 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoPose-NeuS: Jointly Optimizing Camera Poses with Neural Implicit Surfaces for Multi-view Reconstruction
Dec 23, 2023



Learning neural implicit surfaces from volume rendering has become popular for multi-view reconstruction. Neural surface reconstruction approaches can recover complex 3D geometry that are difficult for classical Multi-view Stereo (MVS) approaches, such as non-Lambertian surfaces and thin structures. However, one key assumption for these methods is knowing accurate camera parameters for the input multi-view images, which are not always available. In this paper, we present NoPose-NeuS, a neural implicit surface reconstruction method that extends NeuS to jointly optimize camera poses with the geometry and color networks. We encode the camera poses as a multi-layer perceptron (MLP) and introduce two additional losses, which are multi-view feature consistency and rendered depth losses, to constrain the learned geometry for better estimated camera poses and scene surfaces. Extensive experiments on the DTU dataset show that the proposed method can estimate relatively accurate camera poses, while maintaining a high surface reconstruction quality with 0.89 mean Chamfer distance.
StyleT2F: Generating Human Faces from Textual Description Using StyleGAN2
Apr 17, 2022
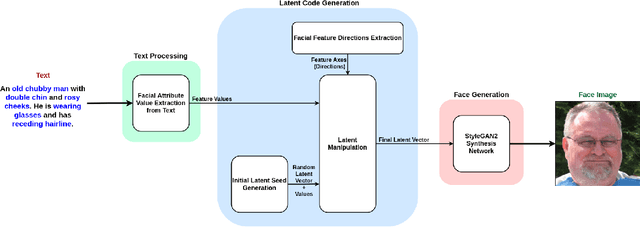
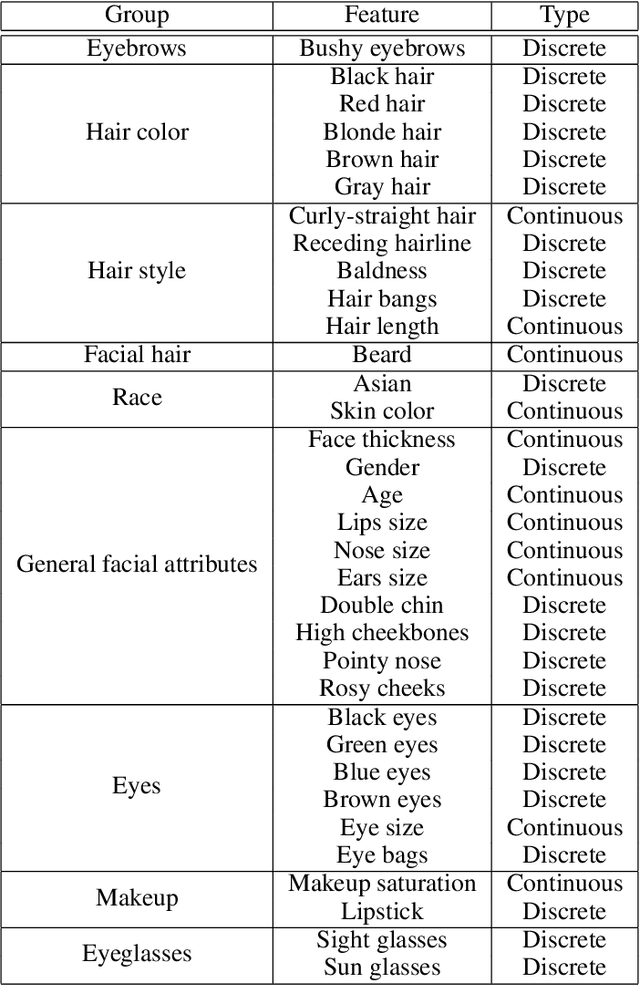
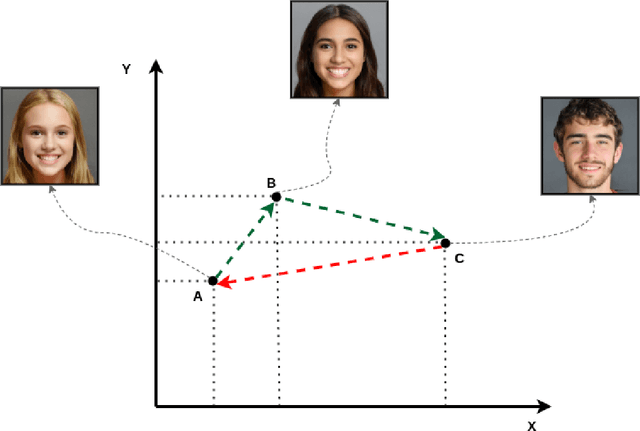
AI-driven image generation has improved significantly in recent years. Generative adversarial networks (GANs), like StyleGAN, are able to generate high-quality realistic data and have artistic control over the output, as well. In this work, we present StyleT2F, a method of controlling the output of StyleGAN2 using text, in order to be able to generate a detailed human face from textual description. We utilize StyleGAN's latent space to manipulate different facial features and conditionally sample the required latent code, which embeds the facial features mentioned in the input text. Our method proves to capture the required features correctly and shows consistency between the input text and the output images. Moreover, our method guarantees disentanglement on manipulating a wide range of facial features that sufficiently describes a human face.