 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using Multiple Subwords to Improve English-Esperanto Automated Literary Translation Quality
Nov 28, 2020
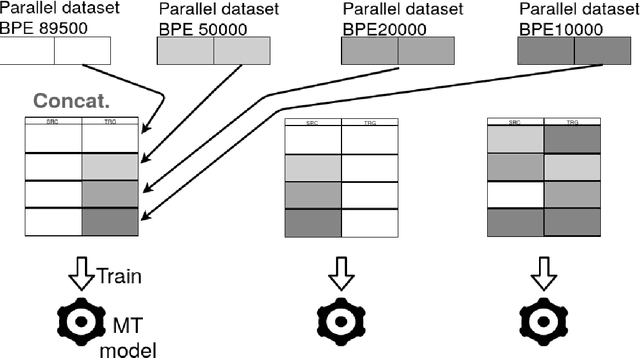
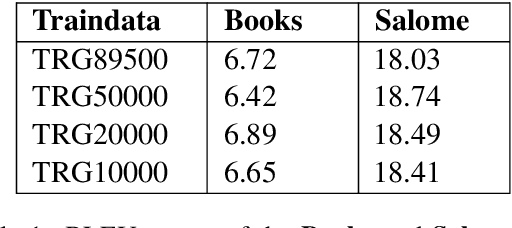
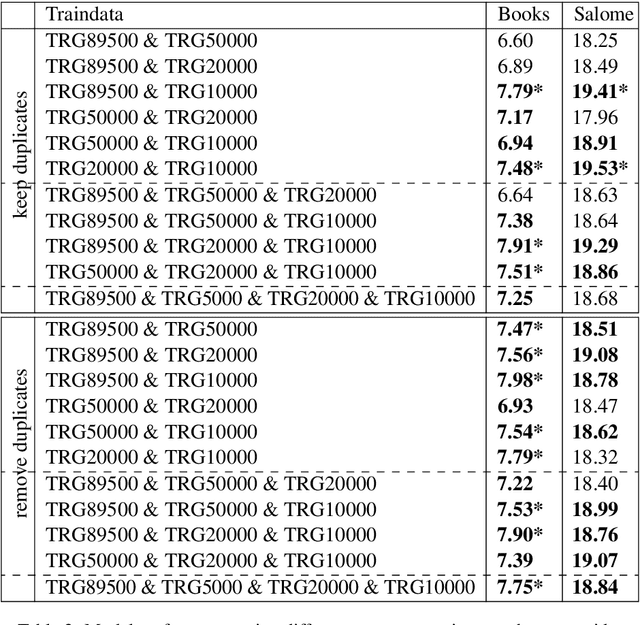
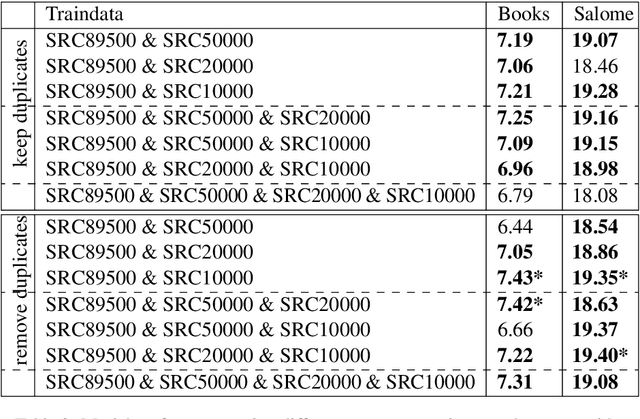
Building Machine Translation (MT) systems for low-resource languages remains challenging. For many language pairs, parallel data are not widely available, and in such cases MT models do not achieve results comparable to those seen with high-resource languages. When data are scarce, it is of paramount importance to make optimal use of the limited material available. To that end, in this paper we propose employing the same parallel sentences multiple times, only changing the way the words are split each time. For this purpose we use several Byte Pair Encoding models, with various merge operations used in their configuration. In our experiments, we use this technique to expand the available data and improve an MT system involving a low-resource language pair, namely English-Esperanto. As an additional contribution, we made available a set of English-Esperanto parallel data in the literary domain.
A General Machine Learning Framework for Survival Analysis
Jun 27, 2020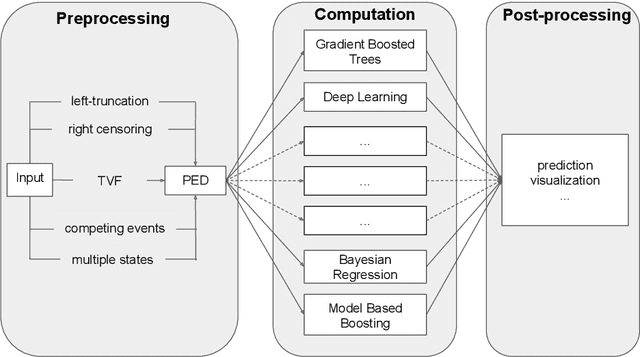

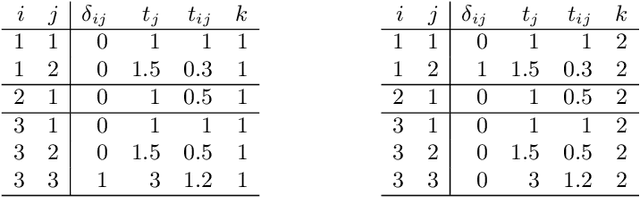
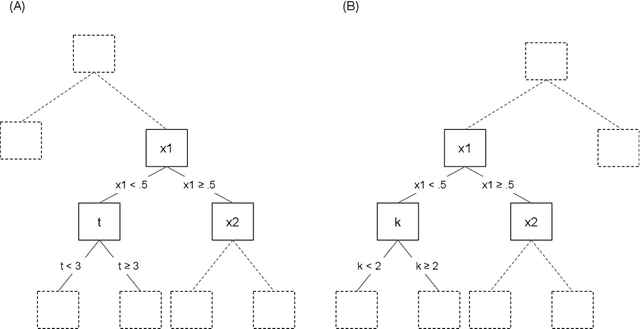
The modeling of time-to-event data, also known as survival analysis, requires specialized methods that can deal with censoring and truncation, time-varying features and effects, and that extend to settings with multiple competing events. However, many machine learning methods for survival analysis only consider the standard setting with right-censored data and proportional hazards assumption. The methods that do provide extensions usually address at most a subset of these challenges and often require specialized software that can not be integrated into standard machine learning workflows directly. In this work, we present a very general machine learning framework for time-to-event analysis that uses a data augmentation strategy to reduce complex survival tasks to standard Poisson regression tasks. This reformulation is based on well developed statistical theory. With the proposed approach, any algorithm that can optimize a Poisson (log-)likelihood, such as gradient boosted trees, deep neural networks, model-based boosting and many more can be used in the context of time-to-event analysis. The proposed technique does not require any assumptions with respect to the distribution of event times or the functional shapes of feature and interaction effects. Based on the proposed framework we develop new methods that are competitive with specialized state of the art approaches in terms of accuracy, and versatility, but with comparatively small investments of programming effort or requirements for specialized methodological know-how.
Agent-based Simulation Model and Deep Learning Techniques to Evaluate and Predict Transportation Trends around COVID-19
Sep 23, 2020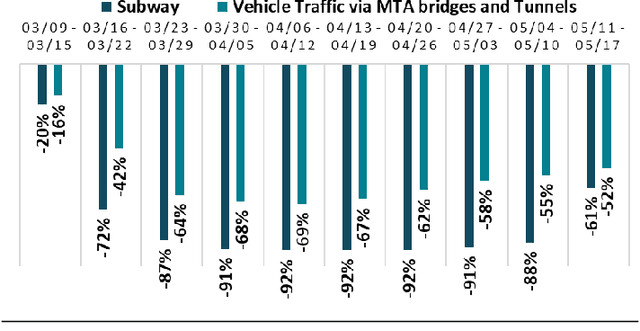

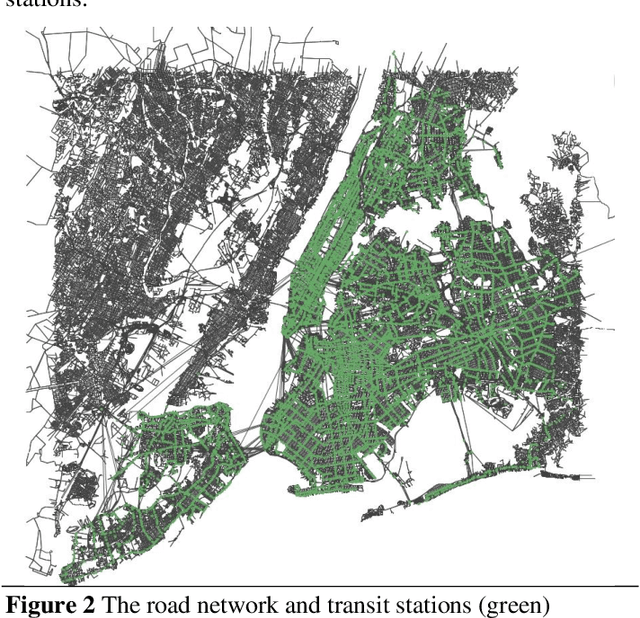
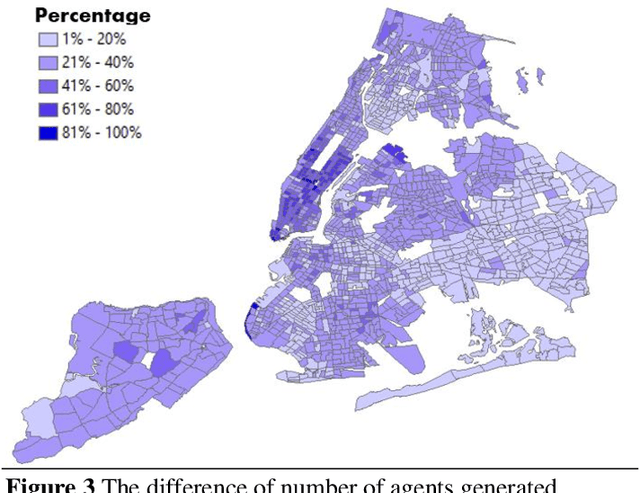
The COVID-19 pandemic has affected travel behaviors and transportation system operations, and cities are grappling with what policies can be effective for a phased reopening shaped by social distancing. This edition of the white paper updates travel trends and highlights an agent-based simulation model's results to predict the impact of proposed phased reopening strategies. It also introduces a real-time video processing method to measure social distancing through cameras on city streets.
Entropic Causal Inference: Identifiability and Finite Sample Results
Jan 10, 2021
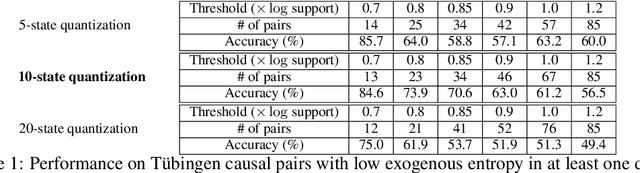
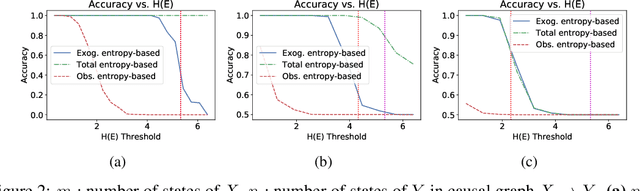
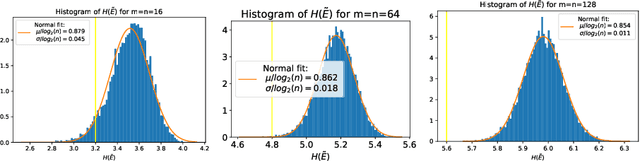
Entropic causal inference is a framework for inferring the causal direction between two categorical variables from observational data. The central assumption is that the amount of unobserved randomness in the system is not too large. This unobserved randomness is measured by the entropy of the exogenous variable in the underlying structural causal model, which governs the causal relation between the observed variables. Kocaoglu et al. conjectured that the causal direction is identifiable when the entropy of the exogenous variable is not too large. In this paper, we prove a variant of their conjecture. Namely, we show that for almost all causal models where the exogenous variable has entropy that does not scale with the number of states of the observed variables, the causal direction is identifiable from observational data. We also consider the minimum entropy coupling-based algorithmic approach presented by Kocaoglu et al., and for the first time demonstrate algorithmic identifiability guarantees using a finite number of samples. We conduct extensive experiments to evaluate the robustness of the method to relaxing some of the assumptions in our theory and demonstrate that both the constant-entropy exogenous variable and the no latent confounder assumptions can be relaxed in practice. We also empirically characterize the number of observational samples needed for causal identification. Finally, we apply the algorithm on Tuebingen cause-effect pairs dataset.
Optimising Design Verification Using Machine Learning: An Open Source Solution
Dec 04, 2020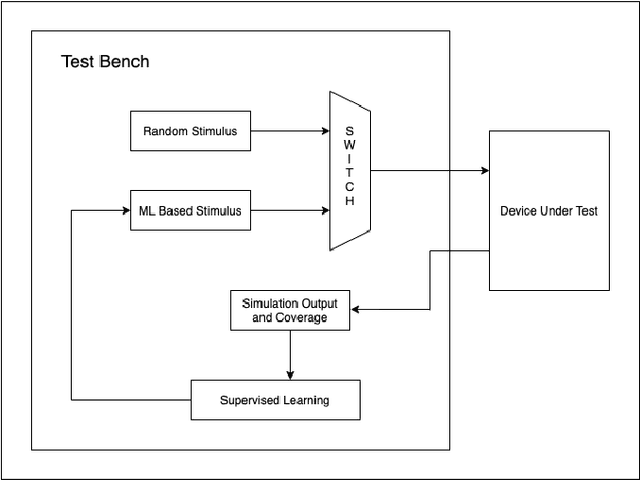

With the complexity of Integrated Circuits increasing, design verification has become the most time consuming part of the ASIC design flow. Nearly 70% of the SoC design cycle is consumed by verification. The most commonly used approach to test all corner cases is through the use of Constrained Random Verification. Random stimulus is given in order to hit all possible combinations and test the design thoroughly. However, this approach often requires significant human expertise to reach all corner cases. This paper presents an alternative using Machine Learning to generate the input stimulus. This will allow for faster thorough verification of the design with less human intervention. Furthermore, it is proposed to use the open source verification environment 'Cocotb'. Based on Python, it is simple, intuitive and has a vast library of functions for machine learning applications. This makes it more convenient to use than the bulkier approach using traditional Hardware Verification Languages such as System Verilog or Specman E.
Multi-Decoder Networks with Multi-Denoising Inputs for Tumor Segmentation
Nov 16, 2020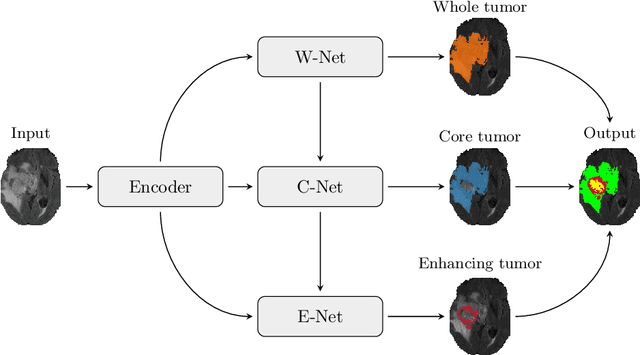
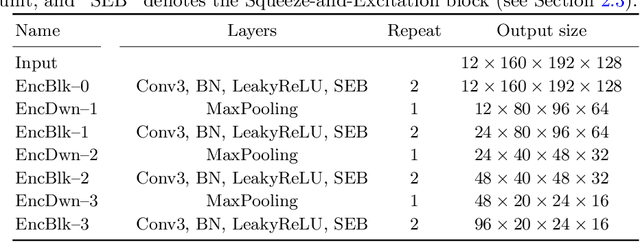
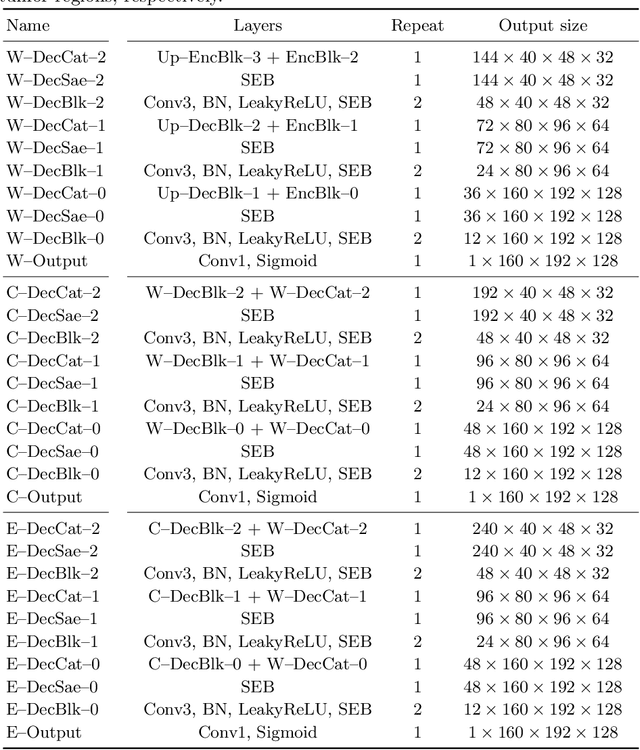
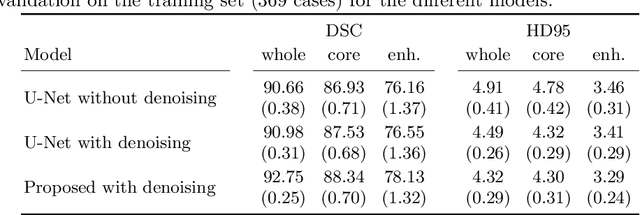
Automatic segmentation of brain glioma from multimodal MRI scans plays a key role in clinical trials and practice. Unfortunately, manual segmentation is very challenging, time-consuming, costly, and often inaccurate despite human expertise due to the high variance and high uncertainty in the human annotations. In the present work, we develop an end-to-end deep-learning-based segmentation method using a multi-decoder architecture by jointly learning three separate sub-problems using a partly shared encoder. We also propose to apply smoothing methods to the input images to generate denoised versions as additional inputs to the network. The validation performance indicate an improvement when using the proposed method. The proposed method was ranked 2nd in the task of Quantification of Uncertainty in Segmentation in the Brain Tumors in Multimodal Magnetic Resonance Imaging Challenge 2020.
Sparse Longitudinal Representations of Electronic Health Record Data for the Early Detection of Chronic Kidney Disease in Diabetic Patients
Nov 09, 2020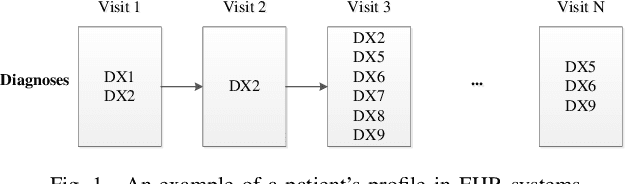
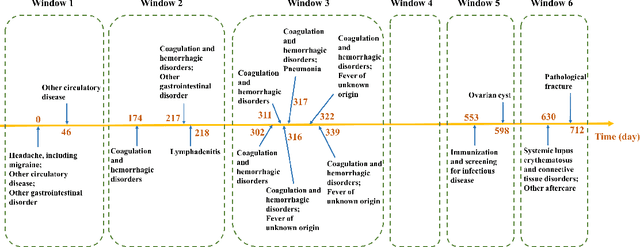
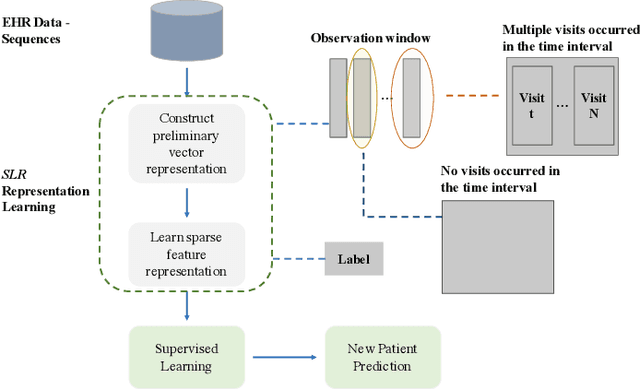
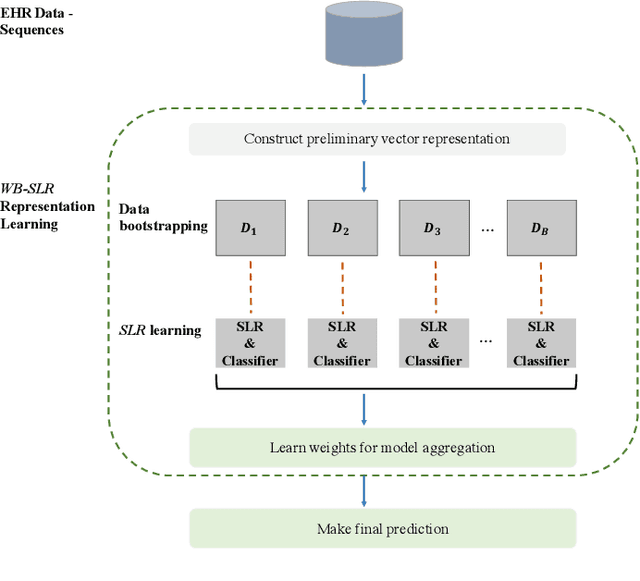
Chronic kidney disease (CKD) is a gradual loss of renal function over time, and it increases the risk of mortality, decreased quality of life, as well as serious complications. The prevalence of CKD has been increasing in the last couple of decades, which is partly due to the increased prevalence of diabetes and hypertension. To accurately detect CKD in diabetic patients, we propose a novel framework to learn sparse longitudinal representations of patients' medical records. The proposed method is also compared with widely used baselines such as Aggregated Frequency Vector and Bag-of-Pattern in Sequences on real EHR data, and the experimental results indicate that the proposed model achieves higher predictive performance. Additionally, the learned representations are interpreted and visualized to bring clinical insights.
Non-linear State-space Model Identification from Video Data using Deep Encoders
Dec 14, 2020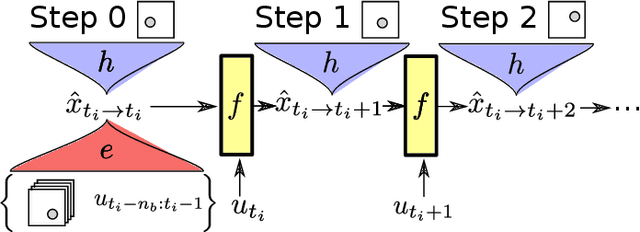
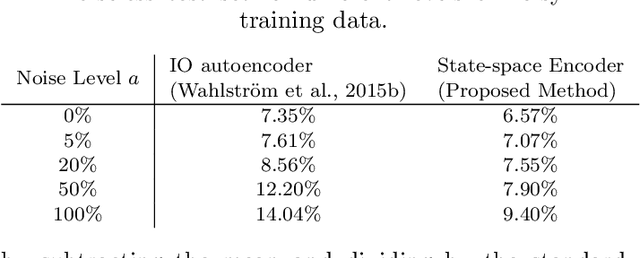
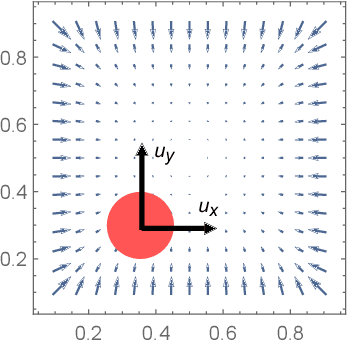

Identifying systems with high-dimensional inputs and outputs, such as systems measured by video streams, is a challenging problem with numerous applications in robotics, autonomous vehicles and medical imaging. In this paper, we propose a novel non-linear state-space identification method starting from high-dimensional input and output data. Multiple computational and conceptual advances are combined to handle the high-dimensional nature of the data. An encoder function, represented by a neural network, is introduced to learn a reconstructability map to estimate the model states from past inputs and outputs. This encoder function is jointly learned with the dynamics. Furthermore, multiple computational improvements, such as an improved reformulation of multiple shooting and batch optimization, are proposed to keep the computational time under control when dealing with high-dimensional and large datasets. We apply the proposed method to a video stream of a simulated environment of a controllable ball in a unit box. The simulation study shows low simulation error with excellent long term prediction for the obtained model using the proposed method.
Predicting Landsat Reflectance with Deep Generative Fusion
Nov 09, 2020
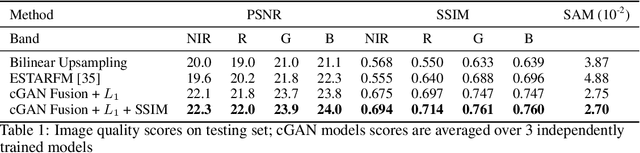
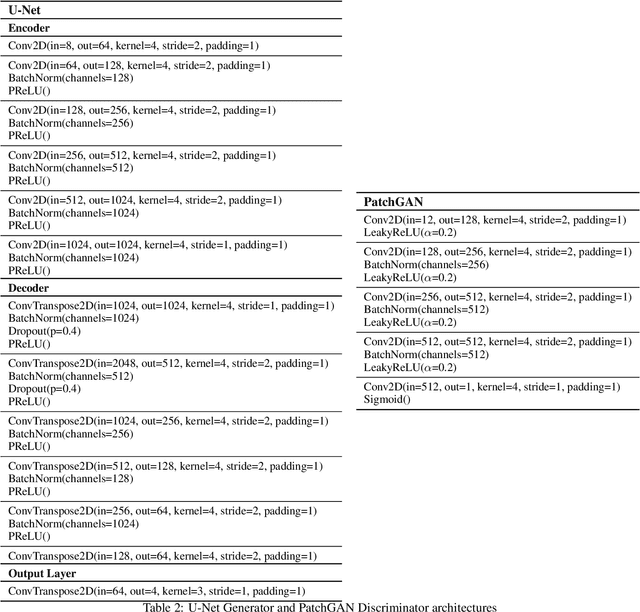
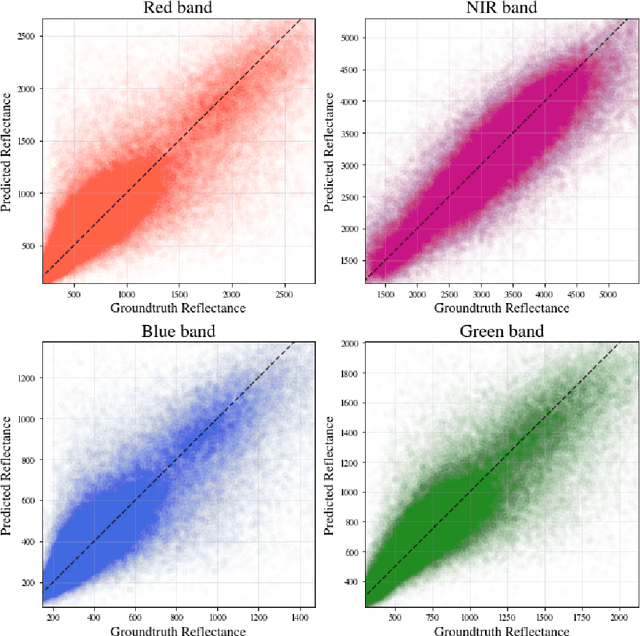
Public satellite missions are commonly bound to a trade-off between spatial and temporal resolution as no single sensor provides fine-grained acquisitions with frequent coverage. This hinders their potential to assist vegetation monitoring or humanitarian actions, which require detecting rapid and detailed terrestrial surface changes. In this work, we probe the potential of deep generative models to produce high-resolution optical imagery by fusing products with different spatial and temporal characteristics. We introduce a dataset of co-registered Moderate Resolution Imaging Spectroradiometer (MODIS) and Landsat surface reflectance time series and demonstrate the ability of our generative model to blend coarse daily reflectance information into low-paced finer acquisitions. We benchmark our proposed model against state-of-the-art reflectance fusion algorithms.
Push, Stop, and Replan: An Application of Pebble Motion on Graphs to Planning in Automated Warehouses
Jul 20, 2020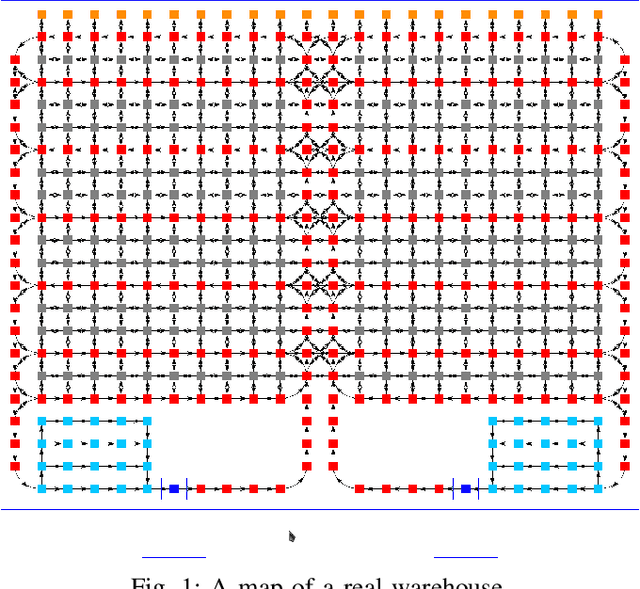
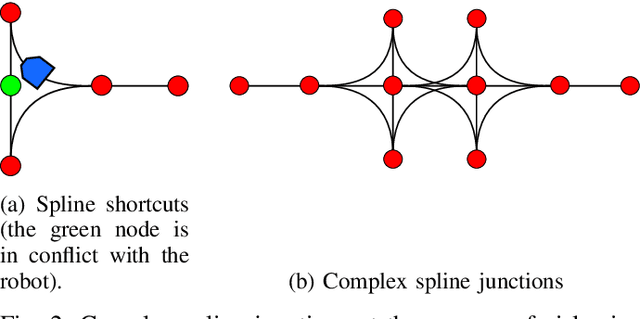
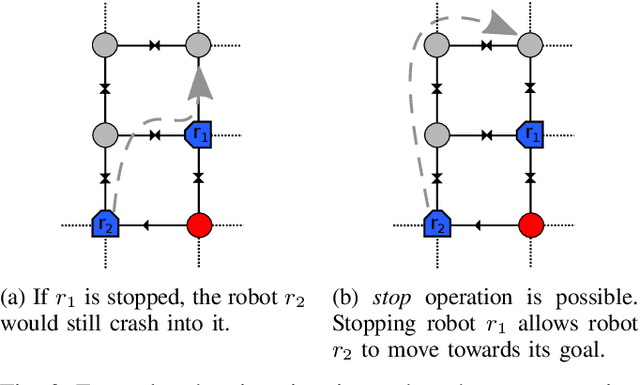
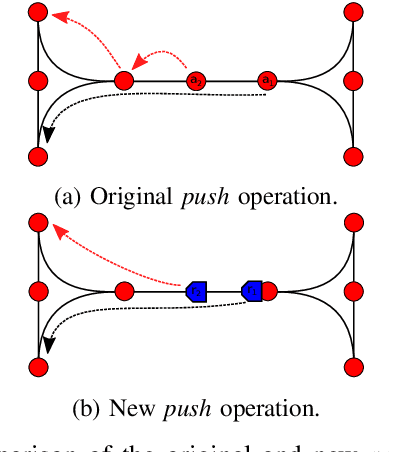
The pebble-motion on graphs is a subcategory of multi-agent pathfinding problems dealing with moving multiple pebble-like objects from a node to a node in a graph with a constraint that only one pebble can occupy one node at a given time. Additionally, algorithms solving this problem assume that individual pebbles (robots) cannot move at the same time and their movement is discrete. These assumptions disqualify them from being directly used in practical applications, although they have otherwise nice theoretical properties. We present modifications of the Push and Rotate algorithm [1], which relax the presumptions mentioned above and demonstrate, through a set of experiments, that the modified algorithm is applicable for planning in automated warehouses.