 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tracking from Patterns: Learning Corresponding Patterns in Point Clouds for 3D Object Tracking
Oct 20, 2020
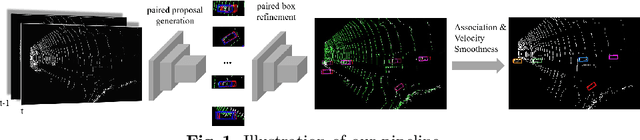


A robust 3D object tracker which continuously tracks surrounding objects and estimates their trajectories is key for self-driving vehicles. Most existing tracking methods employ a tracking-by-detection strategy, which usually requires complex pair-wise similarity computation and neglects the nature of continuous object motion. In this paper, we propose to directly learn 3D object correspondences from temporal point cloud data and infer the motion information from correspondence patterns. We modify the standard 3D object detector to process two lidar frames at the same time and predict bounding box pairs for the association and motion estimation tasks. We also equip our pipeline with a simple yet effective velocity smoothing module to estimate consistent object motion. Benifiting from the learned correspondences and motion refinement, our method exceeds the existing 3D tracking methods on both the KITTI and larger scale Nuscenes dataset.
* 4 pages, ECCV2020 Workshop on Perception for Autonomous Driving(PAD2020)
Optimal Low-Degree Hardness of Maximum Independent Set
Oct 13, 2020We study the algorithmic task of finding a large independent set in a sparse Erd\H{o}s-R\'{e}nyi random graph with $n$ vertices and average degree $d$. The maximum independent set is known to have size $(2 \log d / d)n$ in the double limit $n \to \infty$ followed by $d \to \infty$, but the best known polynomial-time algorithms can only find an independent set of half-optimal size $(\log d / d)n$. We show that the class of low-degree polynomial algorithms can find independent sets of half-optimal size but no larger, improving upon a result of Gamarnik, Jagannath, and the author. This generalizes earlier work by Rahman and Vir\'ag, which proves the analogous result for the weaker class of local algorithms.
Understanding Human Intelligence through Human Limitations
Sep 29, 2020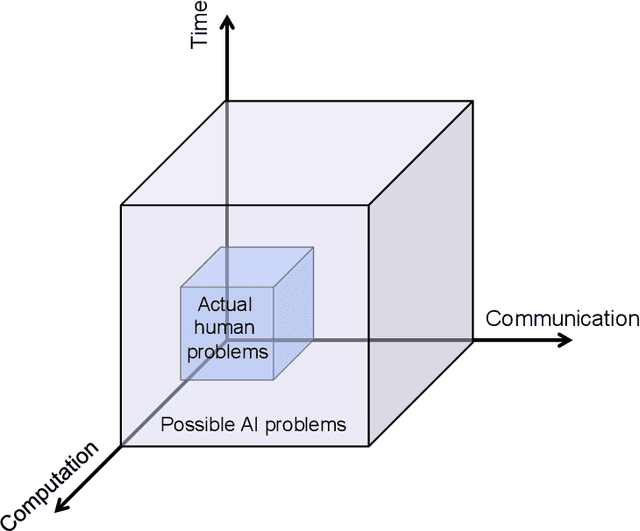
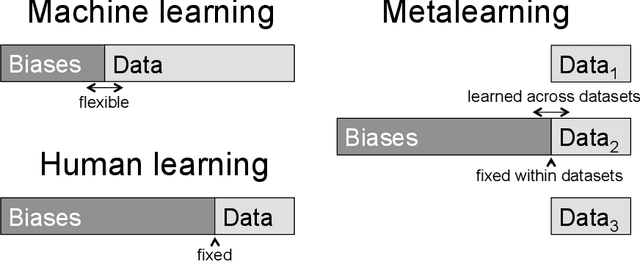
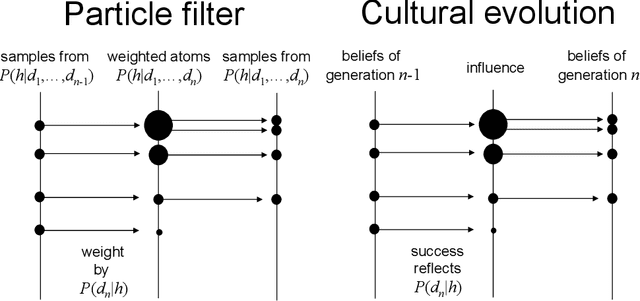
Recent progress in artificial intelligence provides the opportunity to ask the question of what is unique about human intelligence, but with a new comparison class. I argue that we can understand human intelligence, and the ways in which it may differ from artificial intelligence, by considering the characteristics of the kind of computational problems that human minds have to solve. I claim that these problems acquire their structure from three fundamental limitations that apply to human beings: limited time, limited computation, and limited communication. From these limitations we can derive many of the properties we associate with human intelligence, such as rapid learning, the ability to break down problems into parts, and the capacity for cumulative cultural evolution.
Particle Swarm Based Hyper-Parameter Optimization for Machine Learned Interatomic Potentials
Dec 31, 2020
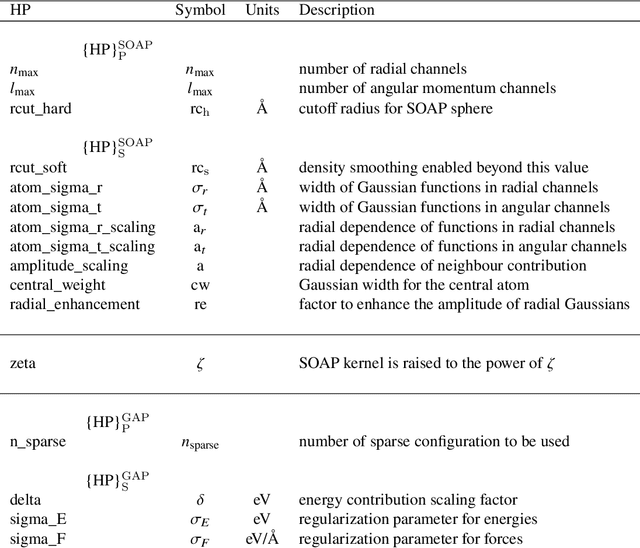
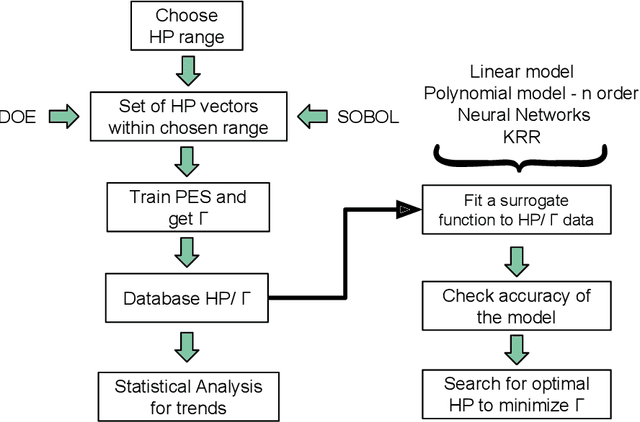
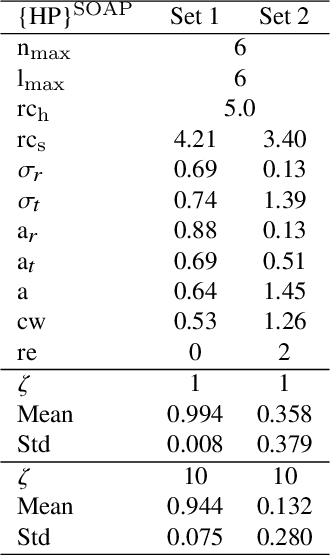
Modeling non-empirical and highly flexible interatomic potential energy surfaces (PES) using machine learning (ML) approaches is becoming popular in molecular and materials research. Training an ML-PES is typically performed in two stages: feature extraction and structure-property relationship modeling. The feature extraction stage transforms atomic positions into a symmetry-invariant mathematical representation. This representation can be fine-tuned by adjusting on a set of so-called "hyper-parameters" (HPs). Subsequently, an ML algorithm such as neural networks or Gaussian process regression (GPR) is used to model the structure-PES relationship based on another set of HPs. Choosing optimal values for the two sets of HPs is critical to ensure the high quality of the resulting ML-PES model. In this paper, we explore HP optimization strategies tailored for ML-PES generation using a custom-coded parallel particle swarm optimizer (available freely at https://github.com/suresh0807/PPSO.git). We employ the smooth overlap of atomic positions (SOAP) descriptor in combination with GPR-based Gaussian approximation potentials (GAP) and optimize HPs for four distinct systems: a toy C dimer, amorphous carbon, $\alpha$-Fe, and small organic molecules (QM9 dataset). We propose a two-step optimization strategy in which the HPs related to the feature extraction stage are optimized first, followed by the optimization of the HPs in the training stage. This strategy is computationally more efficient than optimizing all HPs at the same time by means of significantly reducing the number of ML models needed to be trained to obtain the optimal HPs. This approach can be trivially extended to other combinations of descriptor and ML algorithm and brings us another step closer to fully automated ML-PES generation.
Efficient text generation of user-defined topic using generative adversarial networks
Jun 22, 2020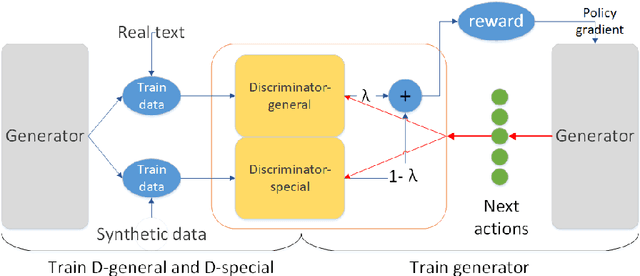
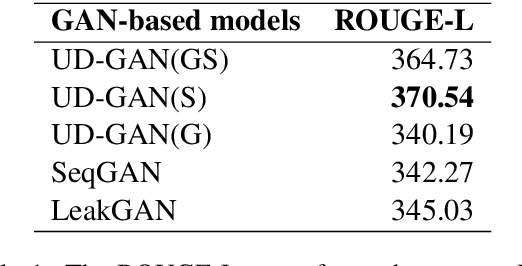
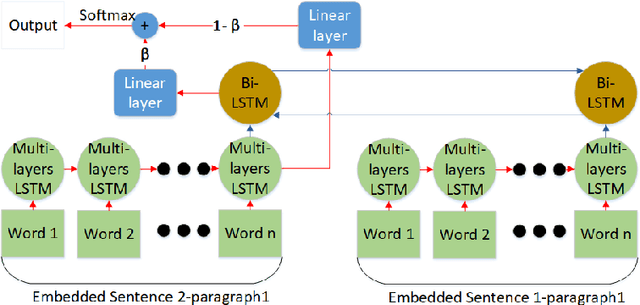
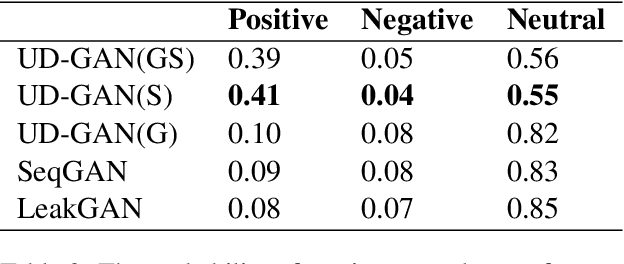
This study focused on efficient text generation using generative adversarial networks (GAN). Assuming that the goal is to generate a paragraph of a user-defined topic and sentimental tendency, conventionally the whole network has to be re-trained to obtain new results each time when a user changes the topic. This would be time-consuming and impractical. Therefore, we propose a User-Defined GAN (UD-GAN) with two-level discriminators to solve this problem. The first discriminator aims to guide the generator to learn paragraph-level information and sentence syntactic structure, which is constructed by multiple-LSTMs. The second one copes with higher-level information, such as the user-defined sentiment and topic for text generation. The cosine similarity based on TF-IDF and length penalty are adopted to determine the relevance of the topic. Then, the second discriminator is re-trained with the generator if the topic or sentiment for text generation is modified. The system evaluations are conducted to compare the performance of the proposed method with other GAN-based ones. The objective results showed that the proposed method is capable of generating texts with less time than others and the generated text is related to the user-defined topic and sentiment. We will further investigate the possibility of incorporating more detailed paragraph information such as semantics into text generation to enhance the result.
A Recurrent Neural Network and Differential Equation Based Spatiotemporal Infectious Disease Model with Application to COVID-19
Jul 14, 2020The outbreaks of Coronavirus Disease 2019 (COVID-19) have impacted the world significantly. Modeling the trend of infection and real-time forecasting of cases can help decision making and control of the disease spread. However, data-driven methods such as recurrent neural networks (RNN) can perform poorly due to limited daily samples in time. In this work, we develop an integrated spatiotemporal model based on the epidemic differential equations (SIR) and RNN. The former after simplification and discretization is a compact model of temporal infection trend of a region while the latter models the effect of nearest neighboring regions. The latter captures latent spatial information. %that is not publicly reported. We trained and tested our model on COVID-19 data in Italy, and show that it out-performs existing temporal models (fully connected NN, SIR, ARIMA) in 1-day, 3-day, and 1-week ahead forecasting especially in the regime of limited training data.
Integrated Self-Organized Traffic Light Controllers for Signalized Intersections
Aug 26, 2020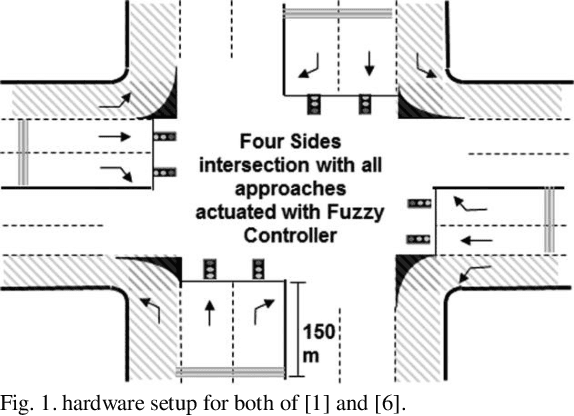
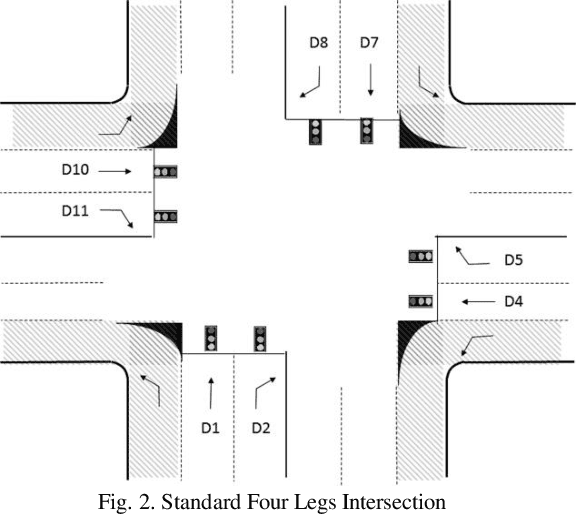

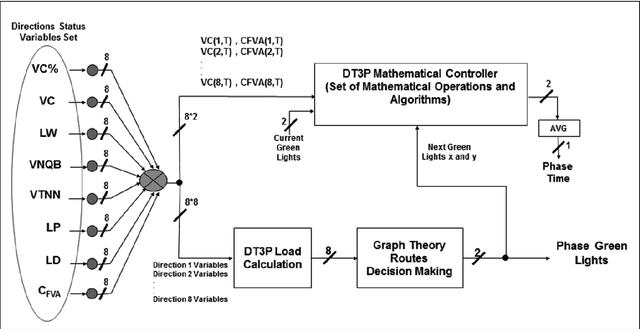
Detecting emergency vehicles arrival on roads has been the focus for many researchers. It is quite important to detect the emergency vehicles (e.g; ambulance) arrival to traffic light to give the green light for it to pass through. Many researchers have suggested and patented emergency vehicles detection systems however, according to our knowledge, none of them considered solving the effect of giving extra green time to a road while the queues are being built on others. This paper considers the problem of finding a better traffic light phase plan to stabilize/recover the situation at an effected intersection after solving an emergency vehicle existence. A hardware setup and a novel messaging protocol have been suggested to be set on roads and vehicles to collect roads real time data. In addition, a novel decision making protocol has been created to make the use of the collected data for making a better traffic light phase plan for an intersection. The phase plan has two main decisions to be made; which light has a higher priority to be green in the next phase, and how long the green phase should be. After simulating the proposed system using our customized simulator written in Matlab programing language and comparing its performance with other related works, significant enhancements have been observed in terms of stabilizing the queue lengths at an intersection after solving an emergency case.
Twitter Spam Detection: A Systematic Review
Dec 01, 2020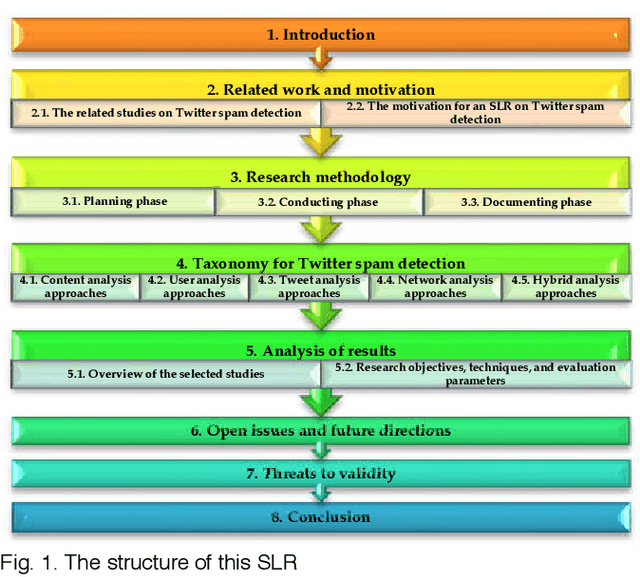
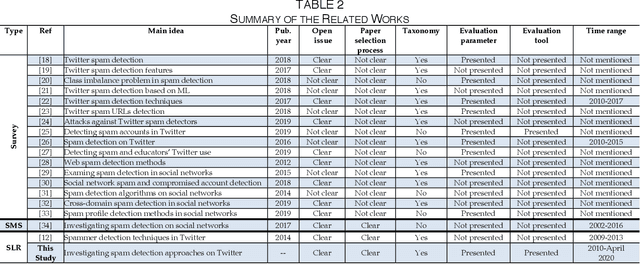
Nowadays, with the rise of Internet access and mobile devices around the globe, more people are using social networks for collaboration and receiving real-time information. Twitter, the microblogging that is becoming a critical source of communication and news propagation, has grabbed the attention of spammers to distract users. So far, researchers have introduced various defense techniques to detect spams and combat spammer activities on Twitter. To overcome this problem, in recent years, many novel techniques have been offered by researchers, which have greatly enhanced the spam detection performance. Therefore, it raises a motivation to conduct a systematic review about different approaches of spam detection on Twitter. This review focuses on comparing the existing research techniques on Twitter spam detection systematically. Literature review analysis reveals that most of the existing methods rely on Machine Learning-based algorithms. Among these Machine Learning algorithms, the major differences are related to various feature selection methods. Hence, we propose a taxonomy based on different feature selection methods and analyses, namely content analysis, user analysis, tweet analysis, network analysis, and hybrid analysis. Then, we present numerical analyses and comparative studies on current approaches, coming up with open challenges that help researchers develop solutions in this topic.
Neural Audio Fingerprint for High-specific Audio Retrieval based on Contrastive Learning
Oct 26, 2020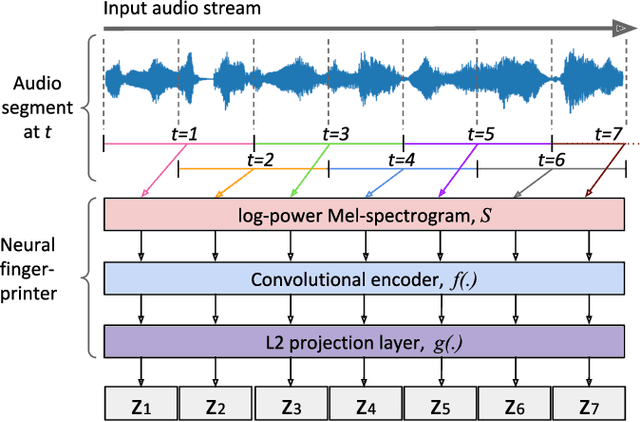

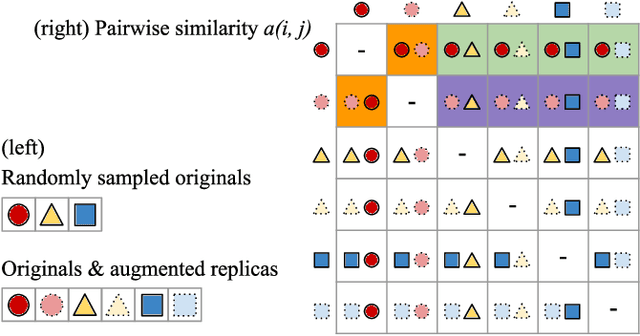
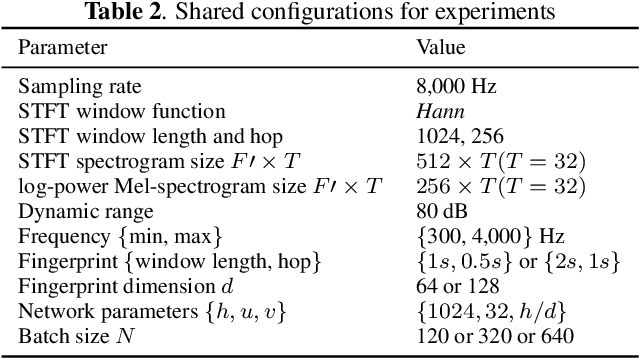
Most of existing audio fingerprinting systems have limitations to be used for high-specific audio retrieval at scale. In this work, we generate a low-dimensional representation from a short unit segment of audio, and couple this fingerprint with a fast maximum inner-product search. To this end, we present a contrastive learning framework that derives from the segment-level search objective. Each update in training uses a batch consisting of a set of pseudo labels, randomly selected original samples, and their augmented replicas. These replicas can simulate the degrading effects on original audio signals by applying small time offsets and various types of distortions, such as background noise and room/microphone impulse responses. In the segment-level search task, where the conventional audio fingerprinting systems used to fail, our system using 10x smaller storage has shown promising results. Our code and dataset will be available.
Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection
Dec 31, 2020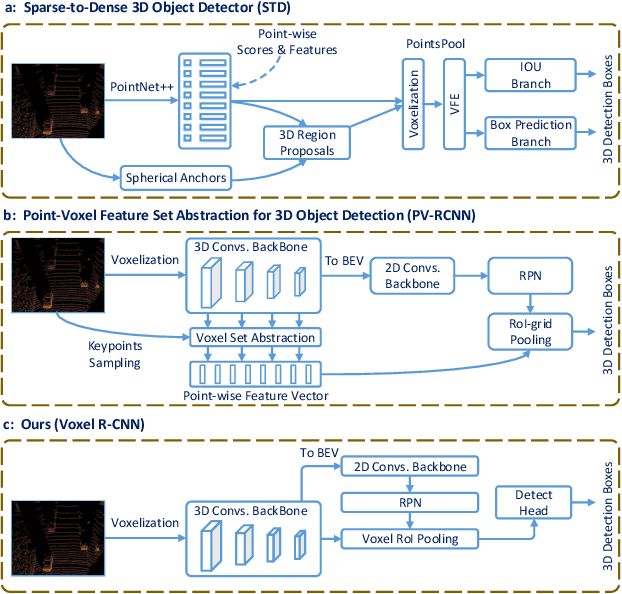


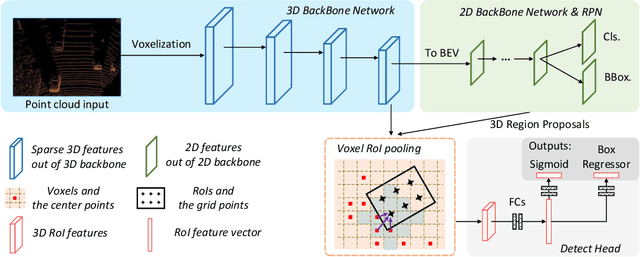
Recent advances on 3D object detection heavily rely on how the 3D data are represented, \emph{i.e.}, voxel-based or point-based representation. Many existing high performance 3D detectors are point-based because this structure can better retain precise point positions. Nevertheless, point-level features lead to high computation overheads due to unordered storage. In contrast, the voxel-based structure is better suited for feature extraction but often yields lower accuracy because the input data are divided into grids. In this paper, we take a slightly different viewpoint -- we find that precise positioning of raw points is not essential for high performance 3D object detection and that the coarse voxel granularity can also offer sufficient detection accuracy. Bearing this view in mind, we devise a simple but effective voxel-based framework, named Voxel R-CNN. By taking full advantage of voxel features in a two stage approach, our method achieves comparable detection accuracy with state-of-the-art point-based models, but at a fraction of the computation cost. Voxel R-CNN consists of a 3D backbone network, a 2D bird-eye-view (BEV) Region Proposal Network and a detect head. A voxel RoI pooling is devised to extract RoI features directly from voxel features for further refinement. Extensive experiments are conducted on the widely used KITTI Dataset and the more recent Waymo Open Dataset. Our results show that compared to existing voxel-based methods, Voxel R-CNN delivers a higher detection accuracy while maintaining a real-time frame processing rate, \emph{i.e}., at a speed of 25 FPS on an NVIDIA RTX 2080 Ti GPU. The code will be make available soon.