 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Machine learning-based decentralized TDMA for VLC IoT networks
Nov 27, 2023
In this paper, a machine learning-based decentralized time division multiple access (TDMA) algorithm for visible light communication (VLC) Internet of Things (IoT) networks is proposed. The proposed algorithm is based on Q-learning, a reinforcement learning algorithm. This paper considers a decentralized condition in which there is no coordinator node for sending synchronization frames and assigning transmission time slots to other nodes. The proposed algorithm uses a decentralized manner for synchronization, and each node uses the Q-learning algorithm to find the optimal transmission time slot for sending data without collisions. The proposed algorithm is implemented on a VLC hardware system, which had been designed and implemented in our laboratory. Average reward, convergence time, goodput, average delay, and data packet size are evaluated parameters. The results show that the proposed algorithm converges quickly and provides collision-free decentralized TDMA for the network. The proposed algorithm is compared with carrier-sense multiple access with collision avoidance (CSMA/CA) algorithm as a potential selection for decentralized VLC IoT networks. The results show that the proposed algorithm provides up to 61% more goodput and up to 49% less average delay than CSMA/CA.
Counterfactual Explanations for Time Series Forecasting
Oct 12, 2023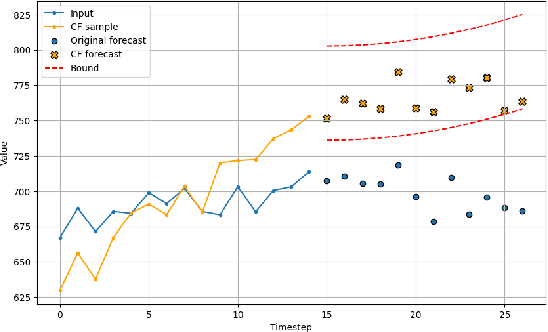
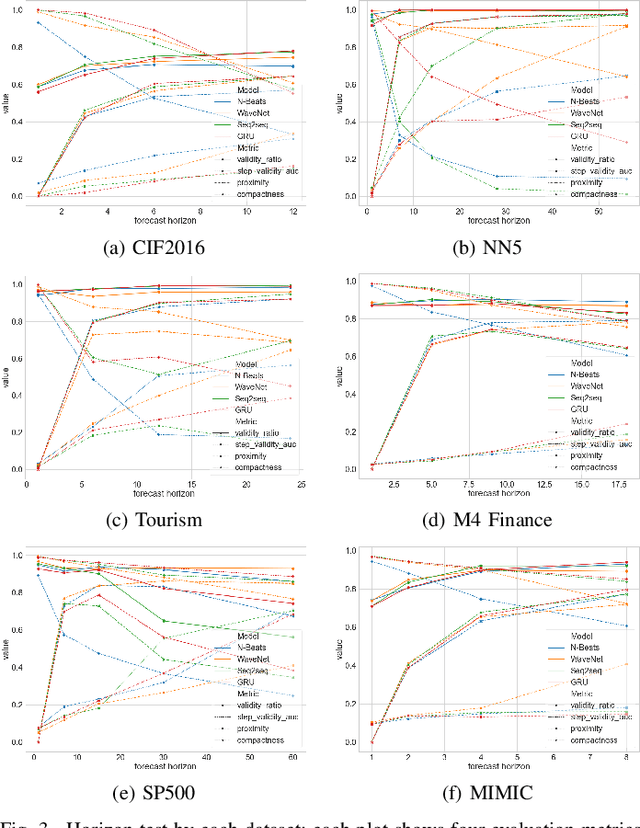
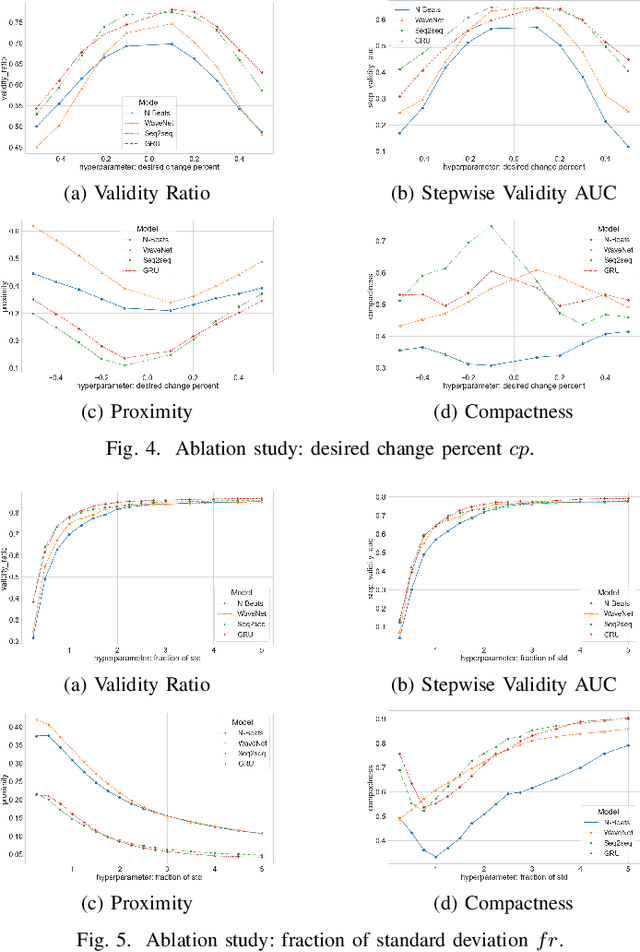
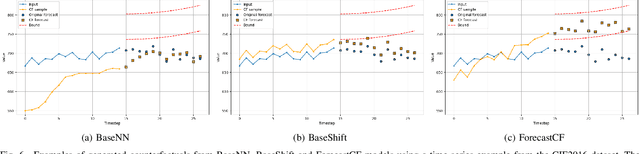
Among recent developments in time series forecasting methods, deep forecasting models have gained popularity as they can utilize hidden feature patterns in time series to improve forecasting performance. Nevertheless, the majority of current deep forecasting models are opaque, hence making it challenging to interpret the results. While counterfactual explanations have been extensively employed as a post-hoc approach for explaining classification models, their application to forecasting models still remains underexplored. In this paper, we formulate the novel problem of counterfactual generation for time series forecasting, and propose an algorithm, called ForecastCF, that solves the problem by applying gradient-based perturbations to the original time series. ForecastCF guides the perturbations by applying constraints to the forecasted values to obtain desired prediction outcomes. We experimentally evaluate ForecastCF using four state-of-the-art deep model architectures and compare to two baselines. Our results show that ForecastCF outperforms the baseline in terms of counterfactual validity and data manifold closeness. Overall, our findings suggest that ForecastCF can generate meaningful and relevant counterfactual explanations for various forecasting tasks.
Virtual Fusion with Contrastive Learning for Single Sensor-based Activity Recognition
Dec 01, 2023Various types of sensors can be used for Human Activity Recognition (HAR), and each of them has different strengths and weaknesses. Sometimes a single sensor cannot fully observe the user's motions from its perspective, which causes wrong predictions. While sensor fusion provides more information for HAR, it comes with many inherent drawbacks like user privacy and acceptance, costly set-up, operation, and maintenance. To deal with this problem, we propose Virtual Fusion - a new method that takes advantage of unlabeled data from multiple time-synchronized sensors during training, but only needs one sensor for inference. Contrastive learning is adopted to exploit the correlation among sensors. Virtual Fusion gives significantly better accuracy than training with the same single sensor, and in some cases, it even surpasses actual fusion using multiple sensors at test time. We also extend this method to a more general version called Actual Fusion within Virtual Fusion (AFVF), which uses a subset of training sensors during inference. Our method achieves state-of-the-art accuracy and F1-score on UCI-HAR and PAMAP2 benchmark datasets. Implementation is available upon request.
Solving the Team Orienteering Problem with Transformers
Dec 01, 2023Route planning for a fleet of vehicles is an important task in applications such as package delivery, surveillance, or transportation. This problem is usually modeled as a Combinatorial Optimization problem named as Team Orienteering Problem. The most popular Team Orienteering Problem solvers are mainly based on either linear programming, which provides accurate solutions by employing a large computation time that grows with the size of the problem, or heuristic methods, which usually find suboptimal solutions in a shorter amount of time. In this paper, a multi-agent route planning system capable of solving the Team Orienteering Problem in a very fast and accurate manner is presented. The proposed system is based on a centralized Transformer neural network that can learn to encode the scenario (modeled as a graph) and the context of the agents to provide fast and accurate solutions. Several experiments have been performed to demonstrate that the presented system can outperform most of the state-of-the-art works in terms of computation speed. In addition, the code is publicly available at http://gti.ssr.upm.es/data.
The Kernel Method for Electrical Resistance Tomography
Dec 08, 2023In this paper we consider the inverse problem of electrical conductivity retrieval starting from boundary measurements, in the framework of Electrical Resistance Tomography (ERT). In particular, the focus is on non-iterative reconstruction algorithms, compatible with real-time applications. In this work a new non-iterative reconstruction method for Electrical Resistance Tomography, termed Kernel Method, is presented. The imaging algorithm deals with the problem of retrieving the shape of one or more anomalies embedded in a known background. The foundation of the proposed method is given by the idea that if there exists a current flux at the boundary (Neumann data) able to produce the same voltage measurements on two different configurations, with and without the anomaly, respectively, then the corresponding electric current density for the problem involving only the background material vanishes in the region occupied by the anomaly. Coherently with this observation, the Kernel Method consists in (i) evaluating a proper current flux at the boundary $g$, (ii) solving one direct problem on a configuration without anomaly and driven by $g$, (iii) reconstructing the anomaly from the spatial plot of the power density as the region in which the power density vanishes. This new tomographic method has a very simple numerical implementation at a very low computational cost. Beside theoretical results and justifications of our method, we present a large number of numerical examples to show the potential of this new algorithm.
neural concatenative singing voice conversion: rethinking concatenation-based approach for one-shot singing voice conversion
Dec 08, 2023Any-to-any singing voice conversion is confronted with a significant challenge of ``timbre leakage'' issue caused by inadequate disentanglement between the content and the speaker timbre. To address this issue, this study introduces a novel neural concatenative singing voice conversion (NeuCoSVC) framework. The NeuCoSVC framework comprises a self-supervised learning (SSL) representation extractor, a neural harmonic signal generator, and a waveform synthesizer. Specifically, the SSL extractor condenses the audio into a sequence of fixed-dimensional SSL features. The harmonic signal generator produces both raw and filtered harmonic signals as the pitch information by leveraging a linear time-varying (LTV) filter. Finally, the audio generator reconstructs the audio waveform based on the SSL features, as well as the harmonic signals and the loudness information. During inference, the system performs voice conversion by substituting source SSL features with their nearest counterparts from a matching pool, which comprises SSL representations extracted from the target audio, while the raw harmonic signals and the loudness are extracted from the source audio and are kept unchanged. Since the utilized SSL features in the conversion stage are directly from the target audio, the proposed framework has great potential to address the ``timbre leakage'' issue caused by previous disentanglement-based approaches. Experimental results confirm that the proposed system delivers much better performance than the speaker embedding approach (disentanglement-based) in the context of one-shot SVC across intra-language, cross-language, and cross-domain evaluations.
User-Aware Prefix-Tuning is a Good Learner for Personalized Image Captioning
Dec 08, 2023

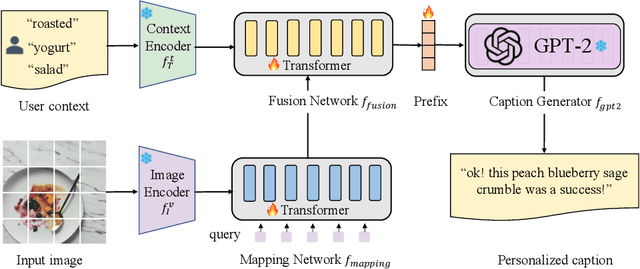
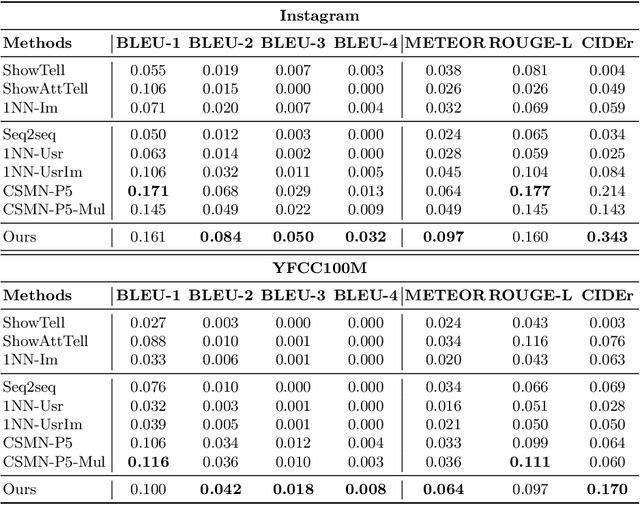
Image captioning bridges the gap between vision and language by automatically generating natural language descriptions for images. Traditional image captioning methods often overlook the preferences and characteristics of users. Personalized image captioning solves this problem by incorporating user prior knowledge into the model, such as writing styles and preferred vocabularies. Most existing methods emphasize the user context fusion process by memory networks or transformers. However, these methods ignore the distinct domains of each dataset. Therefore, they need to update the entire caption model parameters when meeting new samples, which is time-consuming and calculation-intensive. To address this challenge, we propose a novel personalized image captioning framework that leverages user context to consider personality factors. Additionally, our framework utilizes the prefix-tuning paradigm to extract knowledge from a frozen large language model, reducing the gap between different language domains. Specifically, we employ CLIP to extract the visual features of an image and align the semantic space using a query-guided mapping network. By incorporating the transformer layer, we merge the visual features with the user's contextual prior knowledge to generate informative prefixes. Moreover, we employ GPT-2 as the frozen large language model. With a small number of parameters to be trained, our model performs efficiently and effectively. Our model outperforms existing baseline models on Instagram and YFCC100M datasets across five evaluation metrics, demonstrating its superiority, including twofold improvements in metrics such as BLEU-4 and CIDEr.
KwaiAgents: Generalized Information-seeking Agent System with Large Language Models
Dec 08, 2023Driven by curiosity, humans have continually sought to explore and understand the world around them, leading to the invention of various tools to satiate this inquisitiveness. Despite not having the capacity to process and memorize vast amounts of information in their brains, humans excel in critical thinking, planning, reflection, and harnessing available tools to interact with and interpret the world, enabling them to find answers efficiently. The recent advancements in large language models (LLMs) suggest that machines might also possess the aforementioned human-like capabilities, allowing them to exhibit powerful abilities even with a constrained parameter count. In this paper, we introduce KwaiAgents, a generalized information-seeking agent system based on LLMs. Within KwaiAgents, we propose an agent system that employs LLMs as its cognitive core, which is capable of understanding a user's query, behavior guidelines, and referencing external documents. The agent can also update and retrieve information from its internal memory, plan and execute actions using a time-aware search-browse toolkit, and ultimately provide a comprehensive response. We further investigate the system's performance when powered by LLMs less advanced than GPT-4, and introduce the Meta-Agent Tuning (MAT) framework, designed to ensure even an open-sourced 7B or 13B model performs well among many agent systems. We exploit both benchmark and human evaluations to systematically validate these capabilities. Extensive experiments show the superiority of our agent system compared to other autonomous agents and highlight the enhanced generalized agent-abilities of our fine-tuned LLMs.
Towards Clinical Prediction with Transparency: An Explainable AI Approach to Survival Modelling in Residential Aged Care
Dec 08, 2023Background: Accurate survival time estimates aid end-of-life medical decision-making. Objectives: Develop an interpretable survival model for elderly residential aged care residents using advanced machine learning. Setting: A major Australasian residential aged care provider. Participants: Residents aged 65+ admitted for long-term care from July 2017 to August 2023. Sample size: 11,944 residents across 40 facilities. Predictors: Factors include age, gender, health status, co-morbidities, cognitive function, mood, nutrition, mobility, smoking, sleep, skin integrity, and continence. Outcome: Probability of survival post-admission, specifically calibrated for 6-month survival estimates. Statistical Analysis: Tested CoxPH, EN, RR, Lasso, GB, XGB, and RF models in 20 experiments with a 90/10 train/test split. Evaluated accuracy using C-index, Harrell's C-index, dynamic AUROC, IBS, and calibrated ROC. Chose XGB for its performance and calibrated it for 1, 3, 6, and 12-month predictions using Platt scaling. Employed SHAP values to analyze predictor impacts. Results: GB, XGB, and RF models showed the highest C-Index values (0.714, 0.712, 0.712). The optimal XGB model demonstrated a 6-month survival prediction AUROC of 0.746 (95% CI 0.744-0.749). Key mortality predictors include age, male gender, mobility, health status, pressure ulcer risk, and appetite. Conclusions: The study successfully applies machine learning to create a survival model for aged care, aligning with clinical insights on mortality risk factors and enhancing model interpretability and clinical utility through explainable AI.
Learning a Sparse Representation of Barron Functions with the Inverse Scale Space Flow
Dec 05, 2023This paper presents a method for finding a sparse representation of Barron functions. Specifically, given an $L^2$ function $f$, the inverse scale space flow is used to find a sparse measure $\mu$ minimising the $L^2$ loss between the Barron function associated to the measure $\mu$ and the function $f$. The convergence properties of this method are analysed in an ideal setting and in the cases of measurement noise and sampling bias. In an ideal setting the objective decreases strictly monotone in time to a minimizer with $\mathcal{O}(1/t)$, and in the case of measurement noise or sampling bias the optimum is achieved up to a multiplicative or additive constant. This convergence is preserved on discretization of the parameter space, and the minimizers on increasingly fine discretizations converge to the optimum on the full parameter space.