 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnytime Plug-and-Play Control with Contract-Based Distributed MPC
Jul 05, 2026A central challenge in many mobile multi-robot applications is that communication topologies are inherently time-varying. Agents may enter or exit the network and such changes cannot generally be restricted a priori. This work introduces a distributed multi-agent control algorithm based on local communication that supports anytime agent joining and leaving the communication network without centralized coordination. The method scales efficiently with the number of agents by relying on a distance-based neighbor definition and on contracts derived from predicted trajectories. The resulting contract constraints guarantee collision avoidance and constraint satisfaction. We validate the proposed method in an autonomous multi-agent driving scenario, demonstrating effective collision avoidance in high-speed, dynamic environments with agents moving in opposite directions, in both simulated and real-world experiments.
Robust Adaptive Predictive Control for Hook-Based Aerial Transportation Between Moving Platforms
May 04, 2026This paper presents a novel model predictive control (MPC) approach for autonomous pick-and-place between moving platforms with a hook-equipped aerial manipulator. First, for accurate and rapid modeling of the complex dynamics, a digital twin model of the quadcopter equipped with a hook-based gripper, implemented in MuJoCo, is constructed and used as the predictive model for the MPC. To handle uncertainties of the predictive model (e.g. due to aerodynamics and uncertain payloads), a robust adaptive MPC approach is proposed. By systematic integration of zero-order robust optimization (zoRO) based uncertainty propagation and an extended Kalman filter (EKF) for parameter estimation, the MPC algorithm ensures robust constraint satisfaction, high performance, and computational efficiency. The effectiveness of the proposed method is evaluated in complex simulated scenarios and in real-world flight experiments.
Distributed Predictive Control Barrier Functions: Towards Scalable Safety Certification in Modular Multi-Agent Systems
Mar 31, 2026We consider safety-critical multi-agent systems with distributed control architectures and potentially varying network topologies. While learning-based distributed control enables scalability and high performance, a lack of formal safety guarantees in the face of unforeseen disturbances and unsafe network topology changes may lead to system failure. To address this challenge, we introduce structured control barrier functions (s-CBFs) as a multi-agent safety framework. The s-CBFs are augmented to a distributed predictive control barrier function (D-PCBF), a predictive, optimization-based safety layer that uses model predictions to guarantee recoverable safety at all times. The proposed approach enables a permissive yet formal plug-and-play protocol, allowing agents to join or leave the network while ensuring safety recovery if a change in network topology requires temporarily unsafe behavior. We validate the formulation through simulations and real-time experiments of a miniature race-car platoon.
Real-Time Online Learning for Model Predictive Control using a Spatio-Temporal Gaussian Process Approximation
Mar 18, 2026Learning-based model predictive control (MPC) can enhance control performance by correcting for model inaccuracies, enabling more precise state trajectory predictions than traditional MPC. A common approach is to model unknown residual dynamics as a Gaussian process (GP), which leverages data and also provides an estimate of the associated uncertainty. However, the high computational cost of online learning poses a major challenge for real-time GP-MPC applications. This work presents an efficient implementation of an approximate spatio-temporal GP model, offering online learning at constant computational complexity. It is optimized for GP-MPC, where it enables improved control performance by learning more accurate system dynamics online in real-time, even for time-varying systems. The performance of the proposed method is demonstrated by simulations and hardware experiments in the exemplary application of autonomous miniature racing.
Graph Neural Model Predictive Control for High-Dimensional Systems
Feb 19, 2026The control of high-dimensional systems, such as soft robots, requires models that faithfully capture complex dynamics while remaining computationally tractable. This work presents a framework that integrates Graph Neural Network (GNN)-based dynamics models with structure-exploiting Model Predictive Control to enable real-time control of high-dimensional systems. By representing the system as a graph with localized interactions, the GNN preserves sparsity, while a tailored condensing algorithm eliminates state variables from the control problem, ensuring efficient computation. The complexity of our condensing algorithm scales linearly with the number of system nodes, and leverages Graphics Processing Unit (GPU) parallelization to achieve real-time performance. The proposed approach is validated in simulation and experimentally on a physical soft robotic trunk. Results show that our method scales to systems with up to 1,000 nodes at 100 Hz in closed-loop, and demonstrates real-time reference tracking on hardware with sub-centimeter accuracy, outperforming baselines by 63.6%. Finally, we show the capability of our method to achieve effective full-body obstacle avoidance.
Distribution-Free Stochastic MPC for Joint-in-Time Chance-Constrained Linear Systems
Dec 11, 2025
This work presents a stochastic model predictive control (MPC) framework for linear systems subject to joint-in-time chance constraints under unknown disturbance distributions. Unlike existing stochastic MPC formulations that rely on parametric or Gaussian assumptions or require expensive offline computations, the proposed method leverages conformal prediction (CP) as a streamlined tool to construct finite-sample confidence regions for the system's stochastic error trajectories with minimal computational effort. These regions enable the relaxation of probabilistic constraints while providing formal guarantees. By employing an indirect feedback mechanism and a probabilistic set-based formulation, we prove recursive feasibility of the relaxed optimization problem and establish chance constraint satisfaction in closed-loop. Furthermore, we extend the approach to the more general output feedback setting with unknown measurement noise distributions. Given available noise samples, we establish satisfaction of the joint chance constraints and recursive feasibility via output measurements alone. Numerical examples demonstrate the effectiveness and advantages of the proposed method compared to existing approaches.
Multi-Timescale Model Predictive Control for Slow-Fast Systems
Nov 18, 2025



Model Predictive Control (MPC) has established itself as the primary methodology for constrained control, enabling autonomy across diverse applications. While model fidelity is crucial in MPC, solving the corresponding optimization problem in real time remains challenging when combining long horizons with high-fidelity models that capture both short-term dynamics and long-term behavior. Motivated by results on the Exponential Decay of Sensitivities (EDS), which imply that, under certain conditions, the influence of modeling inaccuracies decreases exponentially along the prediction horizon, this paper proposes a multi-timescale MPC scheme for fast-sampled control. Tailored to systems with both fast and slow dynamics, the proposed approach improves computational efficiency by i) switching to a reduced model that captures only the slow, dominant dynamics and ii) exponentially increasing integration step sizes to progressively reduce model detail along the horizon. We evaluate the method on three practically motivated robotic control problems in simulation and observe speed-ups of up to an order of magnitude.
An MPC framework for efficient navigation of mobile robots in cluttered environments
Sep 19, 2025We present a model predictive control (MPC) framework for efficient navigation of mobile robots in cluttered environments. The proposed approach integrates a finite-segment shortest path planner into the finite-horizon trajectory optimization of the MPC. This formulation ensures convergence to dynamically selected targets and guarantees collision avoidance, even under general nonlinear dynamics and cluttered environments. The approach is validated through hardware experiments on a small ground robot, where a human operator dynamically assigns target locations. The robot successfully navigated through complex environments and reached new targets within 2-3 seconds.
Time-Varying Coverage Control: A Distributed Tracker-Planner MPC Framework
Jul 02, 2025Time-varying coverage control addresses the challenge of coordinating multiple agents covering an environment where regions of interest change over time. This problem has broad applications, including the deployment of autonomous taxis and coordination in search and rescue operations. The achievement of effective coverage is complicated by the presence of time-varying density functions, nonlinear agent dynamics, and stringent system and safety constraints. In this paper, we present a distributed multi-agent control framework for time-varying coverage under nonlinear constrained dynamics. Our approach integrates a reference trajectory planner and a tracking model predictive control (MPC) scheme, which operate at different frequencies within a multi-rate framework. For periodic density functions, we demonstrate closed-loop convergence to an optimal configuration of trajectories and provide formal guarantees regarding constraint satisfaction, collision avoidance, and recursive feasibility. Additionally, we propose an efficient algorithm capable of handling nonperiodic density functions, making the approach suitable for practical applications. Finally, we validate our method through hardware experiments using a fleet of four miniature race cars.
Constraint-Aware Diffusion Guidance for Robotics: Real-Time Obstacle Avoidance for Autonomous Racing
May 19, 2025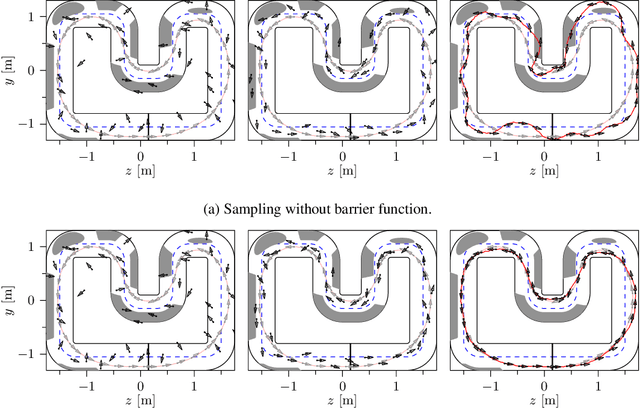

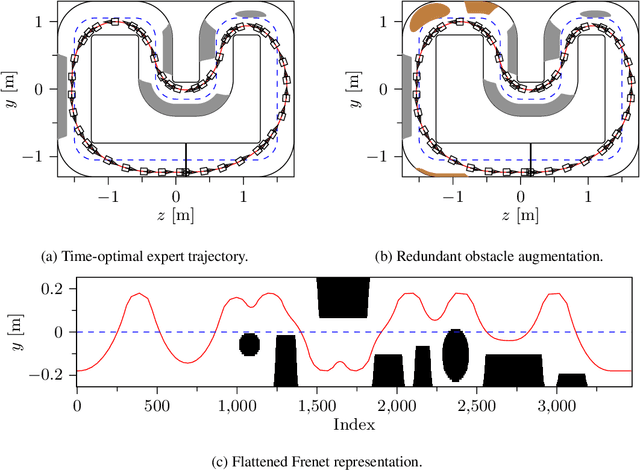
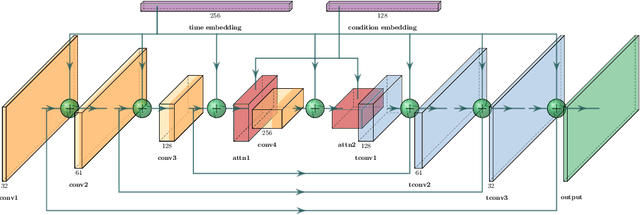
Diffusion models hold great potential in robotics due to their ability to capture complex, high-dimensional data distributions. However, their lack of constraint-awareness limits their deployment in safety-critical applications. We propose Constraint-Aware Diffusion Guidance (CoDiG), a data-efficient and general-purpose framework that integrates barrier functions into the denoising process, guiding diffusion sampling toward constraint-satisfying outputs. CoDiG enables constraint satisfaction even with limited training data and generalizes across tasks. We evaluate our framework in the challenging setting of miniature autonomous racing, where real-time obstacle avoidance is essential. Real-world experiments show that CoDiG generates safe outputs efficiently under dynamic conditions, highlighting its potential for broader robotic applications. A demonstration video is available at https://youtu.be/KNYsTdtdxOU.