 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Ignore: Fair and Task Independent Representations
Jan 11, 2021
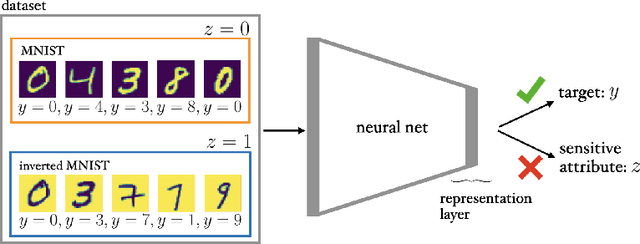

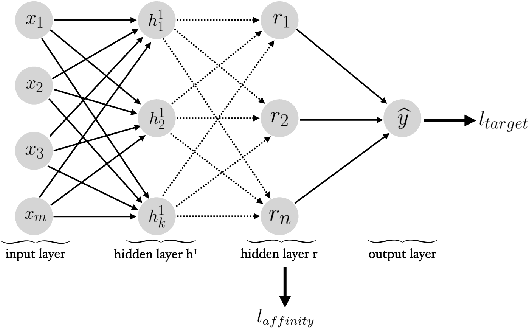

Training fair machine learning models, aiming for their interpretability and solving the problem of domain shift has gained a lot of interest in the last years. There is a vast amount of work addressing these topics, mostly in separation. In this work we show that they can be seen as a common framework of learning invariant representations. The representations should allow to predict the target while at the same time being invariant to sensitive attributes which split the dataset into subgroups. Our approach is based on the simple observation that it is impossible for any learning algorithm to differentiate samples if they have the same feature representation. This is formulated as an additional loss (regularizer) enforcing a common feature representation across subgroups. We apply it to learn fair models and interpret the influence of the sensitive attribute. Furthermore it can be used for domain adaptation, transferring knowledge and learning effectively from very few examples. In all applications it is essential not only to learn to predict the target, but also to learn what to ignore.
Self-Supervised Representation Learning for RGB-D Salient Object Detection
Jan 29, 2021
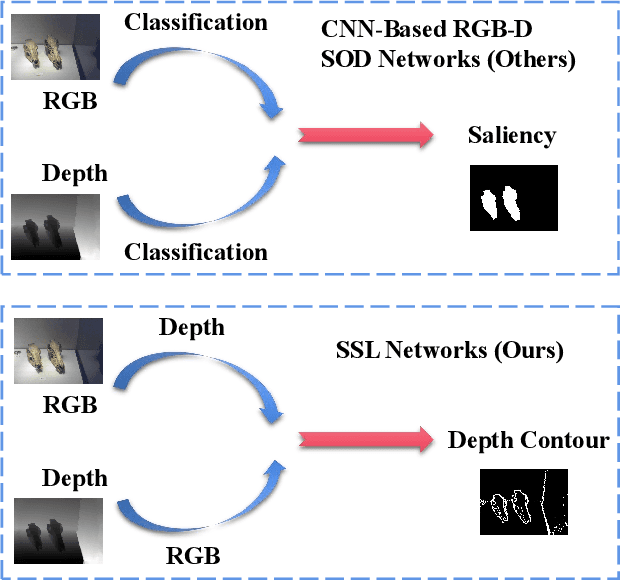
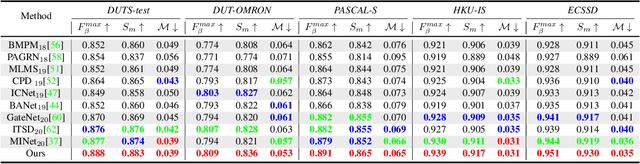
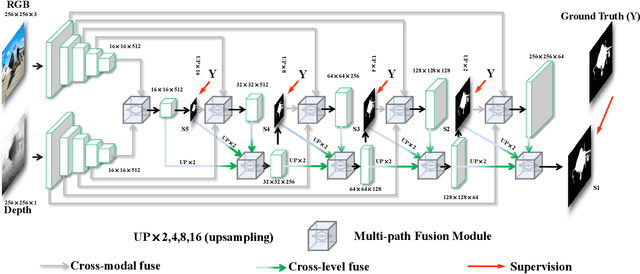
Existing CNNs-Based RGB-D Salient Object Detection (SOD) networks are all required to be pre-trained on the ImageNet to learn the hierarchy features which can help to provide a good initialization. However, the collection and annotation of large-scale datasets are time-consuming and expensive. In this paper, we utilize Self-Supervised Representation Learning (SSL) to design two pretext tasks: the cross-modal auto-encoder and the depth-contour estimation. Our pretext tasks require only a few and unlabeled RGB-D datasets to perform pre-training, which make the network capture rich semantic contexts as well as reduce the gap between two modalities, thereby providing an effective initialization for the downstream task. In addition, for the inherent problem of cross-modal fusion in RGB-D SOD, we propose a multi-path fusion (MPF) module that splits a single feature fusion into multi-path fusion to achieve an adequate perception of consistent and differential information. The MPF module is general and suitable for both cross-modal and cross-level feature fusion. Extensive experiments on six benchmark RGB-D SOD datasets, our model pre-trained on the RGB-D dataset ($6,335$ without any annotations) can perform favorably against most state-of-the-art RGB-D methods pre-trained on ImageNet ($1,280,000$ with image-level annotations).
Automatic Polyp Segmentation using Fully Convolutional Neural Network
Jan 11, 2021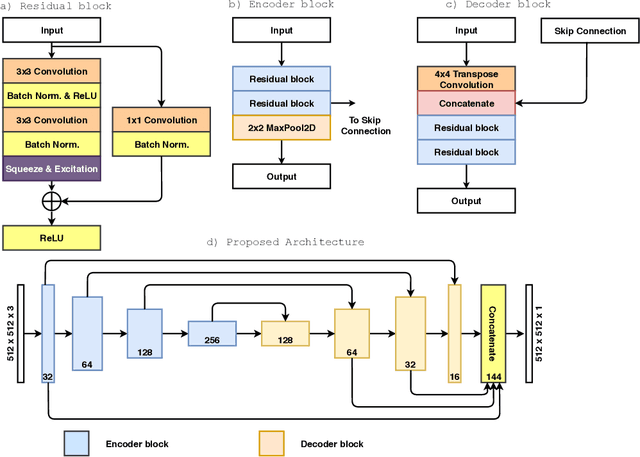
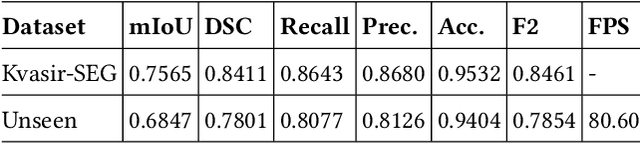
Colorectal cancer is one of fatal cancer worldwide. Colonoscopy is the standard treatment for examination, localization, and removal of colorectal polyps. However, it has been shown that the miss-rate of colorectal polyps during colonoscopy is between 6 to 27%. The use of an automated, accurate, and real-time polyp segmentation during colonoscopy examinations can help the clinicians to eliminate missing lesions and prevent further progression of colorectal cancer. The ``Medico automatic polyp segmentation challenge'' provides an opportunity to study polyp segmentation and build a fast segmentation model. The challenge organizers provide a Kvasir-SEG dataset to train the model. Then it is tested on a separate unseen dataset to validate the efficiency and speed of the segmentation model. The experiments demonstrate that the model trained on the Kvasir-SEG dataset and tested on an unseen dataset achieves a dice coefficient of 0.7801, mIoU of 0.6847, recall of 0.8077, and precision of 0.8126, demonstrating the generalization ability of our model. The model has achieved 80.60 FPS on the unseen dataset with an image resolution of $512 \times 512$.
Cross-domain Activity Recognition via Substructural Optimal Transport
Jan 29, 2021

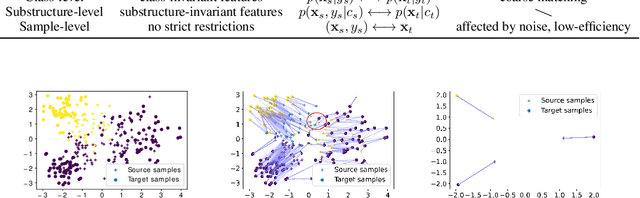

It is expensive and time-consuming to collect sufficient labeled data for human activity recognition (HAR). Recently, lots of work solves the problem via domain adaptation which leverages the labeled samples from the source domain to annotate the target domain. Existing domain adaptation methods mainly focus on adapting cross-domain representations via domain-level, class-level, or sample-level distribution matching. However, the domain- and class-level matching are too coarse that may result in under-adaptation, while sample-level matching may be affected by the noise seriously and eventually cause over-adaptation. In this paper, we propose substructure-level matching for domain adaptation (SSDA) to utilize the internal substructures of the domain to perform accurate and efficient knowledge transfer. Based on SSDA, we propose an optimal transport-based implementation, Substructural Optimal Transport (SOT), for cross-domain HAR. We obtain the substructures of activities via clustering methods and seeks the coupling of the weighted substructures between different domains. We conduct comprehensive experiments on four large public activity recognition datasets (i.e. UCI-DSADS, UCI-HAR, USC-HAD, PAMAP2), which demonstrates that SOT significantly outperforms other state-of-the-art methods w.r.t classification accuracy (10%+ improvement). In addition, SOT is much faster than comparison methods.
Sparsity Based Autoencoders for Denoising Cluttered Radar Signatures
Jan 29, 2021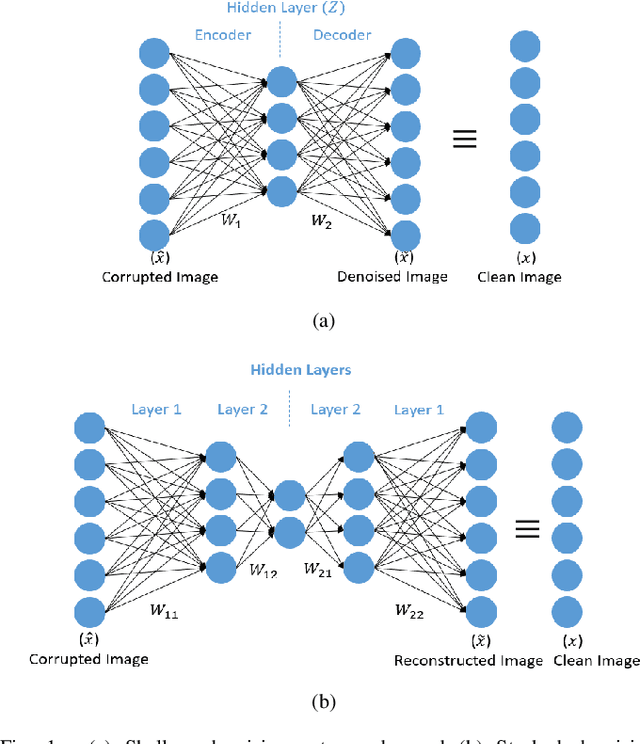
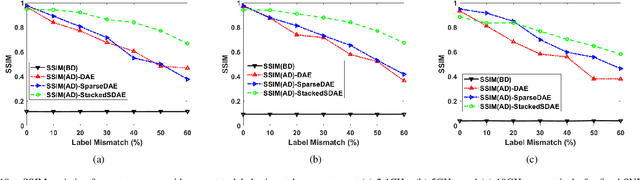
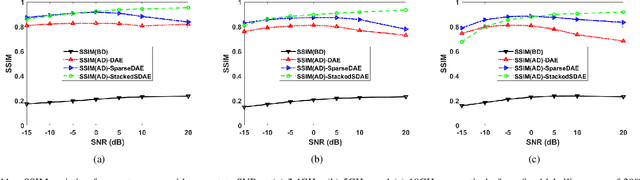
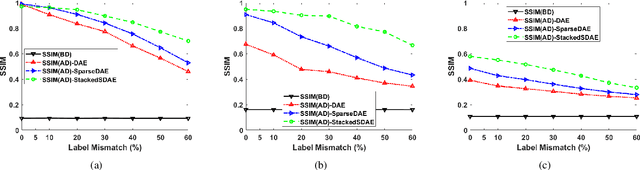
Narrowband and broadband indoor radar images significantly deteriorate in the presence of target dependent and independent static and dynamic clutter arising from walls. A stacked and sparse denoising autoencoder (StackedSDAE) is proposed for mitigating wall clutter in indoor radar images. The algorithm relies on the availability of clean images and corresponding noisy images during training and requires no additional information regarding the wall characteristics. The algorithm is evaluated on simulated Doppler-time spectrograms and high range resolution profiles generated for diverse radar frequencies and wall characteristics in around-the-corner radar (ACR) scenarios. Additional experiments are performed on range-enhanced frontal images generated from measurements gathered from a wideband RF imaging sensor. The results from the experiments show that the StackedSDAE successfully reconstructs images that closely resemble those that would be obtained in free space conditions. Further, the incorporation of sparsity and depth in the hidden layer representations within the autoencoder makes the algorithm more robust to low signal to noise ratio (SNR) and label mismatch between clean and corrupt data during training than the conventional single layer DAE. For example, the denoised ACR signatures show a structural similarity above 0.75 to clean free space images at SNR of -10dB and label mismatch error of 50%.
Machine Learning for Cataract Classification and Grading on Ophthalmic Imaging Modalities: A Survey
Dec 09, 2020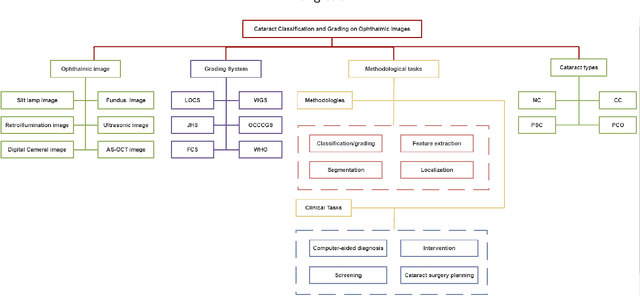


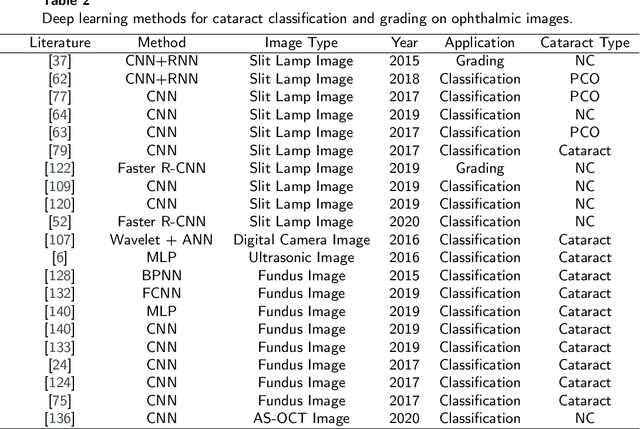
Cataract is one of the leading causes of reversible visual impairment and blindness globally. Over the years, researchers have achieved significant progress in developing state-of-the-art artificial intelligence techniques for automatic cataract classification and grading, helping clinicians prevent and treat cataract in time. This paper provides a comprehensive survey of recent advances in machine learning for cataract classification and grading based on ophthalmic images. We summarize existing literature from two research directions: conventional machine learning techniques and deep learning techniques. This paper also provides insights into existing works of both merits and limitations. In addition, we discuss several challenges of automatic cataract classification and grading based on machine learning techniques and present possible solutions to these challenges for future research.
The Unreasonable Effectiveness of Encoder-Decoder Networks for Retinal Vessel Segmentation
Nov 25, 2020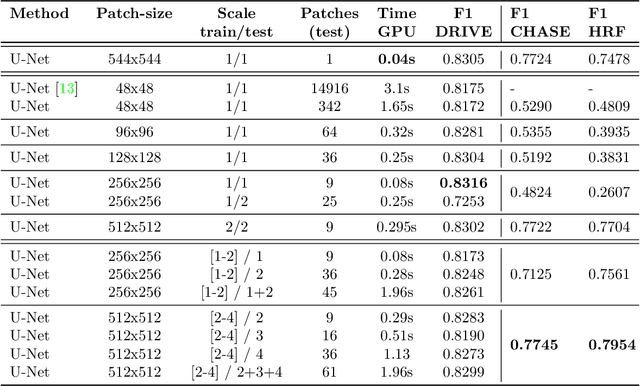
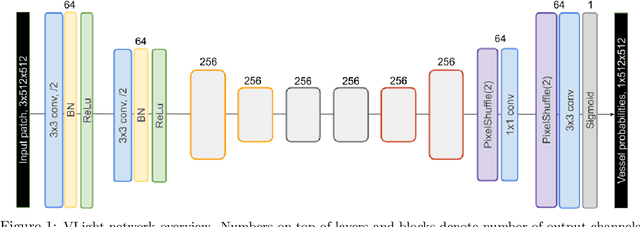
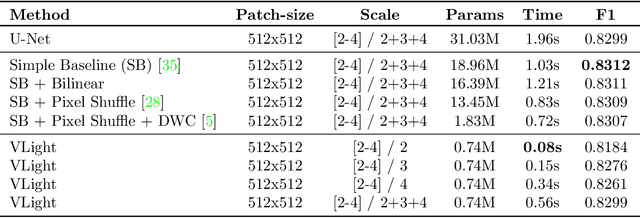
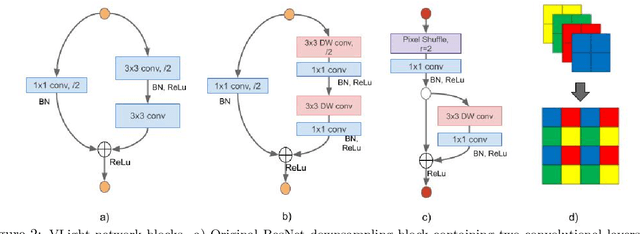
We propose an encoder-decoder framework for the segmentation of blood vessels in retinal images that relies on the extraction of large-scale patches at multiple image-scales during training. Experiments on three fundus image datasets demonstrate that this approach achieves state-of-the-art results and can be implemented using a simple and efficient fully-convolutional network with a parameter count of less than 0.8M. Furthermore, we show that this framework - called VLight - avoids overfitting to specific training images and generalizes well across different datasets, which makes it highly suitable for real-world applications where robustness, accuracy as well as low inference time on high-resolution fundus images is required.
VolumeDeform: Real-time Volumetric Non-rigid Reconstruction
Jul 30, 2016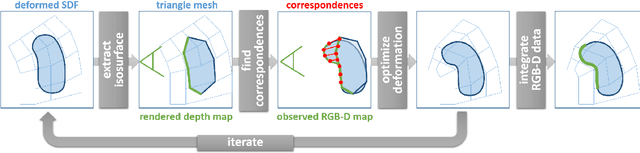



We present a novel approach for the reconstruction of dynamic geometric shapes using a single hand-held consumer-grade RGB-D sensor at real-time rates. Our method does not require a pre-defined shape template to start with and builds up the scene model from scratch during the scanning process. Geometry and motion are parameterized in a unified manner by a volumetric representation that encodes a distance field of the surface geometry as well as the non-rigid space deformation. Motion tracking is based on a set of extracted sparse color features in combination with a dense depth-based constraint formulation. This enables accurate tracking and drastically reduces drift inherent to standard model-to-depth alignment. We cast finding the optimal deformation of space as a non-linear regularized variational optimization problem by enforcing local smoothness and proximity to the input constraints. The problem is tackled in real-time at the camera's capture rate using a data-parallel flip-flop optimization strategy. Our results demonstrate robust tracking even for fast motion and scenes that lack geometric features.
MTCRNN: A multi-scale RNN for directed audio texture synthesis
Nov 25, 2020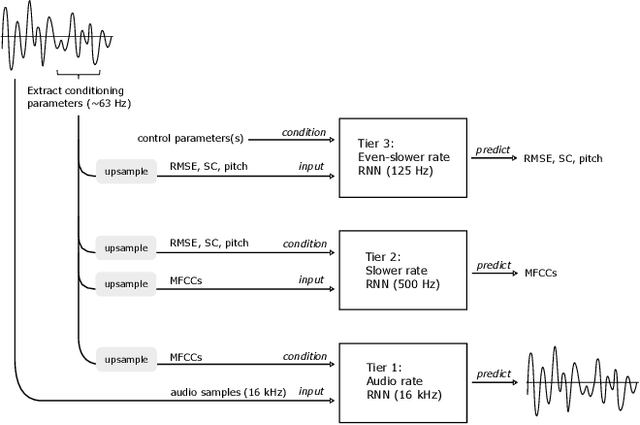
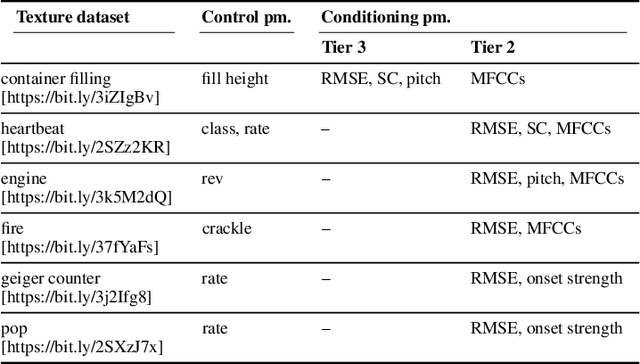
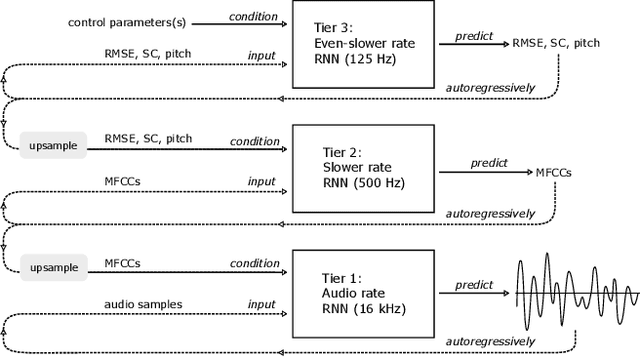

Audio textures are a subset of environmental sounds, often defined as having stable statistical characteristics within an adequately large window of time but may be unstructured locally. They include common everyday sounds such as from rain, wind, and engines. Given that these complex sounds contain patterns on multiple timescales, they are a challenge to model with traditional methods. We introduce a novel modelling approach for textures, combining recurrent neural networks trained at different levels of abstraction with a conditioning strategy that allows for user-directed synthesis. We demonstrate the model's performance on a variety of datasets, examine its performance on various metrics, and discuss some potential applications.
Robust Real-Time Multi-View Eye Tracking
Jan 03, 2018

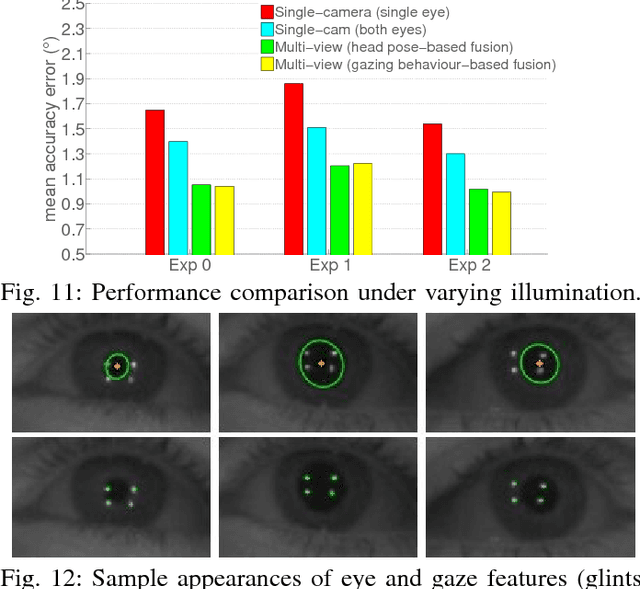
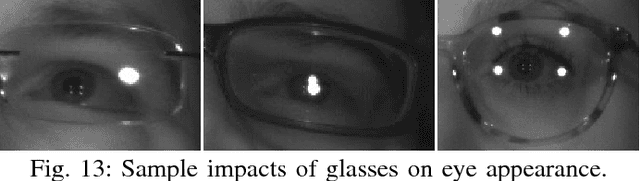
Despite significant advances in improving the gaze tracking accuracy under controlled conditions, the tracking robustness under real-world conditions, such as large head pose and movements, use of eyeglasses, illumination and eye type variations, remains a major challenge in eye tracking. In this paper, we revisit this challenge and introduce a real-time multi-camera eye tracking framework to improve the tracking robustness. First, differently from previous work, we design a multi-view tracking setup that allows for acquiring multiple eye appearances simultaneously. Leveraging multi-view appearances enables to more reliably detect gaze features under challenging conditions, particularly when they are obstructed in conventional single-view appearance due to large head movements or eyewear effects. The features extracted on various appearances are then used for estimating multiple gaze outputs. Second, we propose to combine estimated gaze outputs through an adaptive fusion mechanism to compute user's overall point of regard. The proposed mechanism firstly determines the estimation reliability of each gaze output according to user's momentary head pose and predicted gazing behavior, and then performs a reliability-based weighted fusion. We demonstrate the efficacy of our framework with extensive simulations and user experiments on a collected dataset featuring 20 subjects. Our results show that in comparison with state-of-the-art eye trackers, the proposed framework provides not only a significant enhancement in accuracy but also a notable robustness. Our prototype system runs at 30 frames-per-second (fps) and achieves 1 degree accuracy under challenging experimental scenarios, which makes it suitable for applications demanding high accuracy and robustness.