 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Prediction of the facial growth direction with Machine Learning methods
Jun 19, 2021
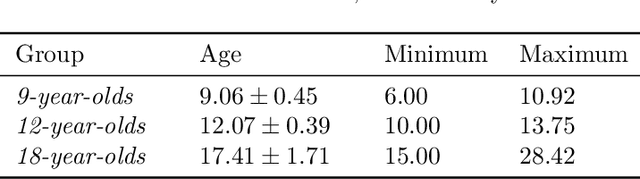
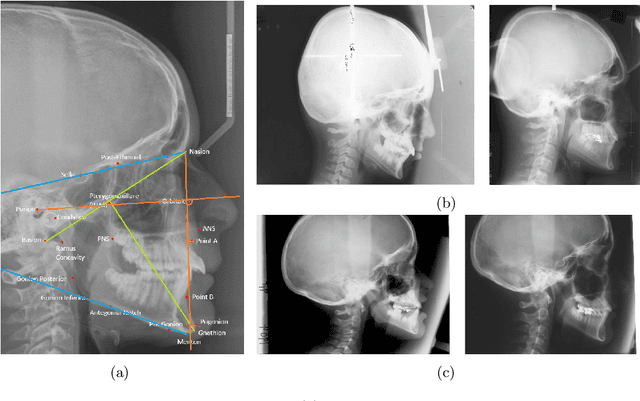
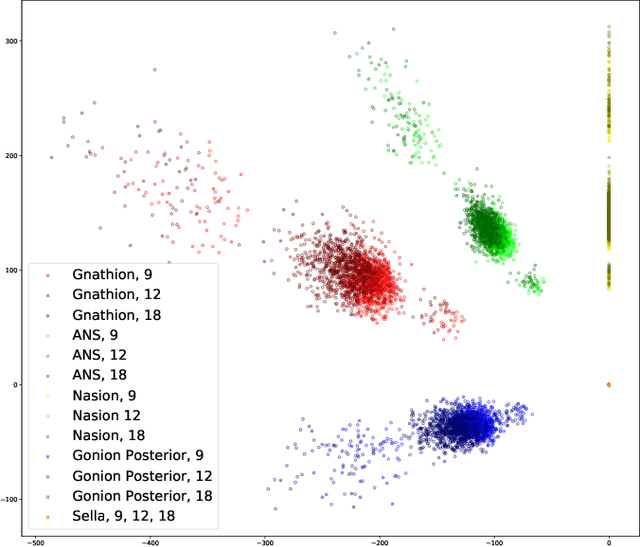
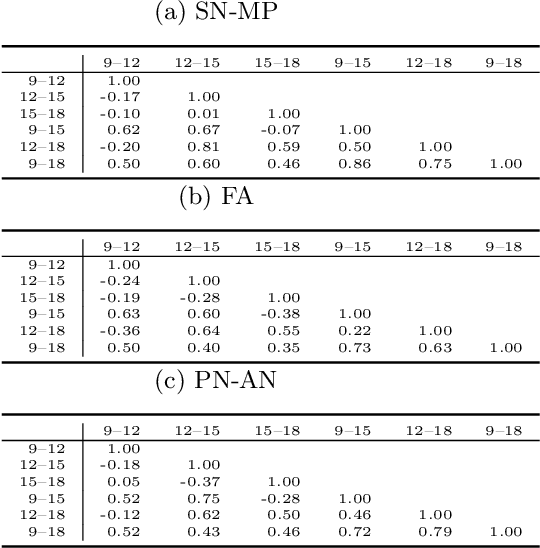
First attempts of prediction of the facial growth (FG) direction were made over half of a century ago. Despite numerous attempts and elapsed time, a satisfactory method has not been established yet and the problem still poses a challenge for medical experts. To our knowledge, this paper is the first Machine Learning approach to the prediction of FG direction. Conducted data analysis reveals the inherent complexity of the problem and explains the reasons of difficulty in FG direction prediction based on 2D X-ray images. To perform growth forecasting, we employ a wide range of algorithms, from logistic regression, through tree ensembles to neural networks and consider three, slightly different, problem formulations. The resulting classification accuracy varies between 71% and 75%.
FERAtt: Facial Expression Recognition with Attention Net
Feb 08, 2019
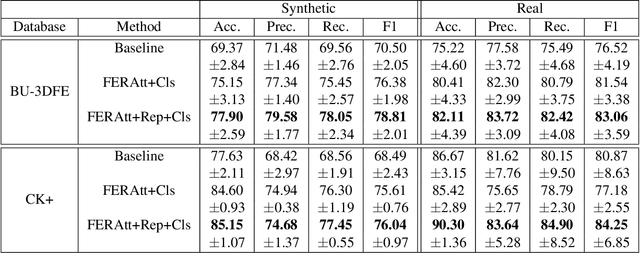
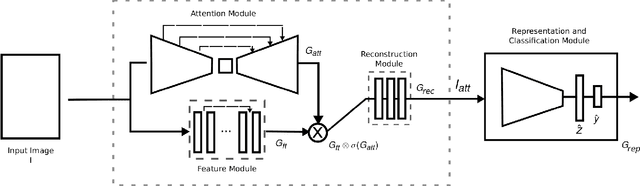
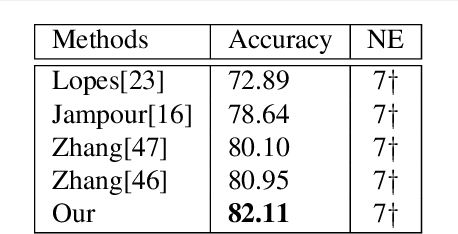
We present a new end-to-end network architecture for facial expression recognition with an attention model. It focuses attention in the human face and uses a Gaussian space representation for expression recognition. We devise this architecture based on two fundamental complementary components: (1) facial image correction and attention and (2) facial expression representation and classification. The first component uses an encoder-decoder style network and a convolutional feature extractor that are pixel-wise multiplied to obtain a feature attention map. The second component is responsible for obtaining an embedded representation and classification of the facial expression. We propose a loss function that creates a Gaussian structure on the representation space. To demonstrate the proposed method, we create two larger and more comprehensive synthetic datasets using the traditional BU3DFE and CK+ facial datasets. We compared results with the PreActResNet18 baseline. Our experiments on these datasets have shown the superiority of our approach in recognizing facial expressions.
StyleT2F: Generating Human Faces from Textual Description Using StyleGAN2
Apr 17, 2022
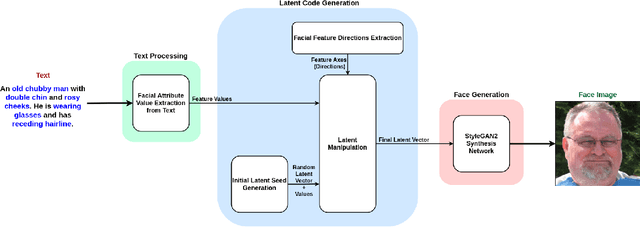
AI-driven image generation has improved significantly in recent years. Generative adversarial networks (GANs), like StyleGAN, are able to generate high-quality realistic data and have artistic control over the output, as well. In this work, we present StyleT2F, a method of controlling the output of StyleGAN2 using text, in order to be able to generate a detailed human face from textual description. We utilize StyleGAN's latent space to manipulate different facial features and conditionally sample the required latent code, which embeds the facial features mentioned in the input text. Our method proves to capture the required features correctly and shows consistency between the input text and the output images. Moreover, our method guarantees disentanglement on manipulating a wide range of facial features that sufficiently describes a human face.
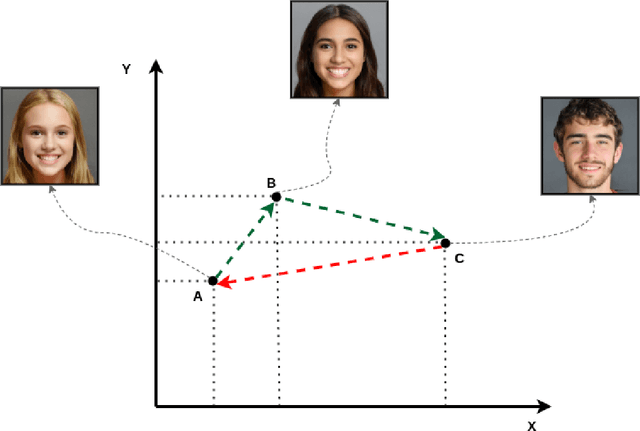
VecGAN: Image-to-Image Translation with Interpretable Latent Directions
Jul 07, 2022
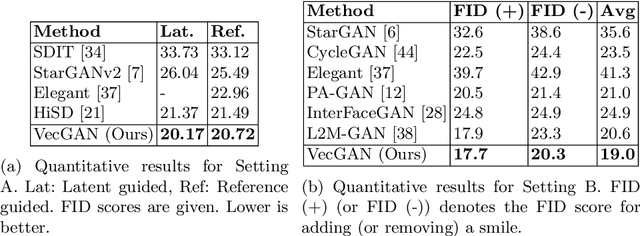
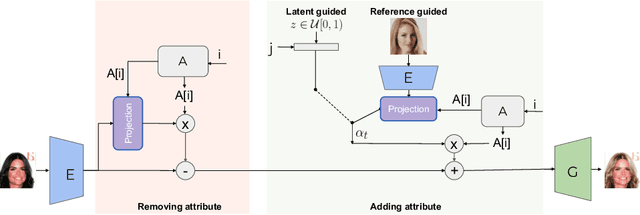

We propose VecGAN, an image-to-image translation framework for facial attribute editing with interpretable latent directions. Facial attribute editing task faces the challenges of precise attribute editing with controllable strength and preservation of the other attributes of an image. For this goal, we design the attribute editing by latent space factorization and for each attribute, we learn a linear direction that is orthogonal to the others. The other component is the controllable strength of the change, a scalar value. In our framework, this scalar can be either sampled or encoded from a reference image by projection. Our work is inspired by the latent space factorization works of fixed pretrained GANs. However, while those models cannot be trained end-to-end and struggle to edit encoded images precisely, VecGAN is end-to-end trained for image translation task and successful at editing an attribute while preserving the others. Our extensive experiments show that VecGAN achieves significant improvements over state-of-the-arts for both local and global edits.
Unconstrained Facial Expression Transfer using Style-based Generator
Dec 12, 2019

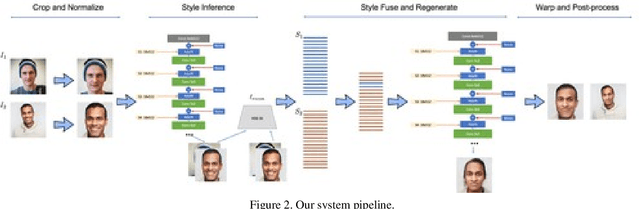
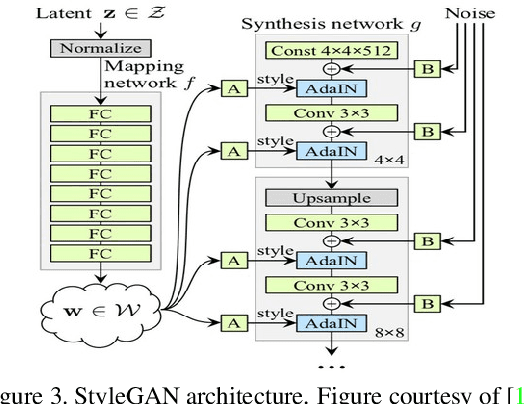
Facial expression transfer and reenactment has been an important research problem given its applications in face editing, image manipulation, and fabricated videos generation. We present a novel method for image-based facial expression transfer, leveraging the recent style-based GAN shown to be very effective for creating realistic looking images. Given two face images, our method can create plausible results that combine the appearance of one image and the expression of the other. To achieve this, we first propose an optimization procedure based on StyleGAN to infer hierarchical style vector from an image that disentangle different attributes of the face. We further introduce a linear combination scheme that fuses the style vectors of the two given images and generate a new face that combines the expression and appearance of the inputs. Our method can create high-quality synthesis with accurate facial reenactment. Unlike many existing methods, we do not rely on geometry annotations, and can be applied to unconstrained facial images of any identities without the need for retraining, making it feasible to generate large-scale expression-transferred results.
A Spontaneous Driver Emotion Facial Expression (DEFE) Dataset for Intelligent Vehicles
Apr 26, 2020
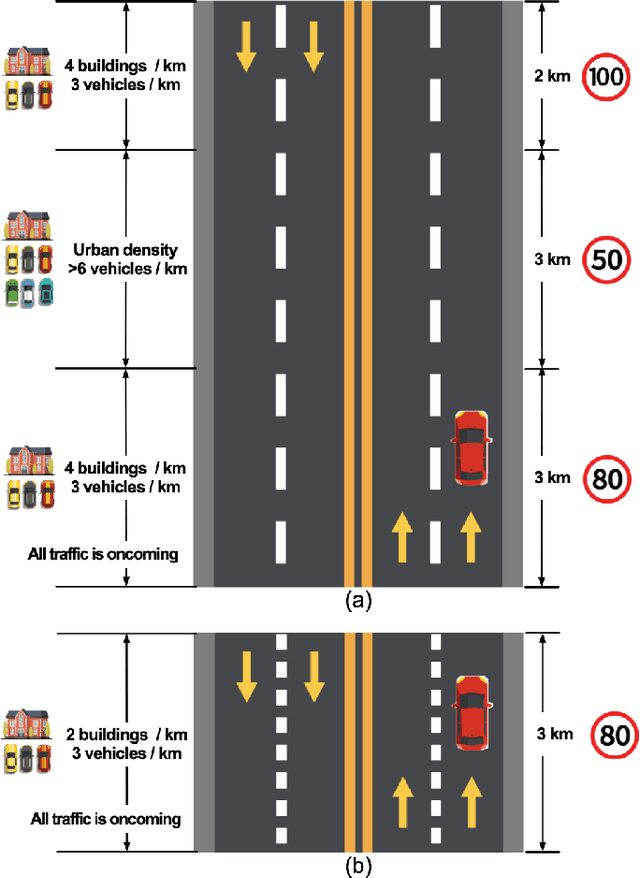
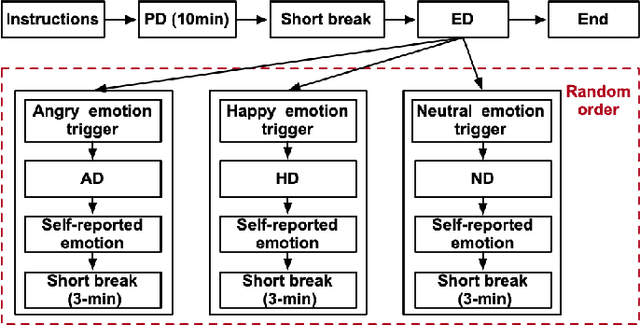
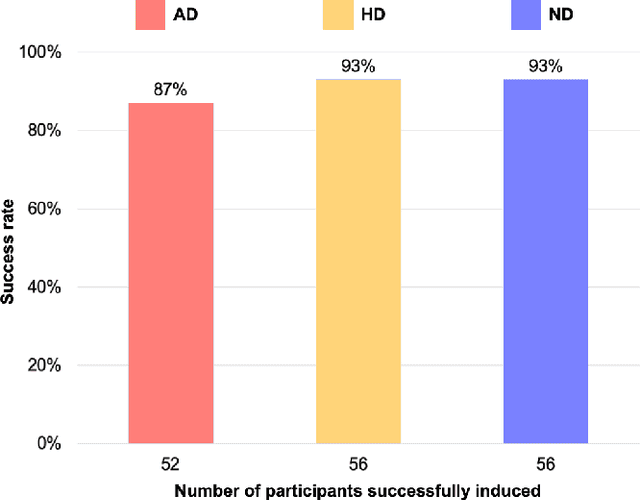
In this paper, we introduce a new dataset, the driver emotion facial expression (DEFE) dataset, for driver spontaneous emotions analysis. The dataset includes facial expression recordings from 60 participants during driving. After watching a selected video-audio clip to elicit a specific emotion, each participant completed the driving tasks in the same driving scenario and rated their emotional responses during the driving processes from the aspects of dimensional emotion and discrete emotion. We also conducted classification experiments to recognize the scales of arousal, valence, dominance, as well as the emotion category and intensity to establish baseline results for the proposed dataset. Besides, this paper compared and discussed the differences in facial expressions between driving and non-driving scenarios. The results show that there were significant differences in AUs (Action Units) presence of facial expressions between driving and non-driving scenarios, indicating that human emotional expressions in driving scenarios were different from other life scenarios. Therefore, publishing a human emotion dataset specifically for the driver is necessary for traffic safety improvement. The proposed dataset will be publicly available so that researchers worldwide can use it to develop and examine their driver emotion analysis methods. To the best of our knowledge, this is currently the only public driver facial expression dataset.
Selective manipulation of disentangled representations for privacy-aware facial image processing
Aug 26, 2022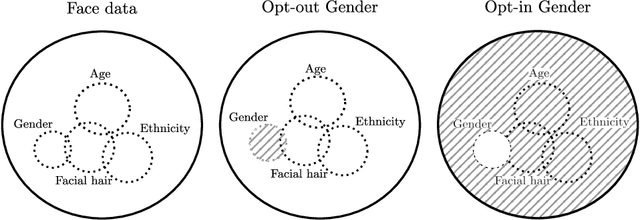
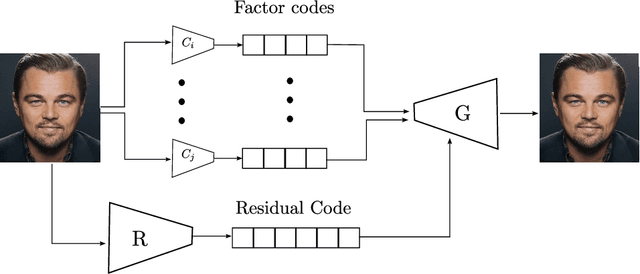
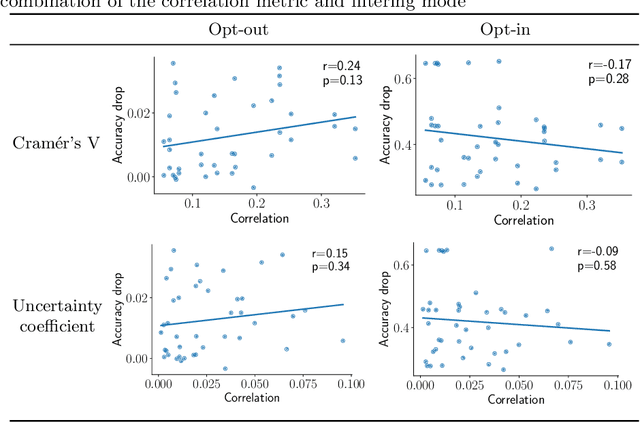
Camera sensors are increasingly being combined with machine learning to perform various tasks such as intelligent surveillance. Due to its computational complexity, most of these machine learning algorithms are offloaded to the cloud for processing. However, users are increasingly concerned about privacy issues such as function creep and malicious usage by third-party cloud providers. To alleviate this, we propose an edge-based filtering stage that removes privacy-sensitive attributes before the sensor data are transmitted to the cloud. We use state-of-the-art image manipulation techniques that leverage disentangled representations to achieve privacy filtering. We define opt-in and opt-out filter operations and evaluate their effectiveness for filtering private attributes from face images. Additionally, we examine the effect of naturally occurring correlations and residual information on filtering. We find the results promising and believe this elicits further research on how image manipulation can be used for privacy preservation.
Face Super-Resolution Using Stochastic Differential Equations
Sep 24, 2022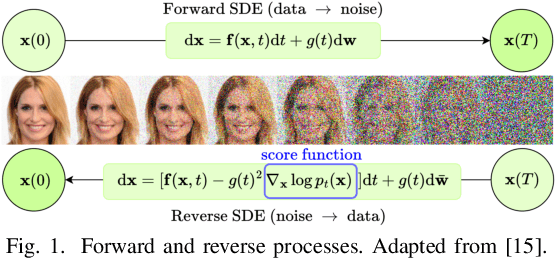
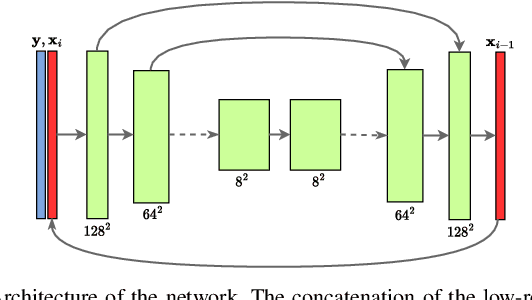

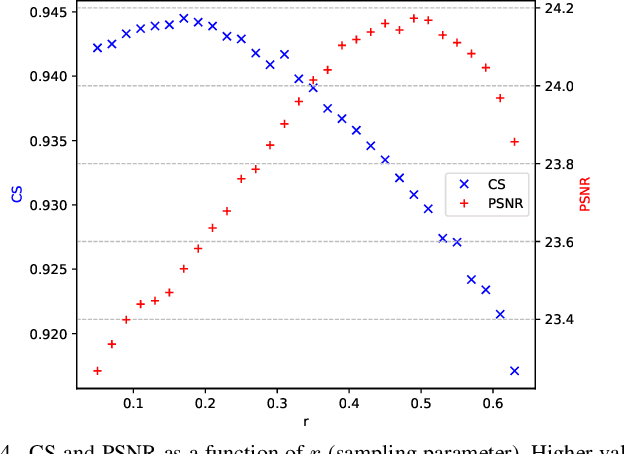
Diffusion models have proven effective for various applications such as images, audio and graph generation. Other important applications are image super-resolution and the solution of inverse problems. More recently, some works have used stochastic differential equations (SDEs) to generalize diffusion models to continuous time. In this work, we introduce SDEs to generate super-resolution face images. To the best of our knowledge, this is the first time SDEs have been used for such an application. The proposed method provides an improved peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and consistency than the existing super-resolution methods based on diffusion models. In particular, we also assess the potential application of this method for the face recognition task. A generic facial feature extractor is used to compare the super-resolution images with the ground truth and superior results were obtained compared with other methods. Our code is publicly available at https://github.com/marcelowds/sr-sde
Deep Multi-task Multi-label CNN for Effective Facial Attribute Classification
Feb 10, 2020
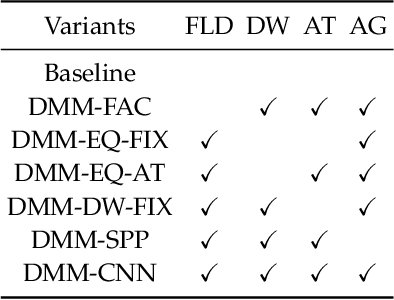
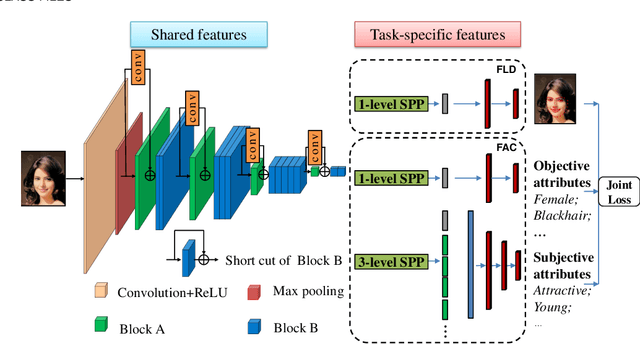
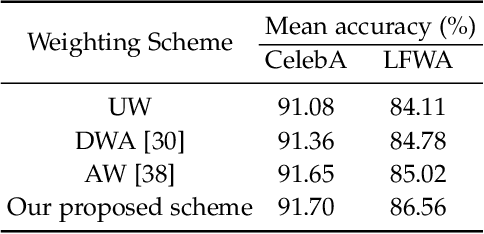
Facial Attribute Classification (FAC) has attracted increasing attention in computer vision and pattern recognition. However, state-of-the-art FAC methods perform face detection/alignment and FAC independently. The inherent dependencies between these tasks are not fully exploited. In addition, most methods predict all facial attributes using the same CNN network architecture, which ignores the different learning complexities of facial attributes. To address the above problems, we propose a novel deep multi-task multi-label CNN, termed DMM-CNN, for effective FAC. Specifically, DMM-CNN jointly optimizes two closely-related tasks (i.e., facial landmark detection and FAC) to improve the performance of FAC by taking advantage of multi-task learning. To deal with the diverse learning complexities of facial attributes, we divide the attributes into two groups: objective attributes and subjective attributes. Two different network architectures are respectively designed to extract features for two groups of attributes, and a novel dynamic weighting scheme is proposed to automatically assign the loss weight to each facial attribute during training. Furthermore, an adaptive thresholding strategy is developed to effectively alleviate the problem of class imbalance for multi-label learning. Experimental results on the challenging CelebA and LFWA datasets show the superiority of the proposed DMM-CNN method compared with several state-of-the-art FAC methods.
Chronic pain patient narratives allow for the estimation of current pain intensity
Oct 31, 2022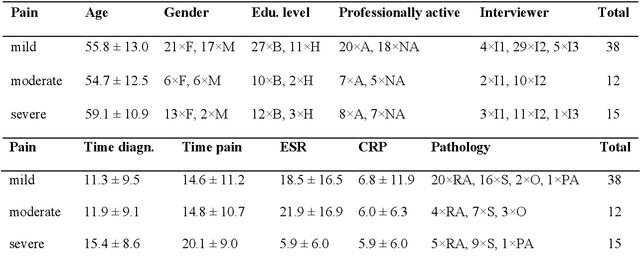
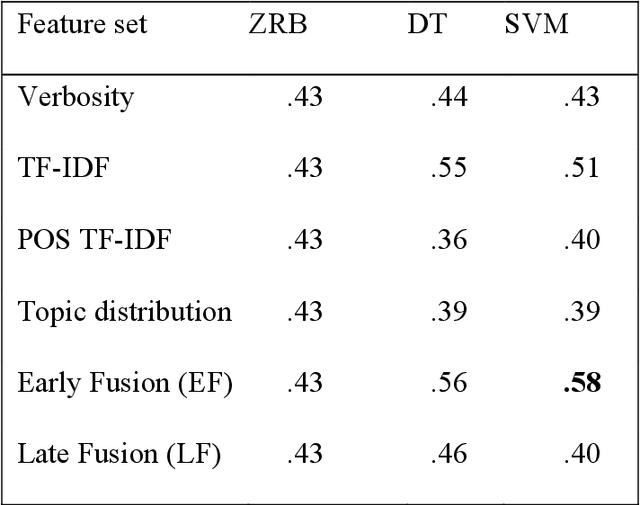

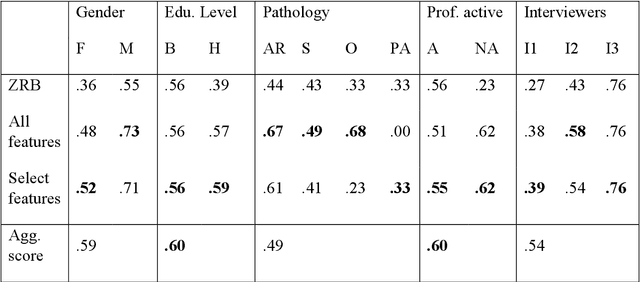
Chronic pain is a multi-dimensional experience, and pain intensity plays an important part, impacting the patients emotional balance, psychology, and behaviour. Standard self-reporting tools, such as the Visual Analogue Scale for pain, fail to capture these impacts. Moreover, these tools are susceptible to a degree of subjectivity, dependent on the patients clear understanding of how to use them, social biases, and their ability to translate a complex experience to a scale. To overcome these and other self-reporting challenges, pain intensity estimation has been previously studied based on facial expressions, electroencephalograms, brain imaging, and autonomic features. However, to the best of our knowledge, it has never been attempted to base this estimation on the patient narratives of the personal experience of chronic pain, which is what we propose in this work. Indeed, in the clinical assessment and management of chronic pain, verbal communication is essential to convey information to physicians that would otherwise not be easily accessible through standard reporting tools, since language, sociocultural, and psychosocial variables are intertwined. We show that language features from patient narratives indeed convey information relevant for pain intensity estimation, and that our computational models can take advantage of that. Specifically, our results show that patients with mild pain focus more on the use of verbs, whilst moderate and severe pain patients focus on adverbs, and nouns and adjectives, respectively, and that these differences allow for the distinction between these three pain classes.