity and reasoning of human experts? We present Glia, an AI architecture for networked systems design that uses large language models (LLMs) in a human-inspired, multi-agent workflow. Each agent specializes in reasoning, experimentation, and analysis, collaborating through an evaluation framework that grounds abstract reasoning in empirical feedback. Unlike prior ML-for-systems methods that optimize black-box policies, Glia generates interpretable designs and exposes its reasoning process. When applied to a distributed GPU cluster for LLM inference, it produces new algorithms for request routing, scheduling, and auto-scaling that perform at human-expert levels in significantly less time, while yielding novel insights into workload behavior. Our results suggest that by combining reasoning LLMs with structured experimentation, an AI can produce creative and understandable designs for complex systems problems.
Savaal: Scalable Concept-Driven Question Generation to Enhance Human Learning
Feb 18, 2025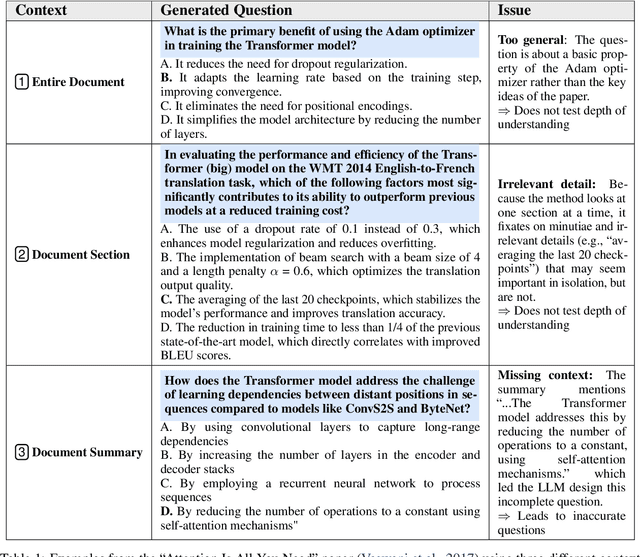
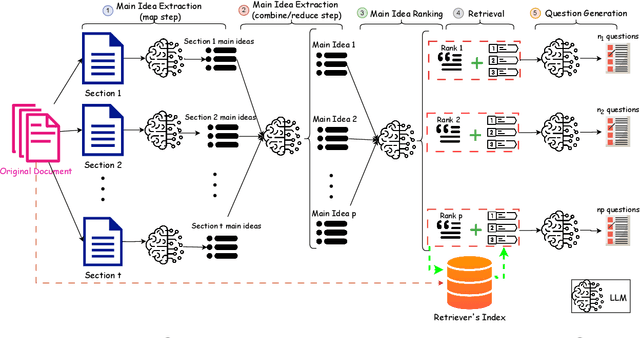

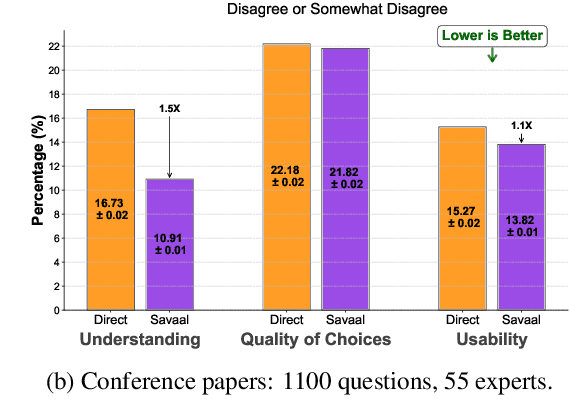
Assessing and enhancing human learning through question-answering is vital, yet automating this process remains challenging. While large language models (LLMs) excel at summarization and query responses, their ability to generate meaningful questions for learners is underexplored. We propose Savaal, a scalable question-generation system with three objectives: (i) scalability, enabling question generation from hundreds of pages of text (ii) depth of understanding, producing questions beyond factual recall to test conceptual reasoning, and (iii) domain-independence, automatically generating questions across diverse knowledge areas. Instead of providing an LLM with large documents as context, Savaal improves results with a three-stage processing pipeline. Our evaluation with 76 human experts on 71 papers and PhD dissertations shows that Savaal generates questions that better test depth of understanding by 6.5X for dissertations and 1.5X for papers compared to a direct-prompting LLM baseline. Notably, as document length increases, Savaal's advantages in higher question quality and lower cost become more pronounced.
Towards Safer Heuristics With XPlain
Oct 19, 2024



Many problems that cloud operators solve are computationally expensive, and operators often use heuristic algorithms (that are faster and scale better than optimal) to solve them more efficiently. Heuristic analyzers enable operators to find when and by how much their heuristics underperform. However, these tools do not provide enough detail for operators to mitigate the heuristic's impact in practice: they only discover a single input instance that causes the heuristic to underperform (and not the full set), and they do not explain why. We propose XPlain, a tool that extends these analyzers and helps operators understand when and why their heuristics underperform. We present promising initial results that show such an extension is viable.
Gemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022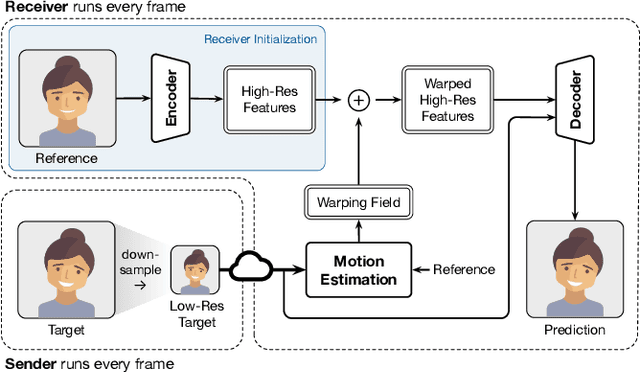
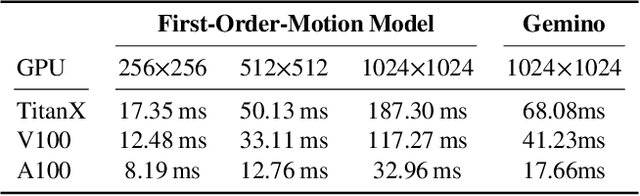


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.