 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Query-time Entity Resolution
Oct 31, 2011
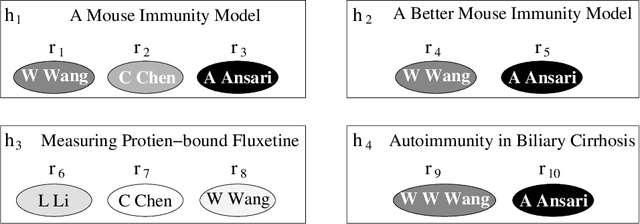
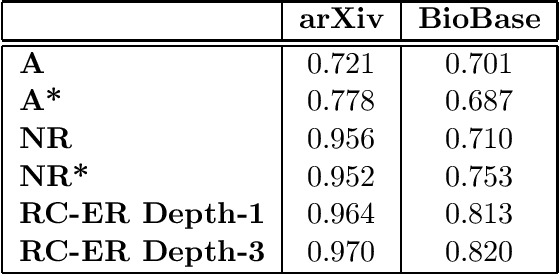

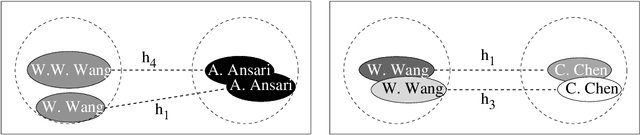
Entity resolution is the problem of reconciling database references corresponding to the same real-world entities. Given the abundance of publicly available databases that have unresolved entities, we motivate the problem of query-time entity resolution quick and accurate resolution for answering queries over such unclean databases at query-time. Since collective entity resolution approaches --- where related references are resolved jointly --- have been shown to be more accurate than independent attribute-based resolution for off-line entity resolution, we focus on developing new algorithms for collective resolution for answering entity resolution queries at query-time. For this purpose, we first formally show that, for collective resolution, precision and recall for individual entities follow a geometric progression as neighbors at increasing distances are considered. Unfolding this progression leads naturally to a two stage expand and resolve query processing strategy. In this strategy, we first extract the related records for a query using two novel expansion operators, and then resolve the extracted records collectively. We then show how the same strategy can be adapted for query-time entity resolution by identifying and resolving only those database references that are the most helpful for processing the query. We validate our approach on two large real-world publication databases where we show the usefulness of collective resolution and at the same time demonstrate the need for adaptive strategies for query processing. We then show how the same queries can be answered in real-time using our adaptive approach while preserving the gains of collective resolution. In addition to experiments on real datasets, we use synthetically generated data to empirically demonstrate the validity of the performance trends predicted by our analysis of collective entity resolution over a wide range of structural characteristics in the data.
Diagnosing and Preventing Instabilities in Recurrent Video Processing
Oct 17, 2020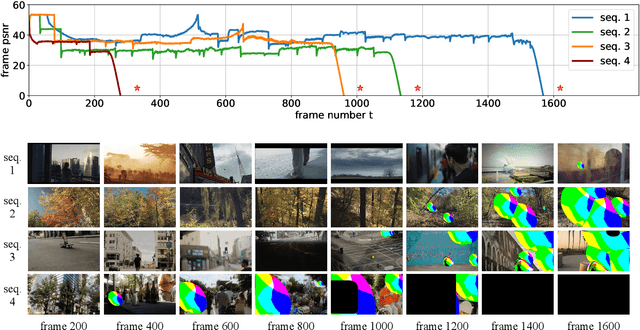
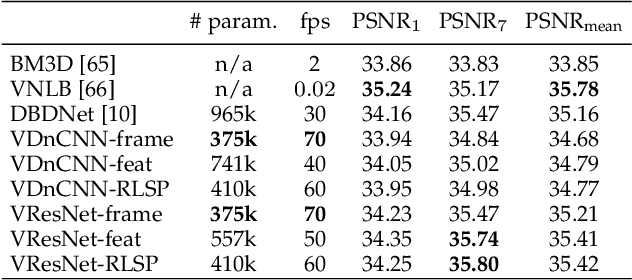
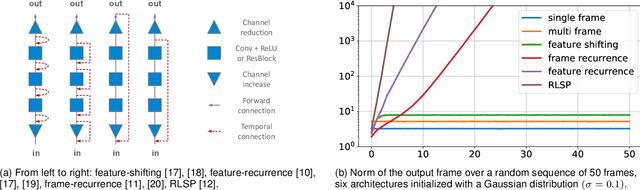
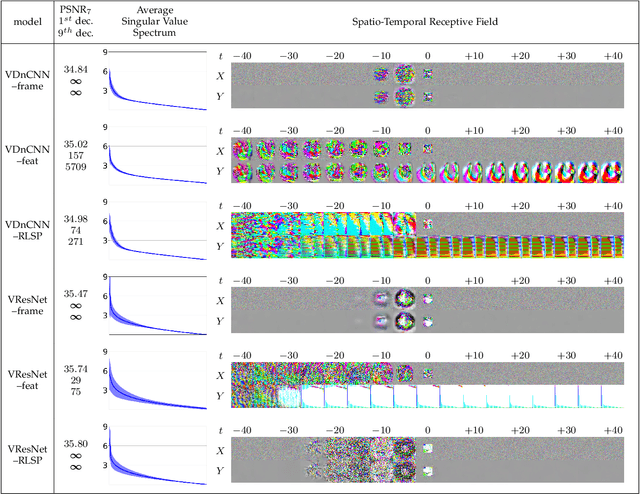
Recurrent models are becoming a popular choice for video enhancement tasks such as video denoising. In this work, we focus on their stability as dynamical systems and show that they tend to fail catastrophically at inference time on long video sequences. To address this issue, we (1) introduce a diagnostic tool which produces adversarial input sequences optimized to trigger instabilities and that can be interpreted as visualizations of spatio-temporal receptive fields, and (2) propose two approaches to enforce the stability of a model: constraining the spectral norm or constraining the stable rank of its convolutional layers. We then introduce Stable Rank Normalization of the Layers (SRNL), a new algorithm that enforces these constraints, and verify experimentally that it successfully results in stable recurrent video processing.
$k$-means on a log-Cholesky Manifold, with Unsupervised Classification of Radar Products
Aug 08, 2020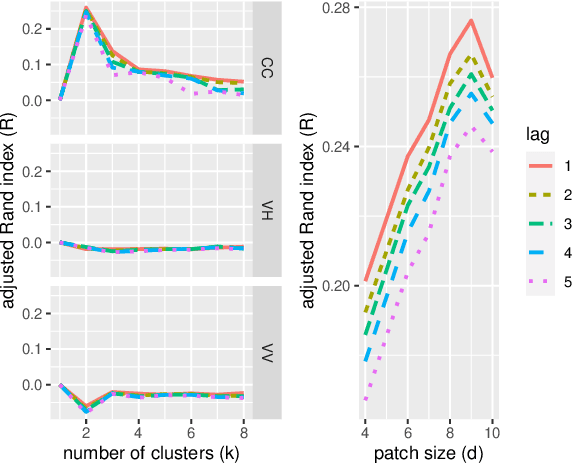
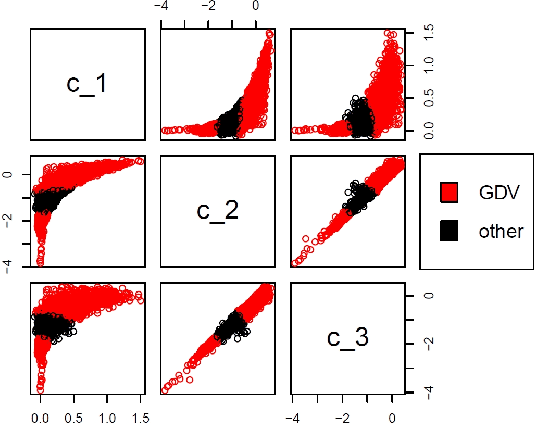
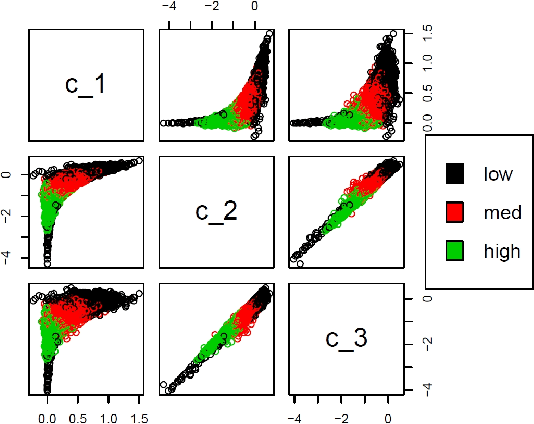
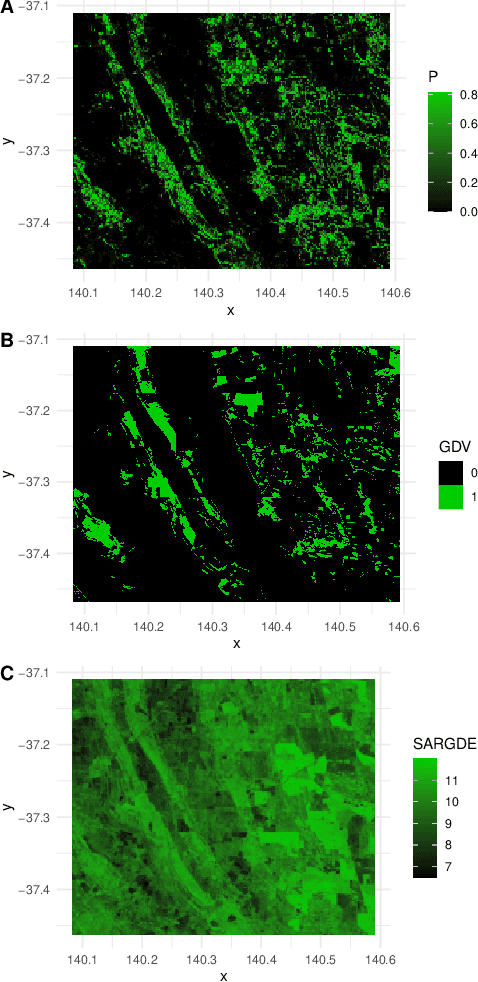
We state theoretical properties for $k$-means clustering of Symmetric Positive Definite (SPD) matrices, in a non-Euclidean space, that provides a natural and favourable representation of these data. We then provide a novel application for this method, to time-series clustering of pixels in a sequence of Synthetic Aperture Radar images, via their finite-lag autocovariance matrices.
Neural Random Projection: From the Initial Task To the Input Similarity Problem
Oct 09, 2020
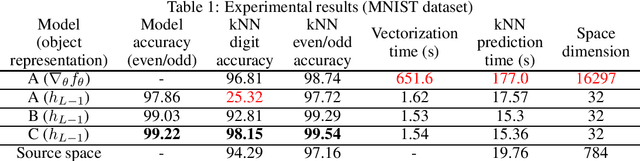
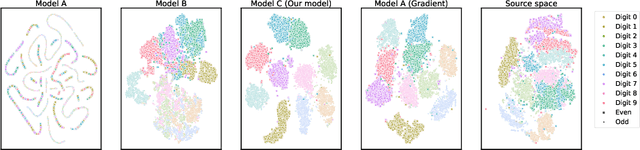
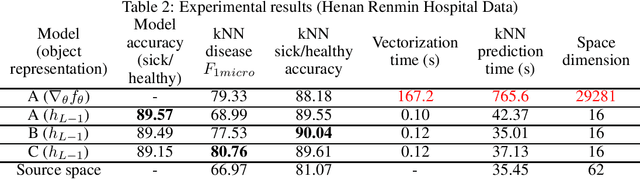
In this paper, we propose a novel approach for implicit data representation to evaluate similarity of input data using a trained neural network. In contrast to the previous approach, which uses gradients for representation, we utilize only the outputs from the last hidden layer of a neural network and do not use a backward step. The proposed technique explicitly takes into account the initial task and significantly reduces the size of the vector representation, as well as the computation time. The key point is minimization of information loss between layers. Generally, a neural network discards information that is not related to the problem, which makes the last hidden layer representation useless for input similarity task. In this work, we consider two main causes of information loss: correlation between neurons and insufficient size of the last hidden layer. To reduce the correlation between neurons we use orthogonal weight initialization for each layer and modify the loss function to ensure orthogonality of the weights during training. Moreover, we show that activation functions can potentially increase correlation. To solve this problem, we apply modified Batch-Normalization with Dropout. Using orthogonal weight matrices allow us to consider such neural networks as an application of the Random Projection method and get a lower bound estimate for the size of the last hidden layer. We perform experiments on MNIST and physical examination datasets. In both experiments, initially, we split a set of labels into two disjoint subsets to train a neural network for binary classification problem, and then use this model to measure similarity between input data and define hidden classes. Our experimental results show that the proposed approach achieves competitive results on the input similarity task while reducing both computation time and the size of the input representation.
Analyzing COVID-19 on Online Social Media: Trends, Sentiments and Emotions
Jun 05, 2020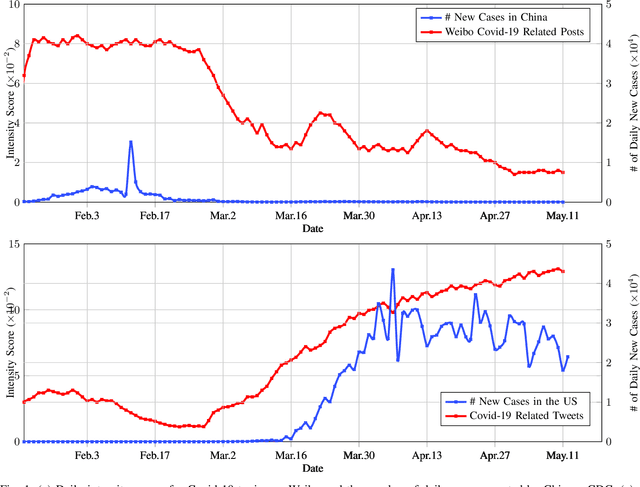
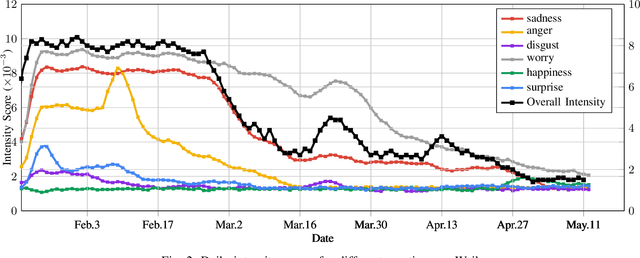
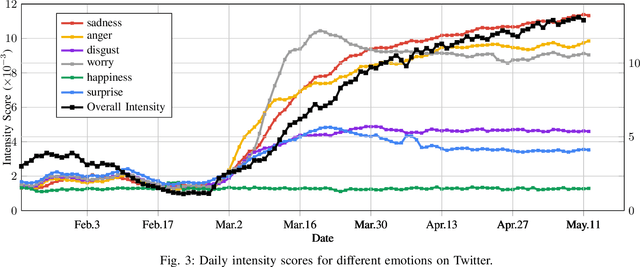
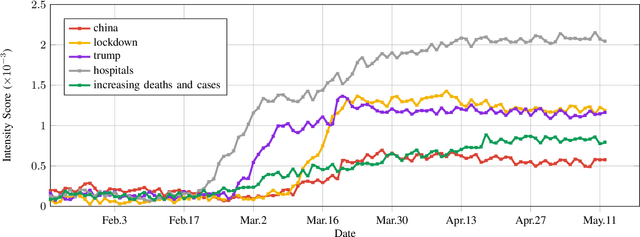
At the time of writing, the ongoing pandemic of coronavirus disease (COVID-19) has caused severe impacts on society, economy and people's daily lives. People constantly express their opinions on various aspects of the pandemic on social media, making user-generated content an important source for understanding public emotions and concerns. In this paper, we perform a comprehensive analysis on the affective trajectories of the American people and the Chinese people based on Twitter and Weibo posts between January 20th, 2020 and May 11th 2020. Specifically, by identifying people's sentiments, emotions (i.e., anger, disgust, fear, happiness, sadness, surprise) and the emotional triggers (e.g., what a user is angry/sad about) we are able to depict the dynamics of public affect in the time of COVID-19. By contrasting two very different countries, China and the Unites States, we reveal sharp differences in people's views on COVID-19 in different cultures. Our study provides a computational approach to unveiling public emotions and concerns on the pandemic in real-time, which would potentially help policy-makers better understand people's need and thus make optimal policy.
Depth as Attention for Face Representation Learning
Jan 03, 2021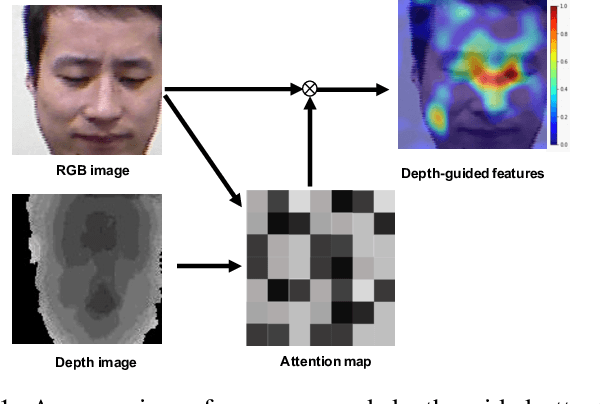
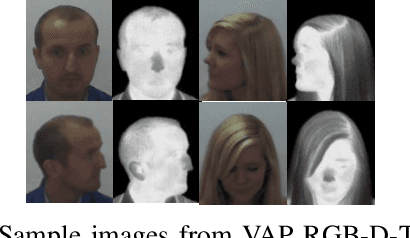
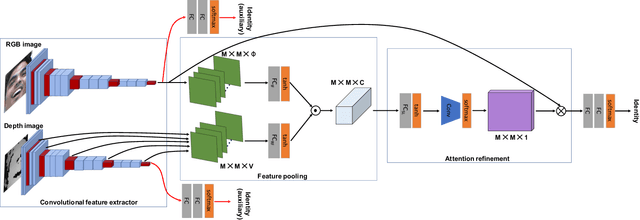
Face representation learning solutions have recently achieved great success for various applications such as verification and identification. However, face recognition approaches that are based purely on RGB images rely solely on intensity information, and therefore are more sensitive to facial variations, notably pose, occlusions, and environmental changes such as illumination and background. A novel depth-guided attention mechanism is proposed for deep multi-modal face recognition using low-cost RGB-D sensors. Our novel attention mechanism directs the deep network "where to look" for visual features in the RGB image by focusing the attention of the network using depth features extracted by a Convolution Neural Network (CNN). The depth features help the network focus on regions of the face in the RGB image that contains more prominent person-specific information. Our attention mechanism then uses this correlation to generate an attention map for RGB images from the depth features extracted by CNN. We test our network on four public datasets, showing that the features obtained by our proposed solution yield better results on the Lock3DFace, CurtinFaces, IIIT-D RGB-D, and KaspAROV datasets which include challenging variations in pose, occlusion, illumination, expression, and time-lapse. Our solution achieves average (increased) accuracies of 87.3\% (+5.0\%), 99.1\% (+0.9\%), 99.7\% (+0.6\%) and 95.3\%(+0.5\%) for the four datasets respectively, thereby improving the state-of-the-art. We also perform additional experiments with thermal images, instead of depth images, showing the high generalization ability of our solution when adopting other modalities for guiding the attention mechanism instead of depth information
Real-Time Community Detection in Large Social Networks on a Laptop
Sep 04, 2016


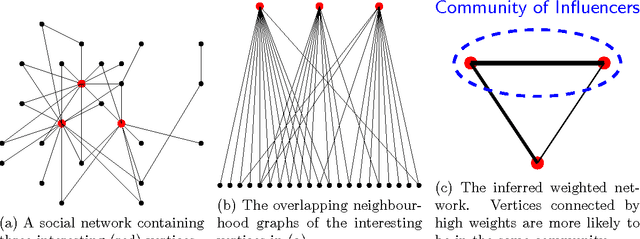
For a broad range of research, governmental and commercial applications it is important to understand the allegiances, communities and structure of key players in society. One promising direction towards extracting this information is to exploit the rich relational data in digital social networks (the social graph). As social media data sets are very large, most approaches make use of distributed computing systems for this purpose. Distributing graph processing requires solving many difficult engineering problems, which has lead some researchers to look at single-machine solutions that are faster and easier to maintain. In this article, we present a single-machine real-time system for large-scale graph processing that allows analysts to interactively explore graph structures. The key idea is that the aggregate actions of large numbers of users can be compressed into a data structure that encapsulates user similarities while being robust to noise and queryable in real-time. We achieve single machine real-time performance by compressing the neighbourhood of each vertex using minhash signatures and facilitate rapid queries through Locality Sensitive Hashing. These techniques reduce query times from hours using industrial desktop machines operating on the full graph to milliseconds on standard laptops. Our method allows exploration of strongly associated regions (i.e. communities) of large graphs in real-time on a laptop. It has been deployed in software that is actively used by social network analysts and offers another channel for media owners to monetise their data, helping them to continue to provide free services that are valued by billions of people globally.
QoS Aware Robot Trajectory Optimization with IRS-Assisted Millimeter-Wave Communications
Dec 19, 2020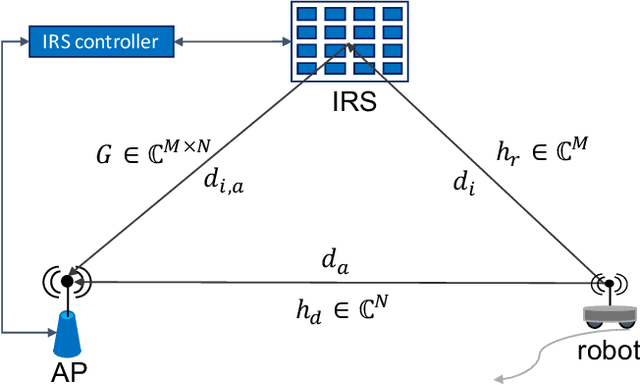
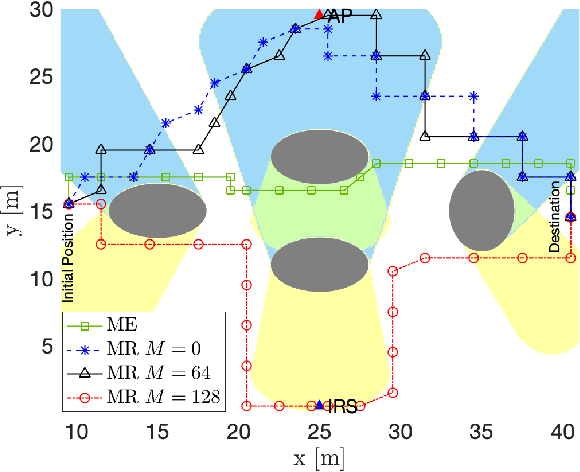
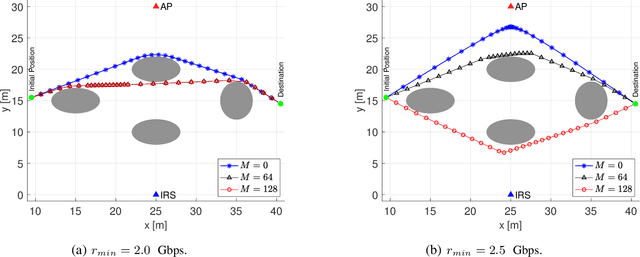
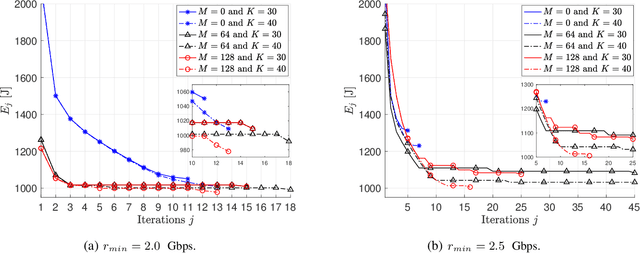
This paper considers the motion energy minimization problem for a wirelessly connected robot using millimeter-wave (mm-wave) communications. These are assisted by an intelligent reflective surface (IRS) that enhances the coverage at such high frequencies characterized by high blockage sensitivity. The robot is subject to time and uplink communication quality of service (QoS) constraints. This is a fundamental problem in fully automated factories that characterize Industry 4.0, where robots may have to perform tasks with given deadlines while maximizing the battery autonomy and communication efficiency. To account for the mutual dependence between robot position and communication QoS, we propose a joint optimization of robot trajectory and beamforming at the IRS and access point (AP). We present a solution that first exploits mm-wave channel characteristics to decouple beamforming and trajectory optimization. Then, the latter is solved by a successive-convex optimization-based algorithm. The algorithm takes into account the obstacles' positions and a radio map to avoid collisions and poorly covered areas. We prove that the algorithm can converge to a solution satisfying the Karush-Kuhn-Tucker (KKT) conditions. The simulation results show a dramatic reduction of the motion energy consumption with respect to methods that aim to find maximum-rate trajectories. Moreover, we show how the IRS and the beamforming optimization improve the motion energy efficiency of the robot.
Multi-Graph Tensor Networks
Nov 11, 2020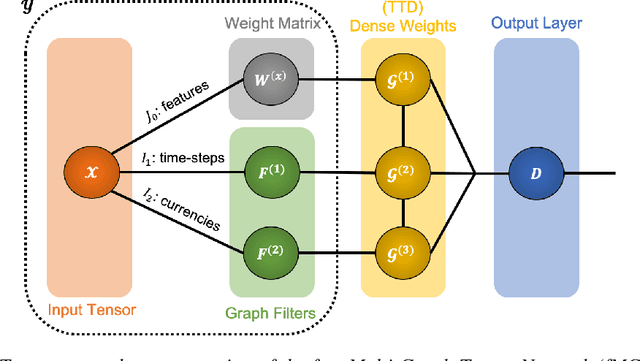
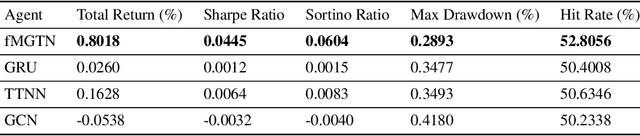
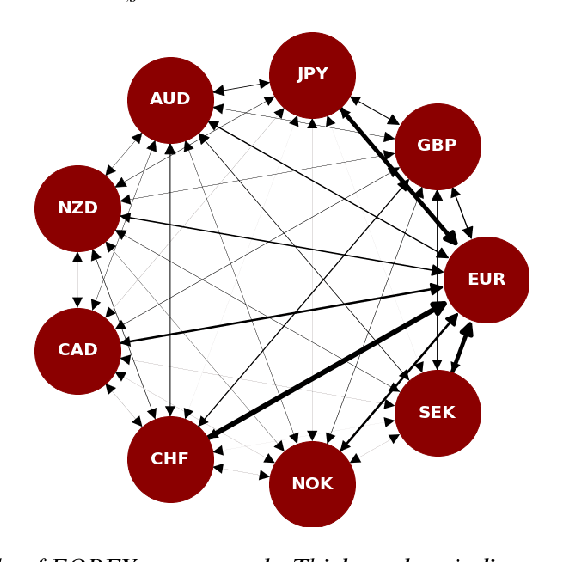
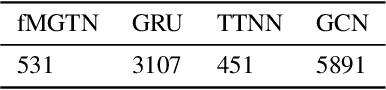
The irregular and multi-modal nature of numerous modern data sources poses serious challenges for traditional deep learning algorithms. To this end, recent efforts have generalized existing algorithms to irregular domains through graphs, with the aim to gain additional insights from data through the underlying graph topology. At the same time, tensor-based methods have demonstrated promising results in bypassing the bottlenecks imposed by the Curse of Dimensionality. In this paper, we introduce a novel Multi-Graph Tensor Network (MGTN) framework, which exploits both the ability of graphs to handle irregular data sources and the compression properties of tensor networks in a deep learning setting. The potential of the proposed framework is demonstrated through an MGTN based deep Q agent for Foreign Exchange (FOREX) algorithmic trading. By virtue of the MGTN, a FOREX currency graph is leveraged to impose an economically meaningful structure on this demanding task, resulting in a highly superior performance against three competing models and at a drastically lower complexity.
Measuring Data Collection Quality for Community Healthcare
Nov 05, 2020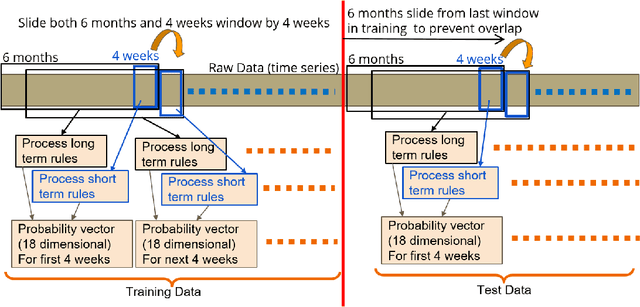
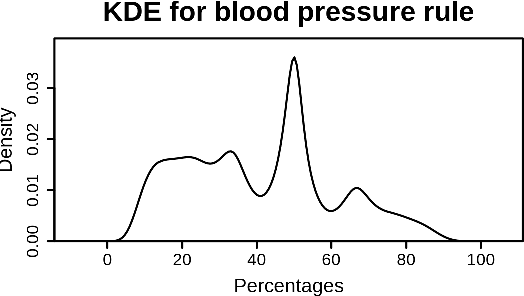
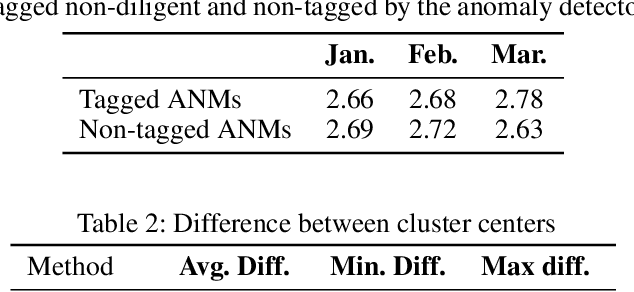
Machine learning has tremendous potential to provide targeted interventions in low-resource communities, however the availability of high-quality public health data is a significant challenge. In this work, we partner with field experts at an non-governmental organization (NGO) in India to define and test a data collection quality score for each health worker who collects data. This challenging unlabeled data problem is handled by building upon domain-expert's guidance to design a useful data representation that is then clustered to infer a data quality score. We also provide a more interpretable version of the score. These scores already provide for a measurement of data collection quality; in addition, we also predict the quality for future time steps and find our results to be very accurate. Our work was successfully field tested and is in the final stages of deployment in Rajasthan, India.