 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Survey on 3D Gaussian Splatting
Jan 08, 2024
3D Gaussian splatting (3D GS) has recently emerged as a transformative technique in the explicit radiance field and computer graphics landscape. This innovative approach, characterized by the utilization of millions of 3D Gaussians, represents a significant departure from the neural radiance field (NeRF) methodologies, which predominantly use implicit, coordinate-based models to map spatial coordinates to pixel values. 3D GS, with its explicit scene representations and differentiable rendering algorithms, not only promises real-time rendering capabilities but also introduces unprecedented levels of control and editability. This positions 3D GS as a potential game-changer for the next generation of 3D reconstruction and representation. In the present paper, we provide the first systematic overview of the recent developments and critical contributions in the domain of 3D GS. We begin with a detailed exploration of the underlying principles and the driving forces behind the advent of 3D GS, setting the stage for understanding its significance. A focal point of our discussion is the practical applicability of 3D GS. By facilitating real-time performance, 3D GS opens up a plethora of applications, ranging from virtual reality to interactive media and beyond. This is complemented by a comparative analysis of leading 3D GS models, evaluated across various benchmark tasks to highlight their performance and practical utility. The survey concludes by identifying current challenges and suggesting potential avenues for future research in this domain. Through this survey, we aim to provide a valuable resource for both newcomers and seasoned researchers, fostering further exploration and advancement in applicable and explicit radiance field representation.
Gerrymandering Planar Graphs
Jan 08, 2024We study the computational complexity of the map redistricting problem (gerrymandering). Mathematically, the electoral district designer (gerrymanderer) attempts to partition a weighted graph into $k$ connected components (districts) such that its candidate (party) wins as many districts as possible. Prior work has principally concerned the special cases where the graph is a path or a tree. Our focus concerns the realistic case where the graph is planar. We prove that the gerrymandering problem is solvable in polynomial time in $\lambda$-outerplanar graphs, when the number of candidates and $\lambda$ are constants and the vertex weights (voting weights) are polynomially bounded. In contrast, the problem is NP-complete in general planar graphs even with just two candidates. This motivates the study of approximation algorithms for gerrymandering planar graphs. However, when the number of candidates is large, we prove it is hard to distinguish between instances where the gerrymanderer cannot win a single district and instances where the gerrymanderer can win at least one district. This immediately implies that the redistricting problem is inapproximable in polynomial time in planar graphs, unless P=NP. This conclusion appears terminal for the design of good approximation algorithms -- but it is not. The inapproximability bound can be circumvented as it only applies when the maximum number of districts the gerrymanderer can win is extremely small, say one. Indeed, for a fixed number of candidates, our main result is that there is a constant factor approximation algorithm for redistricting unweighted planar graphs, provided the optimal value is a large enough constant.
PLE-SLAM: A Visual-Inertial SLAM Based on Point-Line Features and Efficient IMU Initialization
Jan 05, 2024Visual-inertial SLAM is crucial in various fields, such as aerial vehicles, industrial robots, and autonomous driving. The fusion of camera and inertial measurement unit (IMU) makes up for the shortcomings of a signal sensor, which significantly improves the accuracy and robustness of localization in challenging environments. This article presents PLE-SLAM, an accurate and real-time visual-inertial SLAM algorithm based on point-line features and efficient IMU initialization. First, we use parallel computing methods to extract features and compute descriptors to ensure real-time performance. Adjacent short line segments are merged into long line segments, and isolated short line segments are directly deleted. Second, a rotation-translation-decoupled initialization method is extended to use both points and lines. Gyroscope bias is optimized by tightly coupling IMU measurements and image observations. Accelerometer bias and gravity direction are solved by an analytical method for efficiency. To improve the system's intelligence in handling complex environments, a scheme of leveraging semantic information and geometric constraints to eliminate dynamic features and A solution for loop detection and closed-loop frame pose estimation using CNN and GNN are integrated into the system. All networks are accelerated to ensure real-time performance. The experiment results on public datasets illustrate that PLE-SLAM is one of the state-of-the-art visual-inertial SLAM systems.
Incremental FastPitch: Chunk-based High Quality Text to Speech
Jan 03, 2024Parallel text-to-speech models have been widely applied for real-time speech synthesis, and they offer more controllability and a much faster synthesis process compared with conventional auto-regressive models. Although parallel models have benefits in many aspects, they become naturally unfit for incremental synthesis due to their fully parallel architecture such as transformer. In this work, we propose Incremental FastPitch, a novel FastPitch variant capable of incrementally producing high-quality Mel chunks by improving the architecture with chunk-based FFT blocks, training with receptive-field constrained chunk attention masks, and inference with fixed size past model states. Experimental results show that our proposal can produce speech quality comparable to the parallel FastPitch, with a significant lower latency that allows even lower response time for real-time speech applications.
On State Estimation in Multi-Sensor Fusion Navigation: Optimization and Filtering
Jan 11, 2024The essential of navigation, perception, and decision-making which are basic tasks for intelligent robots, is to estimate necessary system states. Among them, navigation is fundamental for other upper applications, providing precise position and orientation, by integrating measurements from multiple sensors. With observations of each sensor appropriately modelled, multi-sensor fusion tasks for navigation are reduced to the state estimation problem which can be solved by two approaches: optimization and filtering. Recent research has shown that optimization-based frameworks outperform filtering-based ones in terms of accuracy. However, both methods are based on maximum likelihood estimation (MLE) and should be theoretically equivalent with the same linearization points, observation model, measurements, and Gaussian noise assumption. In this paper, we deeply dig into the theories and existing strategies utilized in both optimization-based and filtering-based approaches. It is demonstrated that the two methods are equal theoretically, but this equivalence corrupts due to different strategies applied in real-time operation. By adjusting existing strategies of the filtering-based approaches, the Monte-Carlo simulation and vehicular ablation experiments based on visual odometry (VO) indicate that the strategy adjusted filtering strictly equals to optimization. Therefore, future research on sensor-fusion problems should concentrate on their own algorithms and strategies rather than state estimation approaches.
Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation
Jan 11, 2024Recent works demonstrate that using reinforcement learning (RL) with quality rewards can enhance the quality of generated images in text-to-image (T2I) generation. However, a simple aggregation of multiple rewards may cause over-optimization in certain metrics and degradation in others, and it is challenging to manually find the optimal weights. An effective strategy to jointly optimize multiple rewards in RL for T2I generation is highly desirable. This paper introduces Parrot, a novel multi-reward RL framework for T2I generation. Through the use of the batch-wise Pareto optimal selection, Parrot automatically identifies the optimal trade-off among different rewards during the RL optimization of the T2I generation. Additionally, Parrot employs a joint optimization approach for the T2I model and the prompt expansion network, facilitating the generation of quality-aware text prompts, thus further enhancing the final image quality. To counteract the potential catastrophic forgetting of the original user prompt due to prompt expansion, we introduce original prompt centered guidance at inference time, ensuring that the generated image remains faithful to the user input. Extensive experiments and a user study demonstrate that Parrot outperforms several baseline methods across various quality criteria, including aesthetics, human preference, image sentiment, and text-image alignment.
Long-term Safe Reinforcement Learning with Binary Feedback
Jan 11, 2024Safety is an indispensable requirement for applying reinforcement learning (RL) to real problems. Although there has been a surge of safe RL algorithms proposed in recent years, most existing work typically 1) relies on receiving numeric safety feedback; 2) does not guarantee safety during the learning process; 3) limits the problem to a priori known, deterministic transition dynamics; and/or 4) assume the existence of a known safe policy for any states. Addressing the issues mentioned above, we thus propose Long-term Binaryfeedback Safe RL (LoBiSaRL), a safe RL algorithm for constrained Markov decision processes (CMDPs) with binary safety feedback and an unknown, stochastic state transition function. LoBiSaRL optimizes a policy to maximize rewards while guaranteeing a long-term safety that an agent executes only safe state-action pairs throughout each episode with high probability. Specifically, LoBiSaRL models the binary safety function via a generalized linear model (GLM) and conservatively takes only a safe action at every time step while inferring its effect on future safety under proper assumptions. Our theoretical results show that LoBiSaRL guarantees the long-term safety constraint, with high probability. Finally, our empirical results demonstrate that our algorithm is safer than existing methods without significantly compromising performance in terms of reward.
Prediction of rare events in the operation of household equipment using co-evolving time series
Dec 15, 2023
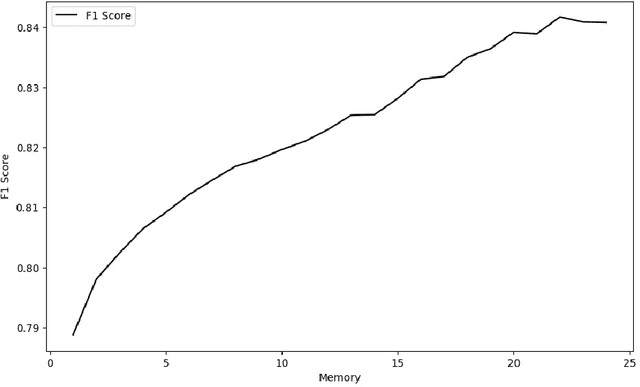
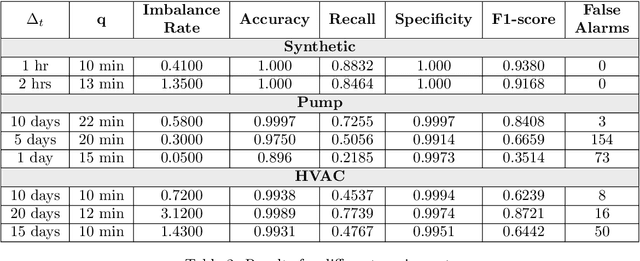
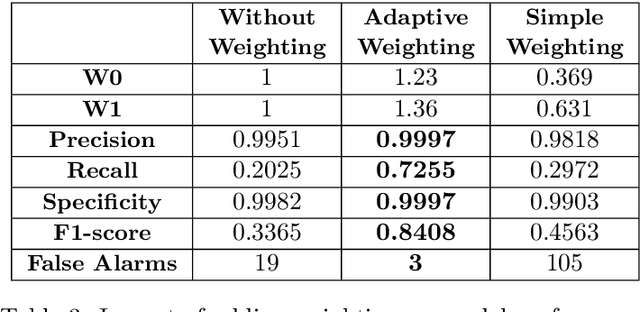
In this study, we propose an approach for predicting rare events by exploiting time series in coevolution. Our approach involves a weighted autologistic regression model, where we leverage the temporal behavior of the data to enhance predictive capabilities. By addressing the issue of imbalanced datasets, we establish constraints leading to weight estimation and to improved performance. Evaluation on synthetic and real-world datasets confirms that our approach outperform state-of-the-art of predicting home equipment failure methods.
Refining Remote Photoplethysmography Architectures using CKA and Empirical Methods
Jan 09, 2024Model architecture refinement is a challenging task in deep learning research fields such as remote photoplethysmography (rPPG). One architectural consideration, the depth of the model, can have significant consequences on the resulting performance. In rPPG models that are overprovisioned with more layers than necessary, redundancies exist, the removal of which can result in faster training and reduced computational load at inference time. With too few layers the models may exhibit sub-optimal error rates. We apply Centered Kernel Alignment (CKA) to an array of rPPG architectures of differing depths, demonstrating that shallower models do not learn the same representations as deeper models, and that after a certain depth, redundant layers are added without significantly increased functionality. An empirical study confirms these findings and shows how this method could be used to refine rPPG architectures.
Single-Microphone Speaker Separation and Voice Activity Detection in Noisy and Reverberant Environments
Jan 07, 2024Speech separation involves extracting an individual speaker's voice from a multi-speaker audio signal. The increasing complexity of real-world environments, where multiple speakers might converse simultaneously, underscores the importance of effective speech separation techniques. This work presents a single-microphone speaker separation network with TF attention aiming at noisy and reverberant environments. We dub this new architecture as Separation TF Attention Network (Sep-TFAnet). In addition, we present a variant of the separation network, dubbed $ \text{Sep-TFAnet}^{\text{VAD}}$, which incorporates a voice activity detector (VAD) into the separation network. The separation module is based on a temporal convolutional network (TCN) backbone inspired by the Conv-Tasnet architecture with multiple modifications. Rather than a learned encoder and decoder, we use short-time Fourier transform (STFT) and inverse short-time Fourier transform (iSTFT) for the analysis and synthesis, respectively. Our system is specially developed for human-robotic interactions and should support online mode. The separation capabilities of $ \text{Sep-TFAnet}^{\text{VAD}}$ and Sep-TFAnet were evaluated and extensively analyzed under several acoustic conditions, demonstrating their advantages over competing methods. Since separation networks trained on simulated data tend to perform poorly on real recordings, we also demonstrate the ability of the proposed scheme to better generalize to realistic examples recorded in our acoustic lab by a humanoid robot. Project page: https://Sep-TFAnet.github.io