 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMTCRNN: A multi-scale RNN for directed audio texture synthesis
Nov 25, 2020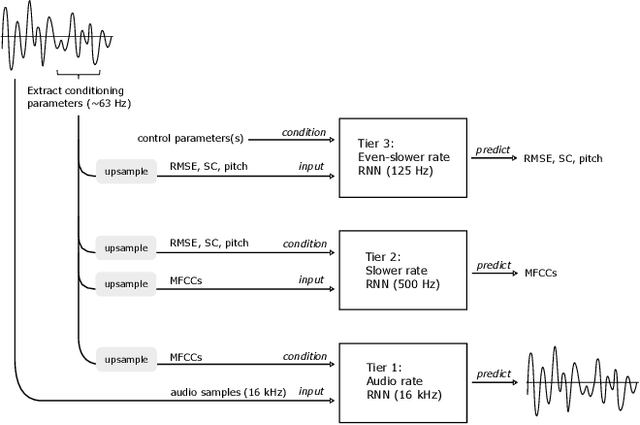
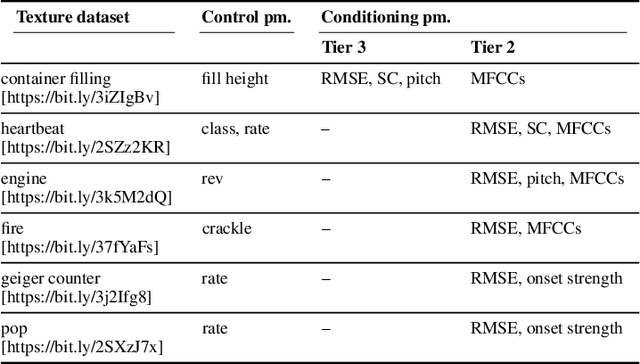
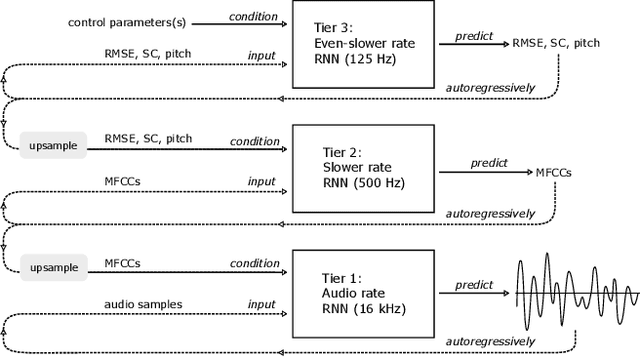

Audio textures are a subset of environmental sounds, often defined as having stable statistical characteristics within an adequately large window of time but may be unstructured locally. They include common everyday sounds such as from rain, wind, and engines. Given that these complex sounds contain patterns on multiple timescales, they are a challenge to model with traditional methods. We introduce a novel modelling approach for textures, combining recurrent neural networks trained at different levels of abstraction with a conditioning strategy that allows for user-directed synthesis. We demonstrate the model's performance on a variety of datasets, examine its performance on various metrics, and discuss some potential applications.
Deep generative models for musical audio synthesis
Jun 10, 2020
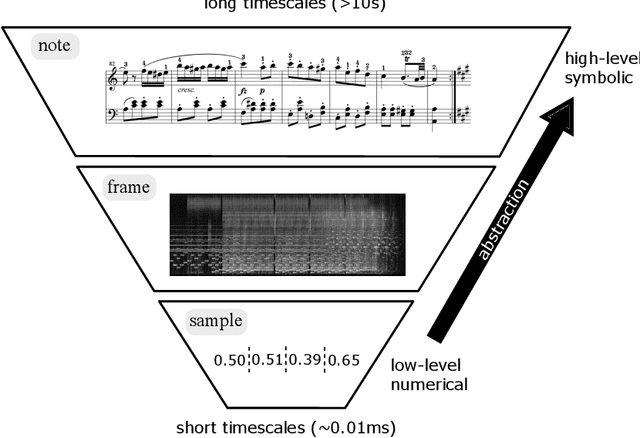
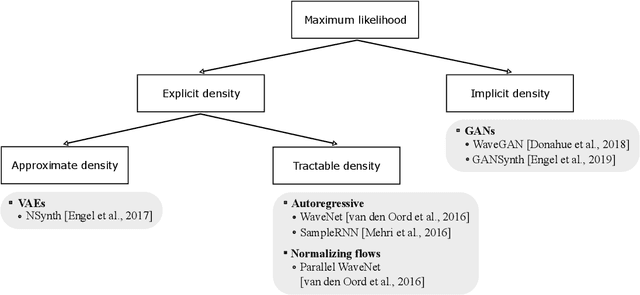
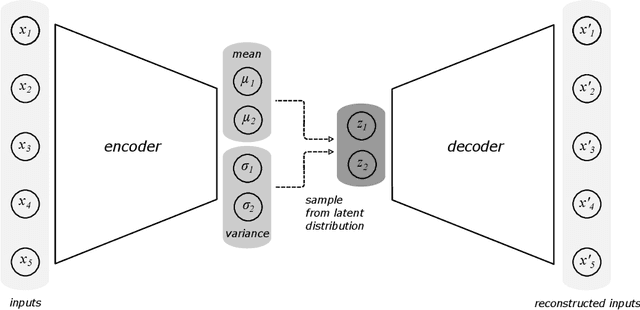
Sound modelling is the process of developing algorithms that generate sound under parametric control. There are a few distinct approaches that have been developed historically including modelling the physics of sound production and propagation, assembling signal generating and processing elements to capture acoustic features, and manipulating collections of recorded audio samples. While each of these approaches has been able to achieve high-quality synthesis and interaction for specific applications, they are all labour-intensive and each comes with its own challenges for designing arbitrary control strategies. Recent generative deep learning systems for audio synthesis are able to learn models that can traverse arbitrary spaces of sound defined by the data they train on. Furthermore, machine learning systems are providing new techniques for designing control and navigation strategies for these models. This paper is a review of developments in deep learning that are changing the practice of sound modelling.
Comparison of Time-Frequency Representations for Environmental Sound Classification using Convolutional Neural Networks
Jun 22, 2017
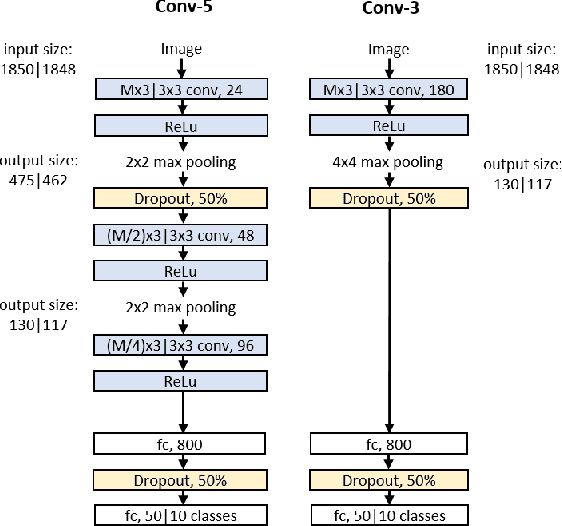

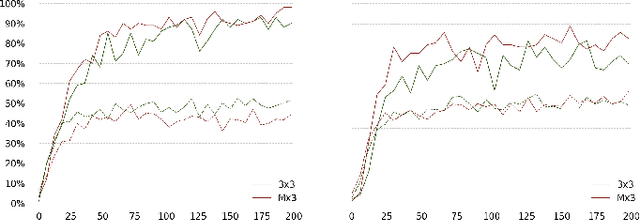
Recent successful applications of convolutional neural networks (CNNs) to audio classification and speech recognition have motivated the search for better input representations for more efficient training. Visual displays of an audio signal, through various time-frequency representations such as spectrograms offer a rich representation of the temporal and spectral structure of the original signal. In this letter, we compare various popular signal processing methods to obtain this representation, such as short-time Fourier transform (STFT) with linear and Mel scales, constant-Q transform (CQT) and continuous Wavelet transform (CWT), and assess their impact on the classification performance of two environmental sound datasets using CNNs. This study supports the hypothesis that time-frequency representations are valuable in learning useful features for sound classification. Moreover, the actual transformation used is shown to impact the classification accuracy, with Mel-scaled STFT outperforming the other discussed methods slightly and baseline MFCC features to a large degree. Additionally, we observe that the optimal window size during transformation is dependent on the characteristics of the audio signal and architecturally, 2D convolution yielded better results in most cases compared to 1D.