 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoFLUX: Distillation-Driven Compression of Large Text-to-Image Generation Models for Mobile Devices
Feb 06, 2026While large-scale text-to-image diffusion models continue to improve in visual quality, their increasing scale has widened the gap between state-of-the-art models and on-device solutions. To address this gap, we introduce NanoFLUX, a 2.4B text-to-image flow-matching model distilled from 17B FLUX.1-Schnell using a progressive compression pipeline designed to preserve generation quality. Our contributions include: (1) A model compression strategy driven by pruning redundant components in the diffusion transformer, reducing its size from 12B to 2B; (2) A ResNet-based token downsampling mechanism that reduces latency by allowing intermediate blocks to operate on lower-resolution tokens while preserving high-resolution processing elsewhere; (3) A novel text encoder distillation approach that leverages visual signals from early layers of the denoiser during sampling. Empirically, NanoFLUX generates 512 x 512 images in approximately 2.5 seconds on mobile devices, demonstrating the feasibility of high-quality on-device text-to-image generation.
RFDM: Residual Flow Diffusion Model for Efficient Causal Video Editing
Feb 06, 2026Instructional video editing applies edits to an input video using only text prompts, enabling intuitive natural-language control. Despite rapid progress, most methods still require fixed-length inputs and substantial compute. Meanwhile, autoregressive video generation enables efficient variable-length synthesis, yet remains under-explored for video editing. We introduce a causal, efficient video editing model that edits variable-length videos frame by frame. For efficiency, we start from a 2D image-to-image (I2I) diffusion model and adapt it to video-to-video (V2V) editing by conditioning the edit at time step t on the model's prediction at t-1. To leverage videos' temporal redundancy, we propose a new I2I diffusion forward process formulation that encourages the model to predict the residual between the target output and the previous prediction. We call this Residual Flow Diffusion Model (RFDM), which focuses the denoising process on changes between consecutive frames. Moreover, we propose a new benchmark that better ranks state-of-the-art methods for editing tasks. Trained on paired video data for global/local style transfer and object removal, RFDM surpasses I2I-based methods and competes with fully spatiotemporal (3D) V2V models, while matching the compute of image models and scaling independently of input video length. More content can be found in: https://smsd75.github.io/RFDM_page/
EDiT: Efficient Diffusion Transformers with Linear Compressed Attention
Mar 20, 2025



Diffusion Transformers (DiTs) have emerged as a leading architecture for text-to-image synthesis, producing high-quality and photorealistic images. However, the quadratic scaling properties of the attention in DiTs hinder image generation with higher resolution or on devices with limited resources. This work introduces an efficient diffusion transformer (EDiT) to alleviate these efficiency bottlenecks in conventional DiTs and Multimodal DiTs (MM-DiTs). First, we present a novel linear compressed attention method that uses a multi-layer convolutional network to modulate queries with local information while keys and values are spatially aggregated. Second, we formulate a hybrid attention scheme for multi-modal inputs that combines linear attention for image-to-image interactions and standard scaled dot-product attention for interactions involving prompts. Merging these two approaches leads to an expressive, linear-time Multimodal Efficient Diffusion Transformer (MM-EDiT). We demonstrate the effectiveness of the EDiT and MM-EDiT architectures by integrating them into PixArt-Sigma(conventional DiT) and Stable Diffusion 3.5-Medium (MM-DiT), achieving up to 2.2x speedup with comparable image quality after distillation.
Upcycling Text-to-Image Diffusion Models for Multi-Task Capabilities
Mar 14, 2025



Text-to-image synthesis has witnessed remarkable advancements in recent years. Many attempts have been made to adopt text-to-image models to support multiple tasks. However, existing approaches typically require resource-intensive re-training or additional parameters to accommodate for the new tasks, which makes the model inefficient for on-device deployment. We propose Multi-Task Upcycling (MTU), a simple yet effective recipe that extends the capabilities of a pre-trained text-to-image diffusion model to support a variety of image-to-image generation tasks. MTU replaces Feed-Forward Network (FFN) layers in the diffusion model with smaller FFNs, referred to as experts, and combines them with a dynamic routing mechanism. To the best of our knowledge, MTU is the first multi-task diffusion modeling approach that seamlessly blends multi-tasking with on-device compatibility, by mitigating the issue of parameter inflation. We show that the performance of MTU is on par with the single-task fine-tuned diffusion models across several tasks including image editing, super-resolution, and inpainting, while maintaining similar latency and computational load (GFLOPs) as the single-task fine-tuned models.
Fast Inference Through The Reuse Of Attention Maps In Diffusion Models
Dec 13, 2023



Text-to-image diffusion models have demonstrated unprecedented abilities at flexible and realistic image synthesis. However, the iterative process required to produce a single image is costly and incurs a high latency, prompting researchers to further investigate its efficiency. Typically, improvements in latency have been achieved in two ways: (1) training smaller models through knowledge distillation (KD); and (2) adopting techniques from ODE-theory to facilitate larger step sizes. In contrast, we propose a training-free approach that does not alter the step-size of the sampler. Specifically, we find the repeated calculation of attention maps to be both costly and redundant; therefore, we propose a structured reuse of attention maps during sampling. Our initial reuse policy is motivated by rudimentary ODE-theory, which suggests that reuse is most suitable late in the sampling procedure. After noting a number of limitations in this theoretical approach, we empirically search for a better policy. Unlike methods that rely on KD, our reuse policies can easily be adapted to a variety of setups in a plug-and-play manner. Furthermore, when applied to Stable Diffusion-1.5, our reuse policies reduce latency with minimal repercussions on sample quality.
How Much Is Hidden in the NAS Benchmarks? Few-Shot Adaptation of a NAS Predictor
Nov 30, 2023



Neural architecture search has proven to be a powerful approach to designing and refining neural networks, often boosting their performance and efficiency over manually-designed variations, but comes with computational overhead. While there has been a considerable amount of research focused on lowering the cost of NAS for mainstream tasks, such as image classification, a lot of those improvements stem from the fact that those tasks are well-studied in the broader context. Consequently, applicability of NAS to emerging and under-represented domains is still associated with a relatively high cost and/or uncertainty about the achievable gains. To address this issue, we turn our focus towards the recent growth of publicly available NAS benchmarks in an attempt to extract general NAS knowledge, transferable across different tasks and search spaces. We borrow from the rich field of meta-learning for few-shot adaptation and carefully study applicability of those methods to NAS, with a special focus on the relationship between task-level correlation (domain shift) and predictor transferability; which we deem critical for improving NAS on diverse tasks. In our experiments, we use 6 NAS benchmarks in conjunction, spanning in total 16 NAS settings -- our meta-learning approach not only shows superior (or matching) performance in the cross-validation experiments but also successful extrapolation to a new search space and tasks.
Federated Self-supervised Speech Representations: Are We There Yet?
Apr 06, 2022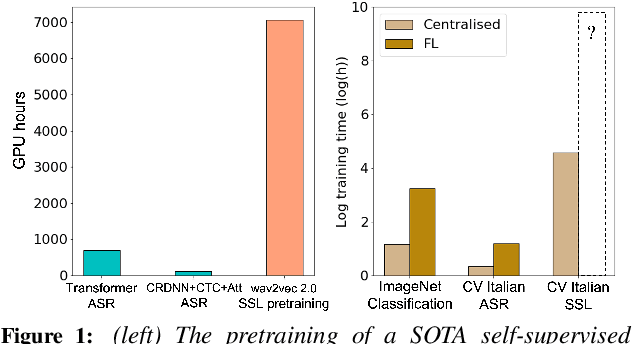
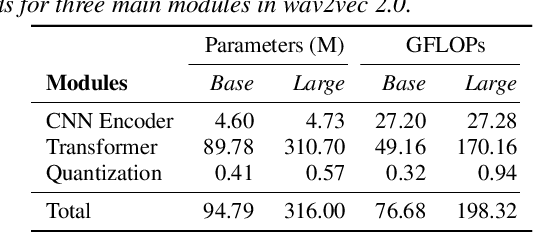
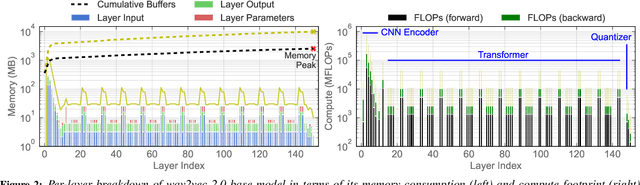
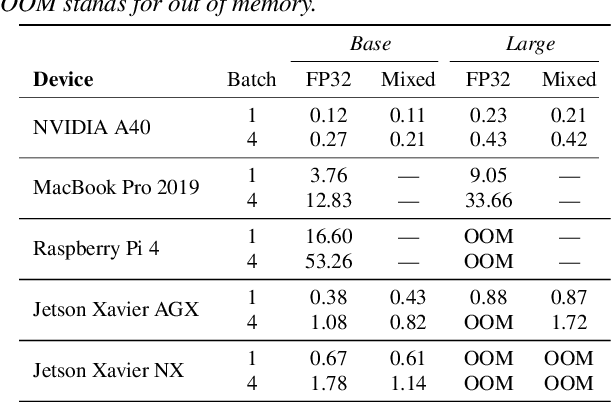
The ubiquity of microphone-enabled devices has lead to large amounts of unlabelled audio data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of speech representations. In this paper, we provide a first-of-its-kind systematic study of the feasibility and complexities for training speech SSL models under FL scenarios from the perspective of algorithms, hardware, and systems limits. Despite the high potential of their combination, we find existing system constraints and algorithmic behaviour make SSL and FL systems nearly impossible to build today. Yet critically, our results indicate specific performance bottlenecks and research opportunities that would allow this situation to be reversed. While our analysis suggests that, given existing trends in hardware, hybrid SSL and FL speech systems will not be viable until 2027. We believe this study can act as a roadmap to accelerate work towards reaching this milestone much earlier.
Inferring Facing Direction from Voice Signals
Sep 29, 2021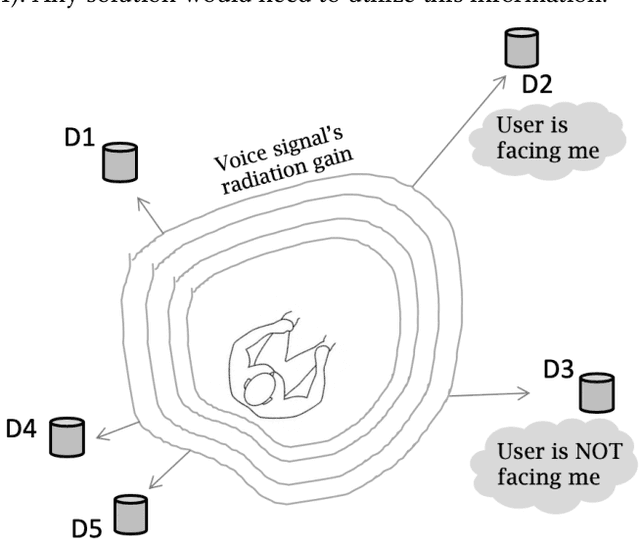
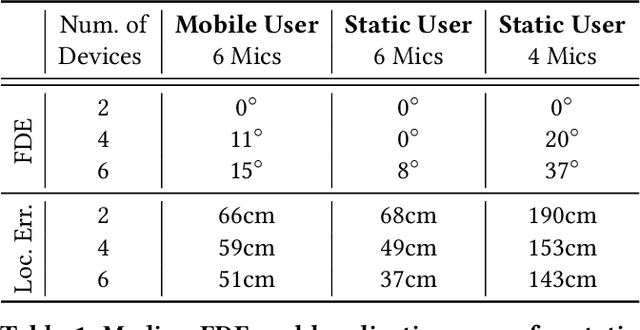
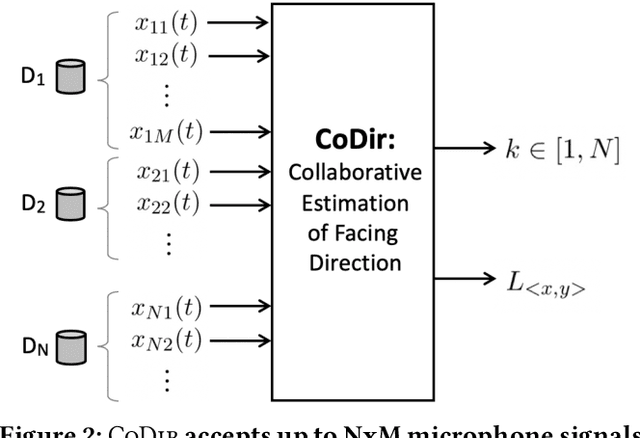
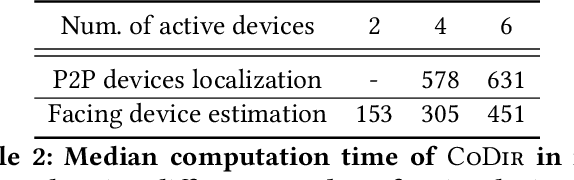
Consider a home or office where multiple devices are running voice assistants (e.g., TVs, lights, ovens, refrigerators, etc.). A human user turns to a particular device and gives a voice command, such as ``Alexa, can you ...''. This paper focuses on the problem of detecting which device the user was facing, and therefore, enabling only that device to respond to the command. Our core intuition emerges from the fact that human voice exhibits a directional radiation pattern, and the orientation of this pattern should influence the signal received at each device. Unfortunately, indoor multipath, unknown user location, and unknown voice signals pose as critical hurdles. Through a new algorithm that estimates the line-of-sight (LoS) power from a given signal, and combined with beamforming and triangulation, we design a functional solution called CoDIR. Results from $500+$ configurations, across $5$ rooms and $9$ different users, are encouraging. While improvements are necessary, we believe this is an important step forward in a challenging but urgent problem space.
Smart at what cost? Characterising Mobile Deep Neural Networks in the wild
Sep 28, 2021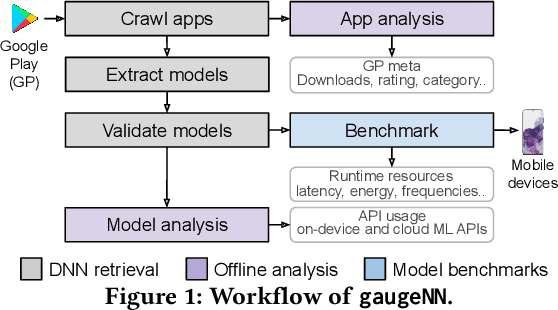
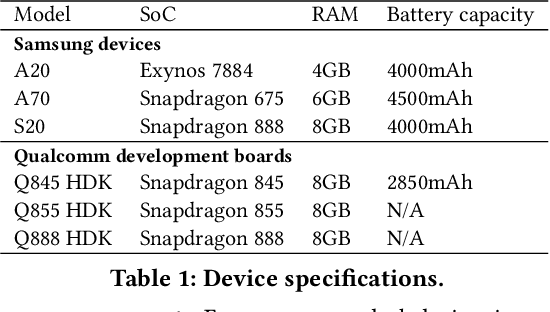
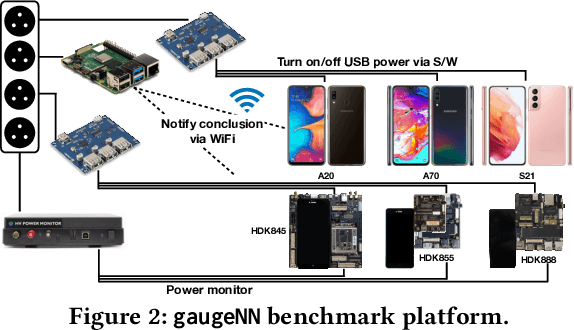
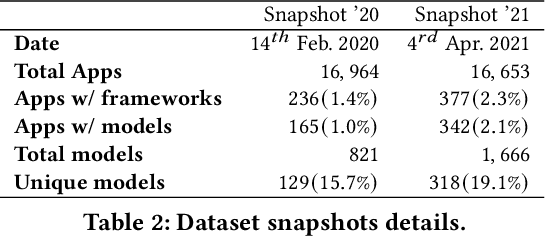
With smartphones' omnipresence in people's pockets, Machine Learning (ML) on mobile is gaining traction as devices become more powerful. With applications ranging from visual filters to voice assistants, intelligence on mobile comes in many forms and facets. However, Deep Neural Network (DNN) inference remains a compute intensive workload, with devices struggling to support intelligence at the cost of responsiveness.On the one hand, there is significant research on reducing model runtime requirements and supporting deployment on embedded devices. On the other hand, the strive to maximise the accuracy of a task is supported by deeper and wider neural networks, making mobile deployment of state-of-the-art DNNs a moving target. In this paper, we perform the first holistic study of DNN usage in the wild in an attempt to track deployed models and match how these run on widely deployed devices. To this end, we analyse over 16k of the most popular apps in the Google Play Store to characterise their DNN usage and performance across devices of different capabilities, both across tiers and generations. Simultaneously, we measure the models' energy footprint, as a core cost dimension of any mobile deployment. To streamline the process, we have developed gaugeNN, a tool that automates the deployment, measurement and analysis of DNNs on devices, with support for different frameworks and platforms. Results from our experience study paint the landscape of deep learning deployments on smartphones and indicate their popularity across app developers. Furthermore, our study shows the gap between bespoke techniques and real-world deployments and the need for optimised deployment of deep learning models in a highly dynamic and heterogeneous ecosystem.
Zero-Cost Proxies for Lightweight NAS
Jan 20, 2021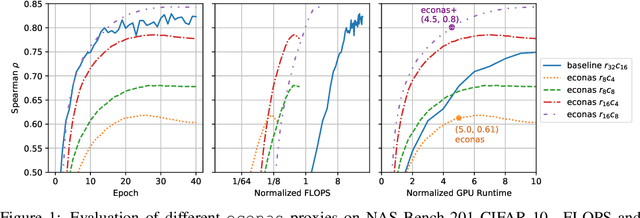

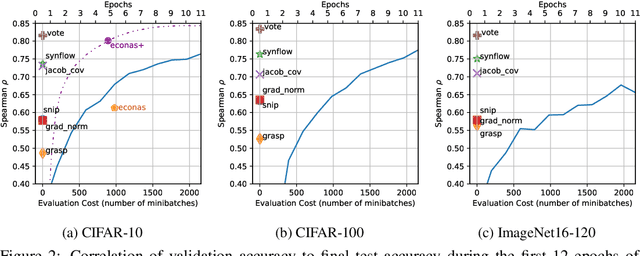

Neural Architecture Search (NAS) is quickly becoming the standard methodology to design neural network models. However, NAS is typically compute-intensive because multiple models need to be evaluated before choosing the best one. To reduce the computational power and time needed, a proxy task is often used for evaluating each model instead of full training. In this paper, we evaluate conventional reduced-training proxies and quantify how well they preserve ranking between multiple models during search when compared with the rankings produced by final trained accuracy. We propose a series of zero-cost proxies, based on recent pruning literature, that use just a single minibatch of training data to compute a model's score. Our zero-cost proxies use 3 orders of magnitude less computation but can match and even outperform conventional proxies. For example, Spearman's rank correlation coefficient between final validation accuracy and our best zero-cost proxy on NAS-Bench-201 is 0.82, compared to 0.61 for EcoNAS (a recently proposed reduced-training proxy). Finally, we use these zero-cost proxies to enhance existing NAS search algorithms such as random search, reinforcement learning, evolutionary search and predictor-based search. For all search methodologies and across three different NAS datasets, we are able to significantly improve sample efficiency, and thereby decrease computation, by using our zero-cost proxies. For example on NAS-Bench-101, we achieved the same accuracy 4$\times$ quicker than the best previous result.