 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive Multi-Level Graph Neural Networks for Session-based Recommendation
Nov 06, 2023
Session-based recommendation (SBR) aims to predict the next item at a certain time point based on anonymous user behavior sequences. Existing methods typically model session representation based on simple item transition information. However, since session-based data consists of limited users' short-term interactions, modeling session representation by capturing fixed item transition information from a single dimension suffers from data sparsity. In this paper, we propose a novel contrastive multi-level graph neural networks (CM-GNN) to better exploit complex and high-order item transition information. Specifically, CM-GNN applies local-level graph convolutional network (L-GCN) and global-level network (G-GCN) on the current session and all the sessions respectively, to effectively capture pairwise relations over all the sessions by aggregation strategy. Meanwhile, CM-GNN applies hyper-level graph convolutional network (H-GCN) to capture high-order information among all the item transitions. CM-GNN further introduces an attention-based fusion module to learn pairwise relation-based session representation by fusing the item representations generated by L-GCN and G-GCN. CM-GNN averages the item representations obtained by H-GCN to obtain high-order relation-based session representation. Moreover, to convert the high-order item transition information into the pairwise relation-based session representation, CM-GNN maximizes the mutual information between the representations derived from the fusion module and the average pool layer by contrastive learning paradigm. We conduct extensive experiments on multiple widely used benchmark datasets to validate the efficacy of the proposed method. The encouraging results demonstrate that our proposed method outperforms the state-of-the-art SBR techniques.
DFL-TORO: A One-Shot Demonstration Framework for Learning Time-Optimal Robotic Manufacturing Tasks
Sep 18, 2023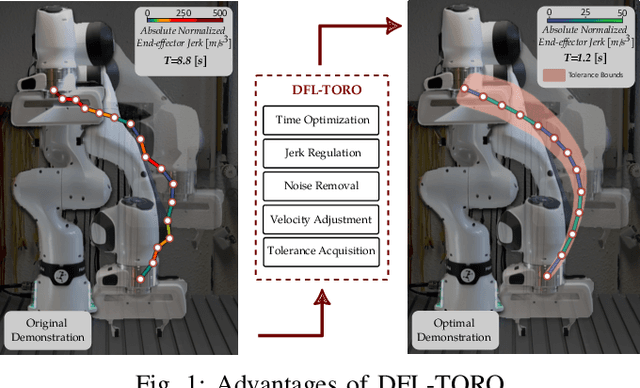
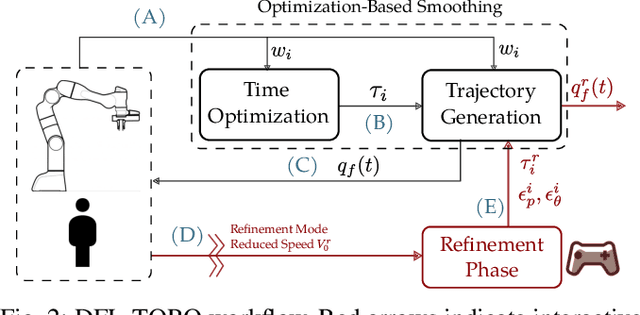
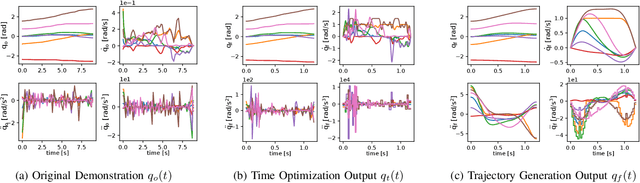
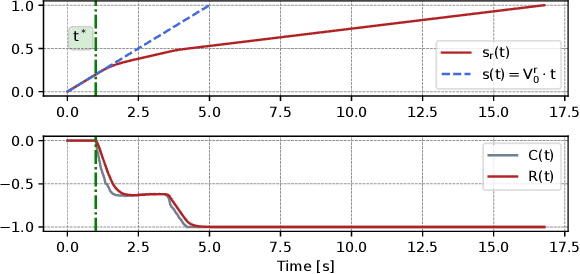
This paper presents DFL-TORO, a novel Demonstration Framework for Learning Time-Optimal Robotic tasks via One-shot kinesthetic demonstration. It aims at optimizing the process of Learning from Demonstration (LfD), applied in the manufacturing sector. As the effectiveness of LfD is challenged by the quality and efficiency of human demonstrations, our approach offers a streamlined method to intuitively capture task requirements from human teachers, by reducing the need for multiple demonstrations. Furthermore, we propose an optimization-based smoothing algorithm that ensures time-optimal and jerk-regulated demonstration trajectories, while also adhering to the robot's kinematic constraints. The result is a significant reduction in noise, thereby boosting the robot's operation efficiency. Evaluations using a Franka Emika Research 3 (FR3) robot for a reaching task further substantiate the efficacy of our framework, highlighting its potential to transform kinesthetic demonstrations in contemporary manufacturing environments.
Boosting Summarization with Normalizing Flows and Aggressive Training
Nov 01, 2023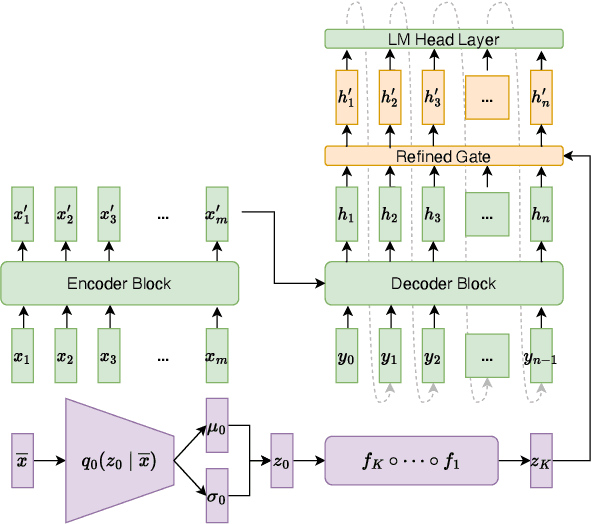
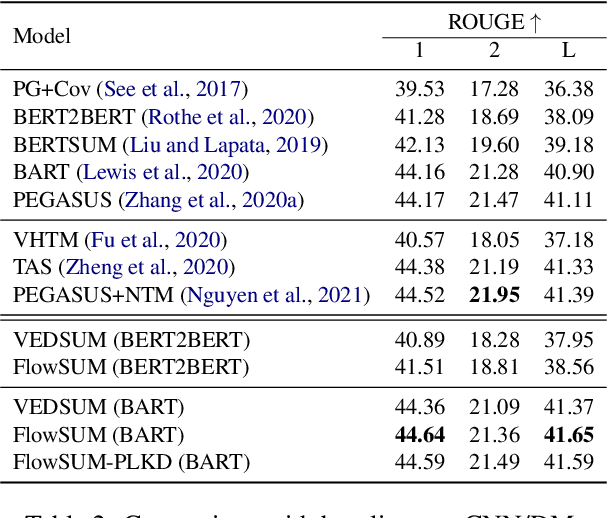
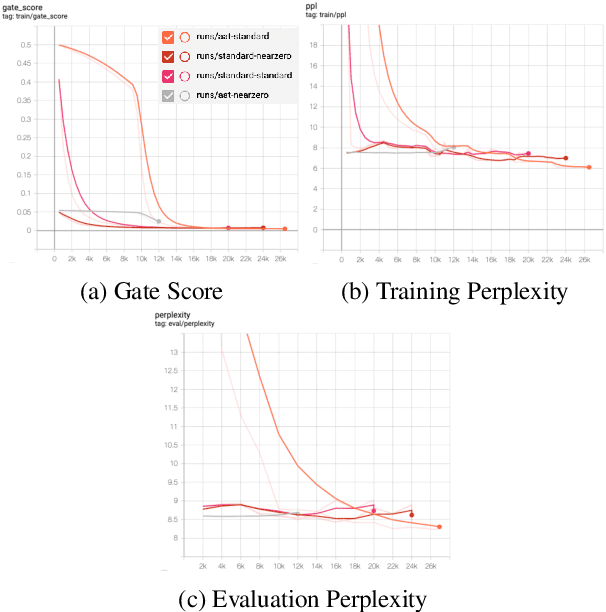
This paper presents FlowSUM, a normalizing flows-based variational encoder-decoder framework for Transformer-based summarization. Our approach tackles two primary challenges in variational summarization: insufficient semantic information in latent representations and posterior collapse during training. To address these challenges, we employ normalizing flows to enable flexible latent posterior modeling, and we propose a controlled alternate aggressive training (CAAT) strategy with an improved gate mechanism. Experimental results show that FlowSUM significantly enhances the quality of generated summaries and unleashes the potential for knowledge distillation with minimal impact on inference time. Furthermore, we investigate the issue of posterior collapse in normalizing flows and analyze how the summary quality is affected by the training strategy, gate initialization, and the type and number of normalizing flows used, offering valuable insights for future research.
PAUMER: Patch Pausing Transformer for Semantic Segmentation
Nov 01, 2023We study the problem of improving the efficiency of segmentation transformers by using disparate amounts of computation for different parts of the image. Our method, PAUMER, accomplishes this by pausing computation for patches that are deemed to not need any more computation before the final decoder. We use the entropy of predictions computed from intermediate activations as the pausing criterion, and find this aligns well with semantics of the image. Our method has a unique advantage that a single network trained with the proposed strategy can be effortlessly adapted at inference to various run-time requirements by modulating its pausing parameters. On two standard segmentation datasets, Cityscapes and ADE20K, we show that our method operates with about a $50\%$ higher throughput with an mIoU drop of about $0.65\%$ and $4.6\%$ respectively.
Learning impartial policies for sequential counterfactual explanations using Deep Reinforcement Learning
Nov 01, 2023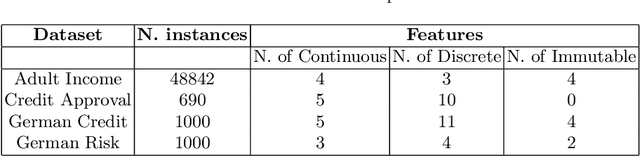
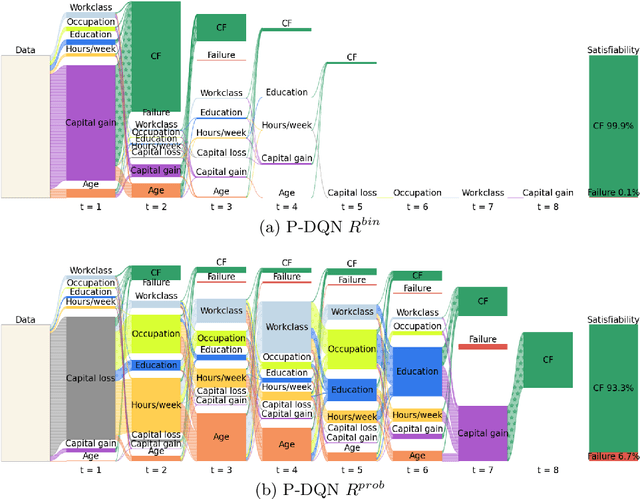
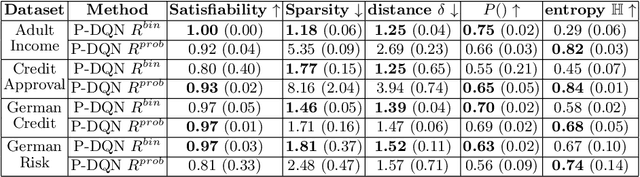
In the field of explainable Artificial Intelligence (XAI), sequential counterfactual (SCF) examples are often used to alter the decision of a trained classifier by implementing a sequence of modifications to the input instance. Although certain test-time algorithms aim to optimize for each new instance individually, recently Reinforcement Learning (RL) methods have been proposed that seek to learn policies for discovering SCFs, thereby enhancing scalability. As is typical in RL, the formulation of the RL problem, including the specification of state space, actions, and rewards, can often be ambiguous. In this work, we identify shortcomings in existing methods that can result in policies with undesired properties, such as a bias towards specific actions. We propose to use the output probabilities of the classifier to create a more informative reward, to mitigate this effect.
Loss Modeling for Multi-Annotator Datasets
Nov 01, 2023Accounting for the opinions of all annotators of a dataset is critical for fairness. However, when annotating large datasets, individual annotators will frequently provide thousands of ratings which can lead to fatigue. Additionally, these annotation processes can occur over multiple days which can lead to an inaccurate representation of an annotator's opinion over time. To combat this, we propose to learn a more accurate representation of diverse opinions by utilizing multitask learning in conjunction with loss-based label correction. We show that using our novel formulation, we can cleanly separate agreeing and disagreeing annotations. Furthermore, we demonstrate that this modification can improve prediction performance in a single or multi-annotator setting. Lastly, we show that this method remains robust to additional label noise that is applied to subjective data.
COSTAR: Improved Temporal Counterfactual Estimation with Self-Supervised Learning
Nov 01, 2023Estimation of temporal counterfactual outcomes from observed history is crucial for decision-making in many domains such as healthcare and e-commerce, particularly when randomized controlled trials (RCTs) suffer from high cost or impracticality. For real-world datasets, modeling time-dependent confounders is challenging due to complex dynamics, long-range dependencies and both past treatments and covariates affecting the future outcomes. In this paper, we introduce COunterfactual Self-supervised TrAnsformeR (COSTAR), a novel approach that integrates self-supervised learning for improved historical representations. The proposed framework combines temporal and feature-wise attention with a component-wise contrastive loss tailored for temporal treatment outcome observations, yielding superior performance in estimation accuracy and generalization to out-of-distribution data compared to existing models, as validated by empirical results on both synthetic and real-world datasets.
One-Shot Strategic Classification Under Unknown Costs
Nov 05, 2023A primary goal in strategic classification is to learn decision rules which are robust to strategic input manipulation. Earlier works assume that strategic responses are known; while some recent works address the important challenge of unknown responses, they exclusively study sequential settings which allow multiple model deployments over time. But there are many domains$\unicode{x2014}$particularly in public policy, a common motivating use-case$\unicode{x2014}$where multiple deployments are unrealistic, or where even a single bad round is undesirable. To address this gap, we initiate the study of strategic classification under unknown responses in the one-shot setting, which requires committing to a single classifier once. Focusing on the users' cost function as the source of uncertainty, we begin by proving that for a broad class of costs, even a small mis-estimation of the true cost can entail arbitrarily low accuracy in the worst case. In light of this, we frame the one-shot task as a minimax problem, with the goal of identifying the classifier with the smallest worst-case risk over an uncertainty set of possible costs. Our main contribution is efficient algorithms for both the full-batch and stochastic settings, which we prove converge (offline) to the minimax optimal solution at the dimension-independent rate of $\tilde{\mathcal{O}}(T^{-\frac{1}{2}})$. Our analysis reveals important structure stemming from the strategic nature of user responses, particularly the importance of dual norm regularization with respect to the cost function.
COPF: Continual Learning Human Preference through Optimal Policy Fitting
Oct 28, 2023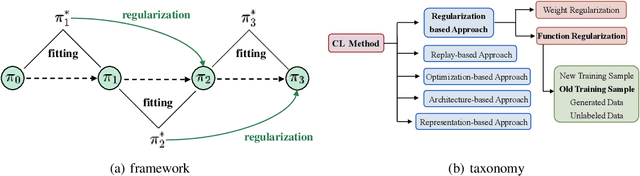
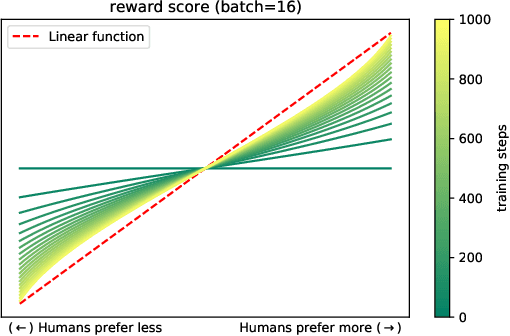

The technique of Reinforcement Learning from Human Feedback (RLHF) is a commonly employed method to improve pre-trained Language Models (LM), enhancing their ability to conform to human preferences. Nevertheless, the current RLHF-based LMs necessitate full retraining each time novel queries or feedback are introduced, which becomes a challenging task because human preferences can vary between different domains or tasks. Retraining LMs poses practical difficulties in many real-world situations due to the significant time and computational resources required, along with concerns related to data privacy. To address this limitation, we propose a new method called Continual Optimal Policy Fitting (COPF), in which we estimate a series of optimal policies using the Monte Carlo method, and then continually fit the policy sequence with the function regularization. COPF involves a single learning phase and doesn't necessitate complex reinforcement learning. Importantly, it shares the capability with RLHF to learn from unlabeled data, making it flexible for continual preference learning. Our experimental results show that COPF outperforms strong Continuous learning (CL) baselines when it comes to consistently aligning with human preferences on different tasks and domains.
LLM4DyG: Can Large Language Models Solve Problems on Dynamic Graphs?
Oct 26, 2023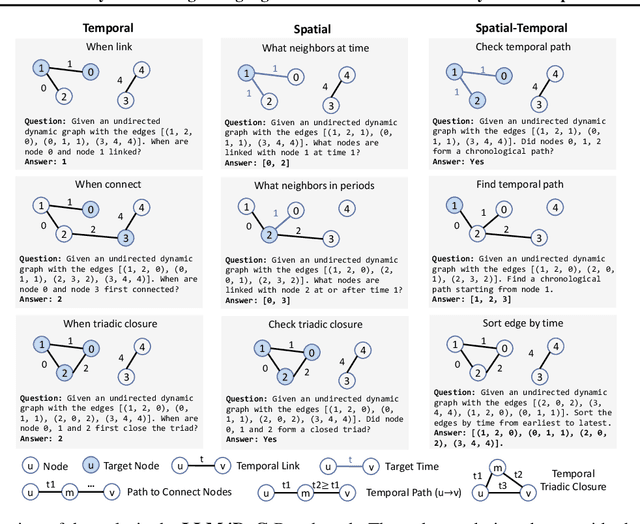
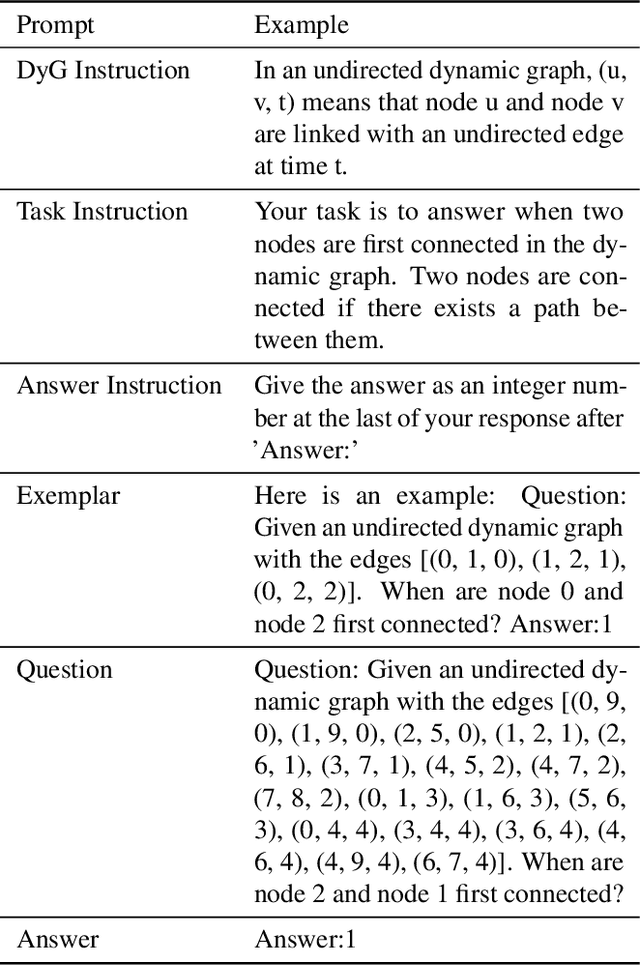

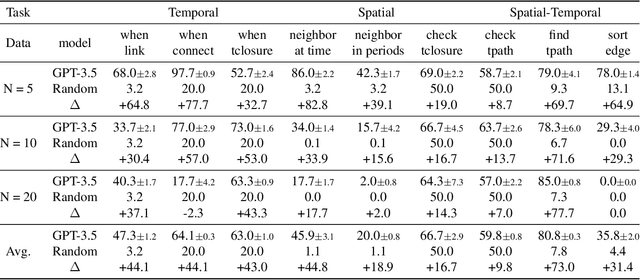
In an era marked by the increasing adoption of Large Language Models (LLMs) for various tasks, there is a growing focus on exploring LLMs' capabilities in handling web data, particularly graph data. Dynamic graphs, which capture temporal network evolution patterns, are ubiquitous in real-world web data. Evaluating LLMs' competence in understanding spatial-temporal information on dynamic graphs is essential for their adoption in web applications, which remains unexplored in the literature. In this paper, we bridge the gap via proposing to evaluate LLMs' spatial-temporal understanding abilities on dynamic graphs, to the best of our knowledge, for the first time. Specifically, we propose the LLM4DyG benchmark, which includes nine specially designed tasks considering the capability evaluation of LLMs from both temporal and spatial dimensions. Then, we conduct extensive experiments to analyze the impacts of different data generators, data statistics, prompting techniques, and LLMs on the model performance. Finally, we propose Disentangled Spatial-Temporal Thoughts (DST2) for LLMs on dynamic graphs to enhance LLMs' spatial-temporal understanding abilities. Our main observations are: 1) LLMs have preliminary spatial-temporal understanding abilities on dynamic graphs, 2) Dynamic graph tasks show increasing difficulties for LLMs as the graph size and density increase, while not sensitive to the time span and data generation mechanism, 3) the proposed DST2 prompting method can help to improve LLMs' spatial-temporal understanding abilities on dynamic graphs for most tasks. The data and codes will be open-sourced at publication time.