 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
A Multimodal Recommender System for Large-scale Assortment Generation in E-commerce
Jun 28, 2018

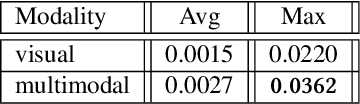
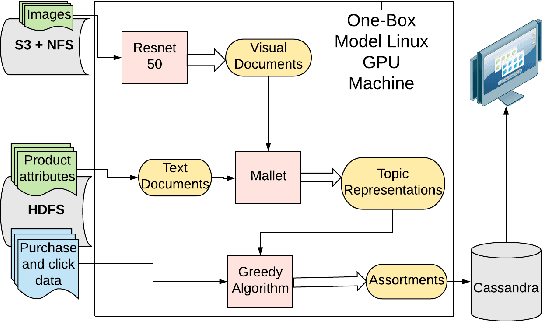

E-commerce platforms surface interesting products largely through product recommendations that capture users' styles and aesthetic preferences. Curating recommendations as a complete complementary set, or assortment, is critical for a successful e-commerce experience, especially for product categories such as furniture, where items are selected together with the overall theme, style or ambiance of a space in mind. In this paper, we propose two visually-aware recommender systems that can automatically curate an assortment of living room furniture around a couple of pre-selected seed pieces for the room. The first system aims to maximize the visual-based style compatibility of the entire selection by making use of transfer learning and topic modeling. The second system extends the first by incorporating text data and applying polylingual topic modeling to infer style over both modalities. We review the production pipeline for surfacing these visually-aware recommender systems and compare them through offline validations and large-scale online A/B tests on Overstock. Our experimental results show that complimentary style is best discovered over product sets when both visual and textual data are incorporated.
Streaming Coresets for Symmetric Tensor Factorization
Jun 01, 2020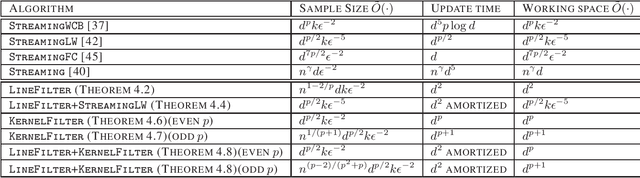
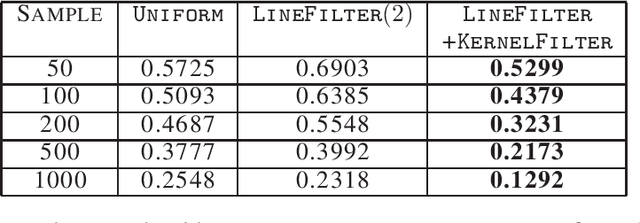
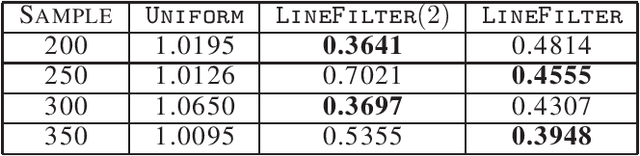
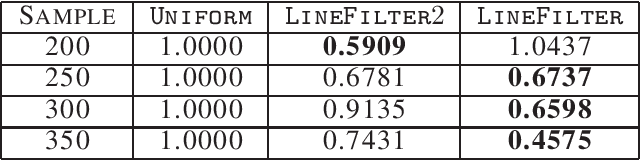
Factorizing tensors has recently become an important optimization module in a number of machine learning pipelines, especially in latent variable models. We show how to do this efficiently in the streaming setting. Given a set of $n$ vectors, each in $\mathbb{R}^d$, we present algorithms to select a sublinear number of these vectors as coreset, while guaranteeing that the CP decomposition of the $p$-moment tensor of the coreset approximates the corresponding decomposition of the $p$-moment tensor computed from the full data. We introduce two novel algorithmic techniques: online filtering and kernelization. Using these two, we present four algorithms that achieve different tradeoffs of coreset size, update time and working space, beating or matching various state of the art algorithms. In case of matrices (2-ordered tensor) our online row sampling algorithm guarantees $(1 \pm \epsilon)$ relative error spectral approximation. We show applications of our algorithms in learning single topic modeling.
Detecting Group Beliefs Related to 2018's Brazilian Elections in Tweets A Combined Study on Modeling Topics and Sentiment Analysis
May 31, 2020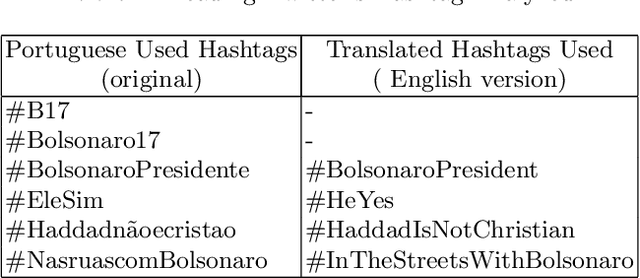
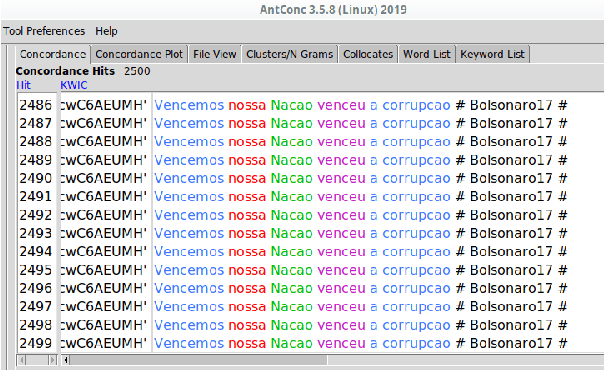
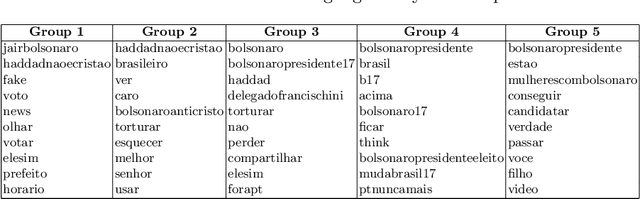
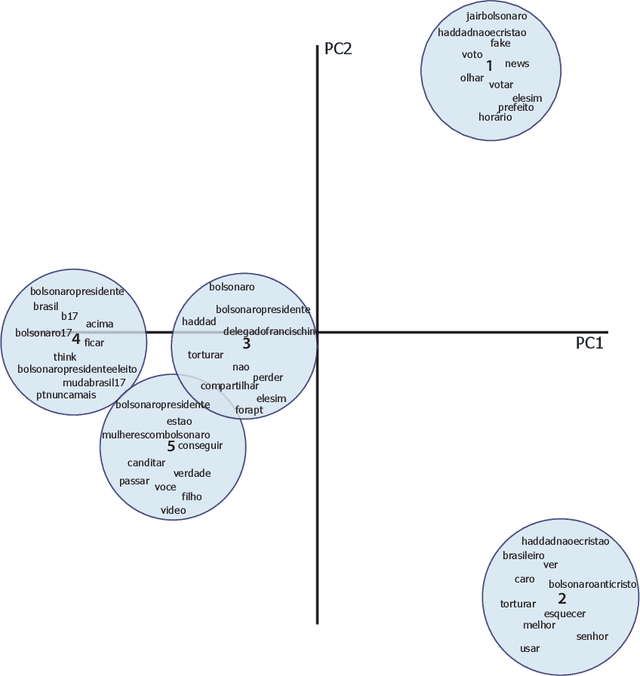
2018's Brazilian presidential elections highlighted the influence of alternative media and social networks, such as Twitter. In this work, we perform an analysis covering politically motivated discourses related to the second round in Brazilian elections. In order to verify whether similar discourses reinforce group engagement to personal beliefs, we collected a set of tweets related to political hashtags at that moment. To this end, we have used a combination of topic modeling approach with opinion mining techniques to analyze the motivated political discourses. Using SentiLex-PT, a Portuguese sentiment lexicon, we extracted from the dataset the top 5 most frequent group of words related to opinions. Applying a bag-of-words model, the cosine similarity calculation was performed between each opinion and the observed groups. This study allowed us to observe an exacerbated use of passionate discourses in the digital political scenario as a form of appreciation and engagement to the groups which convey similar beliefs.
Neural Topic Models with Survival Supervision: Jointly Predicting Time-to-Event Outcomes and Learning How Clinical Features Relate
Jul 15, 2020
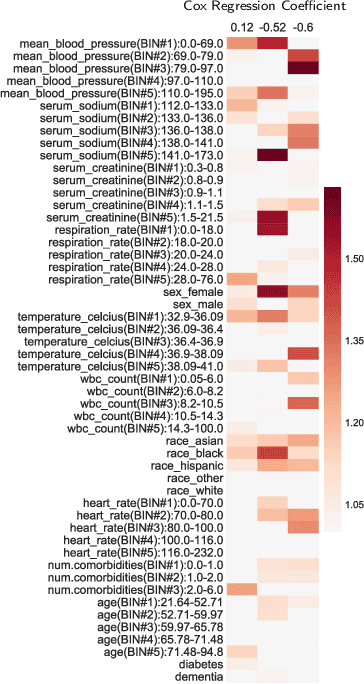
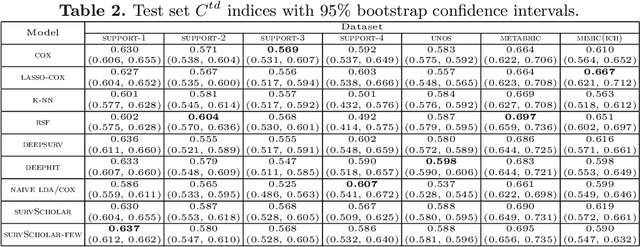
In time-to-event prediction problems, a standard approach to estimating an interpretable model is to use Cox proportional hazards, where features are selected based on lasso regularization or stepwise regression. However, these Cox-based models do not learn how different features relate. As an alternative, we present an interpretable neural network approach to jointly learn a survival model to predict time-to-event outcomes while simultaneously learning how features relate in terms of a topic model. In particular, we model each subject as a distribution over "topics", which are learned from clinical features as to help predict a time-to-event outcome. From a technical standpoint, we extend existing neural topic modeling approaches to also minimize a survival analysis loss function. We study the effectiveness of this approach on seven healthcare datasets on predicting time until death as well as hospital ICU length of stay, where we find that neural survival-supervised topic models achieves competitive accuracy with existing approaches while yielding interpretable clinical "topics" that explain feature relationships.
Latent Dirichlet Allocation (LDA) for Topic Modeling of the CFPB Consumer Complaints
Jul 18, 2018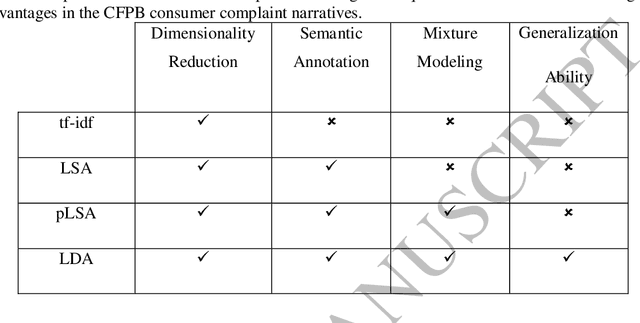
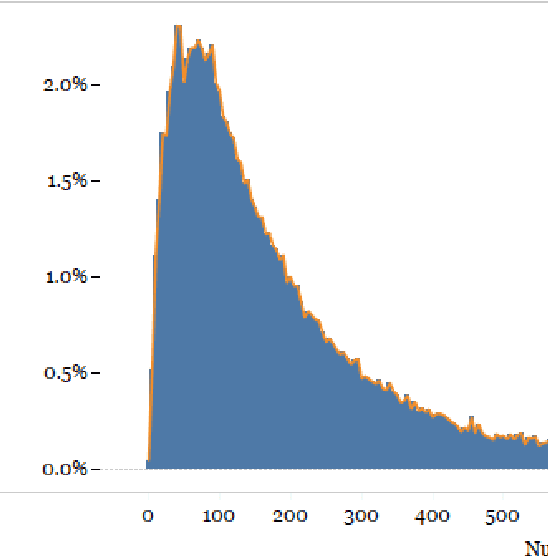
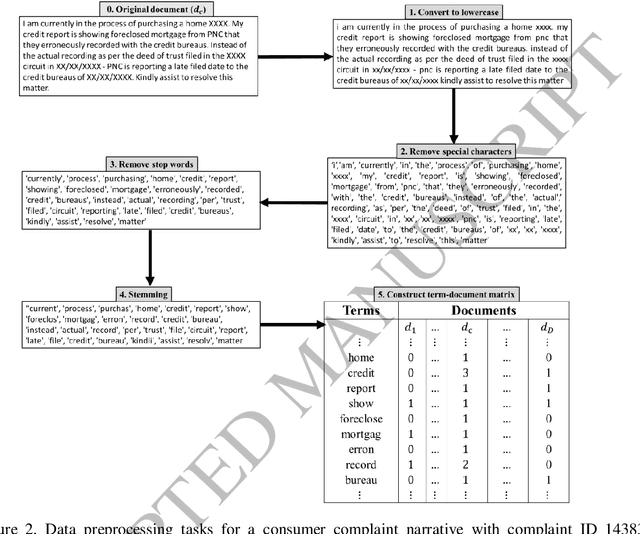
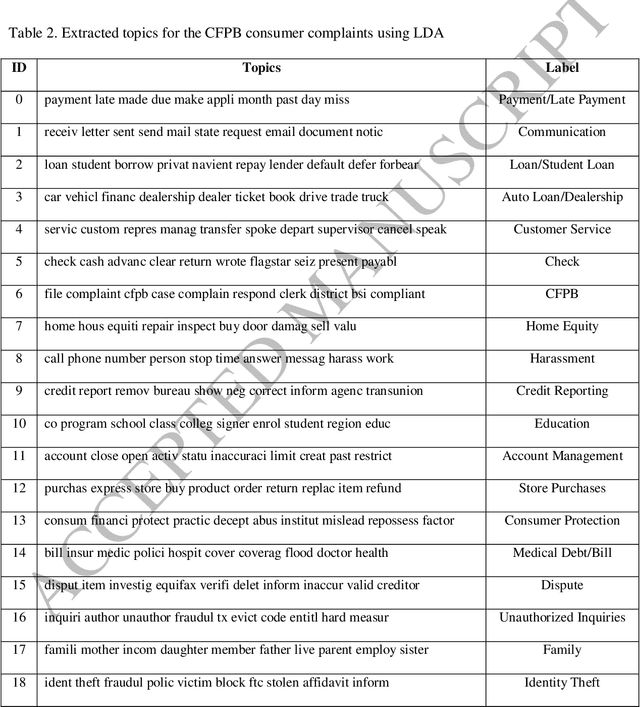
A text mining approach is proposed based on latent Dirichlet allocation (LDA) to analyze the Consumer Financial Protection Bureau (CFPB) consumer complaints. The proposed approach aims to extract latent topics in the CFPB complaint narratives, and explores their associated trends over time. The time trends will then be used to evaluate the effectiveness of the CFPB regulations and expectations on financial institutions in creating a consumer oriented culture that treats consumers fairly and prioritizes consumer protection in their decision making processes. The proposed approach can be easily operationalized as a decision support system to automate detection of emerging topics in consumer complaints. Hence, the technology-human partnership between the proposed approach and the CFPB team could certainly improve consumer protections from unfair, deceptive or abusive practices in the financial markets by providing more efficient and effective investigations of consumer complaint narratives.
Mining Twitter to Assess the Determinants of Health Behavior towards Human Papillomavirus Vaccination in the United States
Jul 06, 2019

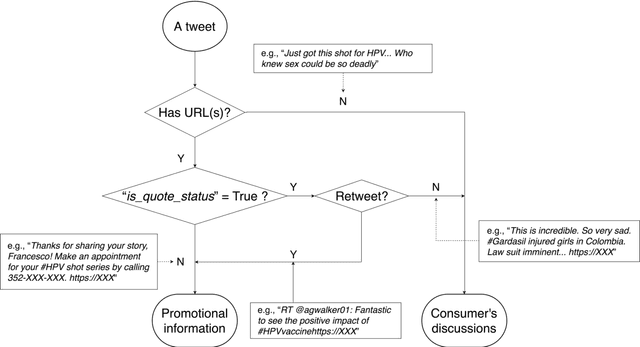

Objectives To test the feasibility of using Twitter data to assess determinants of consumers' health behavior towards Human papillomavirus (HPV) vaccination informed by the Integrated Behavior Model (IBM). Methods We used three Twitter datasets spanning from 2014 to 2018. We preprocessed and geocoded the tweets, and then built a rule-based model that classified each tweet into either promotional information or consumers' discussions. We applied topic modeling to discover major themes, and subsequently explored the associations between the topics learned from consumers' discussions and the responses of HPV-related questions in the Health Information National Trends Survey (HINTS). Results We collected 2,846,495 tweets and analyzed 335,681 geocoded tweets. Through topic modeling, we identified 122 high-quality topics. The most discussed consumer topic is "cervical cancer screening"; while in promotional tweets, the most popular topic is to increase awareness of "HPV causes cancer". 87 out of the 122 topics are correlated between promotional information and consumers' discussions. Guided by IBM, we examined the alignment between our Twitter findings and the results obtained from HINTS. 35 topics can be mapped to HINTS questions by keywords, 112 topics can be mapped to IBM constructs, and 45 topics have statistically significant correlations with HINTS responses in terms of geographic distributions. Conclusion Not only mining Twitter to assess consumers' health behaviors can obtain results comparable to surveys but can yield additional insights via a theory-driven approach. Limitations exist, nevertheless, these encouraging results impel us to develop innovative ways of leveraging social media in the changing health communication landscape.
TwiInsight: Discovering Topics and Sentiments from Social Media Datasets
May 23, 2017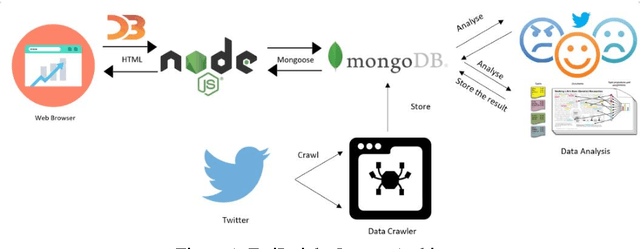



Social media platforms contain a great wealth of information which provides opportunities for us to explore hidden patterns or unknown correlations, and understand people's satisfaction with what they are discussing. As one showcase, in this paper, we present a system, TwiInsight which explores the insight of Twitter data. Different from other Twitter analysis systems, TwiInsight automatically extracts the popular topics under different categories (e.g., healthcare, food, technology, sports and transport) discussed in Twitter via topic modeling and also identifies the correlated topics across different categories. Additionally, it also discovers the people's opinions on the tweets and topics via the sentiment analysis. The system also employs an intuitive and informative visualization to show the uncovered insight. Furthermore, we also develop and compare six most popular algorithms - three for sentiment analysis and three for topic modeling.
Latent Dirichlet Allocation Model Training with Differential Privacy
Oct 09, 2020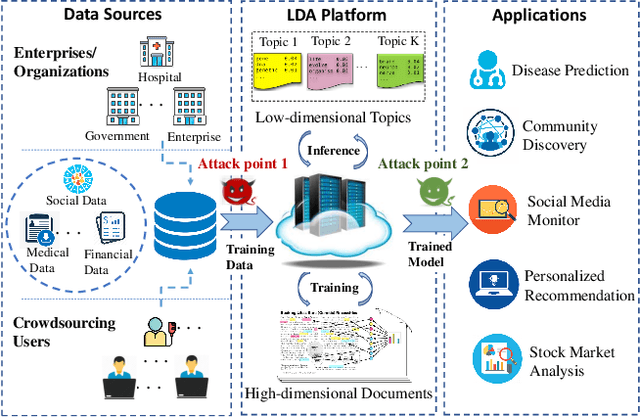
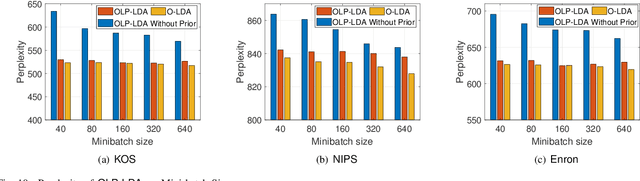
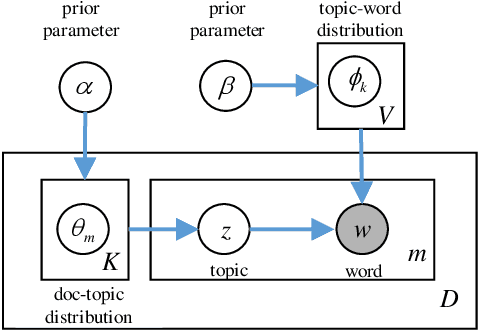
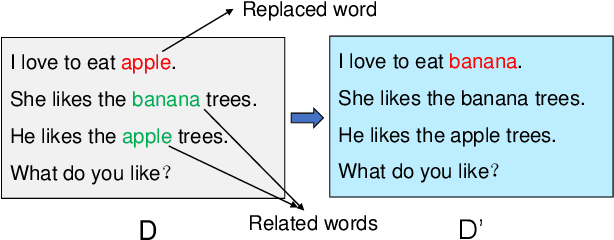
Latent Dirichlet Allocation (LDA) is a popular topic modeling technique for hidden semantic discovery of text data and serves as a fundamental tool for text analysis in various applications. However, the LDA model as well as the training process of LDA may expose the text information in the training data, thus bringing significant privacy concerns. To address the privacy issue in LDA, we systematically investigate the privacy protection of the main-stream LDA training algorithm based on Collapsed Gibbs Sampling (CGS) and propose several differentially private LDA algorithms for typical training scenarios. In particular, we present the first theoretical analysis on the inherent differential privacy guarantee of CGS based LDA training and further propose a centralized privacy-preserving algorithm (HDP-LDA) that can prevent data inference from the intermediate statistics in the CGS training. Also, we propose a locally private LDA training algorithm (LP-LDA) on crowdsourced data to provide local differential privacy for individual data contributors. Furthermore, we extend LP-LDA to an online version as OLP-LDA to achieve LDA training on locally private mini-batches in a streaming setting. Extensive analysis and experiment results validate both the effectiveness and efficiency of our proposed privacy-preserving LDA training algorithms.
Deep Sentiment Classification and Topic Discovery on Novel Coronavirus or COVID-19 Online Discussions: NLP Using LSTM Recurrent Neural Network Approach
Apr 24, 2020
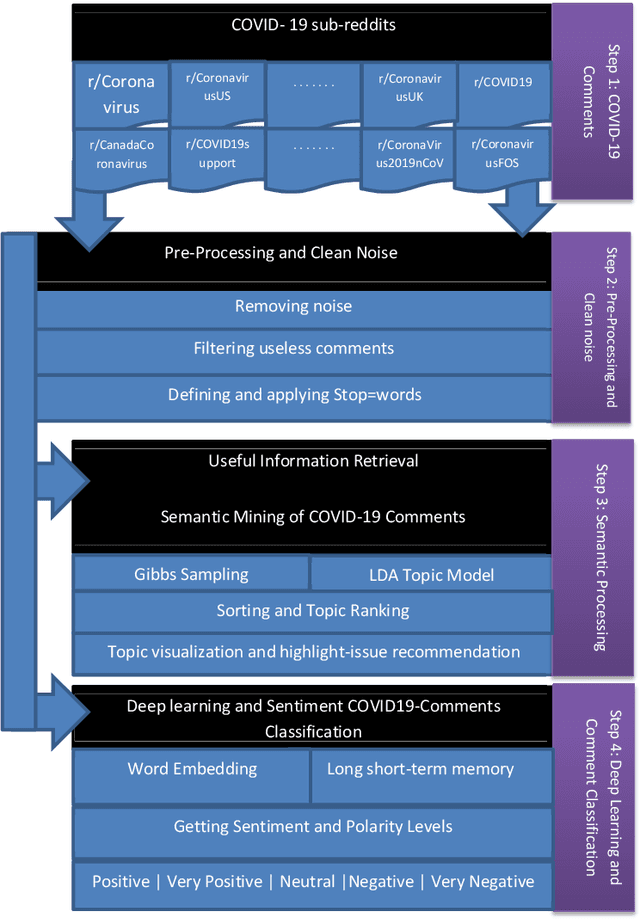
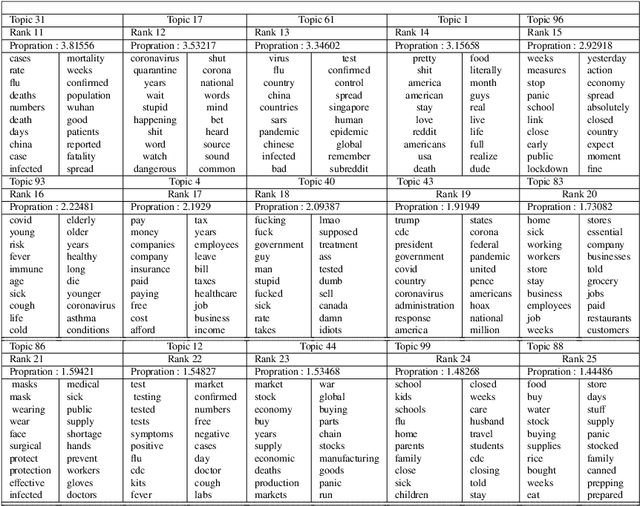
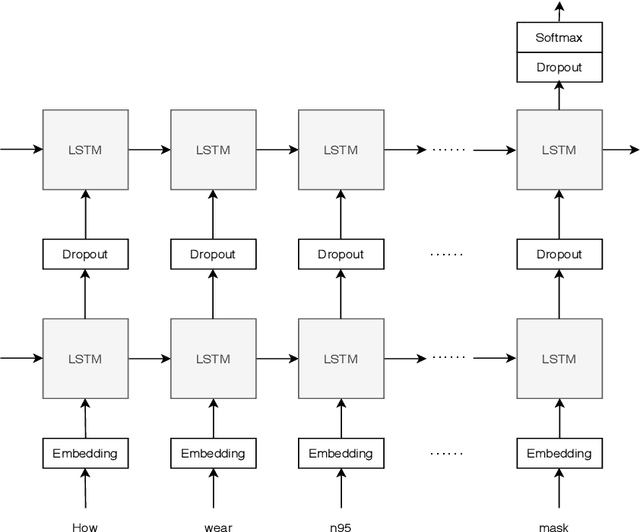
Internet forums and public social media, such as online healthcare forums, provide a convenient channel for users (people/patients) concerned about health issues to discuss and share information with each other. In late December 2019, an outbreak of a novel coronavirus (infection from which results in the disease named COVID-19) was reported, and, due to the rapid spread of the virus in other parts of the world, the World Health Organization declared a state of emergency. In this paper, we used automated extraction of COVID-19 related discussions from social media and a natural language process (NLP) method based on topic modeling to uncover various issues related to COVID-19 from public opinions. Moreover, we also investigate how to use LSTM recurrent neural network for sentiment classification of COVID-19 comments. Our findings shed light on the importance of using public opinions and suitable computational techniques to understand issues surrounding COVID-19 and to guide related decision-making.
Graph-Driven Generative Models for Heterogeneous Multi-Task Learning
Nov 20, 2019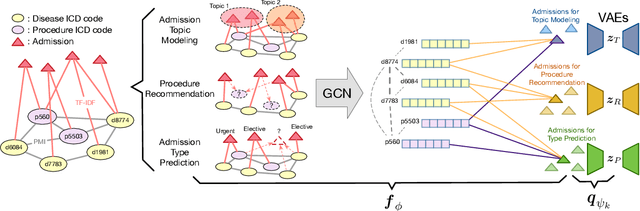

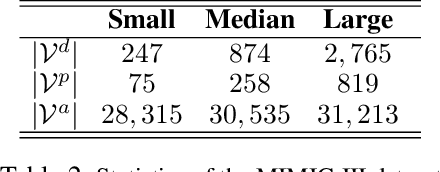

We propose a novel graph-driven generative model, that unifies multiple heterogeneous learning tasks into the same framework. The proposed model is based on the fact that heterogeneous learning tasks, which correspond to different generative processes, often rely on data with a shared graph structure. Accordingly, our model combines a graph convolutional network (GCN) with multiple variational autoencoders, thus embedding the nodes of the graph i.e., samples for the tasks) in a uniform manner while specializing their organization and usage to different tasks. With a focus on healthcare applications (tasks), including clinical topic modeling, procedure recommendation and admission-type prediction, we demonstrate that our method successfully leverages information across different tasks, boosting performance in all tasks and outperforming existing state-of-the-art approaches.