 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectroscopy Analysis with Machine Learning Regression for the Quantification of Carbon and Nitrogen Contents in Inceptisol and Oxisol Soil Types: Comparing Different Preprocessing and Validation methods as well as Feature Importance
Jul 01, 2026Near-Infrared (NIR) spectroscopy has emerged as a promising alternative to traditional soil analysis methods, offering advantages such as speed, low cost, and non-destructive testing. This work proposes a machine learning (ML) approach to calibrate predictive models for carbon (C) and nitrogen (N) content in Oxisols and Inceptisols, utilizing NIR spectral data acquired with a portable MyNIR device. Various preprocessing methods were evaluated, with the most effective being the Savitzky-Golay (SG) filter and a robust outlier removal method based on the Nonlinear Iterative Partial Least Squares (NIPALS) algorithm coupled with a Huber loss function. Multiple validation strategies were compared, including 10-fold cross-validation, leave-one-out, and holdout via the Kennard-Stone method, followed by standardization. Stacking ensemble learning models were employed, using Partial Least Squares (PLS), Support Vector Regression (SVR), and Ridge as base models, with linear regression as the meta-model. The models were evaluated using R2, Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and Ratio of Performance Deviation (RPD) metrics. The performance gap between soil types suggests the influence of pedological characteristics. Furthermore, the models achieved an RPD > 2.0 with low overfitting, validating the potential of this approach for rapid C and N quantification. This study contributes to the optimization of sustainable agricultural practices, aligning with the demand for efficient and environmentally friendly analytical methods. The developed technique enables faster decision-making for producers and consultants based on organic matter content, fertility indicators, and nutrient availability.
Iterative Framework For Data Augmentation Of Segmented Fingerprints
May 29, 2026Infant biometrics presents unique challenges due to the physiological differences between infants and adults, compounded by the scarcity of available data for research that limits the development of robust matching systems. This paper proposes a novel data augmentation method that uses iterative techniques to generate diverse variants of segmented fingerprints by inducing errors in a convolutional neural network trained to extract fingerprint ridges and valleys. Experiments on real infant fingerprints demonstrate the method's effectiveness in expanding fingerprint variability, with augmentations exhibiting significant fluctuations in minutiae counts while still retaining visual similarity to the originals. The study also highlights the method's customizable nature for applying varying levels of changes to fingerprint segmentations. Future research includes training segmentation and matching neural networks using datasets augmented by the proposed framework.
Recursive Class Connectivity Classification (R3C) Applied to Binary Image Segmentation for Improved Infant Fingerprint Enhancement
May 25, 2026Image enhancement plays a crucial role in infant fingerprint matching, as child-specific characteristics such as smaller finger dimensions and thinner ridge structures often degrade image quality during acquisition. To address these limitations, enrollment typically depends on specialized highresolution scanners, which most existing enhancement methods are not designed to support. Consequently, identification rates for children remain significantly lower than those achieved with adult fingerprints. This study introduces Recursive Class Connectivity Classification (R3C), a novel framework that iteratively refines binary segmentation outputs from existing enhancement methods by extending ridge structures. R3C does not require modifications to the underlying classifier and operates without training data, which is not currently available for infant fingerprints. Instead, the method improves segmentation by repeatedly feeding the classified image back into the classification process, while combining each intermediate segmentation with the original input image. Experiments conducted on three fingerprint datasets using four different enhancement classifiers show that R3C can increase the True Acceptance Rate (TAR) by up to 4% for children and over 40% for newborns, compared to using the enhancement methods alone. A qualitative analysis further demonstrates that R3C reconnects fragmented ridge patterns, improving the visual quality of segmentation. Because it functions independently of the enhancement method used, R3C provides a flexible and broadly applicable solution for improving binary segmentation.
Local-sensitive connectivity filter (ls-cf): A post-processing unsupervised improvement of the frangi, hessian and vesselness filters for multimodal vessel segmentation
May 20, 2026A retinal vessel analysis is a procedure that can be used as an assessment of risks to the eye. This work proposes an unsupervised multimodal approach that improves the response of the Frangi filter, enabling automatic vessel segmentation. We propose a filter that computes pixel-level vessel continuity while introducing a local tolerance heuristic to fill in vessel discontinuities produced by the Frangi response. This proposal, called the local-sensitive connectivity filter (LS-CF), is compared against a naive connectivity filter to the baseline thresholded Frangi filter response and to the naive connectivity filter response in combination with the morphological closing and to the current approaches in the literature. The proposal was able to achieve competitive results in a variety of multimodal datasets. It was robust enough to outperform all the state-of-the-art approaches in the literature for the OSIRIX angiographic dataset in terms of accuracy and 4 out of 5 works in the case of the IOSTAR dataset while also outperforming several works in the case of the DRIVE and STARE datasets and 6 out of 10 in the CHASE-DB dataset. For the CHASE-DB, it also outperformed all the state-of-the-art unsupervised methods.
Cardiac fat segmentation using computed tomography and an image-to-image conditional generative adversarial neural network
May 19, 2026In recent years, research has highlighted the association between increased adipose tissue surrounding the human heart and elevated susceptibility to cardiovascular diseases such as atrial fibrillation and coronary heart disease. However, the manual segmentation of these fat deposits has not been widely implemented in clinical practice due to the substantial workload it entails for medical professionals and the associated costs. Consequently, the demand for more precise and time-efficient quantitative analysis has driven the emergence of novel computational methods for fat segmentation. This study presents a novel deep learning-based methodology that offers autonomous segmentation and quantification of two distinct types of cardiac fat deposits. The proposed approach leverages the pix2pix network, a generative conditional adversarial network primarily designed for image-to-image translation tasks. By applying this network architecture, we aim to investigate its efficacy in tackling the specific challenge of cardiac fat segmentation, despite not being originally tailored for this purpose. The two types of fat deposits of interest in this study are referred to as epicardial and mediastinal fats, which are spatially separated by the pericardium. The experimental results demonstrated an average accuracy of 99.08% and f1-score 98.73 for the segmentation of the epicardial fat and 97.90% of accuracy and f1-score of 98.40 for the mediastinal fat. These findings represent the high precision and overlap agreement achieved by the proposed methodology. In comparison to existing studies, our approach exhibited superior performance in terms of f1-score and run time, enabling the images to be segmented in real time.
An on-production high-resolution longitudinal neonatal fingerprint database in Brazil
Apr 27, 2025

The neonatal period is critical for survival, requiring accurate and early identification to enable timely interventions such as vaccinations, HIV treatment, and nutrition programs. Biometric solutions offer potential for child protection by helping to prevent baby swaps, locate missing children, and support national identity systems. However, developing effective biometric identification systems for newborns remains a major challenge due to the physiological variability caused by finger growth, weight changes, and skin texture alterations during early development. Current literature has attempted to address these issues by applying scaling factors to emulate growth-induced distortions in minutiae maps, but such approaches fail to capture the complex and non-linear growth patterns of infants. A key barrier to progress in this domain is the lack of comprehensive, longitudinal biometric datasets capturing the evolution of neonatal fingerprints over time. This study addresses this gap by focusing on designing and developing a high-quality biometric database of neonatal fingerprints, acquired at multiple early life stages. The dataset is intended to support the training and evaluation of machine learning models aimed at emulating the effects of growth on biometric features. We hypothesize that such a dataset will enable the development of more robust and accurate Deep Learning-based models, capable of predicting changes in the minutiae map with higher fidelity than conventional scaling-based methods. Ultimately, this effort lays the groundwork for more reliable biometric identification systems tailored to the unique developmental trajectory of newborns.
The use of Multi-domain Electroencephalogram Representations in the building of Models based on Convolutional and Recurrent Neural Networks for Epilepsy Detection
Apr 24, 2025



Epilepsy, affecting approximately 50 million people globally, is characterized by abnormal brain activity and remains challenging to treat. The diagnosis of epilepsy relies heavily on electroencephalogram (EEG) data, where specialists manually analyze epileptiform patterns across pre-ictal, ictal, post-ictal, and interictal periods. However, the manual analysis of EEG signals is prone to variability between experts, emphasizing the need for automated solutions. Although previous studies have explored preprocessing techniques and machine learning approaches for seizure detection, there is a gap in understanding how the representation of EEG data (time, frequency, or time-frequency domains) impacts the predictive performance of deep learning models. This work addresses this gap by systematically comparing deep neural networks trained on EEG data in these three domains. Through the use of statistical tests, we identify the optimal data representation and model architecture for epileptic seizure detection. The results demonstrate that frequency-domain data achieves detection metrics exceeding 97\%, providing a robust foundation for more accurate and reliable seizure detection systems.
Estimating action plans for smart poultry houses
Aug 17, 2020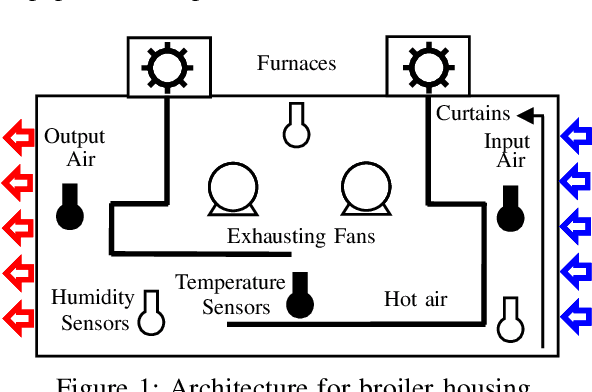
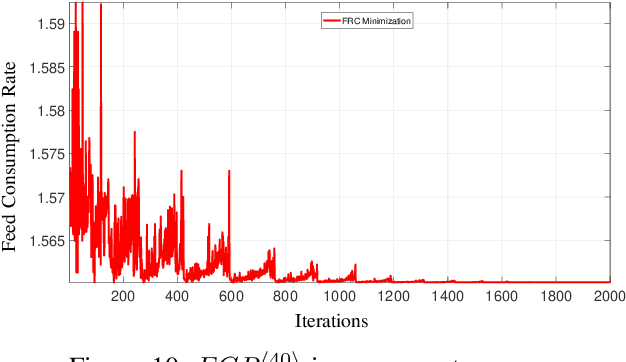
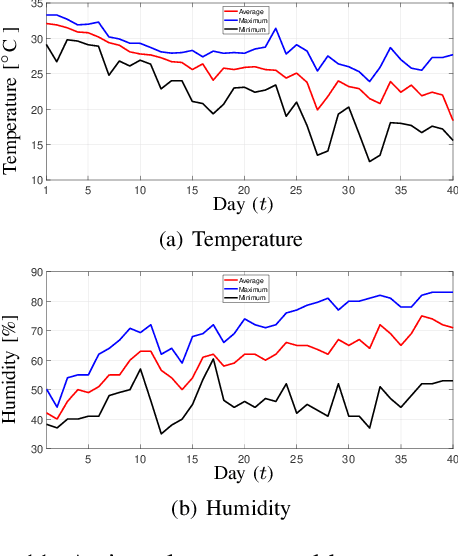
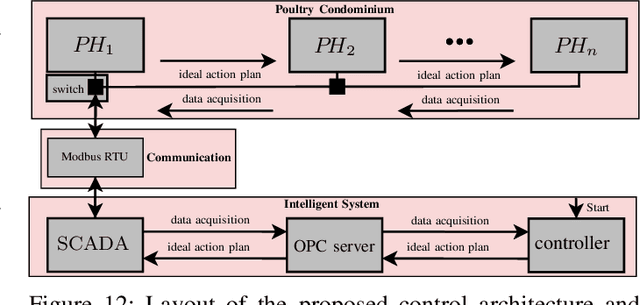
In poultry farming, the systematic choice, update, and implementation of periodic (t) action plans define the feed conversion rate (FCR[t]), which is an acceptable measure for successful production. Appropriate action plans provide tailored resources for broilers, allowing them to grow within the so-called thermal comfort zone, without wast or lack of resources. Although the implementation of an action plan is automatic, its configuration depends on the knowledge of the specialist, tending to be inefficient and error-prone, besides to result in different FCR[t] for each poultry house. In this article, we claim that the specialist's perception can be reproduced, to some extent, by computational intelligence. By combining deep learning and genetic algorithm techniques, we show how action plans can adapt their performance over the time, based on previous well succeeded plans. We also implement a distributed network infrastructure that allows to replicate our method over distributed poultry houses, for their smart, interconnected, and adaptive control. A supervision system is provided as interface to users. Experiments conducted over real data show that our method improves 5% on the performance of the most productive specialist, staying very close to the optimal FCR[t].
Deep Learning Models for Visual Inspection on Automotive Assembling Line
Jul 02, 2020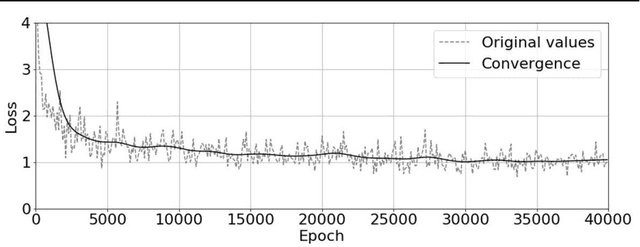

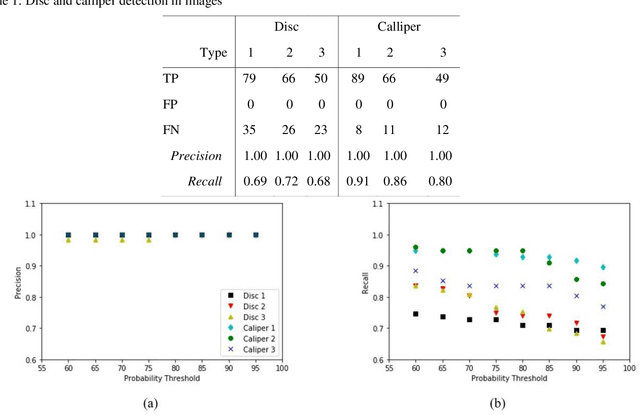

Automotive manufacturing assembly tasks are built upon visual inspections such as scratch identification on machined surfaces, part identification and selection, etc, which guarantee product and process quality. These tasks can be related to more than one type of vehicle that is produced within the same manufacturing line. Visual inspection was essentially human-led but has recently been supplemented by the artificial perception provided by computer vision systems (CVSs). Despite their relevance, the accuracy of CVSs varies accordingly to environmental settings such as lighting, enclosure and quality of image acquisition. These issues entail costly solutions and override part of the benefits introduced by computer vision systems, mainly when it interferes with the operating cycle time of the factory. In this sense, this paper proposes the use of deep learning-based methodologies to assist in visual inspection tasks while leaving very little footprints in the manufacturing environment and exploring it as an end-to-end tool to ease CVSs setup. The proposed approach is illustrated by four proofs of concept in a real automotive assembly line based on models for object detection, semantic segmentation, and anomaly detection.
* arXiv admin note: text overlap with arXiv:1802.08717, arXiv:1703.05921 by other authors
SE3M: A Model for Software Effort Estimation Using Pre-trained Embedding Models
Jun 30, 2020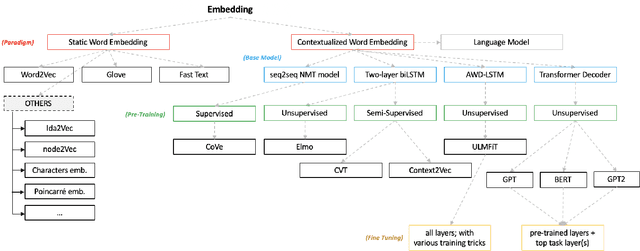
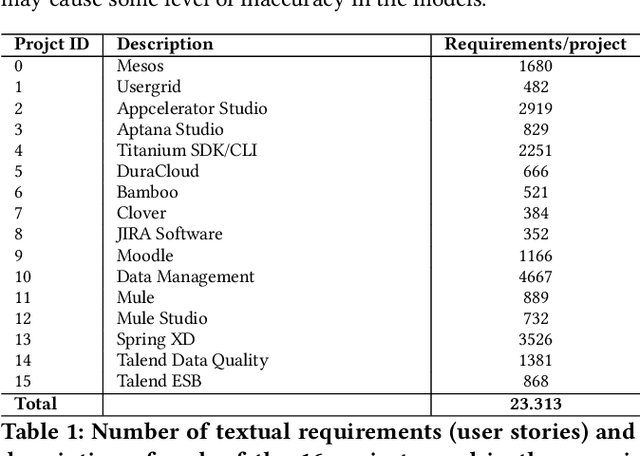
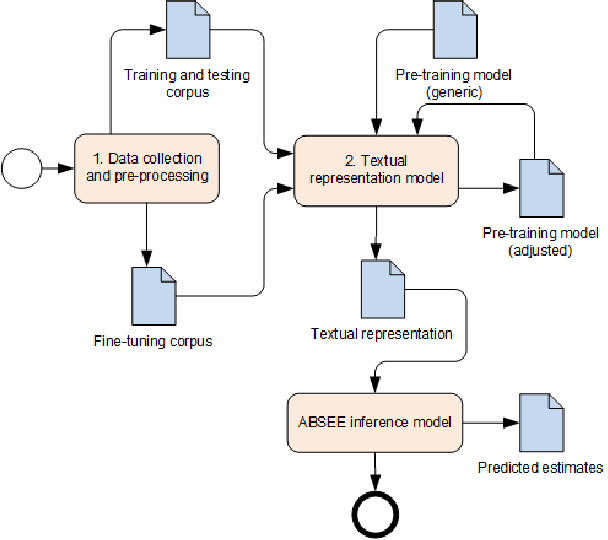
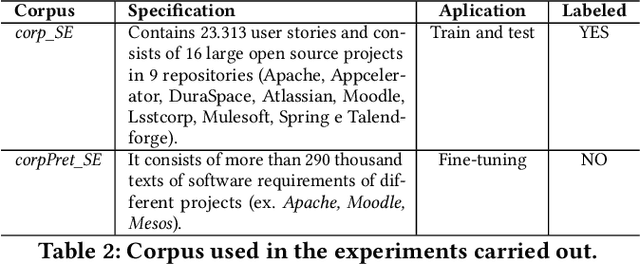
Estimating effort based on requirement texts presents many challenges, especially in obtaining viable features to infer effort. Aiming to explore a more effective technique for representing textual requirements to infer effort estimates by analogy, this paper proposes to evaluate the effectiveness of pre-trained embeddings models. For this, two embeddings approach, context-less and contextualized models are used. Generic pre-trained models for both approaches went through a fine-tuning process. The generated models were used as input in the applied deep learning architecture, with linear output. The results were very promising, realizing that pre-trained incorporation models can be used to estimate software effort based only on requirements texts. We highlight the results obtained to apply the pre-trained BERT model with fine-tuning in a single project repository, whose value is the Mean Absolute Error (MAE) is 4.25 and the standard deviation of only 0.17, which represents a result very positive when compared to similar works. The main advantages of the proposed estimation method are reliability, the possibility of generalization, speed, and low computational cost provided by the fine-tuning process, and the possibility to infer new or existing requirements.