 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"autonomous cars": models, code, and papers
Social and Scene-Aware Trajectory Prediction in Crowded Spaces
Sep 19, 2019
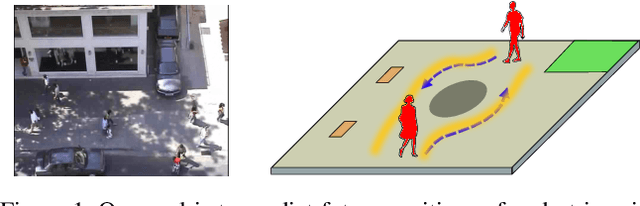
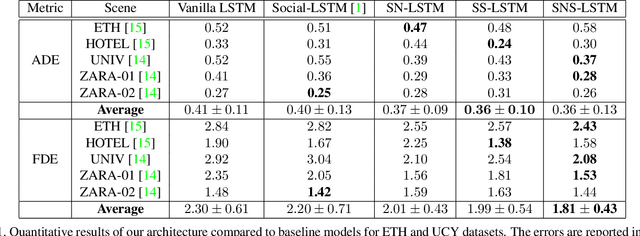
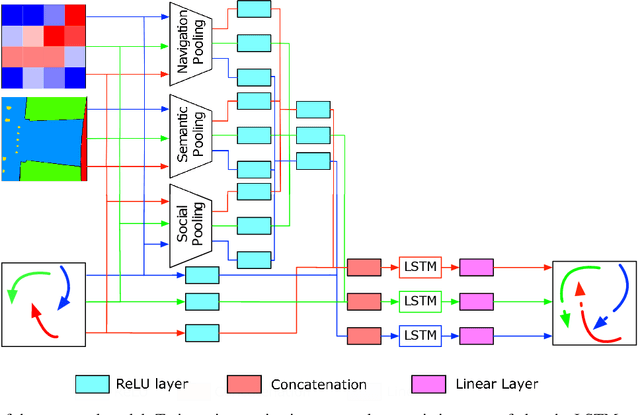
Mimicking human ability to forecast future positions or interpret complex interactions in urban scenarios, such as streets, shopping malls or squares, is essential to develop socially compliant robots or self-driving cars. Autonomous systems may gain advantage on anticipating human motion to avoid collisions or to naturally behave alongside people. To foresee plausible trajectories, we construct an LSTM (long short-term memory)-based model considering three fundamental factors: people interactions, past observations in terms of previously crossed areas and semantics of surrounding space. Our model encompasses several pooling mechanisms to join the above elements defining multiple tensors, namely social, navigation and semantic tensors. The network is tested in unstructured environments where complex paths emerge according to both internal (intentions) and external (other people, not accessible areas) motivations. As demonstrated, modeling paths unaware of social interactions or context information, is insufficient to correctly predict future positions. Experimental results corroborate the effectiveness of the proposed framework in comparison to LSTM-based models for human path prediction.
Automated and Autonomous Experiment in Electron and Scanning Probe Microscopy
Mar 22, 2021
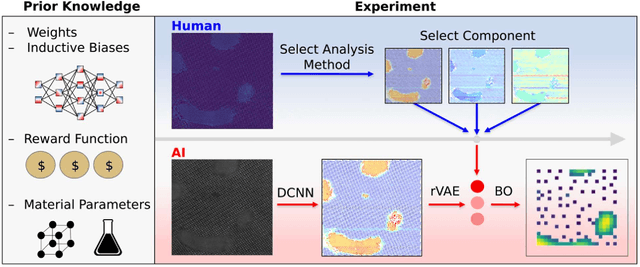
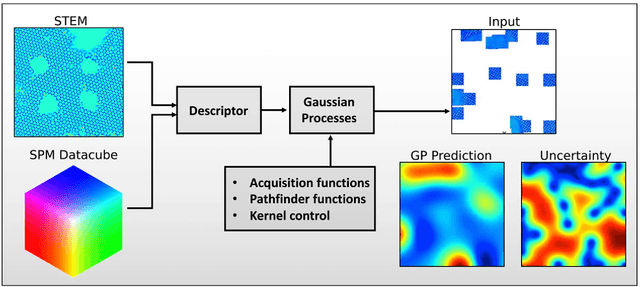
Machine learning and artificial intelligence (ML/AI) are rapidly becoming an indispensable part of physics research, with domain applications ranging from theory and materials prediction to high-throughput data analysis. In parallel, the recent successes in applying ML/AI methods for autonomous systems from robotics through self-driving cars to organic and inorganic synthesis are generating enthusiasm for the potential of these techniques to enable automated and autonomous experiment (AE) in imaging. Here, we aim to analyze the major pathways towards AE in imaging methods with sequential image formation mechanisms, focusing on scanning probe microscopy (SPM) and (scanning) transmission electron microscopy ((S)TEM). We argue that automated experiments should necessarily be discussed in a broader context of the general domain knowledge that both informs the experiment and is increased as the result of the experiment. As such, this analysis should explore the human and ML/AI roles prior to and during the experiment, and consider the latencies, biases, and knowledge priors of the decision-making process. Similarly, such discussion should include the limitations of the existing imaging systems, including intrinsic latencies, non-idealities and drifts comprising both correctable and stochastic components. We further pose that the role of the AE in microscopy is not the exclusion of human operators (as is the case for autonomous driving), but rather automation of routine operations such as microscope tuning, etc., prior to the experiment, and conversion of low latency decision making processes on the time scale spanning from image acquisition to human-level high-order experiment planning.
A Nonlinear Constrained Optimization Framework for Comfortable and Customizable Motion Planning of Nonholonomic Mobile Robots - Part I
May 22, 2013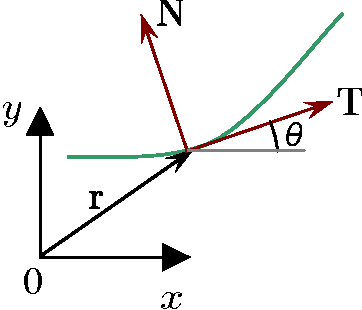
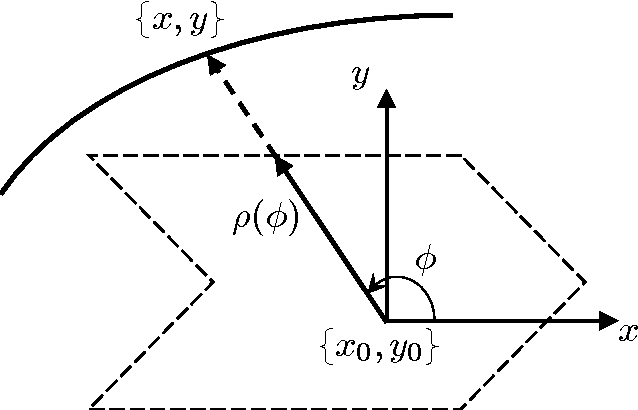
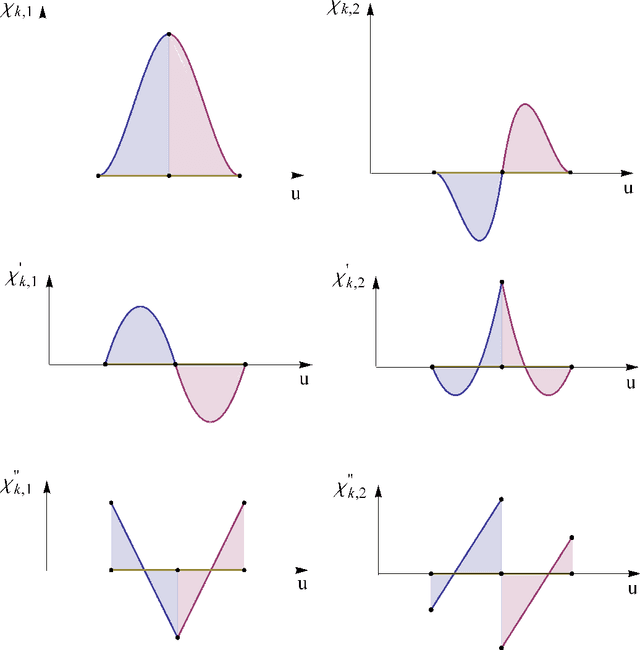
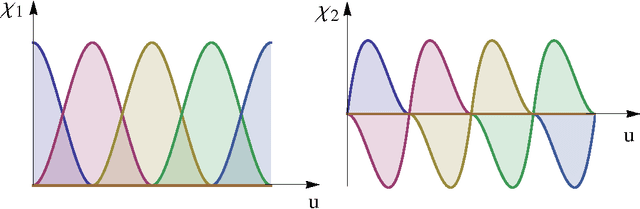
In this series of papers, we present a motion planning framework for planning comfortable and customizable motion of nonholonomic mobile robots such as intelligent wheelchairs and autonomous cars. In this first one we present the mathematical foundation of our framework. The motion of a mobile robot that transports a human should be comfortable and customizable. We identify several properties that a trajectory must have for comfort. We model motion discomfort as a weighted cost functional and define comfortable motion planning as a nonlinear constrained optimization problem of computing trajectories that minimize this discomfort given the appropriate boundary conditions and constraints. The optimization problem is infinite-dimensional and we discretize it using conforming finite elements. We also outline a method by which different users may customize the motion to achieve personal comfort. There exists significant past work in kinodynamic motion planning, to the best of our knowledge, our work is the first comprehensive formulation of kinodynamic motion planning for a nonholonomic mobile robot as a nonlinear optimization problem that includes all of the following - a careful analysis of boundary conditions, continuity requirements on trajectory, dynamic constraints, obstacle avoidance constraints, and a robust numerical implementation. In this paper, we present the mathematical foundation of the motion planning framework and formulate the full nonlinear constrained optimization problem. We describe, in brief, the discretization method using finite elements and the process of computing initial guesses for the optimization problem. Details of the above two are presented in Part II of the series.
Predictive Collision Management for Time and Risk Dependent Path Planning
Nov 26, 2020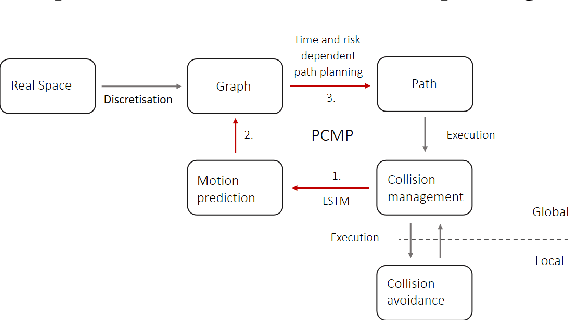
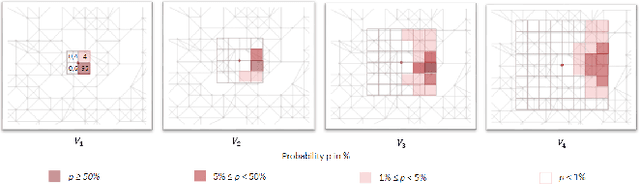
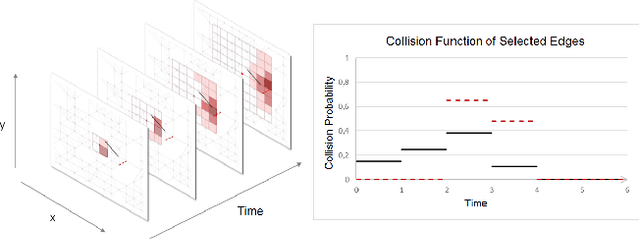
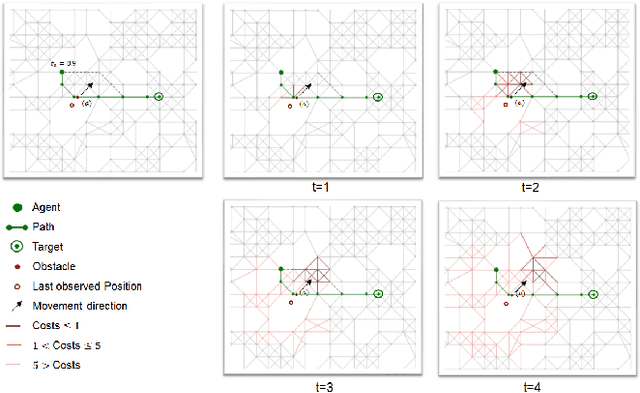
Autonomous agents such as self-driving cars or parcel robots need to recognize and avoid possible collisions with obstacles in order to move successfully in their environment. Humans, however, have learned to predict movements intuitively and to avoid obstacles in a forward-looking way. The task of collision avoidance can be divided into a global and a local level. Regarding the global level, we propose an approach called "Predictive Collision Management Path Planning" (PCMP). At the local level, solutions for collision avoidance are used that prevent an inevitable collision. Therefore, the aim of PCMP is to avoid unnecessary local collision scenarios using predictive collision management. PCMP is a graph-based algorithm with a focus on the time dimension consisting of three parts: (1) movement prediction, (2) integration of movement prediction into a time-dependent graph, and (3) time and risk-dependent path planning. The algorithm combines the search for a shortest path with the question: is the detour worth avoiding a possible collision scenario? We evaluate the evasion behavior in different simulation scenarios and the results show that a risk-sensitive agent can avoid 47.3% of the collision scenarios while making a detour of 1.3%. A risk-averse agent avoids up to 97.3% of the collision scenarios with a detour of 39.1%. Thus, an agent's evasive behavior can be controlled actively and risk-dependent using PCMP.
* Extended version of the SIGSPATIAL '20 paper
Low-cost Retina-like Robotic Lidars Based on Incommensurable Scanning
Jun 19, 2020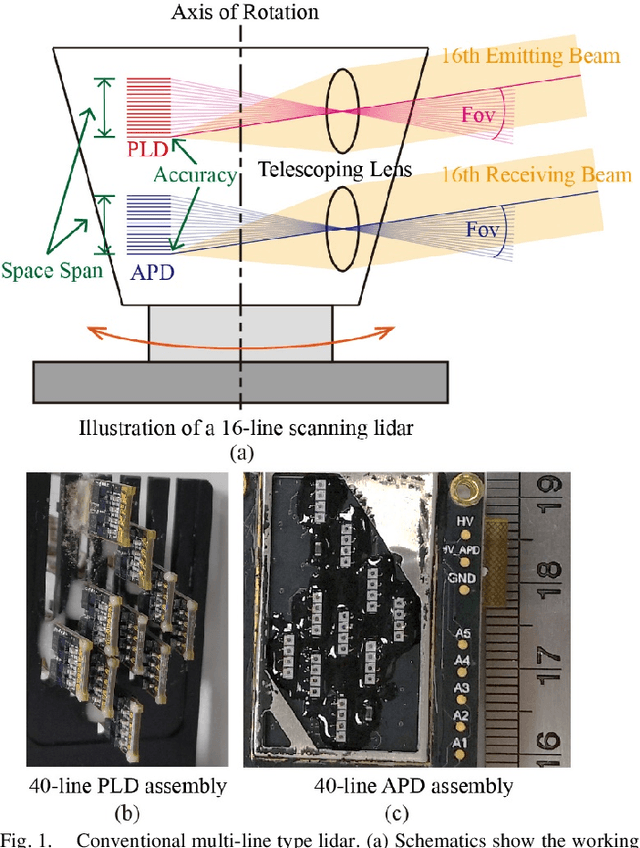
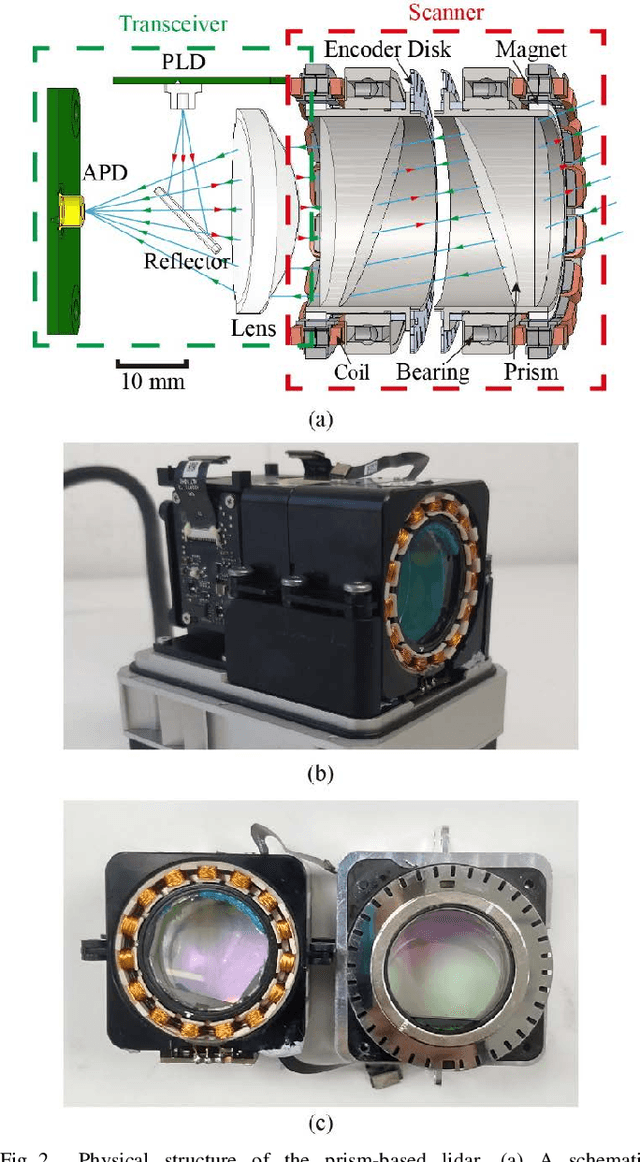
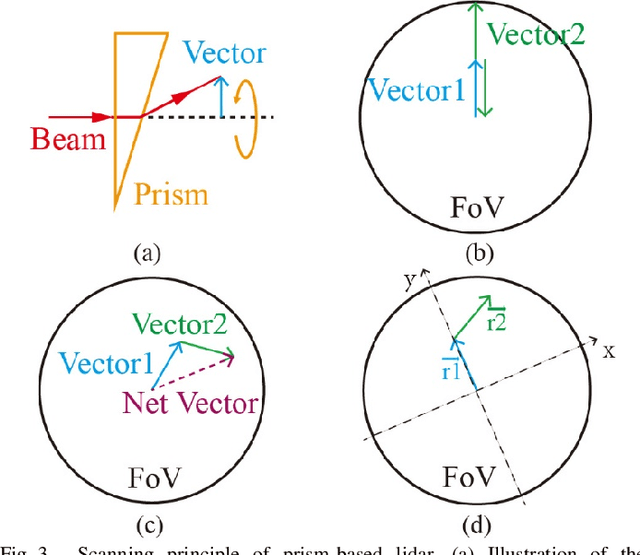
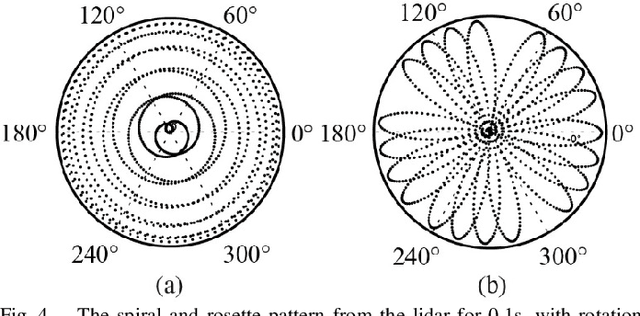
High performance lidars are essential in autonomous robots such as self-driving cars, automated ground vehicles and intelligent machines. Traditional mechanical scanning lidars offer superior performance in autonomous vehicles, but the potential mass application is limited by the inherent manufacturing difficulty. We propose a robotic lidar sensor based on incommensurable scanning that allows straightforward mass production and adoption in autonomous robots. Some unique features are additionally permitted by this incommensurable scanning. Similar to the fovea in human retina, this lidar features a peaked central angular density, enabling in applications that prefers eye-like attention. The incommensurable scanning method of this lidar could also provide a much higher resolution than conventional lidars which is beneficial in robotic applications such as sensor calibration. Examples making use of these advantageous features are demonstrated.
To Explain or Not to Explain: A Study on the Necessity of Explanations for Autonomous Vehicles
Jun 21, 2020

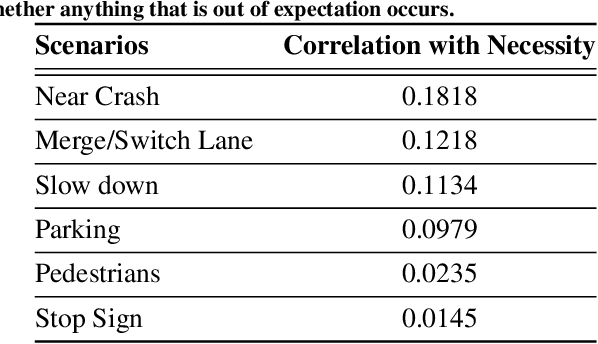
Explainable AI, in the context of autonomous systems, like self driving cars, has drawn broad interests from researchers. Recent studies have found that providing explanations for an autonomous vehicle actions has many benefits, e.g., increase trust and acceptance, but put little emphasis on when an explanation is needed and how the content of explanation changes with context. In this work, we investigate which scenarios people need explanations and how the critical degree of explanation shifts with situations and driver types. Through a user experiment, we ask participants to evaluate how necessary an explanation is and measure the impact on their trust in the self driving cars in different contexts. We also present a self driving explanation dataset with first person explanations and associated measure of the necessity for 1103 video clips, augmenting the Berkeley Deep Drive Attention dataset. Additionally, we propose a learning based model that predicts how necessary an explanation for a given situation in real time, using camera data inputs. Our research reveals that driver types and context dictates whether or not an explanation is necessary and what is helpful for improved interaction and understanding.
Meta Learning MPC using Finite-Dimensional Gaussian Process Approximations
Aug 13, 2020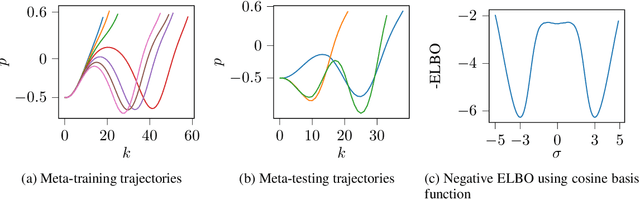
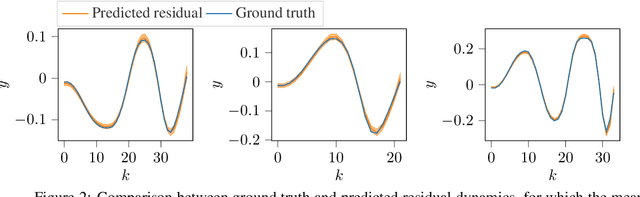
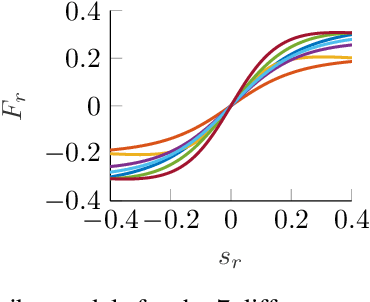
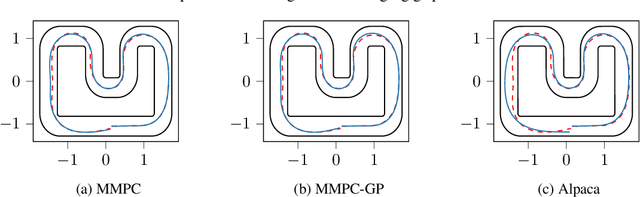
Data availability has dramatically increased in recent years, driving model-based control methods to exploit learning techniques for improving the system description, and thus control performance. Two key factors that hinder the practical applicability of learning methods in control are their high computational complexity and limited generalization capabilities to unseen conditions. Meta-learning is a powerful tool that enables efficient learning across a finite set of related tasks, easing adaptation to new unseen tasks. This paper makes use of a meta-learning approach for adaptive model predictive control, by learning a system model that leverages data from previous related tasks, while enabling fast fine-tuning to the current task during closed-loop operation. The dynamics is modeled via Gaussian process regression and, building on the Karhunen-Lo{\`e}ve expansion, can be approximately reformulated as a finite linear combination of kernel eigenfunctions. Using data collected over a set of tasks, the eigenfunction hyperparameters are optimized in a meta-training phase by maximizing a variational bound for the log-marginal likelihood. During meta-testing, the eigenfunctions are fixed, so that only the linear parameters are adapted to the new unseen task in an online adaptive fashion via Bayesian linear regression, providing a simple and efficient inference scheme. Simulation results are provided for autonomous racing with miniature race cars adapting to unseen road conditions.
Inverse Reinforce Learning with Nonparametric Behavior Clustering
Dec 15, 2017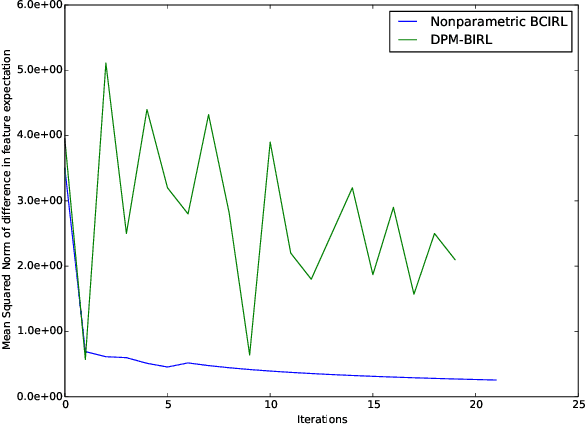

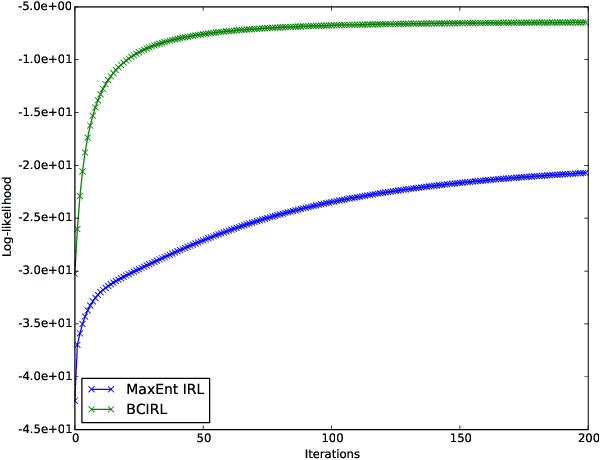
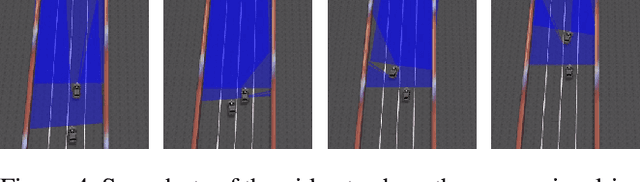
Inverse Reinforcement Learning (IRL) is the task of learning a single reward function given a Markov Decision Process (MDP) without defining the reward function, and a set of demonstrations generated by humans/experts. However, in practice, it may be unreasonable to assume that human behaviors can be explained by one reward function since they may be inherently inconsistent. Also, demonstrations may be collected from various users and aggregated to infer and predict user's behaviors. In this paper, we introduce the Non-parametric Behavior Clustering IRL algorithm to simultaneously cluster demonstrations and learn multiple reward functions from demonstrations that may be generated from more than one behaviors. Our method is iterative: It alternates between clustering demonstrations into different behavior clusters and inverse learning the reward functions until convergence. It is built upon the Expectation-Maximization formulation and non-parametric clustering in the IRL setting. Further, to improve the computation efficiency, we remove the need of completely solving multiple IRL problems for multiple clusters during the iteration steps and introduce a resampling technique to avoid generating too many unlikely clusters. We demonstrate the convergence and efficiency of the proposed method through learning multiple driver behaviors from demonstrations generated from a grid-world environment and continuous trajectories collected from autonomous robot cars using the Gazebo robot simulator.
Cautious NMPC with Gaussian Process Dynamics for Miniature Race Cars
Nov 17, 2017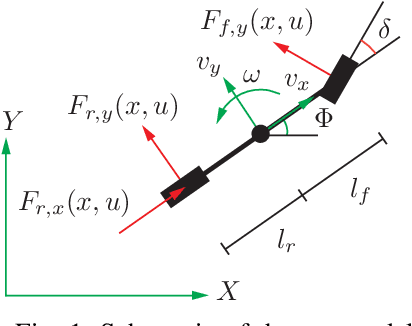
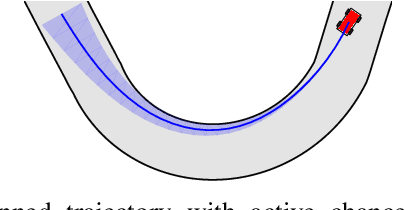
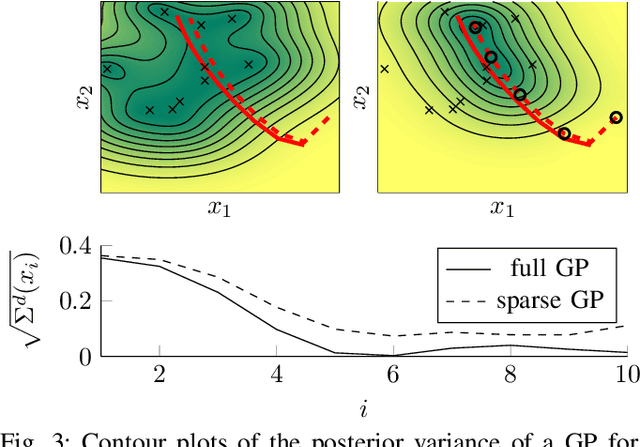
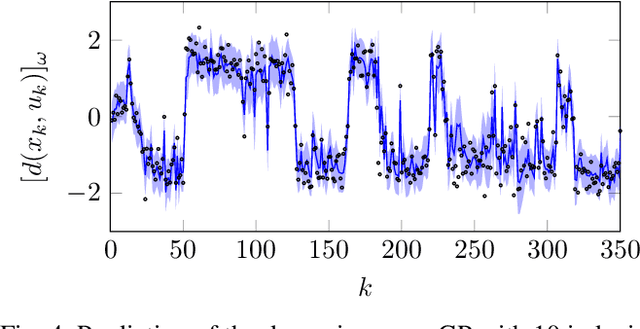
This paper presents an adaptive high performance control method for autonomous miniature race cars. Racing dynamics are notoriously hard to model from first principles, which is addressed by means of a cautious nonlinear model predictive control (NMPC) approach that learns to improve its dynamics model from data and safely increases racing performance. The approach makes use of a Gaussian Process (GP) and takes residual model uncertainty into account through a chance constrained formulation. We present a sparse GP approximation with dynamically adjusting inducing inputs, enabling a real-time implementable controller. The formulation is demonstrated in simulations, which show significant improvement with respect to both lap time and constraint satisfaction compared to an NMPC without model learning.
Unsupervised Abnormality Detection Using Heterogeneous Autonomous Systems
Jun 05, 2020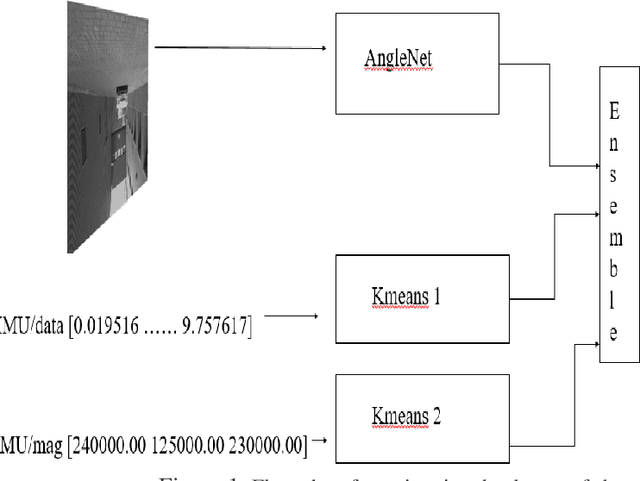


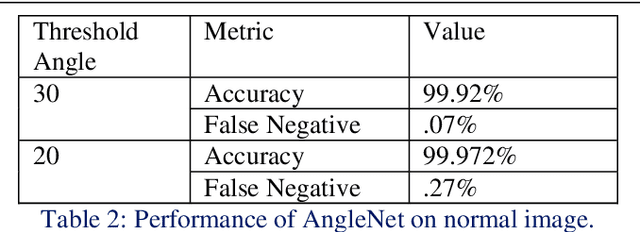
Anomaly detection in a surveillance scenario is an emerging and challenging field of research. For autonomous vehicles like drones or cars, it is immensely important to distinguish between normal and abnormal states in real-time to avoid/detect potential threats. But the nature and degree of abnormality may vary depending upon the actual environment and adversary. As a result, it is impractical to model all cases a priori and use supervised methods to classify. Also, an autonomous vehicle provides various data types like images and other analog or digital sensor data. In this paper, a heterogeneous system is proposed which estimates the degree of abnormality of an environment using drone-feed, analyzing real-time image and IMU sensor data in an unsupervised manner. Here, we have demonstrated AngleNet (a novel CNN architecture) to estimate the angle between a normal image and another image under consideration, which provides us with a measure of anomaly. Moreover, the IMU data are used in clustering models to predict abnormality. Finally, the results from these two algorithms are ensembled to estimate the final abnormality. The proposed method performs satisfactorily on the IEEE SP Cup-2020 dataset with an accuracy of 99.92%. Additionally, we have also tested this approach on an in-house dataset to validate its robustness.