 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4CodeRE: Generative AI for Code Decompilation Analysis and Reverse Engineering
Apr 07, 2026Code decompilation analysis is a fundamental yet challenging task in malware reverse engineering, particularly due to the pervasive use of sophisticated obfuscation techniques. Although recent large language models (LLMs) have shown promise in translating low-level representations into high-level source code, most existing approaches rely on generic code pretraining and lack adaptation to malicious software. We propose LLM4CodeRE, a domain-adaptive LLM framework for bidirectional code reverse engineering that supports both assembly-to-source decompilation and source-to-assembly translation within a unified model. To enable effective task adaptation, we introduce two complementary fine-tuning strategies: (i) a Multi-Adapter approach for task-specific syntactic and semantic alignment, and (ii) a Seq2Seq Unified approach using task-conditioned prefixes to enforce end-to-end generation constraints. Experimental results demonstrate that LLM4CodeRE outperforms existing decompilation tools and general-purpose code models, achieving robust bidirectional generalization.
Automated Malware Family Classification using Weighted Hierarchical Ensembles of Large Language Models
Apr 02, 2026Malware family classification remains a challenging task in automated malware analysis, particularly in real-world settings characterized by obfuscation, packing, and rapidly evolving threats. Existing machine learning and deep learning approaches typically depend on labeled datasets, handcrafted features, supervised training, or dynamic analysis, which limits their scalability and effectiveness in open-world scenarios. This paper presents a zero-label malware family classification framework based on a weighted hierarchical ensemble of pretrained large language models (LLMs). Rather than relying on feature-level learning or model retraining, the proposed approach aggregates decision-level predictions from multiple LLMs with complementary reasoning strengths. Model outputs are weighted using empirically derived macro-F1 scores and organized hierarchically, first resolving coarse-grained malicious behavior before assigning fine-grained malware families. This structure enhances robustness, reduces individual model instability, and aligns with analyst-style reasoning.
LLM Security and Safety: Insights from Homotopy-Inspired Prompt Obfuscation
Jan 20, 2026In this study, we propose a homotopy-inspired prompt obfuscation framework to enhance understanding of security and safety vulnerabilities in Large Language Models (LLMs). By systematically applying carefully engineered prompts, we demonstrate how latent model behaviors can be influenced in unexpected ways. Our experiments encompassed 15,732 prompts, including 10,000 high-priority cases, across LLama, Deepseek, KIMI for code generation, and Claude to verify. The results reveal critical insights into current LLM safeguards, highlighting the need for more robust defense mechanisms, reliable detection strategies, and improved resilience. Importantly, this work provides a principled framework for analyzing and mitigating potential weaknesses, with the goal of advancing safe, responsible, and trustworthy AI technologies.
XGen-Q: An Explainable Domain-Adaptive LLM Framework with Retrieval-Augmented Generation for Software Security
Oct 21, 2025Generative AI and large language models (LLMs) have shown strong capabilities in code understanding, but their use in cybersecurity, particularly for malware detection and analysis, remains limited. Existing detection systems often fail to generalize to obfuscated or previously unseen threats, underscoring the need for more adaptable and explainable models. To address this challenge, we introduce XGen-Q, a domain-adapted LLM built on the Qwen-Coder architecture and pretrained on a large-scale corpus of over one million malware samples, spanning both source and assembly code. XGen-Q uses a multi-stage prompt strategy combined with retrieval-augmented generation (RAG) to deliver reliable malware identification and detailed forensic reporting, even in the presence of complex code obfuscation. To further enhance generalization, we design a training pipeline that systematically exposes the model to diverse obfuscation patterns. Experimental results show that XGen-Q achieves significantly lower perplexity than competitive baselines and exhibits strong performance on novel malware samples, demonstrating the promise of LLM-based approaches for interpretable and robust malware analysis.
SBAN: A Framework \& Multi-Dimensional Dataset for Large Language Model Pre-Training and Software Code Mining
Oct 21, 2025This paper introduces SBAN (Source code, Binary, Assembly, and Natural Language Description), a large-scale, multi-dimensional dataset designed to advance the pre-training and evaluation of large language models (LLMs) for software code analysis. SBAN comprises more than 3 million samples, including 2.9 million benign and 672,000 malware respectively, each represented across four complementary layers: binary code, assembly instructions, natural language descriptions, and source code. This unique multimodal structure enables research on cross-representation learning, semantic understanding of software, and automated malware detection. Beyond security applications, SBAN supports broader tasks such as code translation, code explanation, and other software mining tasks involving heterogeneous data. It is particularly suited for scalable training of deep models, including transformers and other LLM architectures. By bridging low-level machine representations and high-level human semantics, SBAN provides a robust foundation for building intelligent systems that reason about code. We believe that this dataset opens new opportunities for mining software behavior, improving security analytics, and enhancing LLM capabilities in pre-training and fine-tuning tasks for software code mining.
FlexiDataGen: An Adaptive LLM Framework for Dynamic Semantic Dataset Generation in Sensitive Domains
Oct 21, 2025Dataset availability and quality remain critical challenges in machine learning, especially in domains where data are scarce, expensive to acquire, or constrained by privacy regulations. Fields such as healthcare, biomedical research, and cybersecurity frequently encounter high data acquisition costs, limited access to annotated data, and the rarity or sensitivity of key events. These issues-collectively referred to as the dataset challenge-hinder the development of accurate and generalizable machine learning models in such high-stakes domains. To address this, we introduce FlexiDataGen, an adaptive large language model (LLM) framework designed for dynamic semantic dataset generation in sensitive domains. FlexiDataGen autonomously synthesizes rich, semantically coherent, and linguistically diverse datasets tailored to specialized fields. The framework integrates four core components: (1) syntactic-semantic analysis, (2) retrieval-augmented generation, (3) dynamic element injection, and (4) iterative paraphrasing with semantic validation. Together, these components ensure the generation of high-quality, domain-relevant data. Experimental results show that FlexiDataGen effectively alleviates data shortages and annotation bottlenecks, enabling scalable and accurate machine learning model development.
Large Language Model (LLM) for Software Security: Code Analysis, Malware Analysis, Reverse Engineering
Apr 07, 2025



Large Language Models (LLMs) have recently emerged as powerful tools in cybersecurity, offering advanced capabilities in malware detection, generation, and real-time monitoring. Numerous studies have explored their application in cybersecurity, demonstrating their effectiveness in identifying novel malware variants, analyzing malicious code structures, and enhancing automated threat analysis. Several transformer-based architectures and LLM-driven models have been proposed to improve malware analysis, leveraging semantic and structural insights to recognize malicious intent more accurately. This study presents a comprehensive review of LLM-based approaches in malware code analysis, summarizing recent advancements, trends, and methodologies. We examine notable scholarly works to map the research landscape, identify key challenges, and highlight emerging innovations in LLM-driven cybersecurity. Additionally, we emphasize the role of static analysis in malware detection, introduce notable datasets and specialized LLM models, and discuss essential datasets supporting automated malware research. This study serves as a valuable resource for researchers and cybersecurity professionals, offering insights into LLM-powered malware detection and defence strategies while outlining future directions for strengthening cybersecurity resilience.
Semantic Knowledge Discovery and Discussion Mining of Incel Online Community: Topic modeling
Apr 21, 2021
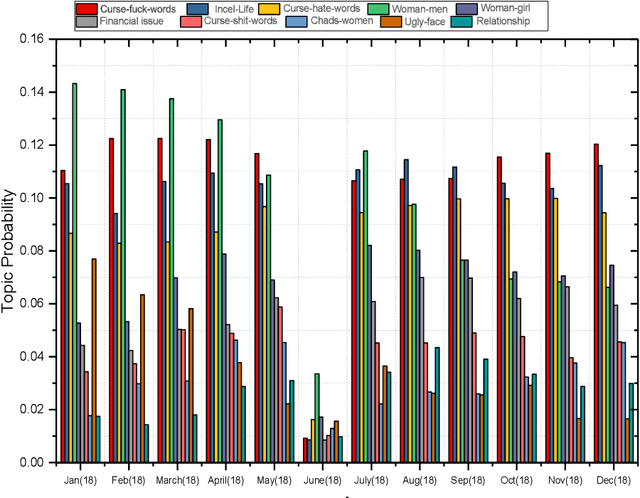
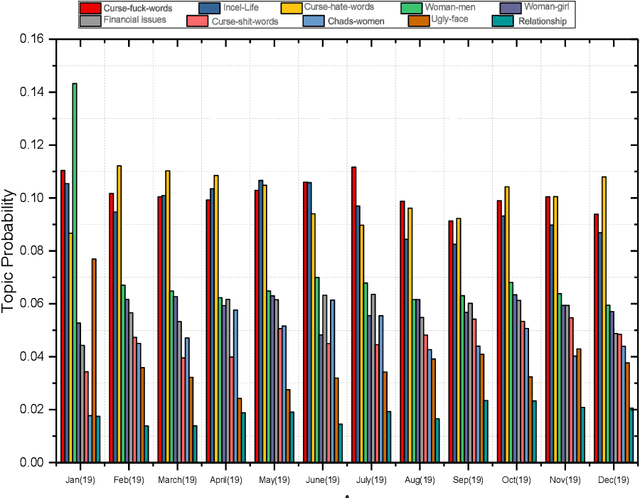
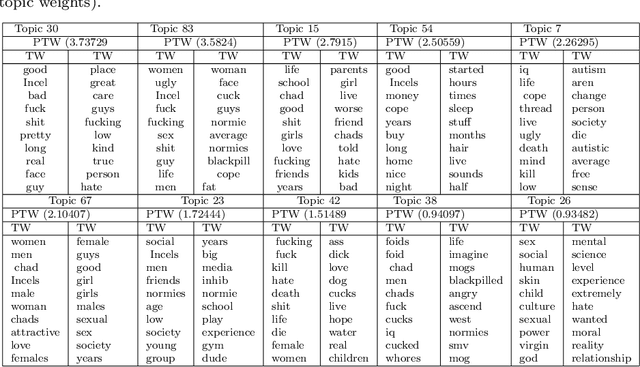
Online forums provide a unique opportunity for online users to share comments and exchange information on a particular topic. Understanding user behaviour is valuable to organizations and has applications for social and security strategies, for instance, identifying user opinions within a community or predicting future behaviour. Discovering the semantic aspects in Incel forums are the main goal of this research; we apply Natural language processing techniques based on topic modeling to latent topic discovery and opinion mining of users from a popular online Incel discussion forum. To prepare the input data for our study, we extracted the comments from Incels.co. The research experiments show that Artificial Intelligence (AI) based on NLP models can be effective for semantic and emotion knowledge discovery and retrieval of useful information from the Incel community. For example, we discovered semantic-related words that describe issues within a large volume of Incel comments, which is difficult with manual methods.
Artificial Intelligence for Emotion-Semantic Trending and People Emotion Detection During COVID-19 Social Isolation
Jan 16, 2021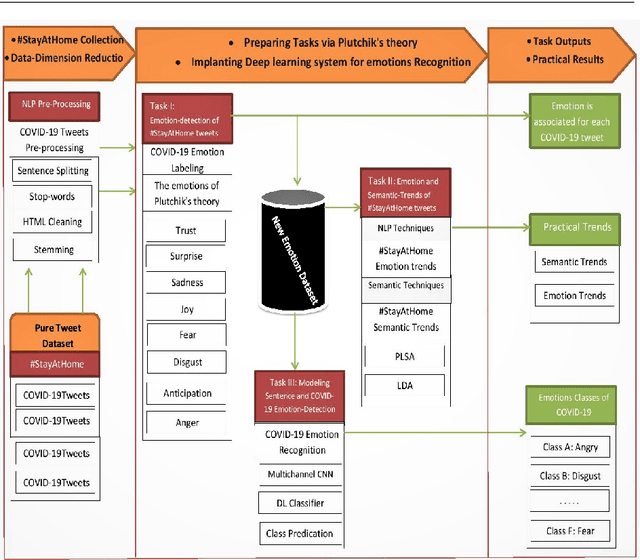

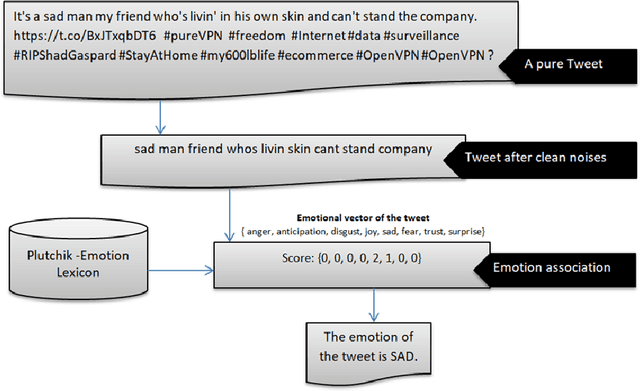

Taking advantage of social media platforms, such as Twitter, this paper provides an effective framework for emotion detection among those who are quarantined. Early detection of emotional feelings and their trends help implement timely intervention strategies. Given the limitations of medical diagnosis of early emotional change signs during the quarantine period, artificial intelligence models provide effective mechanisms in uncovering early signs, symptoms and escalating trends. Novelty of the approach presented herein is a multitask methodological framework of text data processing, implemented as a pipeline for meaningful emotion detection and analysis, based on the Plutchik/Ekman approach to emotion detection and trend detection. We present an evaluation of the framework and a pilot system. Results of confirm the effectiveness of the proposed framework for topic trends and emotion detection of COVID-19 tweets. Our findings revealed Stay-At-Home restrictions result in people expressing on twitter both negative and positive emotional semantics. Semantic trends of safety issues related to staying at home rapidly decreased within the 28 days and also negative feelings related to friends dying and quarantined life increased in some days. These findings have potential to impact public health policy decisions through monitoring trends of emotional feelings of those who are quarantined. The framework presented here has potential to assist in such monitoring by using as an online emotion detection tool kit.
Deep Sentiment Classification and Topic Discovery on Novel Coronavirus or COVID-19 Online Discussions: NLP Using LSTM Recurrent Neural Network Approach
Apr 24, 2020
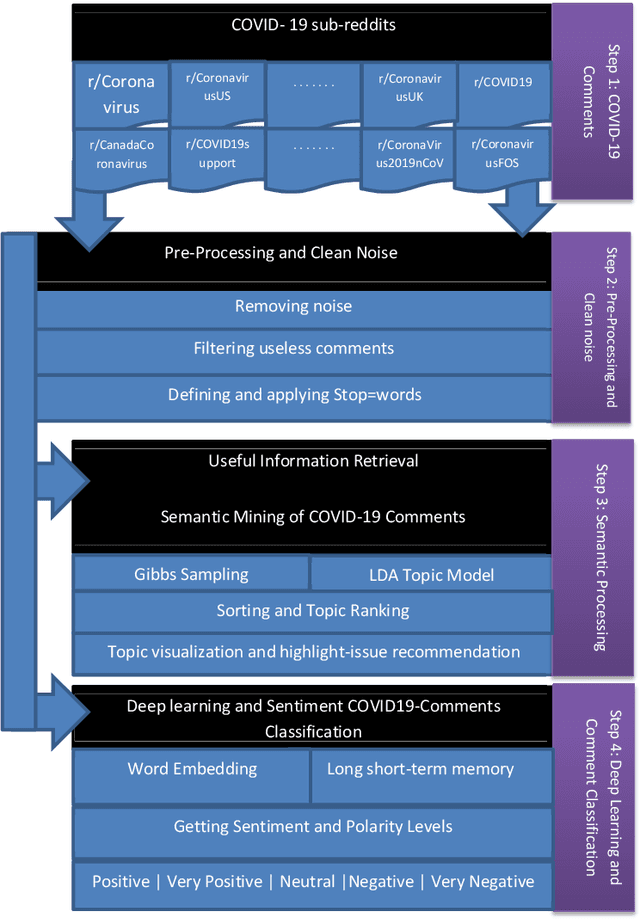
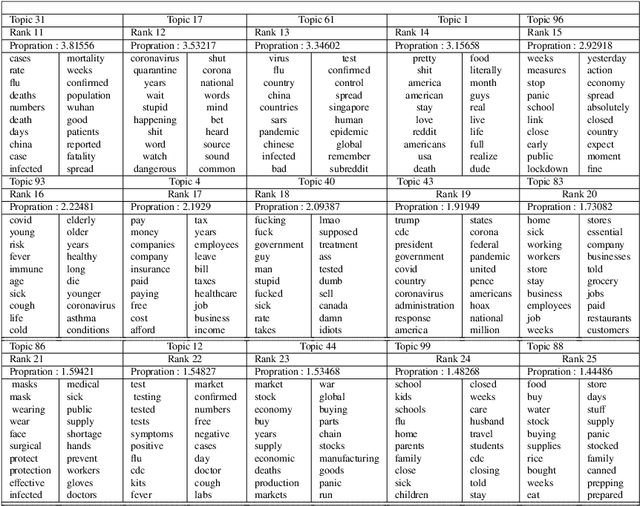
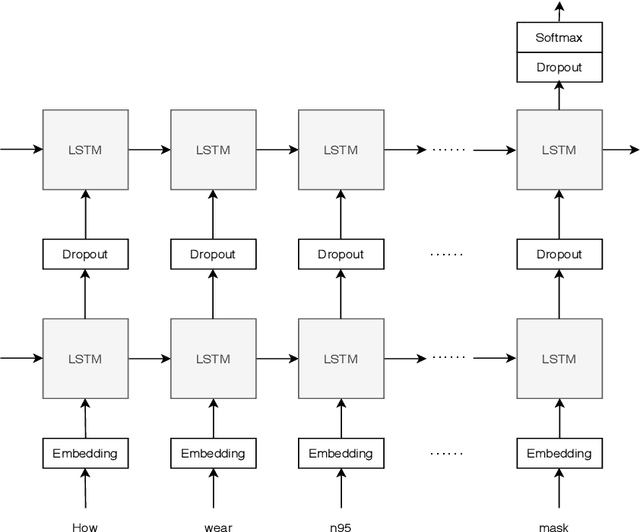
Internet forums and public social media, such as online healthcare forums, provide a convenient channel for users (people/patients) concerned about health issues to discuss and share information with each other. In late December 2019, an outbreak of a novel coronavirus (infection from which results in the disease named COVID-19) was reported, and, due to the rapid spread of the virus in other parts of the world, the World Health Organization declared a state of emergency. In this paper, we used automated extraction of COVID-19 related discussions from social media and a natural language process (NLP) method based on topic modeling to uncover various issues related to COVID-19 from public opinions. Moreover, we also investigate how to use LSTM recurrent neural network for sentiment classification of COVID-19 comments. Our findings shed light on the importance of using public opinions and suitable computational techniques to understand issues surrounding COVID-19 and to guide related decision-making.