 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
SELMA: SEmantic Large-scale Multimodal Acquisitions in Variable Weather, Daytime and Viewpoints
Apr 20, 2022

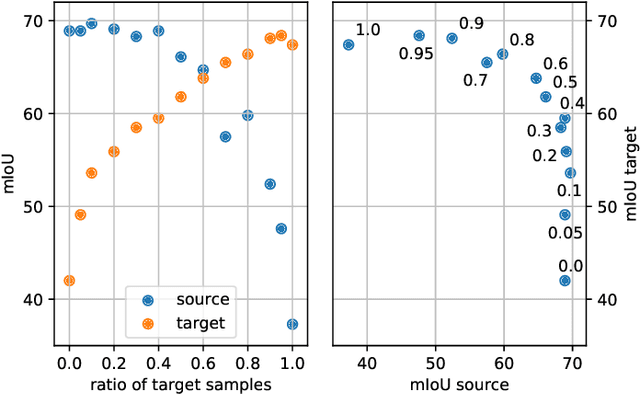
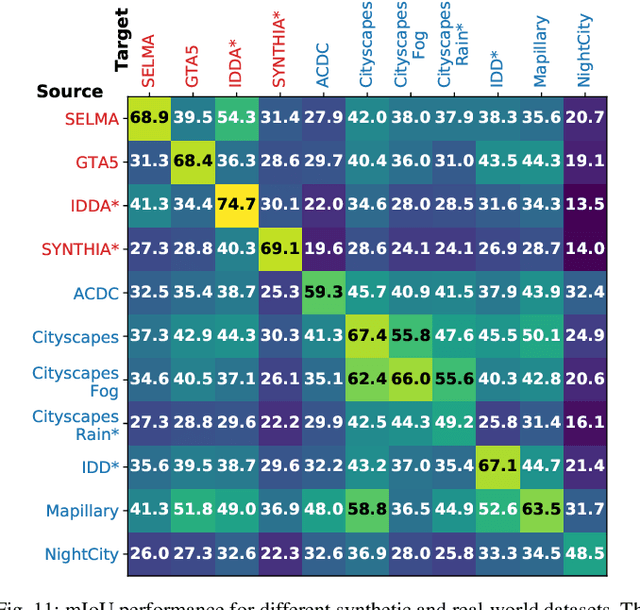

Accurate scene understanding from multiple sensors mounted on cars is a key requirement for autonomous driving systems. Nowadays, this task is mainly performed through data-hungry deep learning techniques that need very large amounts of data to be trained. Due to the high cost of performing segmentation labeling, many synthetic datasets have been proposed. However, most of them miss the multi-sensor nature of the data, and do not capture the significant changes introduced by the variation of daytime and weather conditions. To fill these gaps, we introduce SELMA, a novel synthetic dataset for semantic segmentation that contains more than 30K unique waypoints acquired from 24 different sensors including RGB, depth, semantic cameras and LiDARs, in 27 different atmospheric and daytime conditions, for a total of more than 20M samples. SELMA is based on CARLA, an open-source simulator for generating synthetic data in autonomous driving scenarios, that we modified to increase the variability and the diversity in the scenes and class sets, and to align it with other benchmark datasets. As shown by the experimental evaluation, SELMA allows the efficient training of standard and multi-modal deep learning architectures, and achieves remarkable results on real-world data. SELMA is free and publicly available, thus supporting open science and research.
Embodied AI-Driven Operation of Smart Cities: A Concise Review
Aug 22, 2021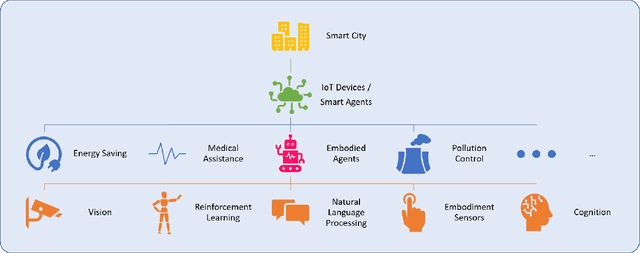
A smart city can be seen as a framework, comprised of Information and Communication Technologies (ICT). An intelligent network of connected devices that collect data with their sensors and transmit them using cloud technologies in order to communicate with other assets in the ecosystem plays a pivotal role in this framework. Maximizing the quality of life of citizens, making better use of resources, cutting costs, and improving sustainability are the ultimate goals that a smart city is after. Hence, data collected from connected devices will continuously get thoroughly analyzed to gain better insights into the services that are being offered across the city; with this goal in mind that they can be used to make the whole system more efficient. Robots and physical machines are inseparable parts of a smart city. Embodied AI is the field of study that takes a deeper look into these and explores how they can fit into real-world environments. It focuses on learning through interaction with the surrounding environment, as opposed to Internet AI which tries to learn from static datasets. Embodied AI aims to train an agent that can See (Computer Vision), Talk (NLP), Navigate and Interact with its environment (Reinforcement Learning), and Reason (General Intelligence), all at the same time. Autonomous driving cars and personal companions are some of the examples that benefit from Embodied AI nowadays. In this paper, we attempt to do a concise review of this field. We will go through its definitions, its characteristics, and its current achievements along with different algorithms, approaches, and solutions that are being used in different components of it (e.g. Vision, NLP, RL). We will then explore all the available simulators and 3D interactable databases that will make the research in this area feasible. Finally, we will address its challenges and identify its potentials for future research.
Attention-based Adaptive Selection of Operations for Image Restoration in the Presence of Unknown Combined Distortions
Dec 03, 2018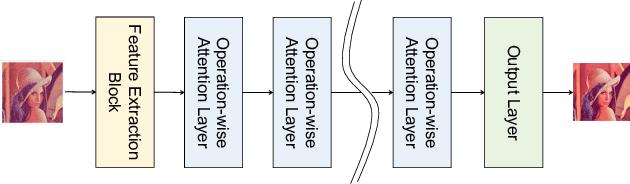
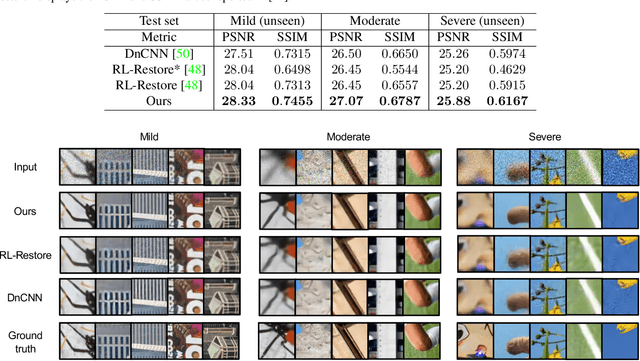
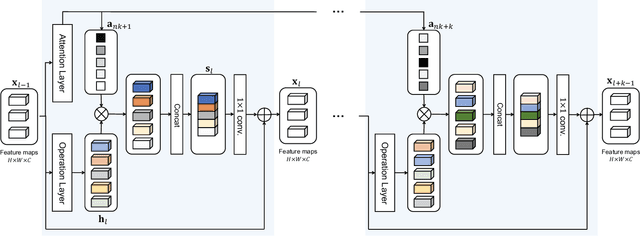

Many studies have been conducted so far on image restoration, the problem of restoring a clean image from its distorted version. There are many different types of distortion which affect image quality. Previous studies have focused on single types of distortion, proposing methods for removing them. However, image quality degrades due to multiple factors in the real world. Thus, depending on applications, e.g., vision for autonomous cars or surveillance cameras, we need to be able to deal with multiple combined distortions with unknown mixture ratios. For this purpose, we propose a simple yet effective layer architecture of neural networks. It performs multiple operations in parallel, which are weighted by an attention mechanism to enable selection of proper operations depending on the input. The layer can be stacked to form a deep network, which is differentiable and thus can be trained in an end-to-end fashion by gradient descent. The experimental results show that the proposed method works better than previous methods by a good margin on tasks of restoring images with multiple combined distortions.
Complex Signal Denoising and Interference Mitigation for Automotive Radar Using Convolutional Neural Networks
Jun 25, 2019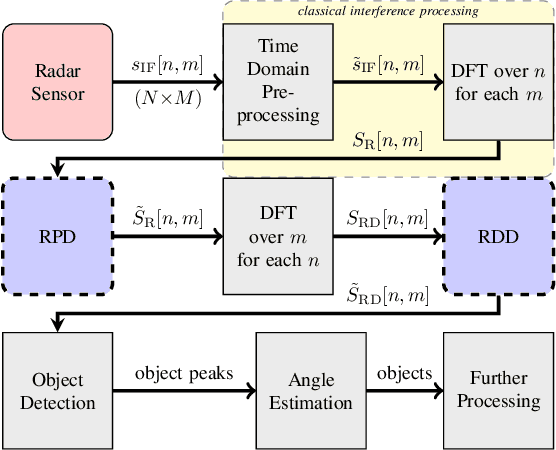
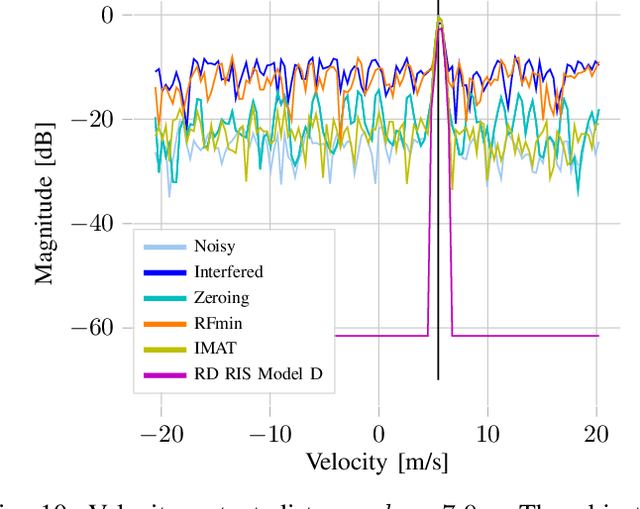
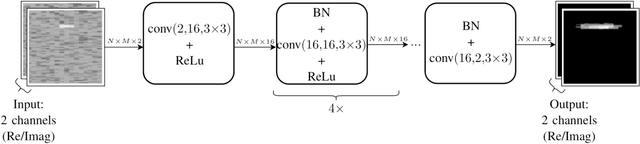
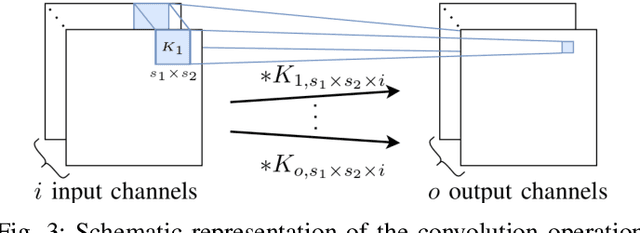
Driver assistance systems as well as autonomous cars have to rely on sensors to perceive their environment. A heterogeneous set of sensors is used to perform this task robustly. Among them, radar sensors are indispensable because of their range resolution and the possibility to directly measure velocity. Since more and more radar sensors are deployed on the streets, mutual interference must be dealt with. In the so far unregulated automotive radar frequency band, a sensor must be capable of detecting, or even mitigating the harmful effects of interference, which include a decreased detection sensitivity. In this paper, we address this issue with Convolutional Neural Networks (CNNs), which are state-of-the-art machine learning tools. We show that the ability of CNNs to find structured information in data while preserving local information enables superior denoising performance. To achieve this, CNN parameters are found using training with simulated data and integrated into the automotive radar signal processing chain. The presented method is compared with the state of the art, highlighting its promising performance. Hence, CNNs can be employed for interference mitigation as an alternative to conventional signal processing methods. Code and pre-trained models are available at https://github.com/johanna-rock/imRICnn.
Transferable Pedestrian Motion Prediction Models at Intersections
Mar 15, 2018
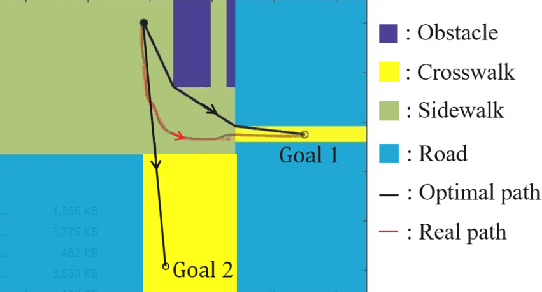


One desirable capability of autonomous cars is to accurately predict the pedestrian motion near intersections for safe and efficient trajectory planning. We are interested in developing transfer learning algorithms that can be trained on the pedestrian trajectories collected at one intersection and yet still provide accurate predictions of the trajectories at another, previously unseen intersection. We first discussed the feature selection for transferable pedestrian motion models in general. Following this discussion, we developed one transferable pedestrian motion prediction algorithm based on Inverse Reinforcement Learning (IRL) that infers pedestrian intentions and predicts future trajectories based on observed trajectory. We evaluated our algorithm on a dataset collected at two intersections, trained at one intersection and tested at the other intersection. We used the accuracy of augmented semi-nonnegative sparse coding (ASNSC), trained and tested at the same intersection as a baseline. The result shows that the proposed algorithm improves the baseline accuracy by 40% in the non-transfer task, and 16% in the transfer task.
Spherical CNNs
Feb 25, 2018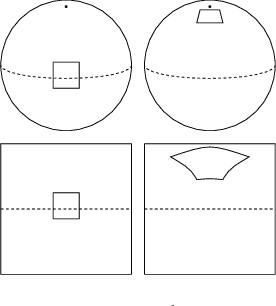
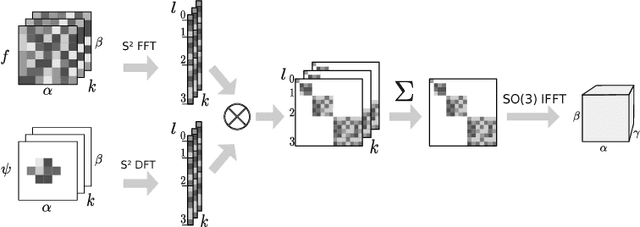

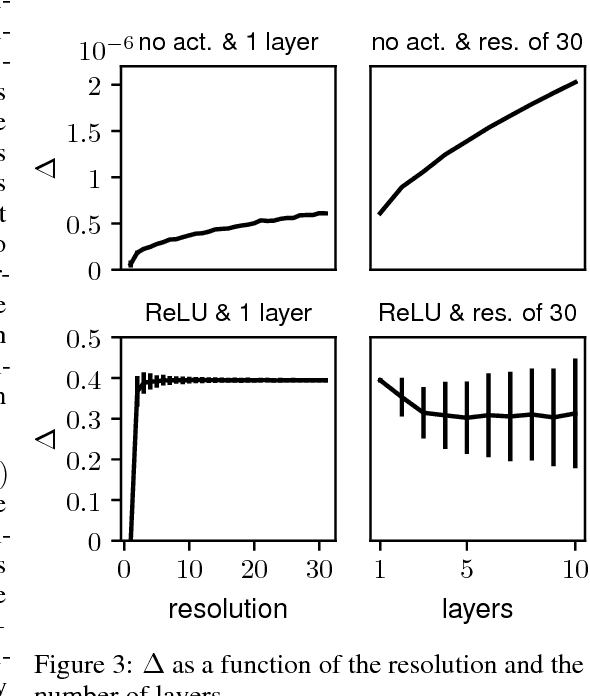
Convolutional Neural Networks (CNNs) have become the method of choice for learning problems involving 2D planar images. However, a number of problems of recent interest have created a demand for models that can analyze spherical images. Examples include omnidirectional vision for drones, robots, and autonomous cars, molecular regression problems, and global weather and climate modelling. A naive application of convolutional networks to a planar projection of the spherical signal is destined to fail, because the space-varying distortions introduced by such a projection will make translational weight sharing ineffective. In this paper we introduce the building blocks for constructing spherical CNNs. We propose a definition for the spherical cross-correlation that is both expressive and rotation-equivariant. The spherical correlation satisfies a generalized Fourier theorem, which allows us to compute it efficiently using a generalized (non-commutative) Fast Fourier Transform (FFT) algorithm. We demonstrate the computational efficiency, numerical accuracy, and effectiveness of spherical CNNs applied to 3D model recognition and atomization energy regression.
Evaluating Explanation Without Ground Truth in Interpretable Machine Learning
Jul 16, 2019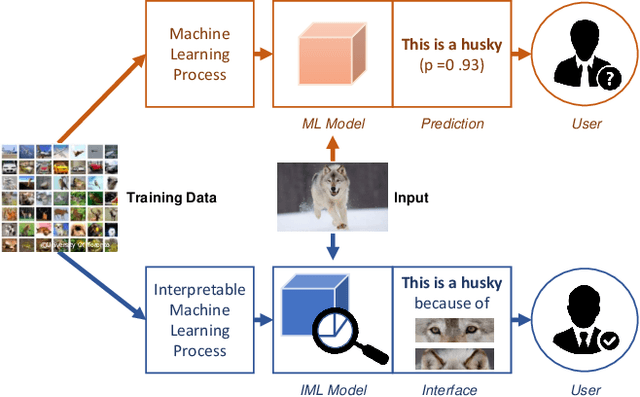
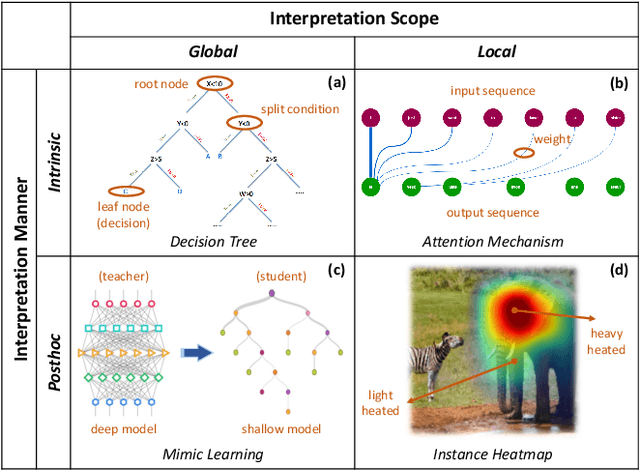
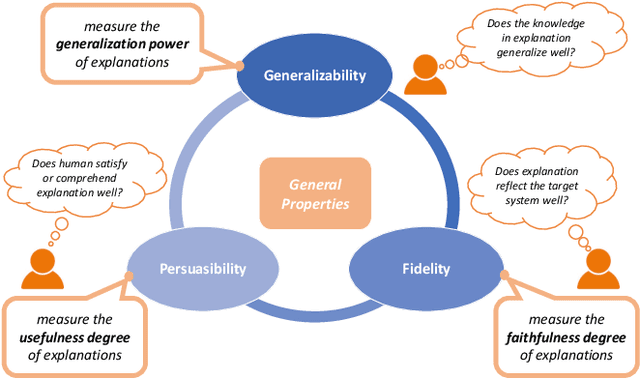
Interpretable Machine Learning (IML) has become increasingly important in many applications, such as autonomous cars and medical diagnosis, where explanations are preferred to help people better understand how machine learning systems work and further enhance their trust towards systems. Particularly in robotics, explanations from IML are significantly helpful in providing reasons for those adverse and inscrutable actions, which could impair the safety and profit of the public. However, due to the diversified scenarios and subjective nature of explanations, we rarely have the ground truth for benchmark evaluation in IML on the quality of generated explanations. Having a sense of explanation quality not only matters for quantifying system boundaries, but also helps to realize the true benefits to human users in real-world applications. To benchmark evaluation in IML, in this paper, we rigorously define the problem of evaluating explanations, and systematically review the existing efforts. Specifically, we summarize three general aspects of explanation (i.e., predictability, fidelity and persuasibility) with formal definitions, and respectively review the representative methodologies for each of them under different tasks. Further, a unified evaluation framework is designed according to the hierarchical needs from developers and end-users, which could be easily adopted for different scenarios in practice. In the end, open problems are discussed, and several limitations of current evaluation techniques are raised for future explorations.
Autonomous Vehicles that Interact with Pedestrians: A Survey of Theory and Practice
May 30, 2018
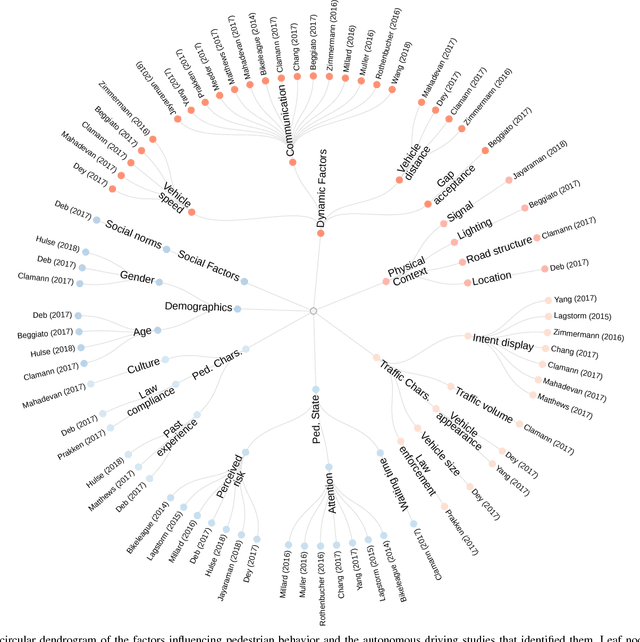


One of the major challenges that autonomous cars are facing today is driving in urban environments. To make it a reality, autonomous vehicles require the ability to communicate with other road users and understand their intentions. Such interactions are essential between the vehicles and pedestrians as the most vulnerable road users. Understanding pedestrian behavior, however, is not intuitive and depends on various factors such as demographics of the pedestrians, traffic dynamics, environmental conditions, etc. In this paper, we identify these factors by surveying pedestrian behavior studies, both the classical works on pedestrian-driver interaction and the modern ones that involve autonomous vehicles. To this end, we will discuss various methods of studying pedestrian behavior, and analyze how the factors identified in the literature are interrelated. We will also review the practical applications aimed at solving the interaction problem including design approaches for autonomous vehicles that communicate with pedestrians and visual perception and reasoning algorithms tailored to understanding pedestrian intention. Based on our findings, we will discuss the open problems and propose future research directions.
Robust Semantic Segmentation in Adverse Weather Conditions by means of Sensor Data Fusion
May 24, 2019
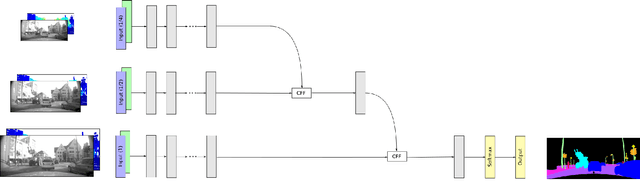
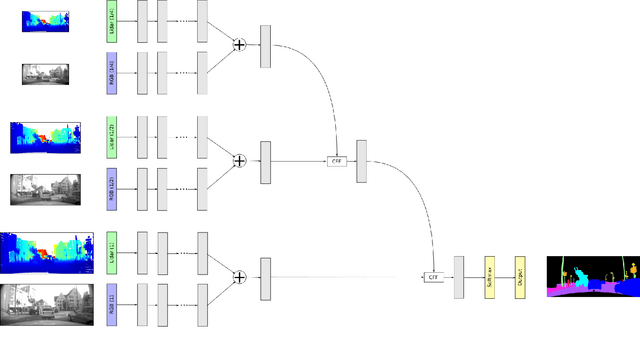

A robust and reliable semantic segmentation in adverse weather conditions is very important for autonomous cars, but most state-of-the-art approaches only achieve high accuracy rates in optimal weather conditions. The reason is that they are only optimized for good weather conditions and given noise models. However, most of them fail, if data with unknown disturbances occur, and their performance decrease enormously. One possibility to still obtain reliable results is to observe the environment with different sensor types, such as camera and lidar, and to fuse the sensor data by means of neural networks, since different sensors behave differently in diverse weather conditions. Hence, the sensors can complement each other by means of an appropriate sensor data fusion. Nevertheless, the fusion-based approaches are still susceptible to disturbances and fail to classify disturbed image areas correctly. This problem can be solved by means of a special training method, the so called Robust Learning Method (RLM), a method by which the neural network learns to handle unknown noise. In this work, two different sensor fusion architectures for semantic segmentation are compared and evaluated on several datasets. Furthermore, it is shown that the RLM increases the robustness in adverse weather conditions enormously, and achieve good results although no disturbance model has been learned by the neural network.
Automatic Building and Labeling of HD Maps with Deep Learning
Jun 01, 2020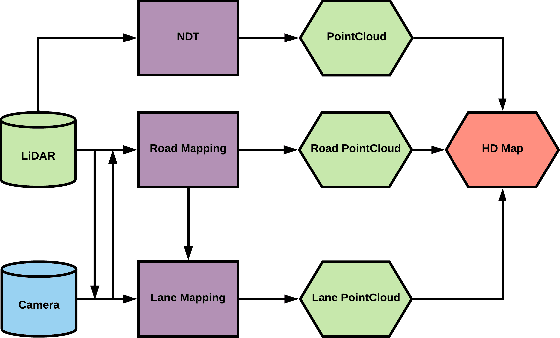
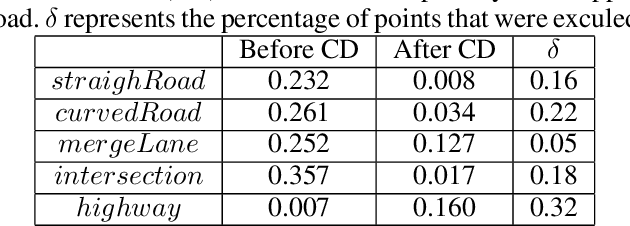
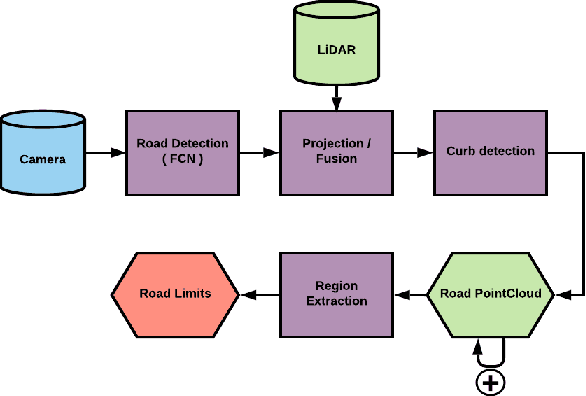
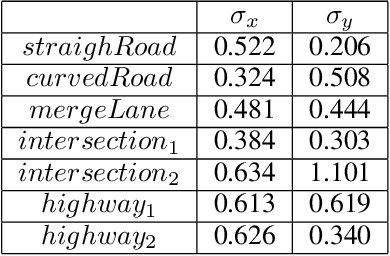
In a world where autonomous driving cars are becoming increasingly more common, creating an adequate infrastructure for this new technology is essential. This includes building and labeling high-definition (HD) maps accurately and efficiently. Today, the process of creating HD maps requires a lot of human input, which takes time and is prone to errors. In this paper, we propose a novel method capable of generating labelled HD maps from raw sensor data. We implemented and tested our methods on several urban scenarios using data collected from our test vehicle. The results show that the pro-posed deep learning based method can produce highly accurate HD maps. This approach speeds up the process of building and labeling HD maps, which can make meaningful contribution to the deployment of autonomous vehicle.