 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SAFCAR: Structured Attention Fusion for Compositional Action Recognition
Dec 17, 2020
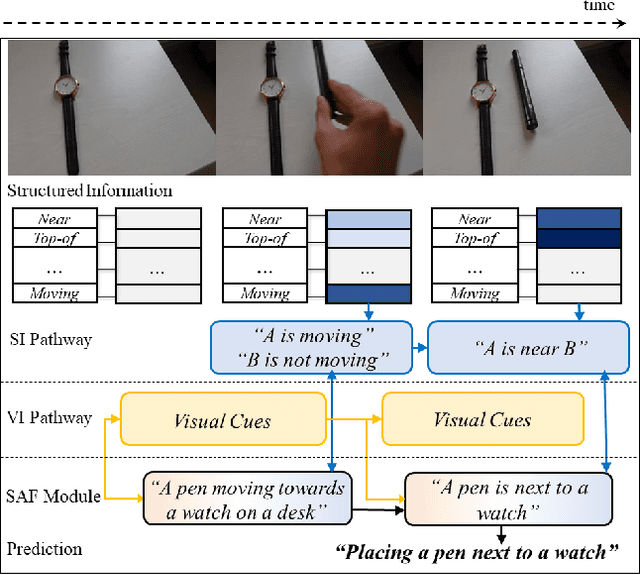
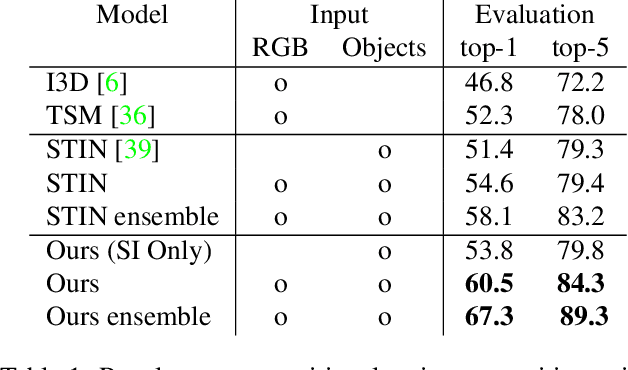
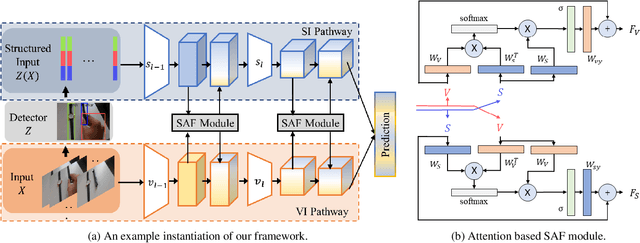
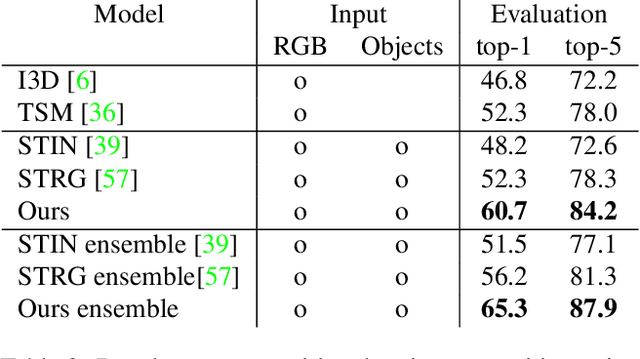
We present a general framework for compositional action recognition -- i.e. action recognition where the labels are composed out of simpler components such as subjects, atomic-actions and objects. The main challenge in compositional action recognition is that there is a combinatorially large set of possible actions that can be composed using basic components. However, compositionality also provides a structure that can be exploited. To do so, we develop and test a novel Structured Attention Fusion (SAF) self-attention mechanism to combine information from object detections, which capture the time-series structure of an action, with visual cues that capture contextual information. We show that our approach recognizes novel verb-noun compositions more effectively than current state of the art systems, and it generalizes to unseen action categories quite efficiently from only a few labeled examples. We validate our approach on the challenging Something-Else tasks from the Something-Something-V2 dataset. We further show that our framework is flexible and can generalize to a new domain by showing competitive results on the Charades-Fewshot dataset.
Ensembles of Randomized Time Series Shapelets Provide Improved Accuracy while Reducing Computational Costs
Feb 22, 2017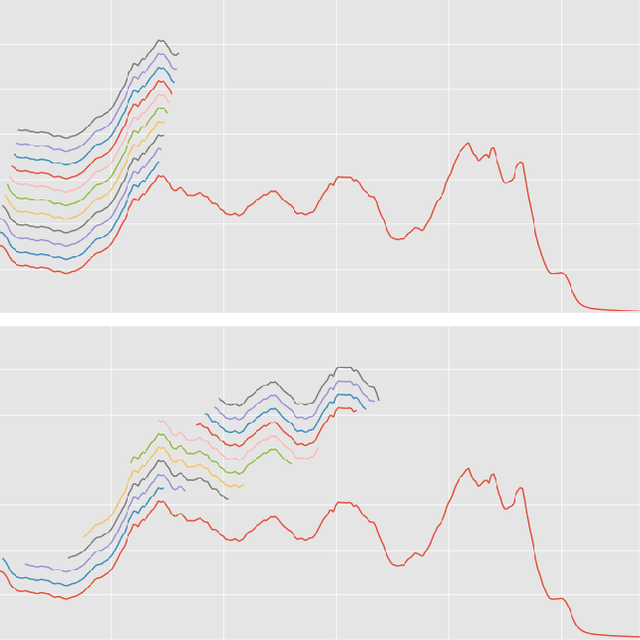
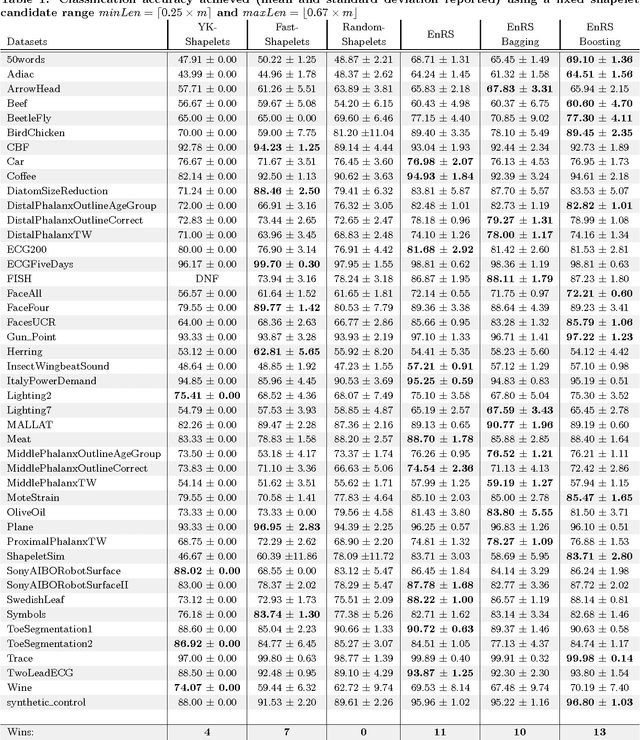
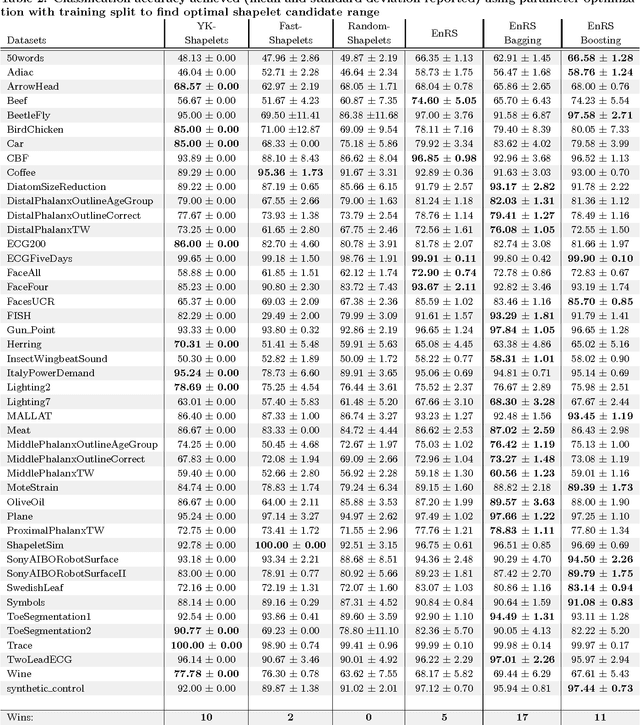
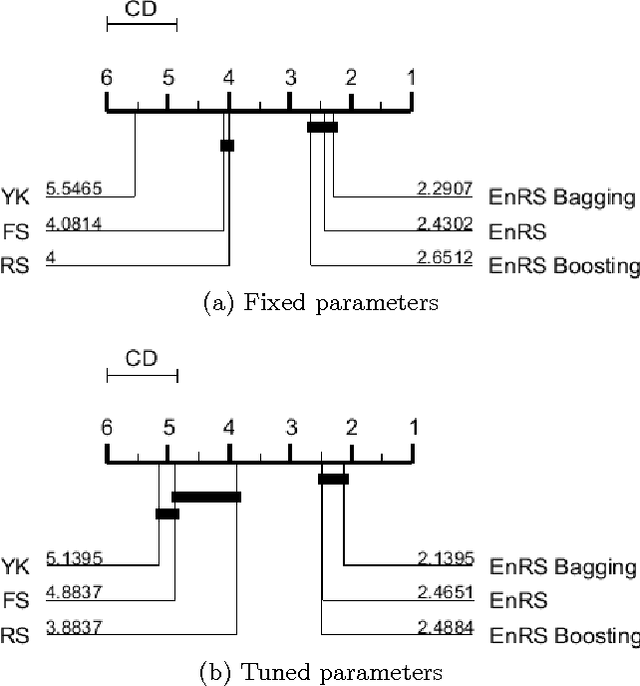
Shapelets are discriminative time series subsequences that allow generation of interpretable classification models, which provide faster and generally better classification than the nearest neighbor approach. However, the shapelet discovery process requires the evaluation of all possible subsequences of all time series in the training set, making it extremely computation intensive. Consequently, shapelet discovery for large time series datasets quickly becomes intractable. A number of improvements have been proposed to reduce the training time. These techniques use approximation or discretization and often lead to reduced classification accuracy compared to the exact method. We are proposing the use of ensembles of shapelet-based classifiers obtained using random sampling of the shapelet candidates. Using random sampling reduces the number of evaluated candidates and consequently the required computational cost, while the classification accuracy of the resulting models is also not significantly different than that of the exact algorithm. The combination of randomized classifiers rectifies the inaccuracies of individual models because of the diversity of the solutions. Based on the experiments performed, it is shown that the proposed approach of using an ensemble of inexpensive classifiers provides better classification accuracy compared to the exact method at a significantly lesser computational cost.
A Legged Soft Robot Platform for Dynamic Locomotion
Nov 13, 2020
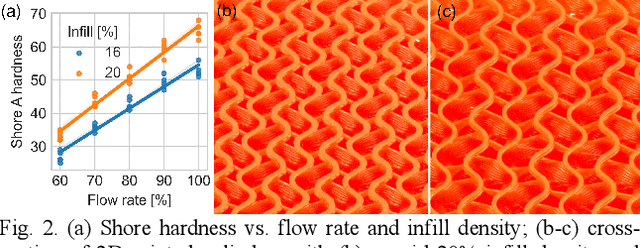

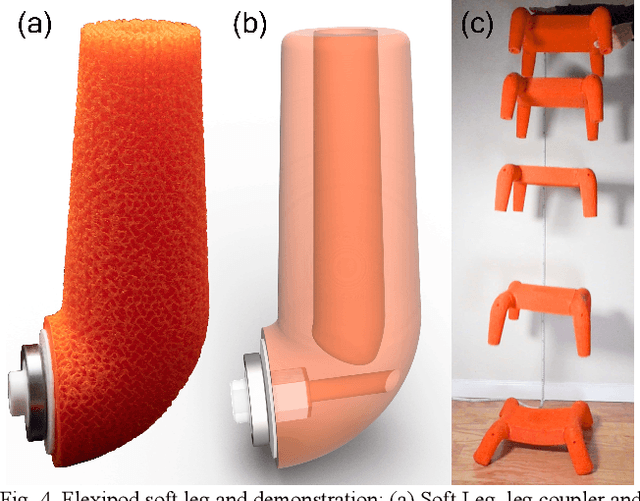
We present an open-source untethered quadrupedal soft robot platform for dynamic locomotion (e.g., high-speed running and backflipping). The robot is mostly soft (80 vol.%) while driven by four geared servo motors. The robot's soft body and soft legs were 3D printed with gyroid infill using a flexible material, enabling it to conform to the environment and passively stabilize during locomotion on multi-terrain environments. In addition, we simulated the robot in a real-time soft body simulation. With tuned gaits in simulation, the real robot can locomote at a speed of 0.9 m/s (2.5 body length/second), substantially faster than most untethered legged soft robots published to date. We hope this platform, along with its verified simulator, can catalyze the development of soft robotics.
Improved Runtime Results for Simple Randomised Search Heuristics on Linear Functions with a Uniform Constraint
Oct 21, 2020In the last decade remarkable progress has been made in development of suitable proof techniques for analysing randomised search heuristics. The theoretical investigation of these algorithms on classes of functions is essential to the understanding of the underlying stochastic process. Linear functions have been traditionally studied in this area resulting in tight bounds on the expected optimisation time of simple randomised search algorithms for this class of problems. Recently, the constrained version of this problem has gained attention and some theoretical results have also been obtained on this class of problems. In this paper we study the class of linear functions under uniform constraint and investigate the expected optimisation time of Randomised Local Search (RLS) and a simple evolutionary algorithm called (1+1) EA. We prove a tight bound of $\Theta(n^2)$ for RLS and improve the previously best known upper bound of (1+1) EA from $O(n^2 \log (Bw_{\max}))$ to $O(n^2\log B)$ in expectation and to $O(n^2 \log n)$ with high probability, where $w_{\max}$ and $B$ are the maximum weight of the linear objective function and the bound of the uniform constraint, respectively. Also, we obtain a tight bound of $O(n^2)$ for the (1+1) EA on a special class of instances. We complement our theoretical studies by experimental investigations that consider different values of $B$ and also higher mutation rates that reflect the fact that $2$-bit flips are crucial for dealing with the uniform constraint.
Kinematic Resolutions of Redundant Robot Manipulators using Integration-Enhanced RNNs
Aug 19, 2020

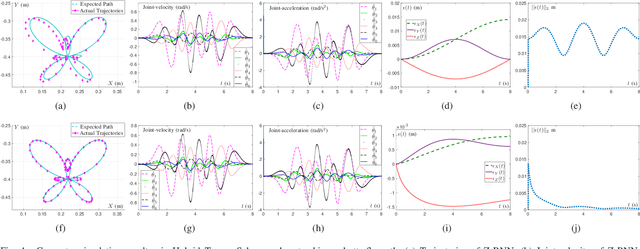
Recently, a time-varying quadratic programming (QP) framework that describes the tracking operations of redundant robot manipulators is introduced to handle the kinematic resolutions of many robot control tasks. Based on the generalization of such a time-varying QP framework, two schemes, i.e., the Repetitive Motion Scheme and the Hybrid Torque Scheme, are proposed. However, measurement noises are unavoidable when a redundant robot manipulator is executing a tracking task. To solve this problem, a novel integration-enhanced recurrent neural network (IE-RNN) is proposed in this paper. Associating with the aforementioned two schemes, the tracking task can be accurately completed by IE-RNN. Both theoretical analyses and simulations results prove that the residual errors of IE-RNN can converge to zero under different kinds of measurement noises. Moreover, practical experiments are elaborately made to verify the excellent convergence and strong robustness properties of the proposed IE-RNN.
AI-enabled Prediction of eSports Player Performance Using the Data from Heterogeneous Sensors
Dec 07, 2020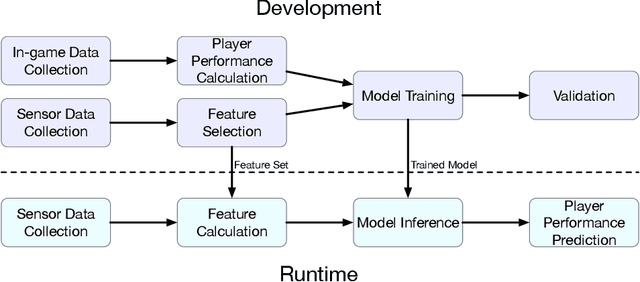

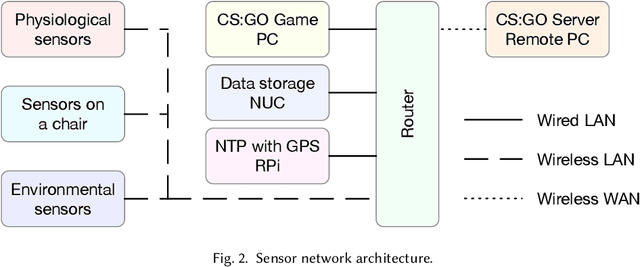
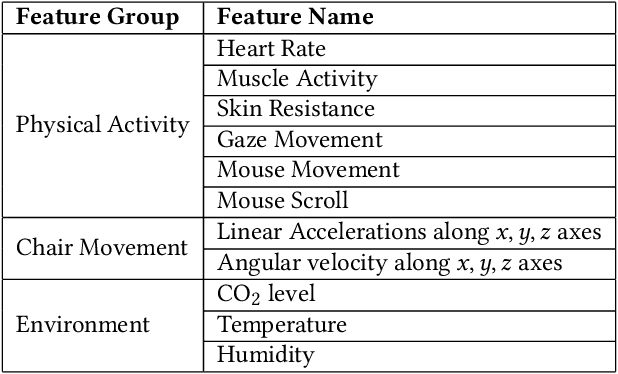
The emerging progress of eSports lacks the tools for ensuring high-quality analytics and training in Pro and amateur eSports teams. We report on an Artificial Intelligence (AI) enabled solution for predicting the eSports player in-game performance using exclusively the data from sensors. For this reason, we collected the physiological, environmental, and the game chair data from Pro and amateur players. The player performance is assessed from the game logs in a multiplayer game for each moment of time using a recurrent neural network. We have investigated that attention mechanism improves the generalization of the network and provides the straightforward feature importance as well. The best model achieves ROC AUC score 0.73. The prediction of the performance of particular player is realized although his data are not utilized in the training set. The proposed solution has a number of promising applications for Pro eSports teams as well as a learning tool for amateur players.
Low-rank Tensor Bandits
Jul 31, 2020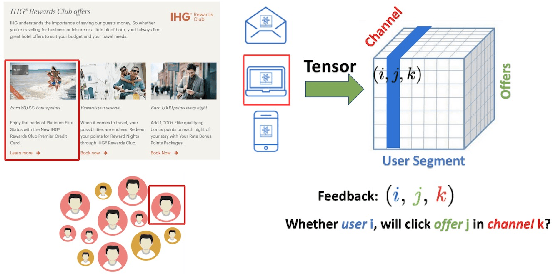
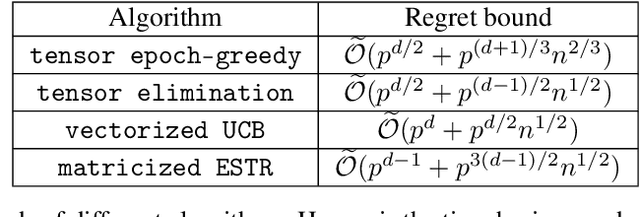
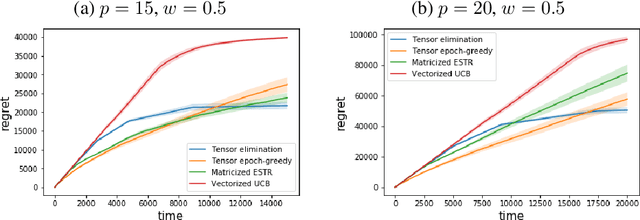
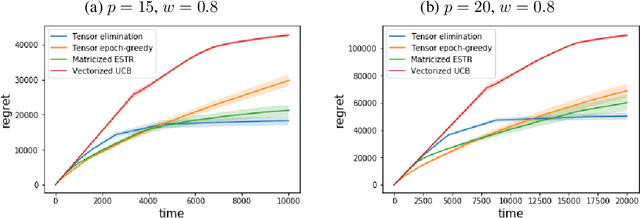
In recent years, multi-dimensional online decision making has been playing a crucial role in many practical applications such as online recommendation and digital marketing. To solve it, we introduce stochastic low-rank tensor bandits, a class of bandits whose mean rewards can be represented as a low-rank tensor. We propose two learning algorithms, tensor epoch-greedy and tensor elimination, and develop finite-time regret bounds for them. We observe that tensor elimination has an optimal dependency on the time horizon, while tensor epoch-greedy has a sharper dependency on tensor dimensions. Numerical experiments further back up these theoretical findings and show that our algorithms outperform various state-of-the-art approaches that ignore the tensor low-rank structure.
Generating Large-Scale Trajectories Efficiently using Double Descriptions of Polynomials
Nov 06, 2020
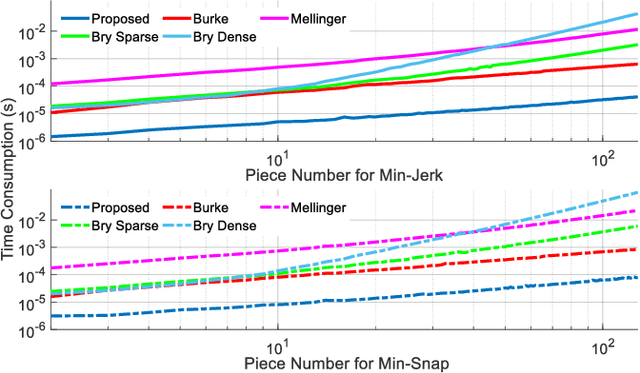
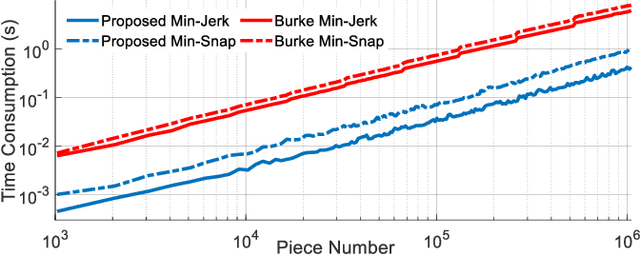
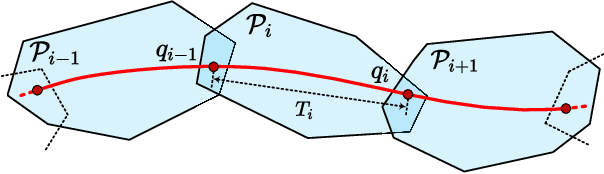
For quadrotor trajectory planning, describing a polynomial trajectory through coefficients and end-derivatives both enjoy their own convenience in energy minimization. We name them double descriptions of polynomial trajectories. The transformation between them, causing most of the inefficiency and instability, is formally analyzed in this paper. Leveraging its analytic structure, we design a linear-complexity scheme for both jerk/snap minimization and parameter gradient evaluation, which possesses efficiency, stability, flexibility, and scalability. With the help of our scheme, generating an energy optimal (minimum snap) trajectory only costs 1 $\mu s$ per piece at the scale up to 1,000,000 pieces. Moreover, generating large-scale energy-time optimal trajectories is also accelerated by an order of magnitude against conventional methods.
Zero-Cost Proxies for Lightweight NAS
Jan 20, 2021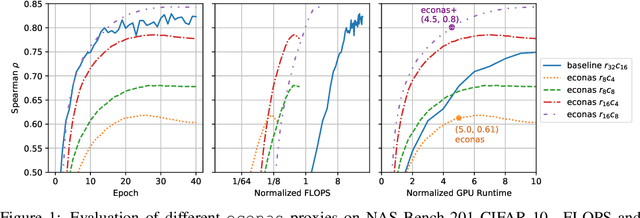

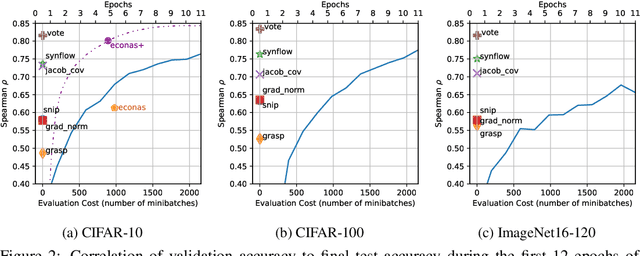

Neural Architecture Search (NAS) is quickly becoming the standard methodology to design neural network models. However, NAS is typically compute-intensive because multiple models need to be evaluated before choosing the best one. To reduce the computational power and time needed, a proxy task is often used for evaluating each model instead of full training. In this paper, we evaluate conventional reduced-training proxies and quantify how well they preserve ranking between multiple models during search when compared with the rankings produced by final trained accuracy. We propose a series of zero-cost proxies, based on recent pruning literature, that use just a single minibatch of training data to compute a model's score. Our zero-cost proxies use 3 orders of magnitude less computation but can match and even outperform conventional proxies. For example, Spearman's rank correlation coefficient between final validation accuracy and our best zero-cost proxy on NAS-Bench-201 is 0.82, compared to 0.61 for EcoNAS (a recently proposed reduced-training proxy). Finally, we use these zero-cost proxies to enhance existing NAS search algorithms such as random search, reinforcement learning, evolutionary search and predictor-based search. For all search methodologies and across three different NAS datasets, we are able to significantly improve sample efficiency, and thereby decrease computation, by using our zero-cost proxies. For example on NAS-Bench-101, we achieved the same accuracy 4$\times$ quicker than the best previous result.
On the performance of deep learning for numerical optimization: an application to protein structure prediction
Dec 17, 2020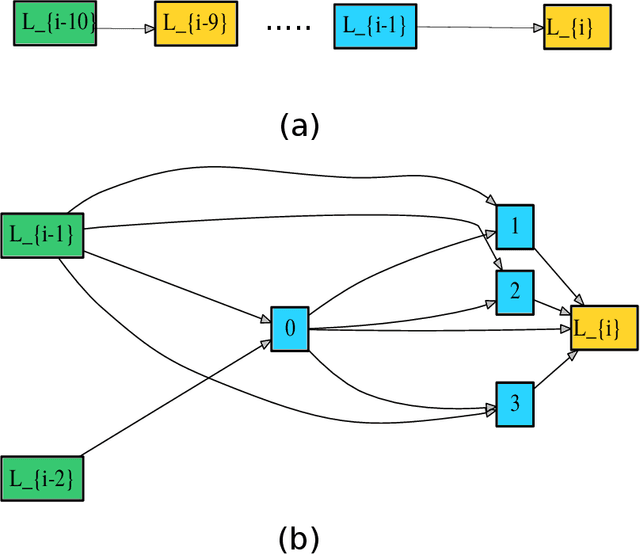
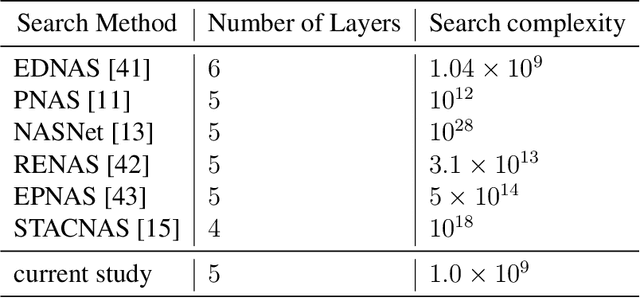
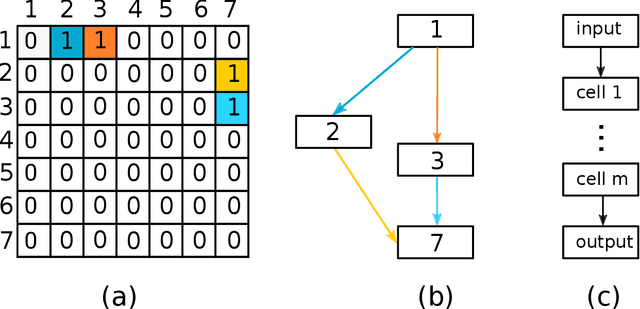
Deep neural networks have recently drawn considerable attention to build and evaluate artificial learning models for perceptual tasks. Here, we present a study on the performance of the deep learning models to deal with global optimization problems. The proposed approach adopts the idea of the neural architecture search (NAS) to generate efficient neural networks for solving the problem at hand. The space of network architectures is represented using a directed acyclic graph and the goal is to find the best architecture to optimize the objective function for a new, previously unknown task. Different from proposing very large networks with GPU computational burden and long training time, we focus on searching for lightweight implementations to find the best architecture. The performance of NAS is first analyzed through empirical experiments on CEC 2017 benchmark suite. Thereafter, it is applied to a set of protein structure prediction (PSP) problems. The experiments reveal that the generated learning models can achieve competitive results when compared to hand-designed algorithms; given enough computational budget