 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RESenv: A Realistic Earthquake Simulation Environment based on Unreal Engine
Nov 13, 2023


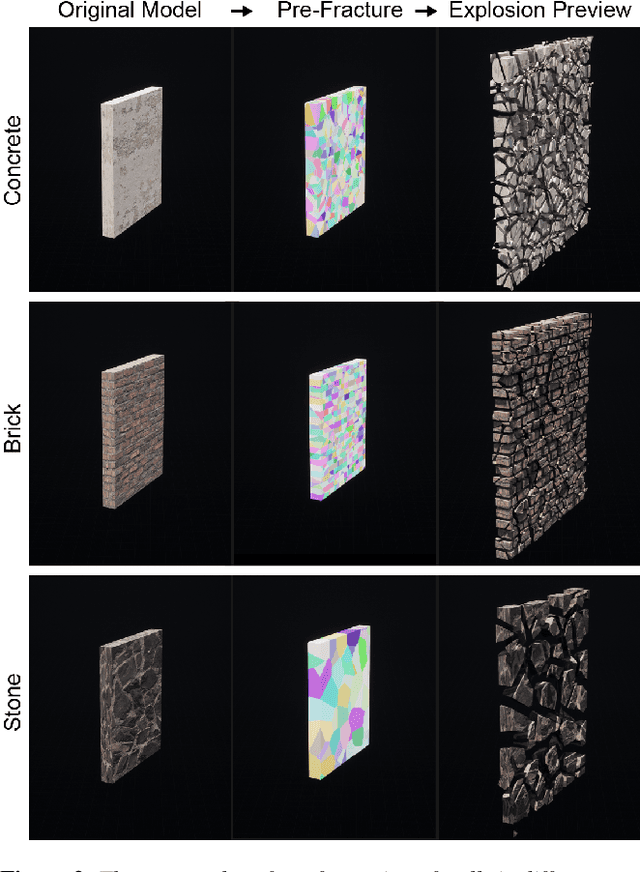
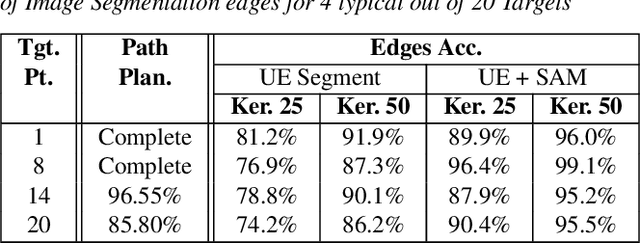
Earthquakes have a significant impact on societies and economies, driving the need for effective search and rescue strategies. With the growing role of AI and robotics in these operations, high-quality synthetic visual data becomes crucial. Current simulation methods, mostly focusing on single building damages, often fail to provide realistic visuals for complex urban settings. To bridge this gap, we introduce an innovative earthquake simulation system using the Chaos Physics System in Unreal Engine. Our approach aims to offer detailed and realistic visual simulations essential for AI and robotic training in rescue missions. By integrating real seismic waveform data, we enhance the authenticity and relevance of our simulations, ensuring they closely mirror real-world earthquake scenarios. Leveraging the advanced capabilities of Unreal Engine, our system delivers not only high-quality visualisations but also real-time dynamic interactions, making the simulated environments more immersive and responsive. By providing advanced renderings, accurate physical interactions, and comprehensive geological movements, our solution outperforms traditional methods in efficiency and user experience. Our simulation environment stands out in its detail and realism, making it a valuable tool for AI tasks such as path planning and image recognition related to earthquake responses. We validate our approach through three AI-based tasks: similarity detection, path planning, and image segmentation.
Robust and Scalable Hyperdimensional Computing With Brain-Like Neural Adaptations
Nov 13, 2023The Internet of Things (IoT) has facilitated many applications utilizing edge-based machine learning (ML) methods to analyze locally collected data. Unfortunately, popular ML algorithms often require intensive computations beyond the capabilities of today's IoT devices. Brain-inspired hyperdimensional computing (HDC) has been introduced to address this issue. However, existing HDCs use static encoders, requiring extremely high dimensionality and hundreds of training iterations to achieve reasonable accuracy. This results in a huge efficiency loss, severely impeding the application of HDCs in IoT systems. We observed that a main cause is that the encoding module of existing HDCs lacks the capability to utilize and adapt to information learned during training. In contrast, neurons in human brains dynamically regenerate all the time and provide more useful functionalities when learning new information. While the goal of HDC is to exploit the high-dimensionality of randomly generated base hypervectors to represent the information as a pattern of neural activity, it remains challenging for existing HDCs to support a similar behavior as brain neural regeneration. In this work, we present dynamic HDC learning frameworks that identify and regenerate undesired dimensions to provide adequate accuracy with significantly lowered dimensionalities, thereby accelerating both the training and inference.
KnowSafe: Combined Knowledge and Data Driven Hazard Mitigation in Artificial Pancreas Systems
Nov 13, 2023Significant progress has been made in anomaly detection and run-time monitoring to improve the safety and security of cyber-physical systems (CPS). However, less attention has been paid to hazard mitigation. This paper proposes a combined knowledge and data driven approach, KnowSafe, for the design of safety engines that can predict and mitigate safety hazards resulting from safety-critical malicious attacks or accidental faults targeting a CPS controller. We integrate domain-specific knowledge of safety constraints and context-specific mitigation actions with machine learning (ML) techniques to estimate system trajectories in the far and near future, infer potential hazards, and generate optimal corrective actions to keep the system safe. Experimental evaluation on two realistic closed-loop testbeds for artificial pancreas systems (APS) and a real-world clinical trial dataset for diabetes treatment demonstrates that KnowSafe outperforms the state-of-the-art by achieving higher accuracy in predicting system state trajectories and potential hazards, a low false positive rate, and no false negatives. It also maintains the safe operation of the simulated APS despite faults or attacks without introducing any new hazards, with a hazard mitigation success rate of 92.8%, which is at least 76% higher than solely rule-based (50.9%) and data-driven (52.7%) methods.
On Measuring Faithfulness of Natural Language Explanations
Nov 13, 2023Large language models (LLMs) can explain their own predictions, through post-hoc or Chain-of-Thought (CoT) explanations. However the LLM could make up reasonably sounding explanations that are unfaithful to its underlying reasoning. Recent work has designed tests that aim to judge the faithfulness of either post-hoc or CoT explanations. In this paper we argue that existing faithfulness tests are not actually measuring faithfulness in terms of the models' inner workings, but only evaluate their self-consistency on the output level. The aims of our work are two-fold. i) We aim to clarify the status of existing faithfulness tests in terms of model explainability, characterising them as self-consistency tests instead. This assessment we underline by constructing a Comparative Consistency Bank for self-consistency tests that for the first time compares existing tests on a common suite of 11 open-source LLMs and 5 datasets -- including ii) our own proposed self-consistency measure CC-SHAP. CC-SHAP is a new fine-grained measure (not test) of LLM self-consistency that compares a model's input contributions to answer prediction and generated explanation. With CC-SHAP, we aim to take a step further towards measuring faithfulness with a more interpretable and fine-grained method. Code available at \url{https://github.com/Heidelberg-NLP/CC-SHAP}
MemDA: Forecasting Urban Time Series with Memory-based Drift Adaptation
Sep 25, 2023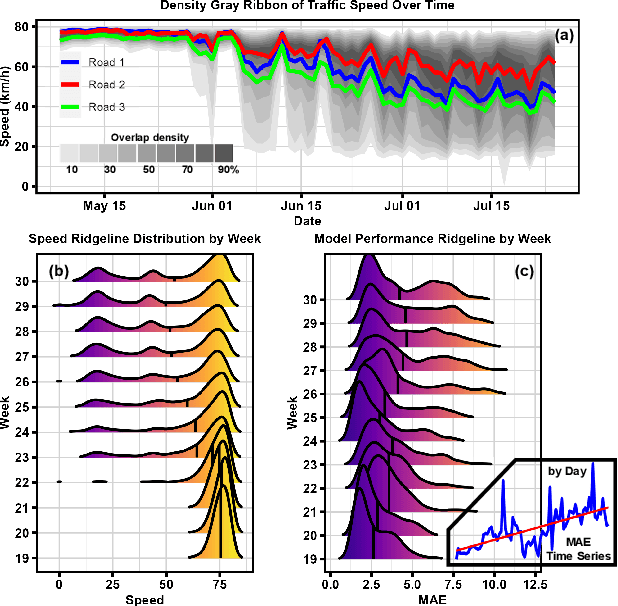
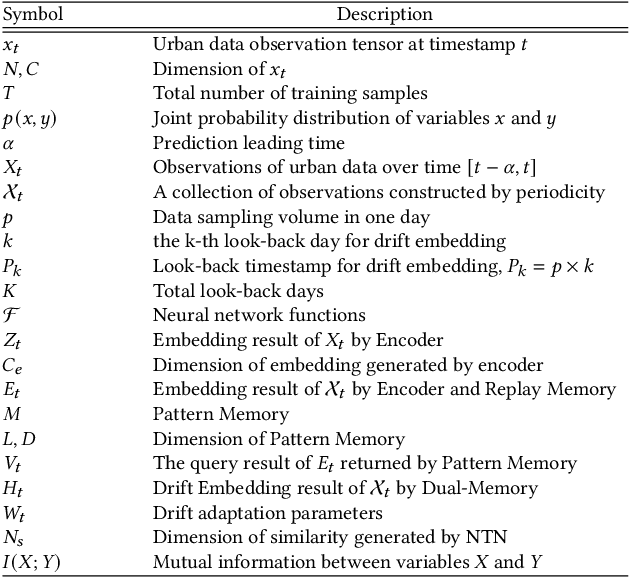
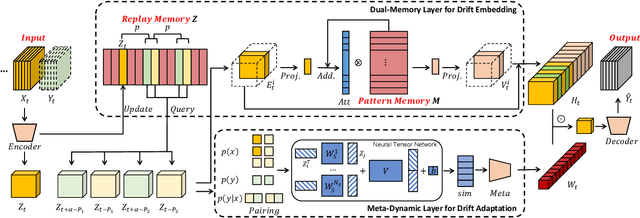
Urban time series data forecasting featuring significant contributions to sustainable development is widely studied as an essential task of the smart city. However, with the dramatic and rapid changes in the world environment, the assumption that data obey Independent Identically Distribution is undermined by the subsequent changes in data distribution, known as concept drift, leading to weak replicability and transferability of the model over unseen data. To address the issue, previous approaches typically retrain the model, forcing it to fit the most recent observed data. However, retraining is problematic in that it leads to model lag, consumption of resources, and model re-invalidation, causing the drift problem to be not well solved in realistic scenarios. In this study, we propose a new urban time series prediction model for the concept drift problem, which encodes the drift by considering the periodicity in the data and makes on-the-fly adjustments to the model based on the drift using a meta-dynamic network. Experiments on real-world datasets show that our design significantly outperforms state-of-the-art methods and can be well generalized to existing prediction backbones by reducing their sensitivity to distribution changes.
RigLSTM: Recurrent Independent Grid LSTM for Generalizable Sequence Learning
Nov 03, 2023Sequential processes in real-world often carry a combination of simple subsystems that interact with each other in certain forms. Learning such a modular structure can often improve the robustness against environmental changes. In this paper, we propose recurrent independent Grid LSTM (RigLSTM), composed of a group of independent LSTM cells that cooperate with each other, for exploiting the underlying modular structure of the target task. Our model adopts cell selection, input feature selection, hidden state selection, and soft state updating to achieve a better generalization ability on the basis of the recent Grid LSTM for the tasks where some factors differ between training and evaluation. Specifically, at each time step, only a fraction of cells are activated, and the activated cells select relevant inputs and cells to communicate with. At the end of one time step, the hidden states of the activated cells are updated by considering the relevance between the inputs and the hidden states from the last and current time steps. Extensive experiments on diversified sequential modeling tasks are conducted to show the superior generalization ability when there exist changes in the testing environment. Source code is available at \url{https://github.com/ziyuwwang/rig-lstm}.
Time-Series Classification in Smart Manufacturing Systems: An Experimental Evaluation of State-of-the-Art Machine Learning Algorithms
Oct 04, 2023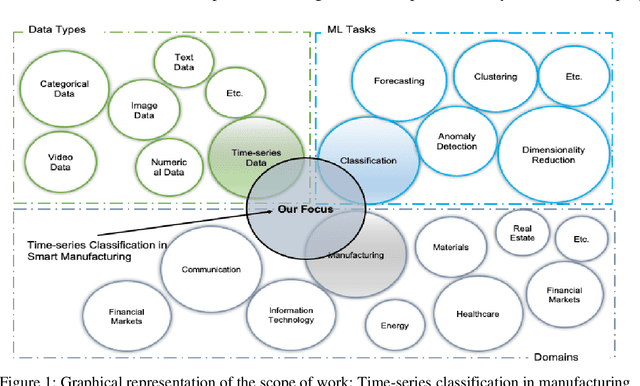

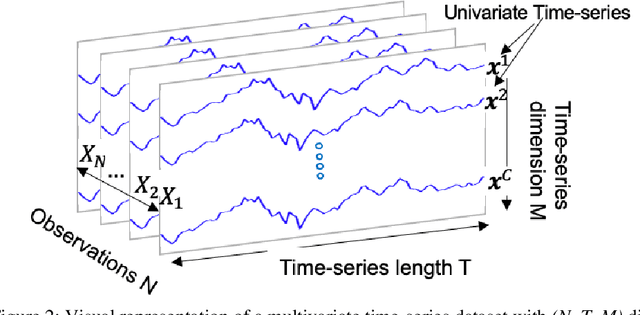
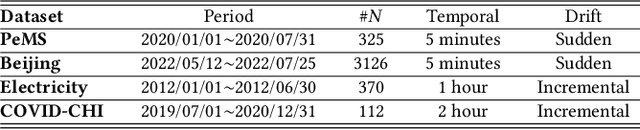
Manufacturing is gathering extensive amounts of diverse data, thanks to the growing number of sensors and rapid advances in sensing technologies. Among the various data types available in SMS settings, time-series data plays a pivotal role. Hence, TSC emerges is crucial in this domain. The objective of this study is to fill this gap by providing a rigorous experimental evaluation of the SoTA ML and DL algorithms for TSC tasks in manufacturing and industrial settings. We first explored and compiled a comprehensive list of more than 92 SoTA algorithms from both TSC and manufacturing literature. Following, we selected the 36 most representative algorithms from this list. To evaluate their performance across various manufacturing classification tasks, we curated a set of 22 manufacturing datasets, representative of different characteristics that cover diverse manufacturing problems. Subsequently, we implemented and evaluated the algorithms on the manufacturing benchmark datasets, and analyzed the results for each dataset. Based on the results, ResNet, DrCIF, InceptionTime, and ARSENAL are the top-performing algorithms, boasting an average accuracy of over 96.6% across all 22 manufacturing TSC datasets. These findings underscore the robustness, efficiency, scalability, and effectiveness of convolutional kernels in capturing temporal features in time-series data, as three out of the top four performing algorithms leverage these kernels for feature extraction. Additionally, LSTM, BiLSTM, and TS-LSTM algorithms deserve recognition for their effectiveness in capturing features within time-series data using RNN-based structures.
DEYOv3: DETR with YOLO for Real-time Object Detection
Sep 22, 2023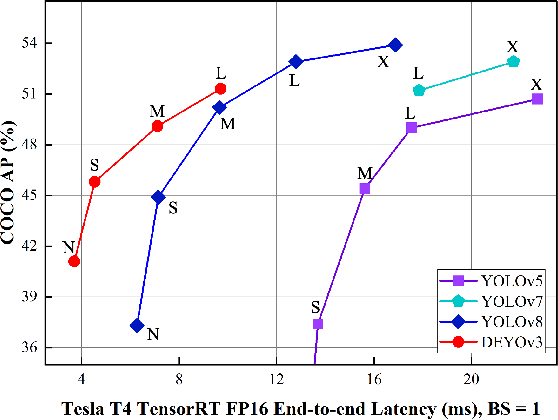
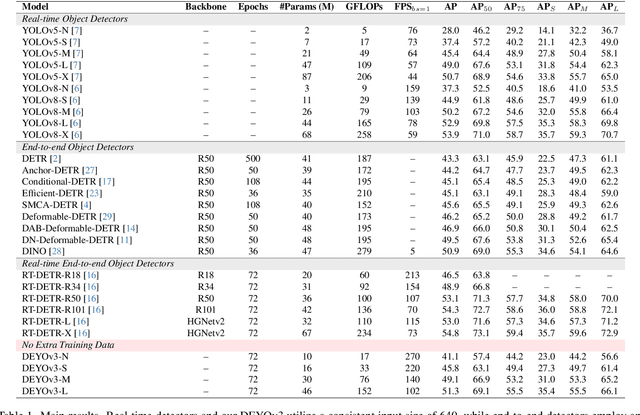


Recently, end-to-end object detectors have gained significant attention from the research community due to their outstanding performance. However, DETR typically relies on supervised pretraining of the backbone on ImageNet, which limits the practical application of DETR and the design of the backbone, affecting the model's potential generalization ability. In this paper, we propose a new training method called step-by-step training. Specifically, in the first stage, the one-to-many pre-trained YOLO detector is used to initialize the end-to-end detector. In the second stage, the backbone and encoder are consistent with the DETR-like model, but only the detector needs to be trained from scratch. Due to this training method, the object detector does not need the additional dataset (ImageNet) to train the backbone, which makes the design of the backbone more flexible and dramatically reduces the training cost of the detector, which is helpful for the practical application of the object detector. At the same time, compared with the DETR-like model, the step-by-step training method can achieve higher accuracy than the traditional training method of the DETR-like model. With the aid of this novel training method, we propose a brand-new end-to-end real-time object detection model called DEYOv3. DEYOv3-N achieves 41.1% on COCO val2017 and 270 FPS on T4 GPU, while DEYOv3-L achieves 51.3% AP and 102 FPS. Without the use of additional training data, DEYOv3 surpasses all existing real-time object detectors in terms of both speed and accuracy. It is worth noting that for models of N, S, and M scales, the training on the COCO dataset can be completed using a single 24GB RTX3090 GPU. Code will be released at https://github.com/ouyanghaodong/DEYOv3.
Multi-Sensor Terrestrial SLAM for Real-Time, Large-Scale, and GNSS-Interrupted Forest Mapping
Oct 02, 2023Forests, as critical components of our ecosystem, demand effective monitoring and management. However, conducting real-time forest inventory in large-scale and GNSS-interrupted forest environments has long been a formidable challenge. In this paper, we present a novel solution that leverages robotics and sensor-fusion technologies to overcome these challenges and enable real-time forest inventory with higher accuracy and efficiency. The proposed solution consists of a new SLAM algorithm to create an accurate 3D map of large-scale forest stands with detailed estimation about the number of trees and the corresponding DBH, solely with the consecutive scans of a 3D lidar and an imu. This method utilized a hierarchical unsupervised clustering algorithm to detect the trees and measure the DBH from the lidar point cloud. The algorithm can run simultaneously as the data is being recorded or afterwards on the recorded dataset. Furthermore, due to the proposed fast feature extraction and transform estimation modules, the recorded data can be fed to the SLAM with higher frequency than common SLAM algorithms. The performance of the proposed solution was tested through filed data collection with hand-held sensor platform as well as a mobile forestry robot. The accuracy of the results was also compared to the state-of-the-art SLAM solutions.
DUBLINE: A Deep Unfolding Network for B-line Detection in Lung Ultrasound Images
Nov 11, 2023In the context of lung ultrasound, the detection of B-lines, which are indicative of interstitial lung disease and pulmonary edema, plays a pivotal role in clinical diagnosis. Current methods still rely on visual inspection by experts. Vision-based automatic B-line detection methods have been developed, but their performance has yet to improve in terms of both accuracy and computational speed. This paper presents a novel approach to posing B-line detection as an inverse problem via deep unfolding of the Alternating Direction Method of Multipliers (ADMM). It tackles the challenges of data labelling and model training in lung ultrasound image analysis by harnessing the capabilities of deep neural networks and model-based methods. Our objective is to substantially enhance diagnostic accuracy while ensuring efficient real-time capabilities. The results show that the proposed method runs more than 90 times faster than the traditional model-based method and achieves an F1 score that is 10.6% higher.