 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Multilingual Models with Language-Clustered Vocabularies
Oct 24, 2020

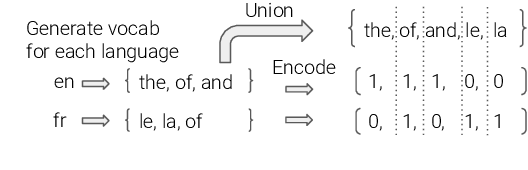
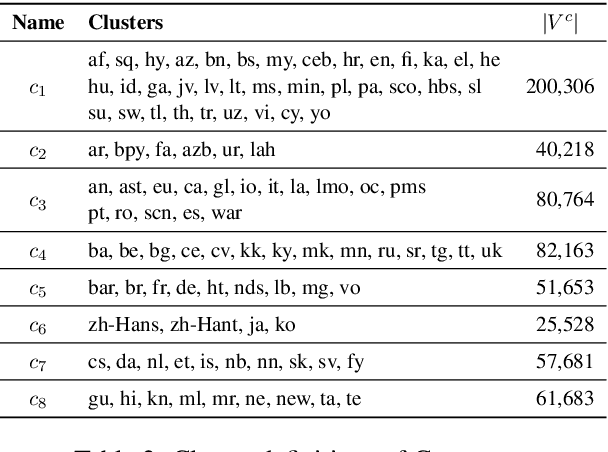
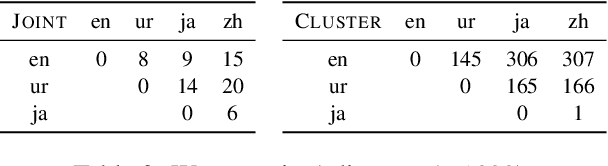
State-of-the-art multilingual models depend on vocabularies that cover all of the languages the model will expect to see at inference time, but the standard methods for generating those vocabularies are not ideal for massively multilingual applications. In this work, we introduce a novel procedure for multilingual vocabulary generation that combines the separately trained vocabularies of several automatically derived language clusters, thus balancing the trade-off between cross-lingual subword sharing and language-specific vocabularies. Our experiments show improvements across languages on key multilingual benchmark tasks TyDi QA (+2.9 F1), XNLI (+2.1\%), and WikiAnn NER (+2.8 F1) and factor of 8 reduction in out-of-vocabulary rate, all without increasing the size of the model or data.
Relation Extraction from Biomedical and Clinical Text: Unified Multitask Learning Framework
Sep 20, 2020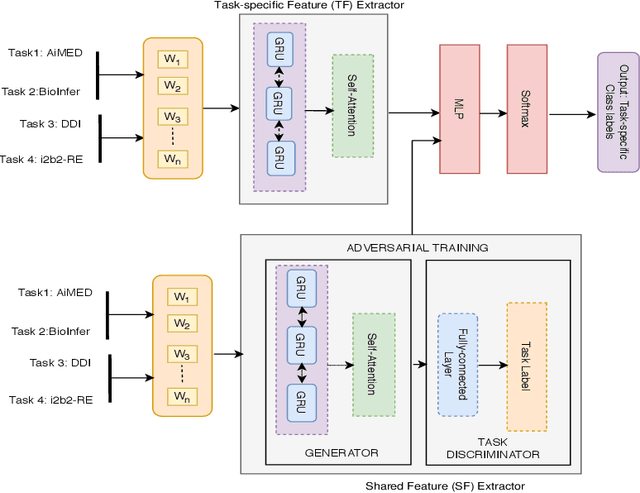

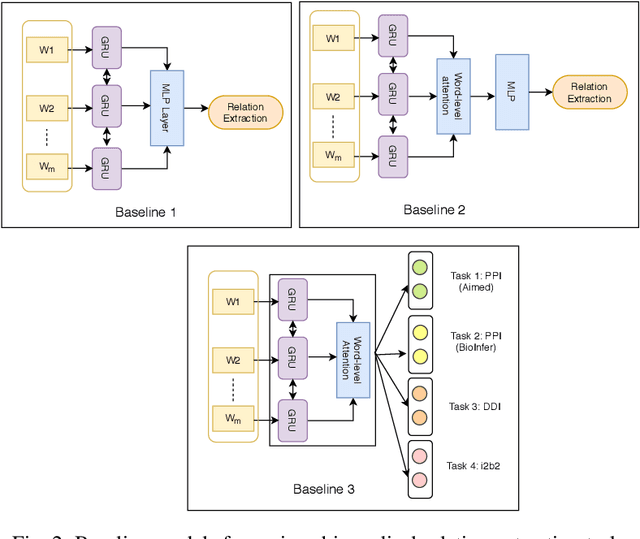
To minimize the accelerating amount of time invested in the biomedical literature search, numerous approaches for automated knowledge extraction have been proposed. Relation extraction is one such task where semantic relations between the entities are identified from the free text. In the biomedical domain, extraction of regulatory pathways, metabolic processes, adverse drug reaction or disease models necessitates knowledge from the individual relations, for example, physical or regulatory interactions between genes, proteins, drugs, chemical, disease or phenotype. In this paper, we study the relation extraction task from three major biomedical and clinical tasks, namely drug-drug interaction, protein-protein interaction, and medical concept relation extraction. Towards this, we model the relation extraction problem in multi-task learning (MTL) framework and introduce for the first time the concept of structured self-attentive network complemented with the adversarial learning approach for the prediction of relationships from the biomedical and clinical text. The fundamental notion of MTL is to simultaneously learn multiple problems together by utilizing the concepts of the shared representation. Additionally, we also generate the highly efficient single task model which exploits the shortest dependency path embedding learned over the attentive gated recurrent unit to compare our proposed MTL models. The framework we propose significantly improves overall the baselines (deep learning techniques) and single-task models for predicting the relationships, without compromising on the performance of all the tasks.
An Unsupervised method for OCR Post-Correction and Spelling Normalisation for Finnish
Nov 06, 2020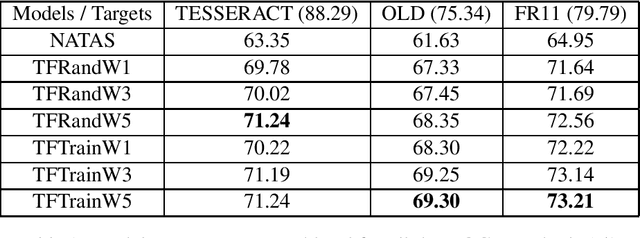
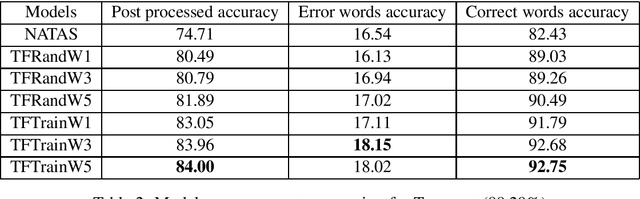
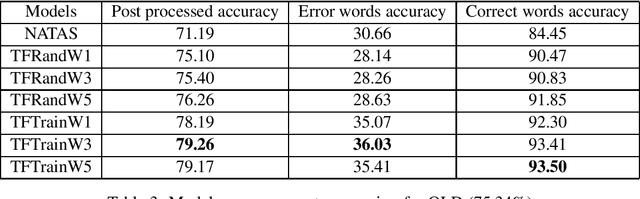
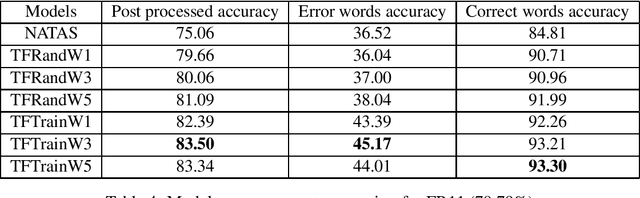
Historical corpora are known to contain errors introduced by OCR (optical character recognition) methods used in the digitization process, often said to be degrading the performance of NLP systems. Correcting these errors manually is a time-consuming process and a great part of the automatic approaches have been relying on rules or supervised machine learning. We build on previous work on fully automatic unsupervised extraction of parallel data to train a character-based sequence-to-sequence NMT (neural machine translation) model to conduct OCR error correction designed for English, and adapt it to Finnish by proposing solutions that take the rich morphology of the language into account. Our new method shows increased performance while remaining fully unsupervised, with the added benefit of spelling normalisation. The source code and models are available on GitHub and Zenodo.
Direct Policy Optimization using Deterministic Sampling and Collocation
Oct 16, 2020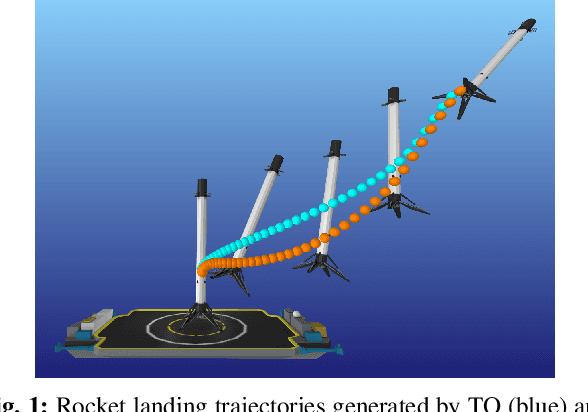
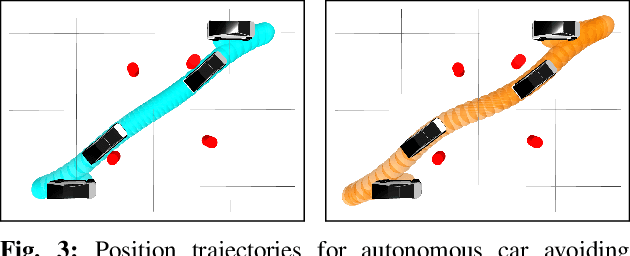
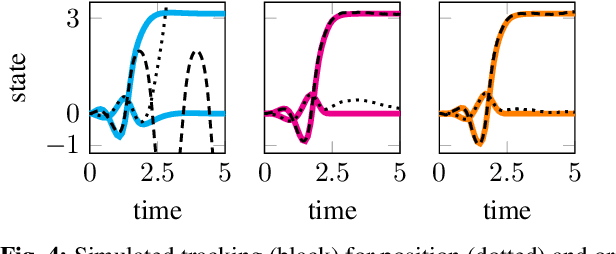
We present an approach for approximately solving discrete-time stochastic optimal control problems by combining direct trajectory optimization, deterministic sampling, and policy optimization. Our feedback motion planning algorithm uses a quasi-Newton method to simultaneously optimize a nominal trajectory, a set of deterministically chosen sample trajectories, and a parameterized policy. We demonstrate that this approach exactly recovers LQR policies in the case of linear dynamics, quadratic cost, and Gaussian noise. We also demonstrate the algorithm on several nonlinear, underactuated robotic systems to highlight its performance and ability to handle control limits, safely avoid obstacles, and generate robust plans in the presence of unmodeled dynamics.
LADDER: A Human-Level Bidding Agent for Large-Scale Real-Time Online Auctions
Sep 01, 2017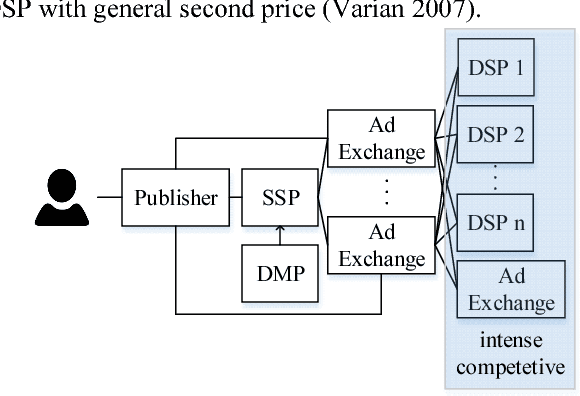
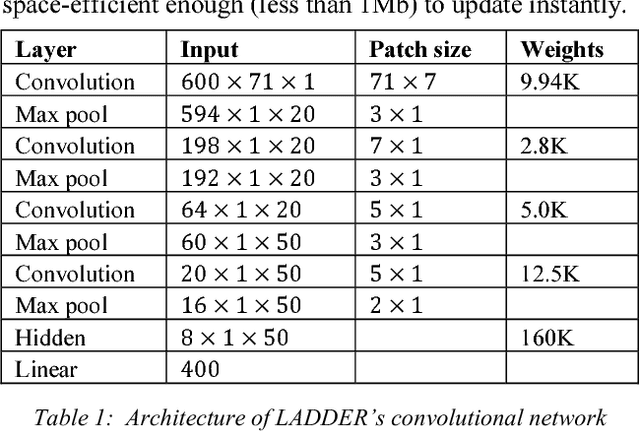
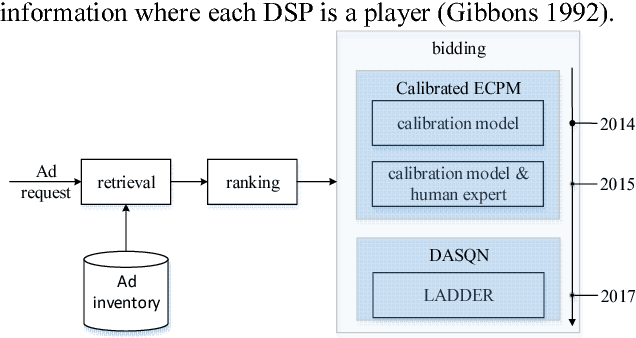
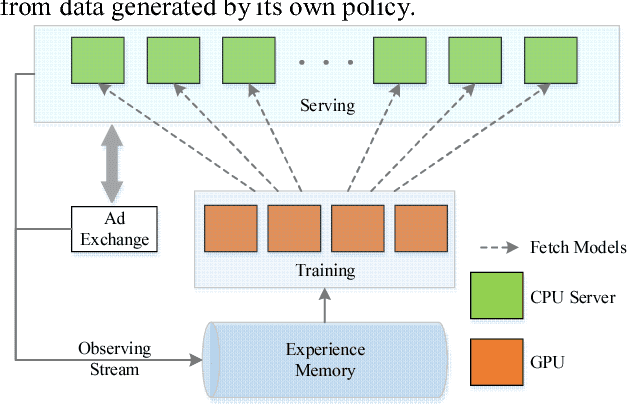
We present LADDER, the first deep reinforcement learning agent that can successfully learn control policies for large-scale real-world problems directly from raw inputs composed of high-level semantic information. The agent is based on an asynchronous stochastic variant of DQN (Deep Q Network) named DASQN. The inputs of the agent are plain-text descriptions of states of a game of incomplete information, i.e. real-time large scale online auctions, and the rewards are auction profits of very large scale. We apply the agent to an essential portion of JD's online RTB (real-time bidding) advertising business and find that it easily beats the former state-of-the-art bidding policy that had been carefully engineered and calibrated by human experts: during JD.com's June 18th anniversary sale, the agent increased the company's ads revenue from the portion by more than 50%, while the advertisers' ROI (return on investment) also improved significantly.
Accelerating combinatorial filter reduction through constraints
Nov 06, 2020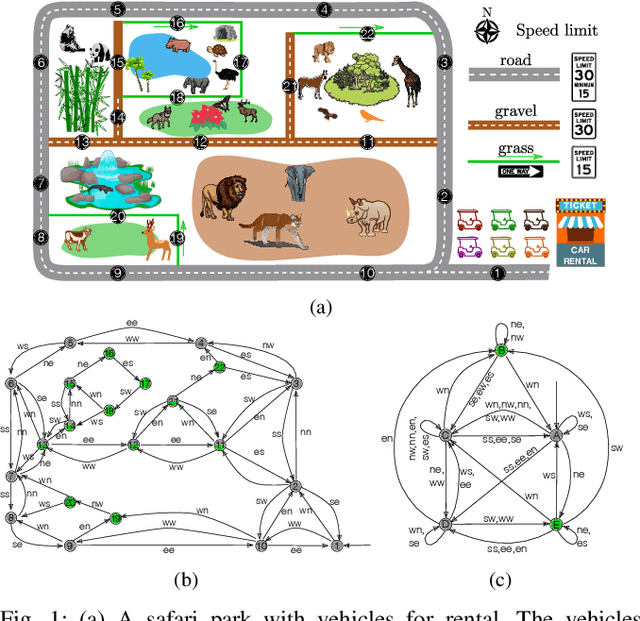
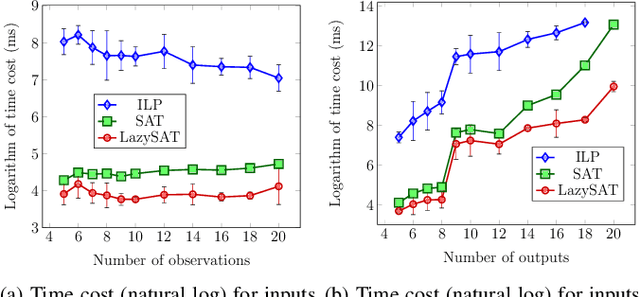

Reduction of combinatorial filters involves compressing state representations that robots use. Such optimization arises in automating the construction of minimalist robots. But exact combinatorial filter reduction is an NP-complete problem and all current techniques are either inexact or formalized with exponentially many constraints. This paper proposes a new formalization needing only a polynomial number of constraints, and characterizes these constraints in three different forms: nonlinear, linear, and conjunctive normal form. Empirical results show that constraints in conjunctive normal form capture the problem most effectively, leading to a method that outperforms the others. Further examination indicates that a substantial proportion of constraints remain inactive during iterative filter reduction. To leverage this observation, we introduce just-in-time generation of such constraints, which yields improvements in efficiency and has the potential to minimize large filters.
SAFARI: Safe and Active Robot Imitation Learning with Imagination
Nov 18, 2020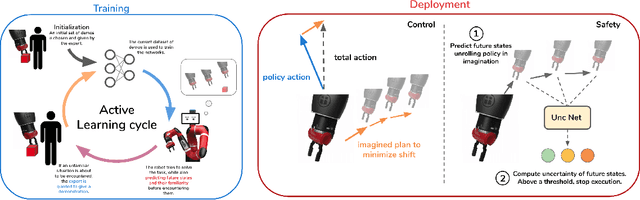
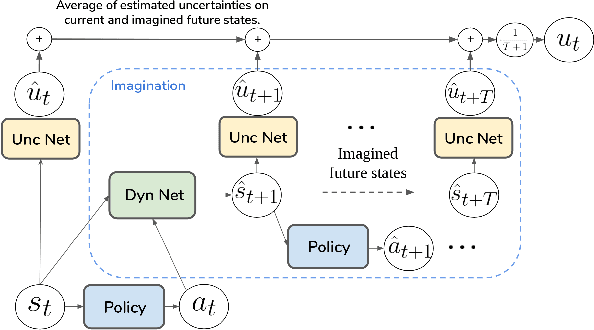
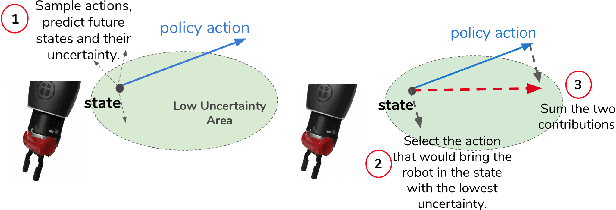

One of the main issues in Imitation Learning is the erroneous behavior of an agent when facing out-of-distribution situations, not covered by the set of demonstrations given by the expert. In this work, we tackle this problem by introducing a novel active learning and control algorithm, SAFARI. During training, it allows an agent to request further human demonstrations when these out-of-distribution situations are met. At deployment, it combines model-free acting using behavioural cloning with model-based planning to reduce state-distribution shift, using future state reconstruction as a test for state familiarity. We empirically demonstrate how this method increases the performance on a set of manipulation tasks with respect to passive Imitation Learning, by gathering more informative demonstrations and by minimizing state-distribution shift at test time. We also show how this method enables the agent to autonomously predict failure rapidly and safely.
Team Deep Mixture of Experts for Distributed Power Control
Jul 28, 2020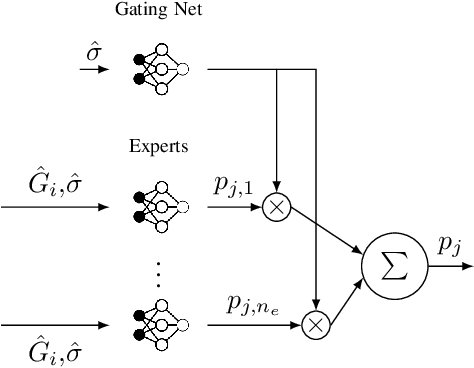
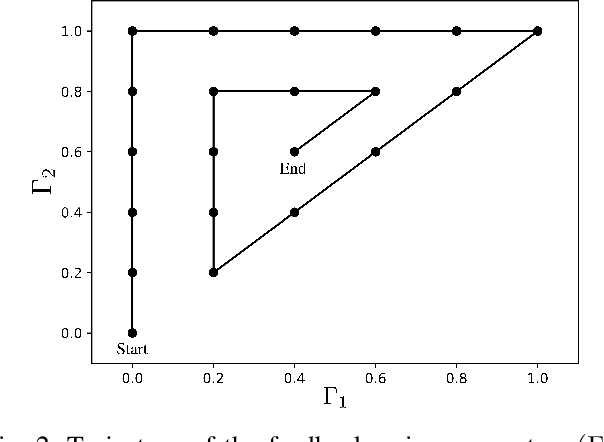
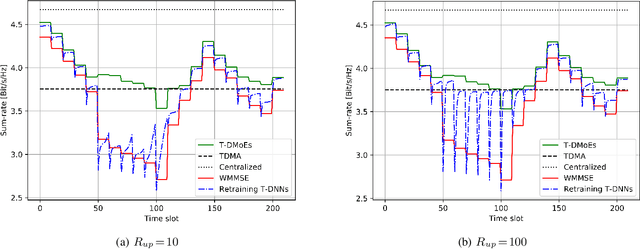

In the context of wireless networking, it was recently shown that multiple DNNs can be jointly trained to offer a desired collaborative behaviour capable of coping with a broad range of sensing uncertainties. In particular, it was established that DNNs can be used to derive policies that are robust with respect to the information noise statistic affecting the local information (e.g. CSI in a wireless network) used by each agent (e.g. transmitter) to make its decision. While promising, a major challenge in the implementation of such method is that information noise statistics may differ from agent to agent and, more importantly, that such statistics may not be available at the time of training or may evolve over time, making burdensome retraining necessary. This situation makes it desirable to devise a "universal" machine learning model, which can be trained once for all so as to allow for decentralized cooperation in any future feedback noise environment. With this goal in mind, we propose an architecture inspired from the well-known Mixture of Experts (MoE) model, which was previously used for non-linear regression and classification tasks in various contexts, such as computer vision and speech recognition. We consider the decentralized power control problem as an example to showcase the validity of the proposed model and to compare it against other power control algorithms. We show the ability of the so called Team-DMoE model to efficiently track time-varying statistical scenarios.
Prediction of Traffic Flow via Connected Vehicles
Jul 10, 2020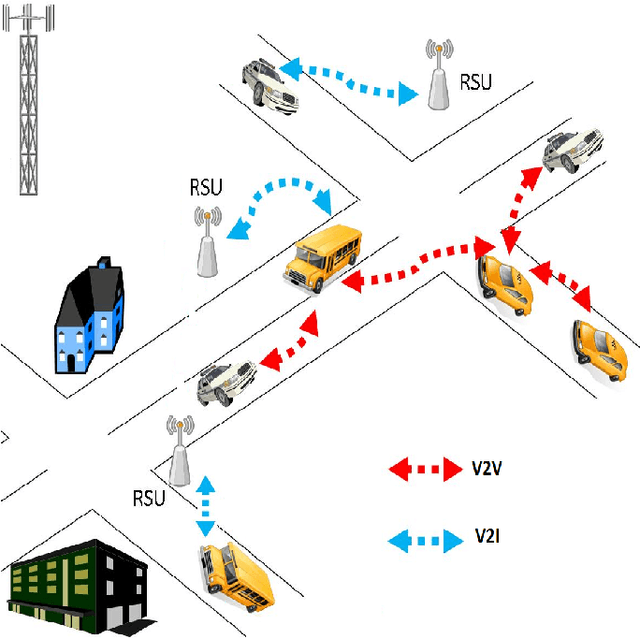
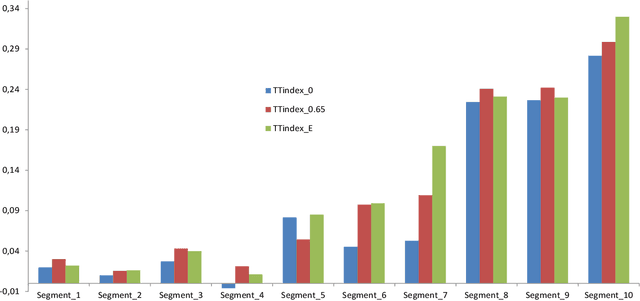
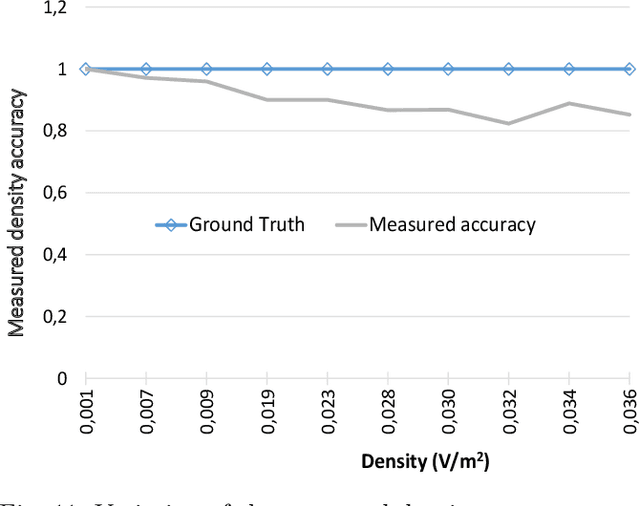
We propose a Short-term Traffic flow Prediction (STP) framework so that transportation authorities take early actions to control flow and prevent congestion. We anticipate flow at future time frames on a target road segment based on historical flow data and innovative features such as real time feeds and trajectory data provided by Connected Vehicles (CV) technology. To cope with the fact that existing approaches do not adapt to variation in traffic, we show how this novel approach allows advanced modelling by integrating into the forecasting of flow, the impact of the various events that CV realistically encountered on segments along their trajectory. We solve the STP problem with a Deep Neural Networks (DNN) in a multitask learning setting augmented by input from CV. Results show that our approach, namely MTL-CV, with an average Root-Mean-Square Error (RMSE) of 0.052, outperforms state-of-the-art ARIMA time series (RMSE of 0.255) and baseline classifiers (RMSE of 0.122). Compared to single task learning with Artificial Neural Network (ANN), ANN had a lower performance, 0.113 for RMSE, than MTL-CV. MTL-CV learned historical similarities between segments, in contrast to using direct historical trends in the measure, because trends may not exist in the measure but do in the similarities.
How should a fixed budget of dwell time be spent in scanning electron microscopy to optimize image quality?
Jan 12, 2018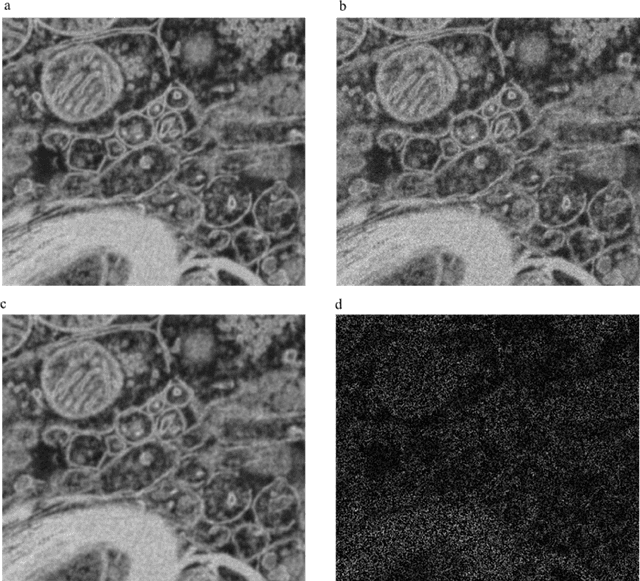
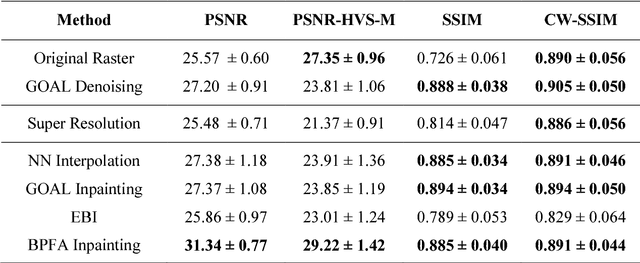

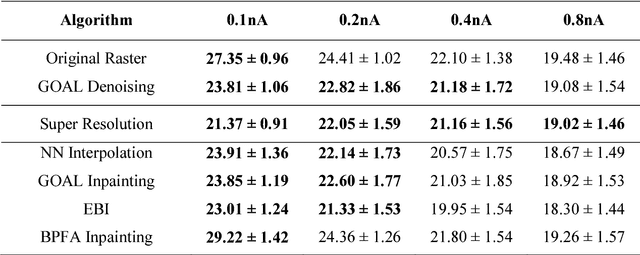
In scanning electron microscopy, the achievable image quality is often limited by a maximum feasible acquisition time per dataset. Particularly with regard to three-dimensional or large field-of-view imaging, a compromise must be found between a high amount of shot noise, which leads to a low signal-to-noise ratio, and excessive acquisition times. Assuming a fixed acquisition time per frame, we compared three different strategies for algorithm-assisted image acquisition in scanning electron microscopy. We evaluated (1) raster scanning with a reduced dwell time per pixel followed by a state-of-the-art Denoising algorithm, (2) raster scanning with a decreased resolution in conjunction with a state-of-the-art Super Resolution algorithm, and (3) a sparse scanning approach where a fixed percentage of pixels is visited by the beam in combination with state-of-the-art inpainting algorithms. Additionally, we considered increased beam currents for each of the strategies. The experiments showed that sparse scanning using an appropriate reconstruction technique was superior to the other strategies.