 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern Sampling for Shapelet-based Time Series Classification
Feb 16, 2021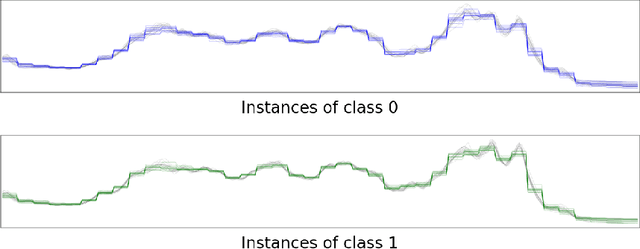
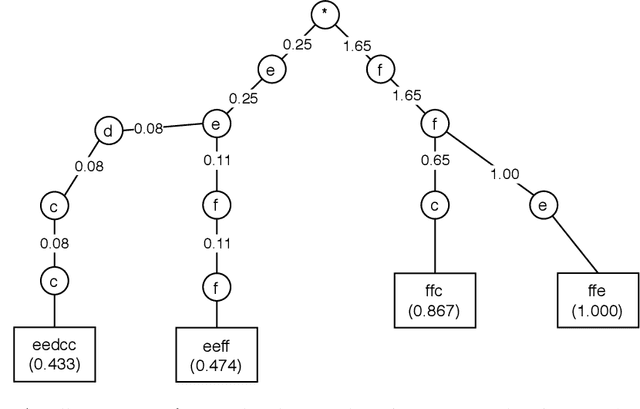
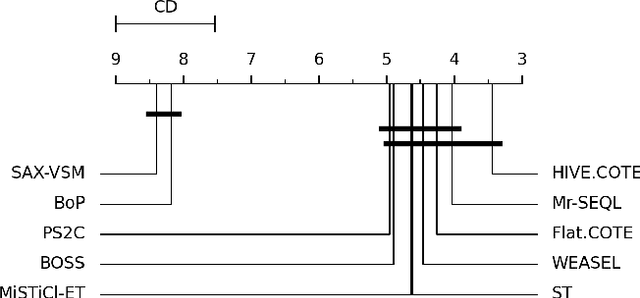
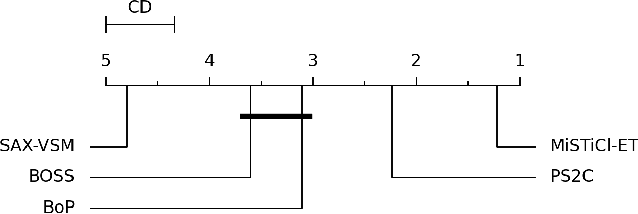
Subsequence-based time series classification algorithms provide accurate and interpretable models, but training these models is extremely computation intensive. The asymptotic time complexity of subsequence-based algorithms remains a higher-order polynomial, because these algorithms are based on exhaustive search for highly discriminative subsequences. Pattern sampling has been proposed as an effective alternative to mitigate the pattern explosion phenomenon. Therefore, we employ pattern sampling to extract discriminative features from discretized time series data. A weighted trie is created based on the discretized time series data to sample highly discriminative patterns. These sampled patterns are used to identify the shapelets which are used to transform the time series classification problem into a feature-based classification problem. Finally, a classification model can be trained using any off-the-shelf algorithm. Creating a pattern sampler requires a small number of patterns to be evaluated compared to an exhaustive search as employed by previous approaches. Compared to previously proposed algorithms, our approach requires considerably less computational and memory resources. Experiments demonstrate how the proposed approach fares in terms of classification accuracy and runtime performance.
Ensembles of Randomized Time Series Shapelets Provide Improved Accuracy while Reducing Computational Costs
Feb 22, 2017
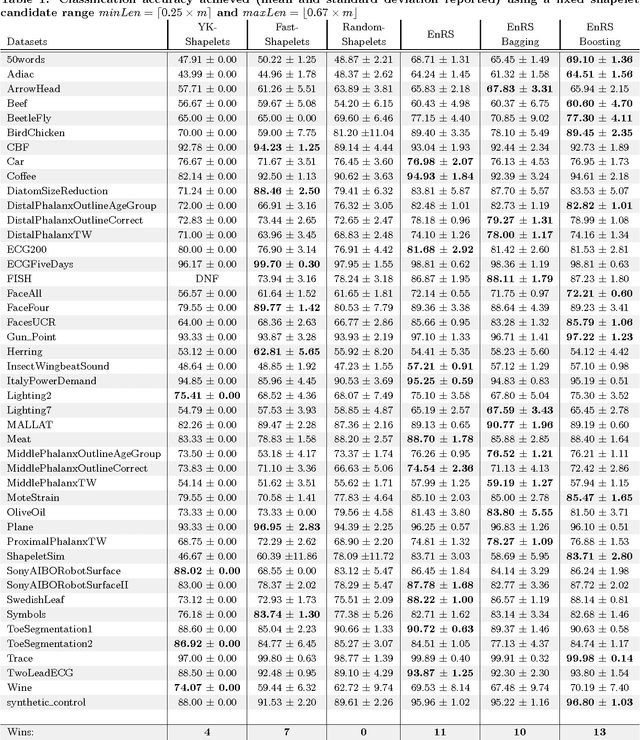
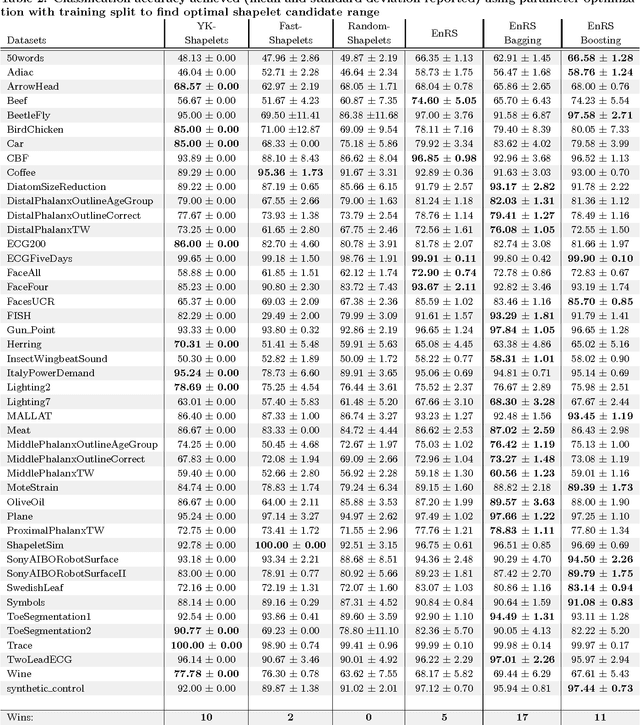
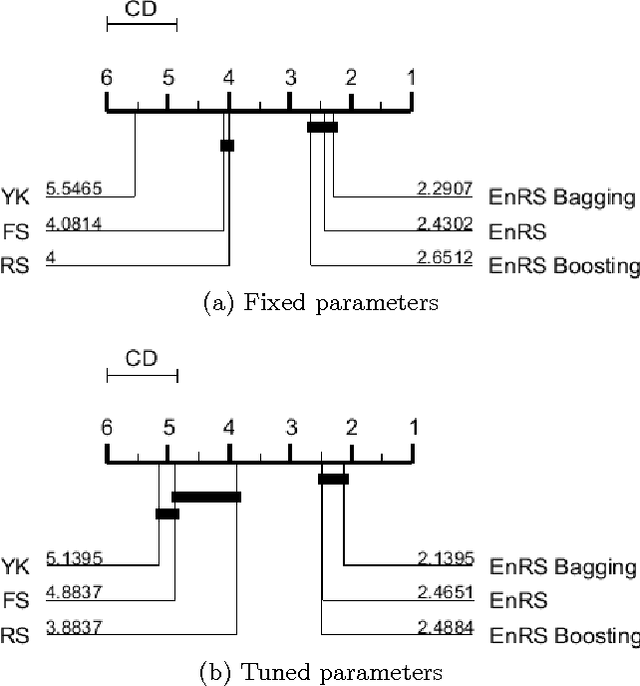
Shapelets are discriminative time series subsequences that allow generation of interpretable classification models, which provide faster and generally better classification than the nearest neighbor approach. However, the shapelet discovery process requires the evaluation of all possible subsequences of all time series in the training set, making it extremely computation intensive. Consequently, shapelet discovery for large time series datasets quickly becomes intractable. A number of improvements have been proposed to reduce the training time. These techniques use approximation or discretization and often lead to reduced classification accuracy compared to the exact method. We are proposing the use of ensembles of shapelet-based classifiers obtained using random sampling of the shapelet candidates. Using random sampling reduces the number of evaluated candidates and consequently the required computational cost, while the classification accuracy of the resulting models is also not significantly different than that of the exact algorithm. The combination of randomized classifiers rectifies the inaccuracies of individual models because of the diversity of the solutions. Based on the experiments performed, it is shown that the proposed approach of using an ensemble of inexpensive classifiers provides better classification accuracy compared to the exact method at a significantly lesser computational cost.