 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
S-RASTER: Contraction Clustering for Evolving Data Streams
Nov 21, 2019

Contraction Clustering (RASTER) is a very fast algorithm for density-based clustering, which requires only a single pass. It can process arbitrary amounts of data in linear time and in constant memory, quickly identifying approximate clusters. It also exhibits good scalability in the presence of multiple CPU cores. Yet, RASTER is limited to batch processing. In contrast, S-RASTER is an adaptation of RASTER to the stream processing paradigm that is able to identify clusters in evolving data streams. This algorithm retains the main benefits of its parent algorithm, i.e. single-pass linear time cost and constant memory requirements for each discrete time step in the sliding window. The sliding window is efficiently pruned, and clustering is still performed in linear time. Like RASTER, S-RASTER trades off an often negligible amount of precision for speed. It is therefore very well suited to real-world scenarios where clustering does not happen continually but only periodically. We describe the algorithm, including a discussion of implementation details.
Self-Supervised Contrastive Learning for Unsupervised Phoneme Segmentation
Aug 06, 2020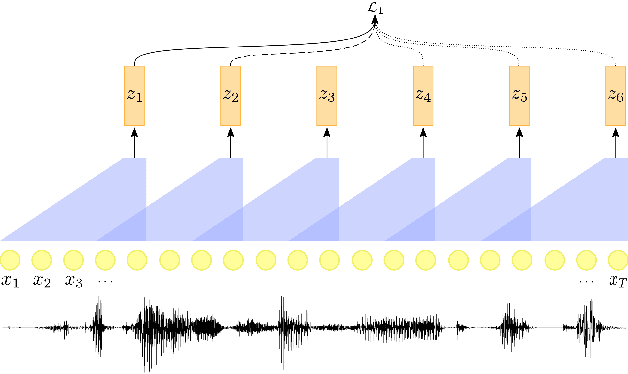
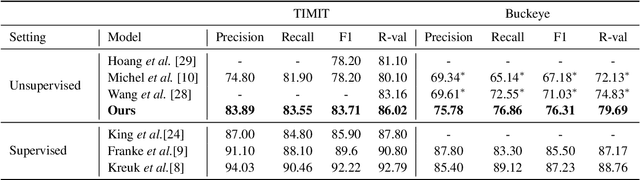
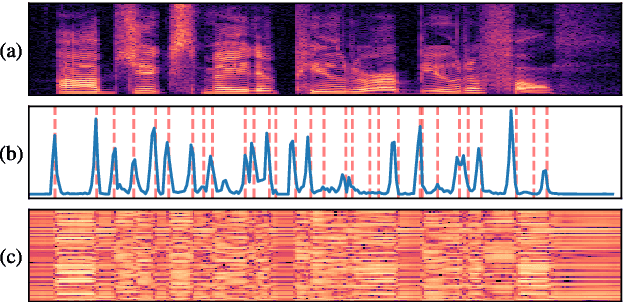
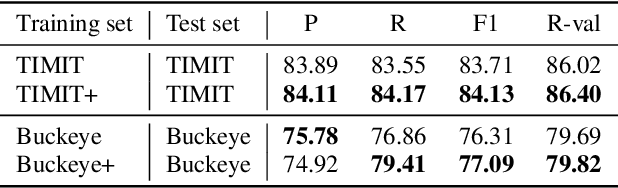
We propose a self-supervised representation learning model for the task of unsupervised phoneme boundary detection. The model is a convolutional neural network that operates directly on the raw waveform. It is optimized to identify spectral changes in the signal using the Noise-Contrastive Estimation principle. At test time, a peak detection algorithm is applied over the model outputs to produce the final boundaries. As such, the proposed model is trained in a fully unsupervised manner with no manual annotations in the form of target boundaries nor phonetic transcriptions. We compare the proposed approach to several unsupervised baselines using both TIMIT and Buckeye corpora. Results suggest that our approach surpasses the baseline models and reaches state-of-the-art performance on both data sets. Furthermore, we experimented with expanding the training set with additional examples from the Librispeech corpus. We evaluated the resulting model on distributions and languages that were not seen during the training phase (English, Hebrew and German) and showed that utilizing additional untranscribed data is beneficial for model performance.
Improving Few-Shot Visual Classification with Unlabelled Examples
Jun 17, 2020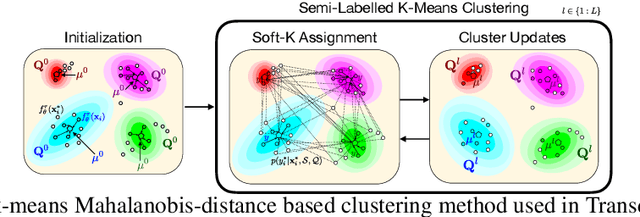
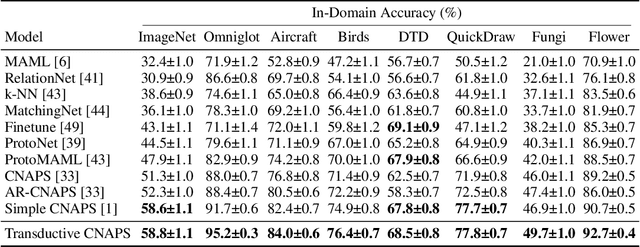
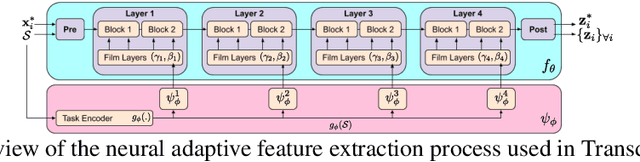
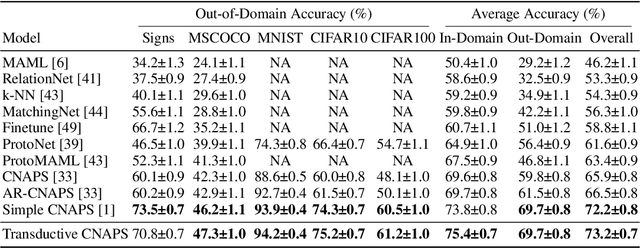
We propose a transductive meta-learning method that uses unlabelled instances to improve few-shot image classification performance. Our approach combines a regularized Mahalanobis-distance-based soft k-means clustering procedure with a state of the art neural adaptive feature extractor to achieve improved test-time classification accuracy using unlabelled data. We evaluate our method on transductive few-shot learning tasks, in which the goal is to jointly predict labels for query (test) examples given a set of support (training) examples. We achieve new state of the art in-domain performance on Meta-Dataset, and improve accuracy on mini- and tiered-ImageNet as compared to other conditional neural adaptive methods that use the same pre-trained feature extractor.
The Surprising Effectiveness of Linear Unsupervised Image-to-Image Translation
Jul 24, 2020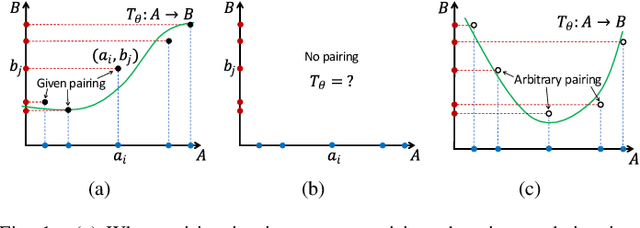



Unsupervised image-to-image translation is an inherently ill-posed problem. Recent methods based on deep encoder-decoder architectures have shown impressive results, but we show that they only succeed due to a strong locality bias, and they fail to learn very simple nonlocal transformations (e.g. mapping upside down faces to upright faces). When the locality bias is removed, the methods are too powerful and may fail to learn simple local transformations. In this paper we introduce linear encoder-decoder architectures for unsupervised image to image translation. We show that learning is much easier and faster with these architectures and yet the results are surprisingly effective. In particular, we show a number of local problems for which the results of the linear methods are comparable to those of state-of-the-art architectures but with a fraction of the training time, and a number of nonlocal problems for which the state-of-the-art fails while linear methods succeed.
An Improved Historical Embedding without Alignment
Oct 19, 2019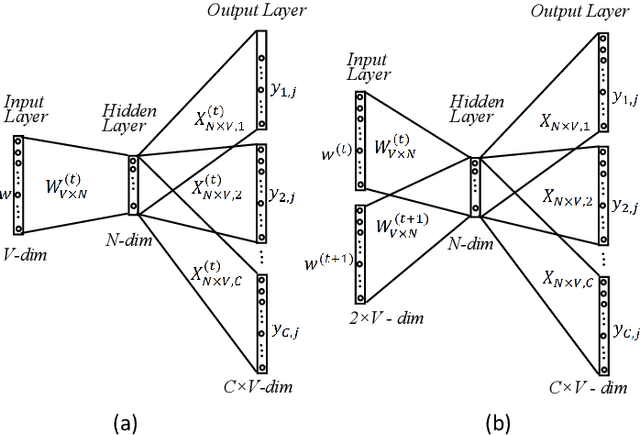
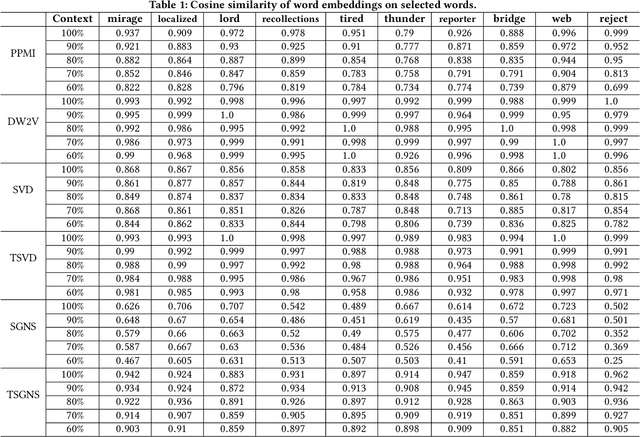
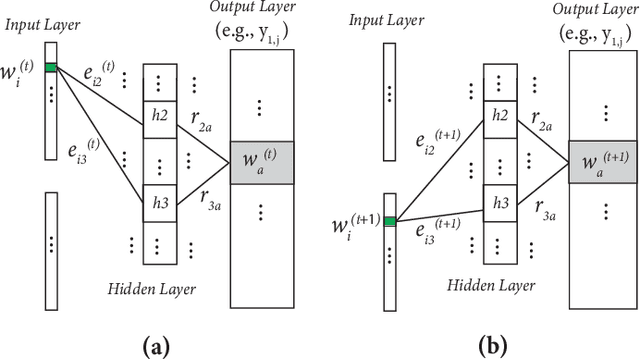
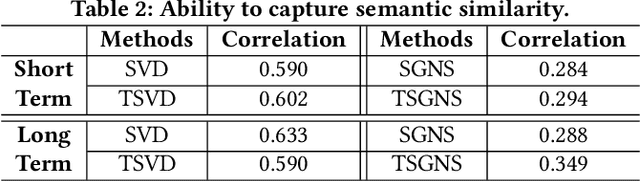
Many words have evolved in meaning as a result of cultural and social change. Understanding such changes is crucial for modelling language and cultural evolution. Low-dimensional embedding methods have shown promise in detecting words' meaning change by encoding them into dense vectors. However, when exploring semantic change of words over time, these methods require the alignment of word embeddings across different time periods. This process is computationally expensive, prohibitively time consuming and suffering from contextual variability. In this paper, we propose a new and scalable method for encoding words from different time periods into one dense vector space. This can greatly improve performance when it comes to identifying words that have changed in meaning over time. We evaluated our method on dataset from Google Books N-gram. Our method outperformed three other popular methods in terms of the number of words correctly identified to have changed in meaning. Additionally, we provide an intuitive visualization of the semantic evolution of some words extracted by our method
Iterative Refinement in the Continuous Space for Non-Autoregressive Neural Machine Translation
Sep 15, 2020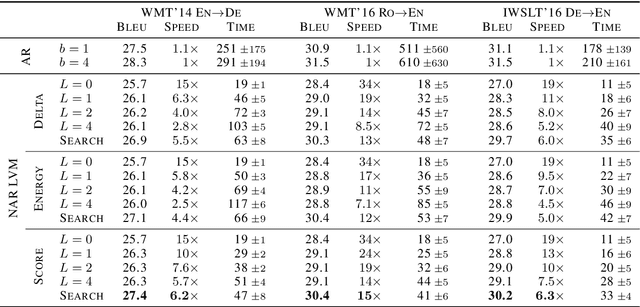
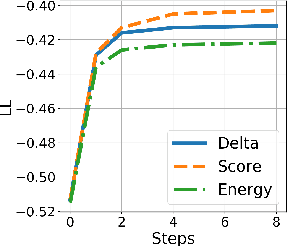
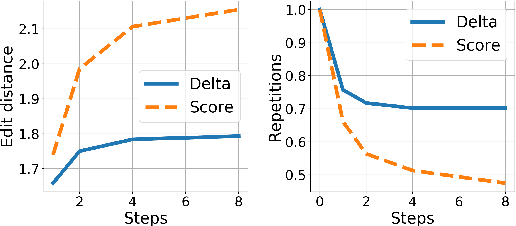

We propose an efficient inference procedure for non-autoregressive machine translation that iteratively refines translation purely in the continuous space. Given a continuous latent variable model for machine translation (Shu et al., 2020), we train an inference network to approximate the gradient of the marginal log probability of the target sentence, using only the latent variable as input. This allows us to use gradient-based optimization to find the target sentence at inference time that approximately maximizes its marginal probability. As each refinement step only involves computation in the latent space of low dimensionality (we use 8 in our experiments), we avoid computational overhead incurred by existing non-autoregressive inference procedures that often refine in token space. We compare our approach to a recently proposed EM-like inference procedure (Shu et al., 2020) that optimizes in a hybrid space, consisting of both discrete and continuous variables. We evaluate our approach on WMT'14 En-De, WMT'16 Ro-En and IWSLT'16 De-En, and observe two advantages over the EM-like inference: (1) it is computationally efficient, i.e. each refinement step is twice as fast, and (2) it is more effective, resulting in higher marginal probabilities and BLEU scores with the same number of refinement steps. On WMT'14 En-De, for instance, our approach is able to decode 6.2 times faster than the autoregressive model with minimal degradation to translation quality (0.9 BLEU).
First U-Net Layers Contain More Domain Specific Information Than The Last Ones
Aug 17, 2020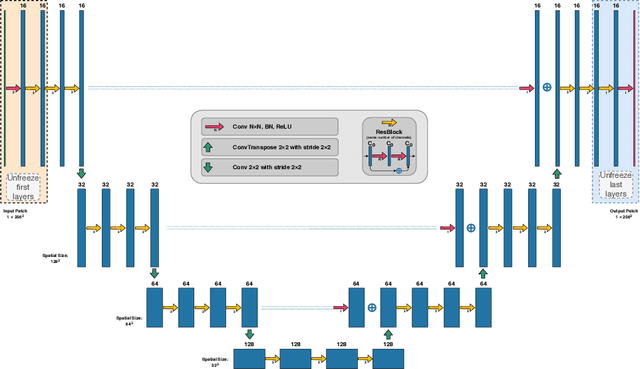
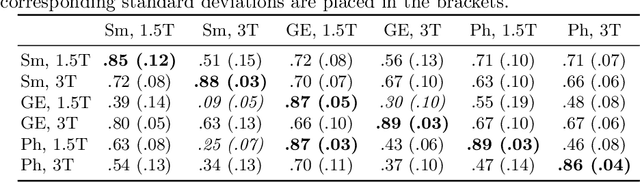
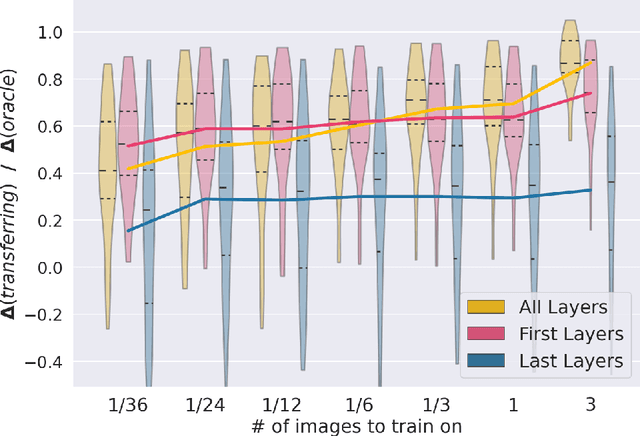
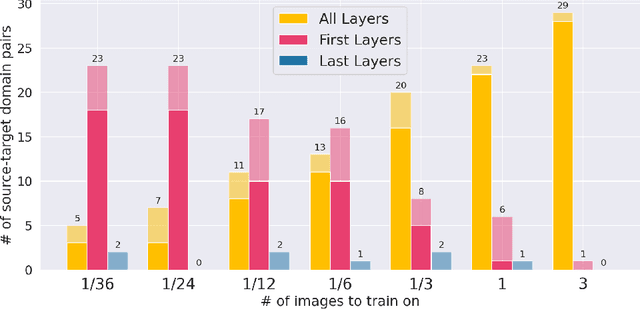
MRI scans appearance significantly depends on scanning protocols and, consequently, the data-collection institution. These variations between clinical sites result in dramatic drops of CNN segmentation quality on unseen domains. Many of the recently proposed MRI domain adaptation methods operate with the last CNN layers to suppress domain shift. At the same time, the core manifestation of MRI variability is a considerable diversity of image intensities. We hypothesize that these differences can be eliminated by modifying the first layers rather than the last ones. To validate this simple idea, we conducted a set of experiments with brain MRI scans from six domains. Our results demonstrate that 1) domain-shift may deteriorate the quality even for a simple brain extraction segmentation task (surface Dice Score drops from 0.85-0.89 even to 0.09); 2) fine-tuning of the first layers significantly outperforms fine-tuning of the last layers in almost all supervised domain adaptation setups. Moreover, fine-tuning of the first layers is a better strategy than fine-tuning of the whole network, if the amount of annotated data from the new domain is strictly limited.
Estimating action plans for smart poultry houses
Aug 17, 2020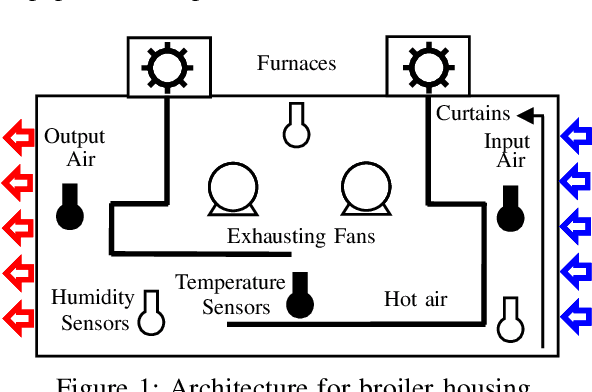
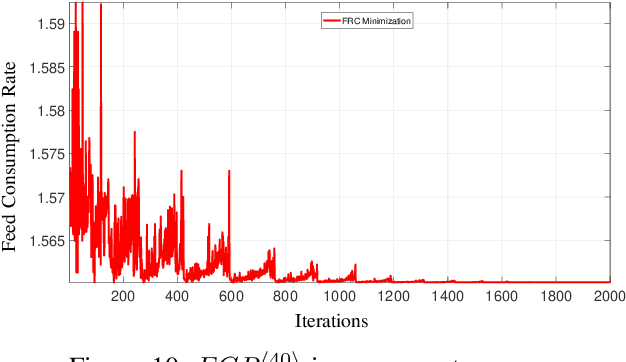
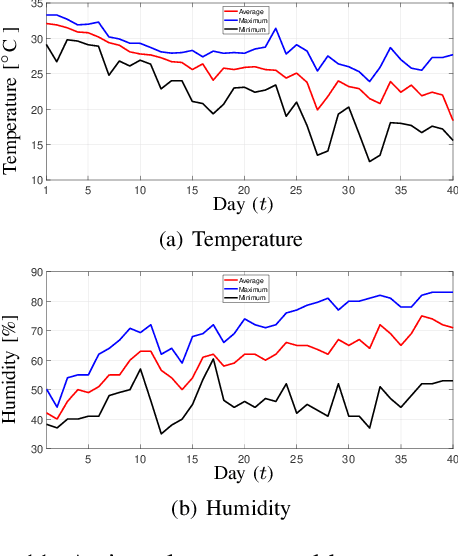
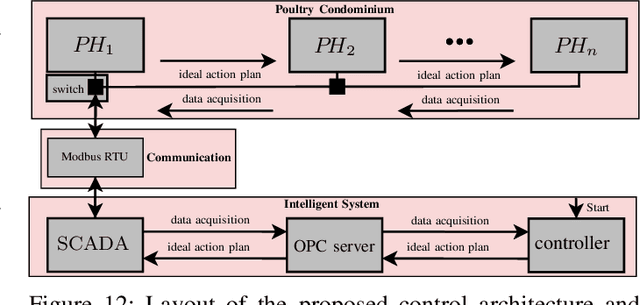
In poultry farming, the systematic choice, update, and implementation of periodic (t) action plans define the feed conversion rate (FCR[t]), which is an acceptable measure for successful production. Appropriate action plans provide tailored resources for broilers, allowing them to grow within the so-called thermal comfort zone, without wast or lack of resources. Although the implementation of an action plan is automatic, its configuration depends on the knowledge of the specialist, tending to be inefficient and error-prone, besides to result in different FCR[t] for each poultry house. In this article, we claim that the specialist's perception can be reproduced, to some extent, by computational intelligence. By combining deep learning and genetic algorithm techniques, we show how action plans can adapt their performance over the time, based on previous well succeeded plans. We also implement a distributed network infrastructure that allows to replicate our method over distributed poultry houses, for their smart, interconnected, and adaptive control. A supervision system is provided as interface to users. Experiments conducted over real data show that our method improves 5% on the performance of the most productive specialist, staying very close to the optimal FCR[t].
Better Fine-Tuning by Reducing Representational Collapse
Aug 06, 2020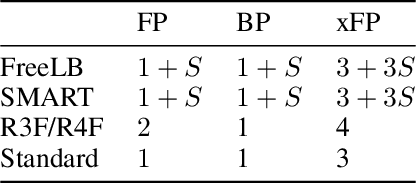
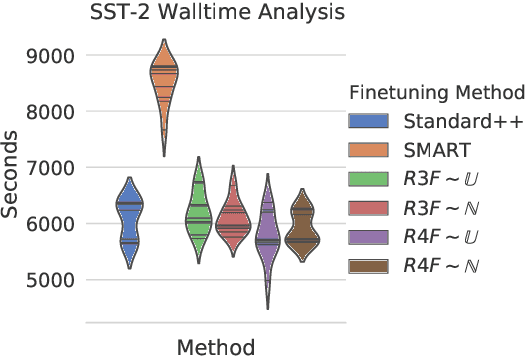
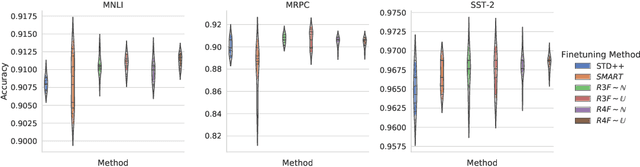
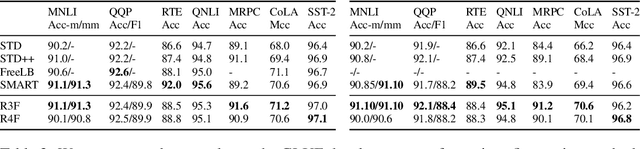
Although widely adopted, existing approaches for fine-tuning pre-trained language models have been shown to be unstable across hyper-parameter settings, motivating recent work on trust region methods. In this paper, we present a simplified and efficient method rooted in trust region theory that replaces previously used adversarial objectives with parametric noise (sampling from either a normal or uniform distribution), thereby discouraging representation change during fine-tuning when possible without hurting performance. We also introduce a new analysis to motivate the use of trust region methods more generally, by studying representational collapse; the degradation of generalizable representations from pre-trained models as they are fine-tuned for a specific end task. Extensive experiments show that our fine-tuning method matches or exceeds the performance of previous trust region methods on a range of understanding and generation tasks (including DailyMail/CNN, Gigaword, Reddit TIFU, and the GLUE benchmark), while also being much faster. We also show that it is less prone to representation collapse; the pre-trained models maintain more generalizable representations every time they are fine-tuned.
Intelligent Residential Energy Management System using Deep Reinforcement Learning
May 28, 2020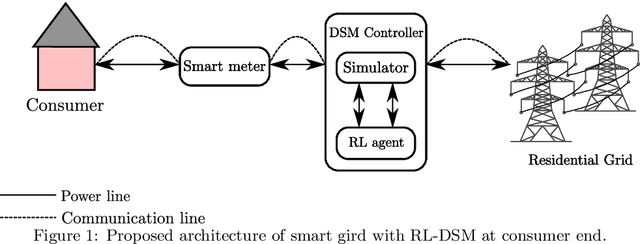
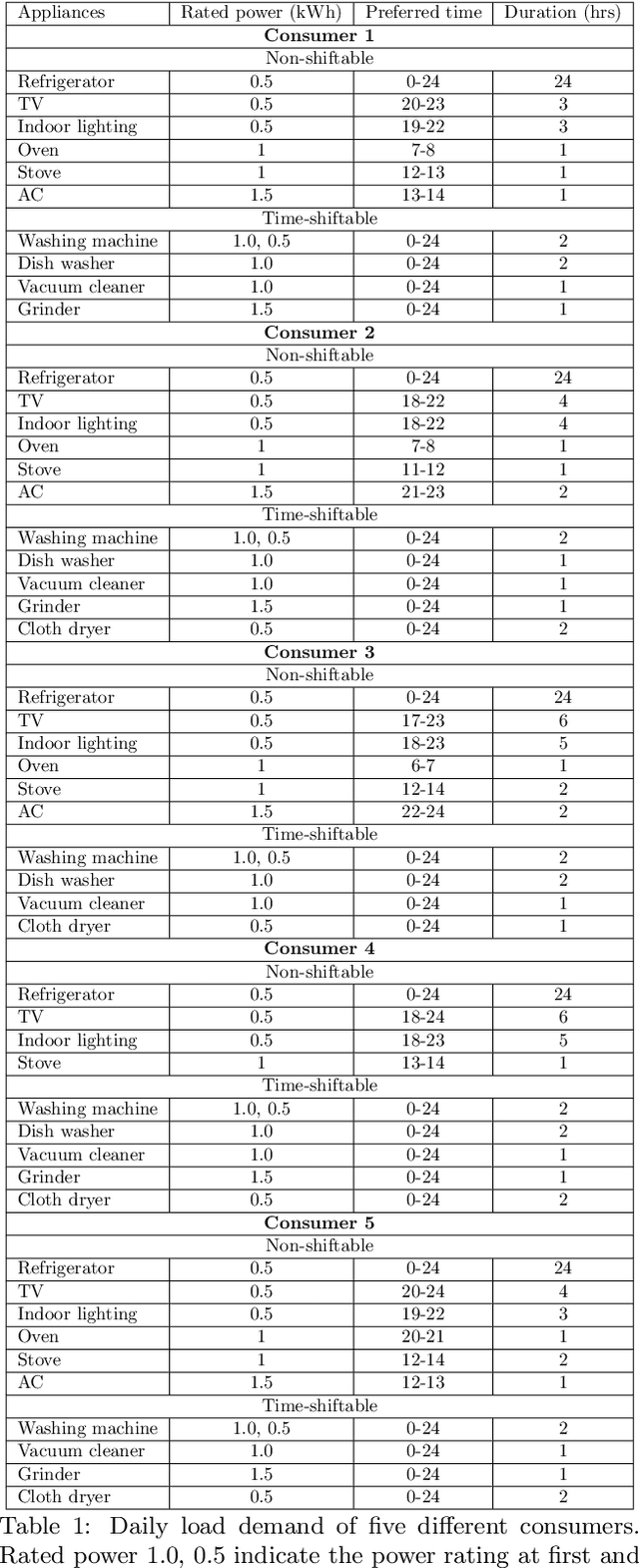
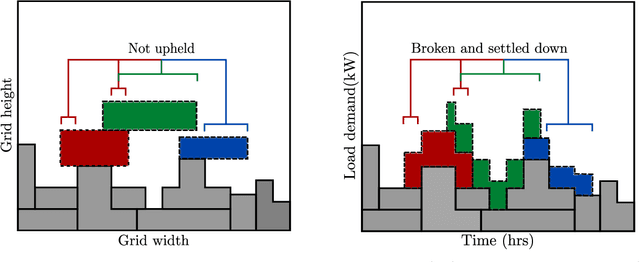
The rising demand for electricity and its essential nature in today's world calls for intelligent home energy management (HEM) systems that can reduce energy usage. This involves scheduling of loads from peak hours of the day when energy consumption is at its highest to leaner off-peak periods of the day when energy consumption is relatively lower thereby reducing the system's peak load demand, which would consequently result in lesser energy bills, and improved load demand profile. This work introduces a novel way to develop a learning system that can learn from experience to shift loads from one time instance to another and achieve the goal of minimizing the aggregate peak load. This paper proposes a Deep Reinforcement Learning (DRL) model for demand response where the virtual agent learns the task like humans do. The agent gets feedback for every action it takes in the environment; these feedbacks will drive the agent to learn about the environment and take much smarter steps later in its learning stages. Our method outperformed the state of the art mixed integer linear programming (MILP) for load peak reduction. The authors have also designed an agent to learn to minimize both consumers' electricity bills and utilities' system peak load demand simultaneously. The proposed model was analyzed with loads from five different residential consumers; the proposed method increases the monthly savings of each consumer by reducing their electricity bill drastically along with minimizing the peak load on the system when time shiftable loads are handled by the proposed method.