 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Dynamic Factor Models
Jul 23, 2020
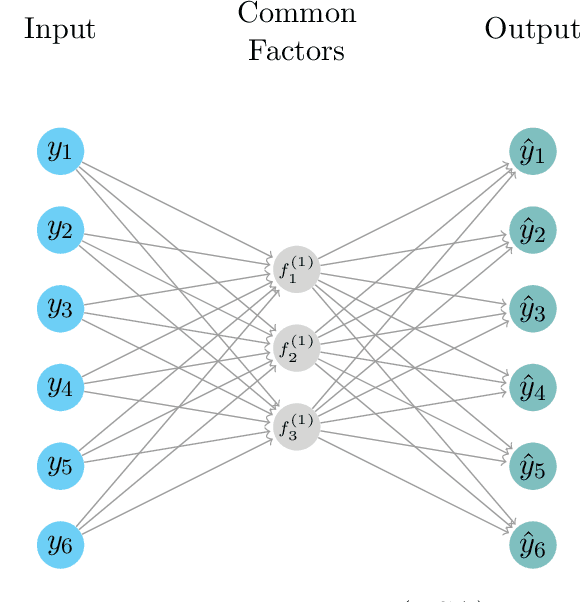

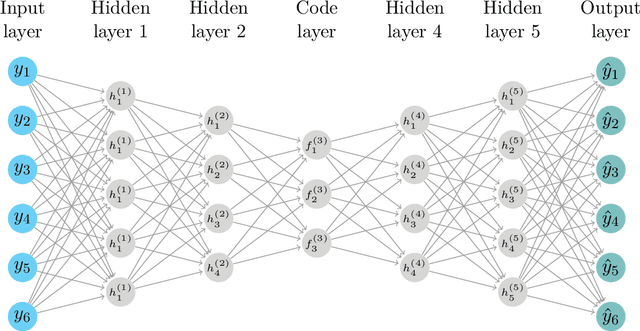
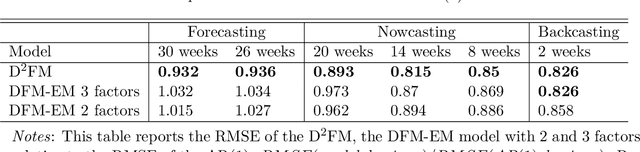
We propose a novel deep neural net framework - that we refer to as Deep Dynamic Factor Model (D2FM) -, to encode the information available, from hundreds of macroeconomic and financial time-series into a handful of unobserved latent states. While similar in spirit to traditional dynamic factor models (DFMs), differently from those, this new class of models allows for nonlinearities between factors and observables due to the deep neural net structure. However, by design, the latent states of the model can still be interpreted as in a standard factor model. In an empirical application to the forecast and nowcast of economic conditions in the US, we show the potential of this framework in dealing with high dimensional, mixed frequencies and asynchronously published time series data. In a fully real-time out-of-sample exercise with US data, the D2FM improves over the performances of a state-of-the-art DFM.
Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration
Feb 07, 2018
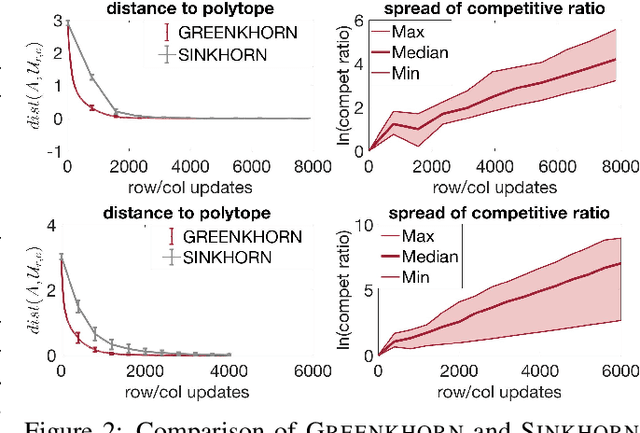
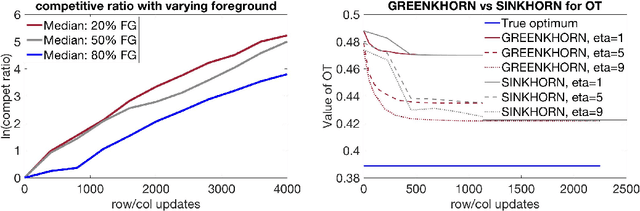
Computing optimal transport distances such as the earth mover's distance is a fundamental problem in machine learning, statistics, and computer vision. Despite the recent introduction of several algorithms with good empirical performance, it is unknown whether general optimal transport distances can be approximated in near-linear time. This paper demonstrates that this ambitious goal is in fact achieved by Cuturi's Sinkhorn Distances. This result relies on a new analysis of Sinkhorn iteration, which also directly suggests a new greedy coordinate descent algorithm, Greenkhorn, with the same theoretical guarantees. Numerical simulations illustrate that Greenkhorn significantly outperforms the classical Sinkhorn algorithm in practice.
Clustering Financial Time Series: How Long is Enough?
Apr 14, 2016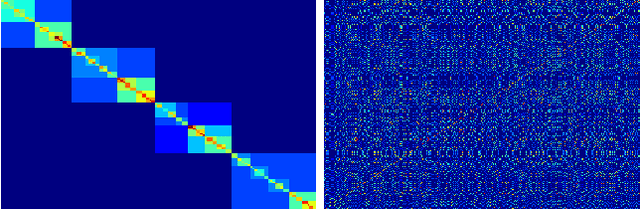
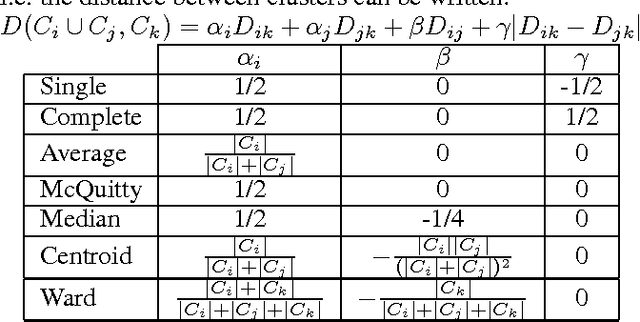
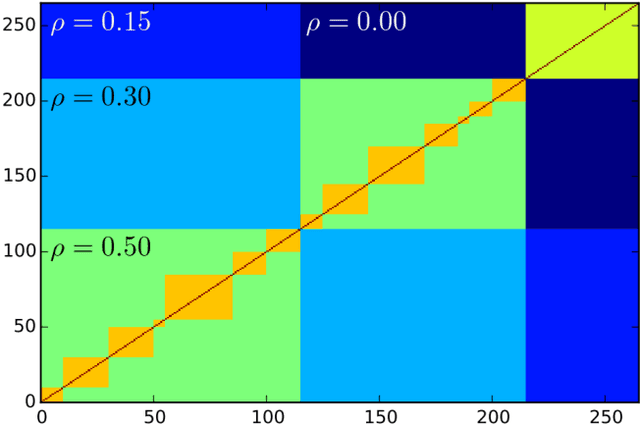
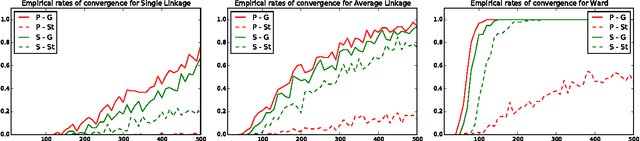
Researchers have used from 30 days to several years of daily returns as source data for clustering financial time series based on their correlations. This paper sets up a statistical framework to study the validity of such practices. We first show that clustering correlated random variables from their observed values is statistically consistent. Then, we also give a first empirical answer to the much debated question: How long should the time series be? If too short, the clusters found can be spurious; if too long, dynamics can be smoothed out.
Deep Learning for Moving Blockage Prediction using Real Millimeter Wave Measurements
Jan 21, 2021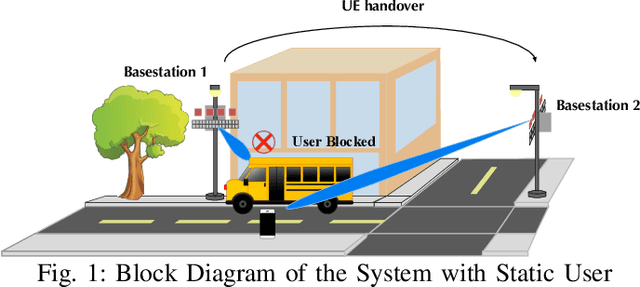
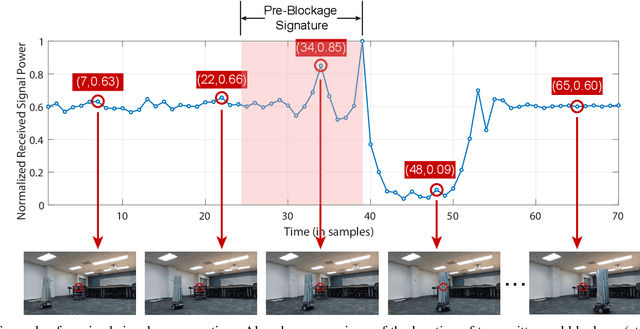
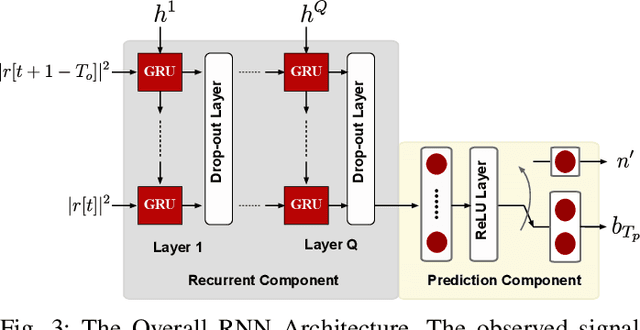

Millimeter wave (mmWave) communication is a key component of 5G and beyond. Harvesting the gains of the large bandwidth and low latency at mmWave systems, however, is challenged by the sensitivity of mmWave signals to blockages; a sudden blockage in the line of sight (LOS) link leads to abrupt disconnection, which affects the reliability of the network. In addition, searching for an alternative base station to re-establish the link could result in needless latency overhead. In this paper, we address these challenges collectively by utilizing machine learning to anticipate dynamic blockages proactively. The proposed approach sees a machine learning algorithm learning to predict future blockages by observing what we refer to as the \textit{pre-blockage signature}. To evaluate our proposed approach, we build a mmWave communication setup with a moving blockage and collect a dataset of received power sequences. Simulation results on a real dataset show that blockage occurrence could be predicted with more than 85\% accuracy and the exact time instance of blockage occurrence can be obtained with low error. This highlights the potential of the proposed solution for dynamic blockage prediction and proactive hand-off, which enhances the reliability and latency of future wireless networks.
MP Twitter Engagement and Abuse Post-first COVID-19 Lockdown in the UK: White Paper
Mar 04, 2021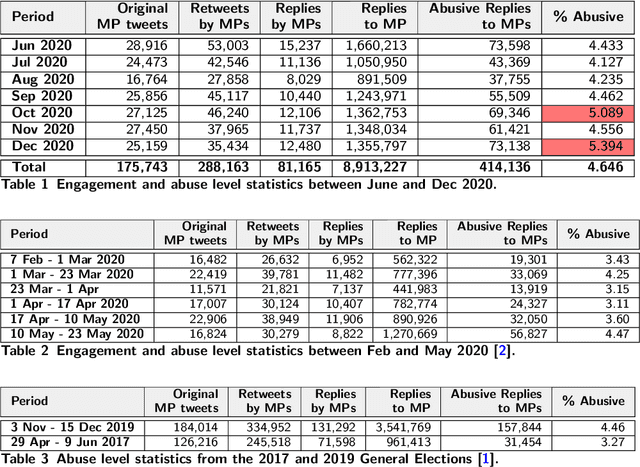
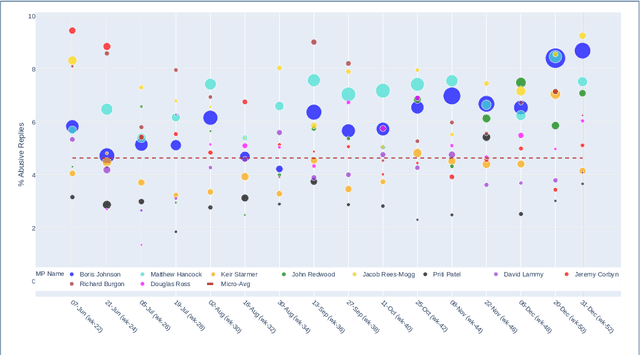
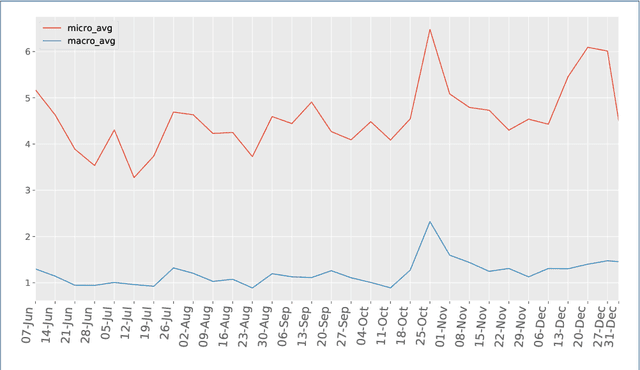
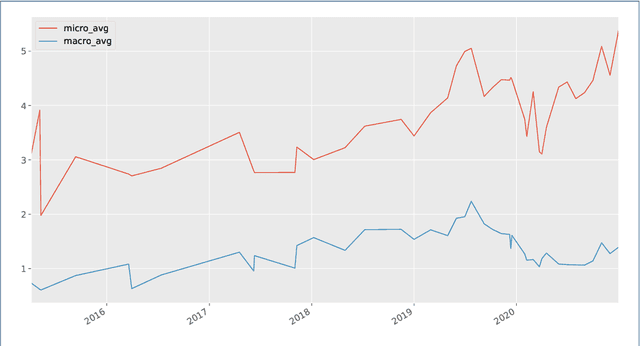
The UK has had a volatile political environment for some years now, with Brexit and leadership crises marking the past five years. With this work, we wanted to understand more about how the global health emergency, COVID-19, influences the amount, type or topics of abuse that UK politicians receive when engaging with the public. With this work, we wanted to understand more about how the global health emergency, COVID-19, influences the amount, type or topics of abuse that UK politicians receive when engaging with the public. This work covers the period of June to December 2020 and analyses Twitter abuse in replies to UK MPs. This work is a follow-up from our analysis of online abuse during the first four months of the COVID-19 pandemic in the UK. The paper examines overall abuse levels during this new seven month period, analyses reactions to members of different political parties and the UK government, and the relationship between online abuse and topics such as Brexit, government's COVID-19 response and policies, and social issues. In addition, we have also examined the presence of conspiracy theories posted in abusive replies to MPs during the period. We have found that abuse levels toward UK MPs were at an all-time high in December 2020 (5.4% of all reply tweets sent to MPs). This is almost 1% higher that the two months preceding the General Election. In a departure from the trend seen in the first four months of the pandemic, MPs from the Tory party received the highest percentage of abusive replies from July 2020 onward, which stays above 5% starting from September 2020 onward, as the COVID-19 crisis deepened and the Brexit negotiations with the EU started nearing completion.
Layer-Peeled Model: Toward Understanding Well-Trained Deep Neural Networks
Jan 29, 2021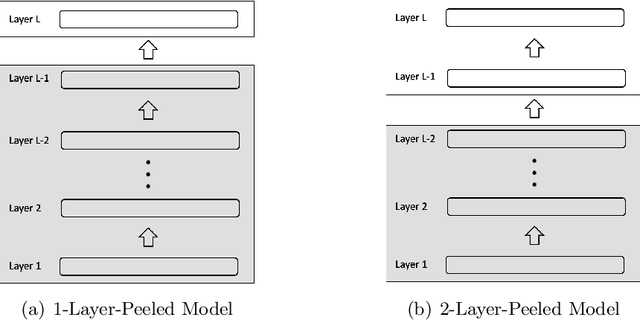

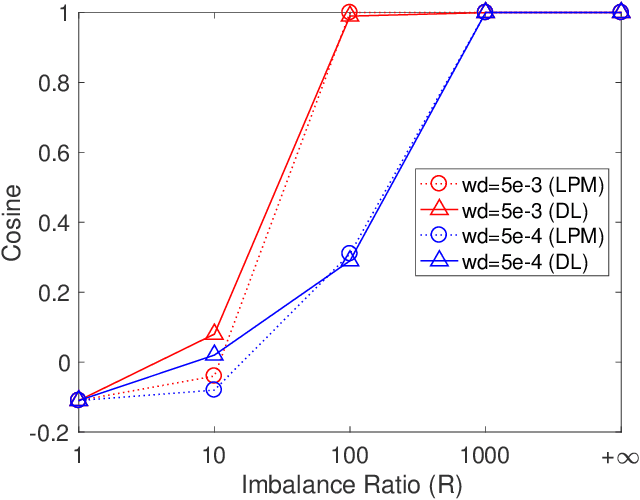

In this paper, we introduce the Layer-Peeled Model, a nonconvex yet analytically tractable optimization program, in a quest to better understand deep neural networks that are trained for a sufficiently long time. As the name suggests, this new model is derived by isolating the topmost layer from the remainder of the neural network, followed by imposing certain constraints separately on the two parts. We demonstrate that the Layer-Peeled Model, albeit simple, inherits many characteristics of well-trained neural networks, thereby offering an effective tool for explaining and predicting common empirical patterns of deep learning training. First, when working on class-balanced datasets, we prove that any solution to this model forms a simplex equiangular tight frame, which in part explains the recently discovered phenomenon of neural collapse in deep learning training [PHD20]. Moreover, when moving to the imbalanced case, our analysis of the Layer-Peeled Model reveals a hitherto unknown phenomenon that we term Minority Collapse, which fundamentally limits the performance of deep learning models on the minority classes. In addition, we use the Layer-Peeled Model to gain insights into how to mitigate Minority Collapse. Interestingly, this phenomenon is first predicted by the Layer-Peeled Model before its confirmation by our computational experiments.
Fast Adaptation of Manipulator Trajectories to Task Perturbation By Differentiating through the Optimal Solution
Nov 01, 2020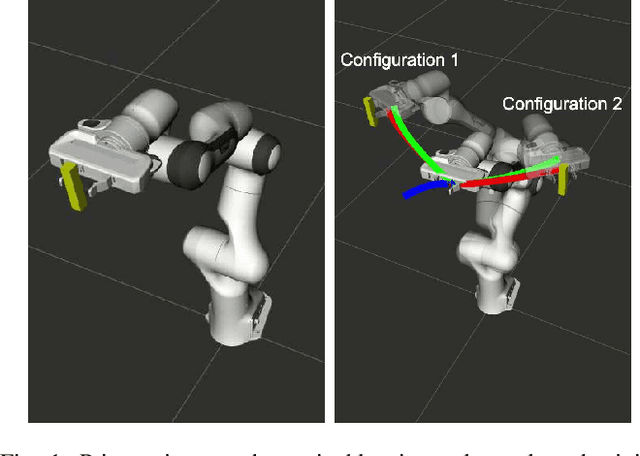
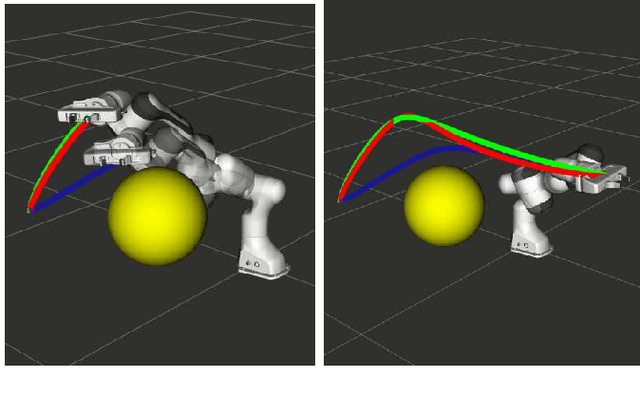
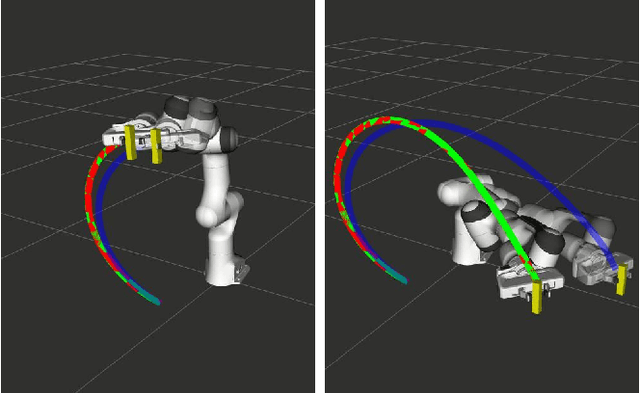
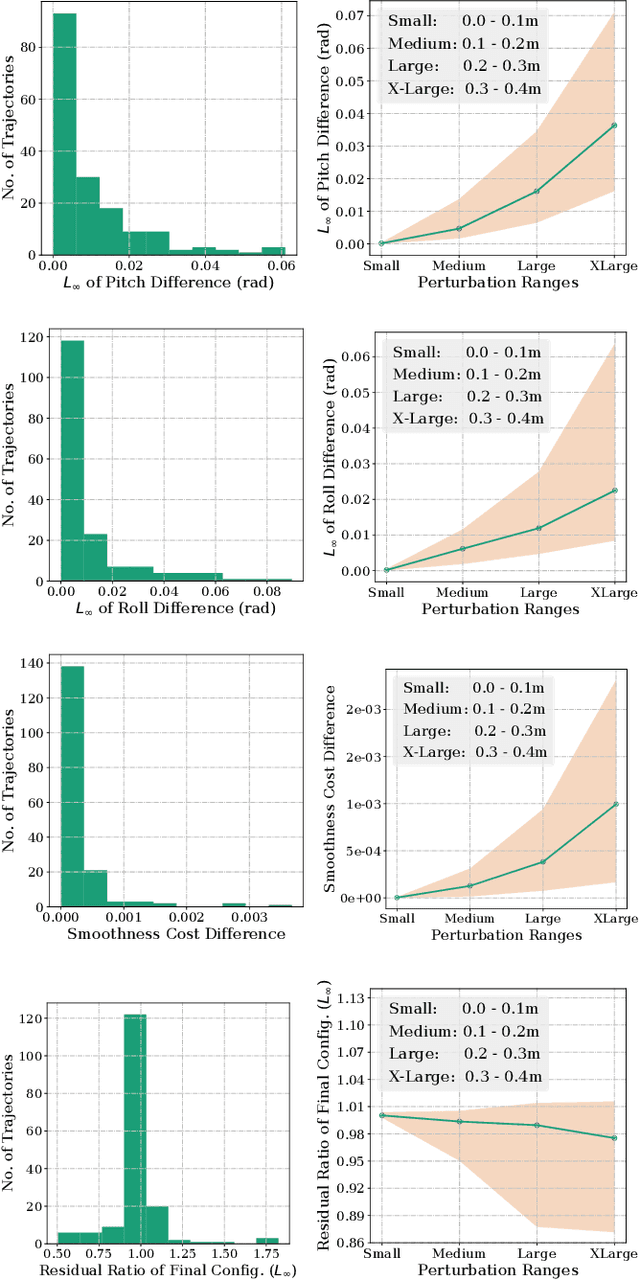
Joint space trajectory optimization under end-effector task constraints leads to a challenging non-convex problem. Thus, a real-time adaptation of prior computed trajectories to perturbation in task constraints often becomes intractable. Existing works use the so-called warm-starting of trajectory optimization to improve computational performance. We present a fundamentally different approach that relies on deriving analytical gradients of the optimal solution with respect to the task constraint parameters. This gradient map characterizes the direction in which the prior computed joint trajectories need to be deformed to comply with the new task constraints. Subsequently, we develop an iterative line-search algorithm for computing the scale of deformation. Our algorithm provides near real-time adaptation of joint trajectories for a diverse class of task perturbations such as (i) changes in initial and final joint configurations of end-effector orientation-constrained trajectories and (ii) changes in end-effector goal or way-points under end-effector orientation constraints. We relate each of these examples to real-world applications ranging from learning from demonstration to obstacle avoidance. We also show that our algorithm produces trajectories with quality similar to what one would obtain by solving the trajectory optimization from scratch with warm-start initialization. But most importantly, our algorithm achieves a worst-case speed-up of 160x over the latter approach.
On the Convergence of Deep Networks with Sample Quadratic Overparameterization
Jan 12, 2021
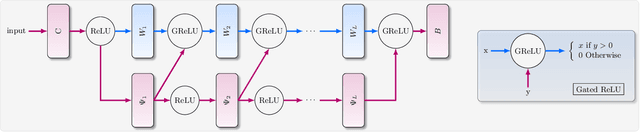
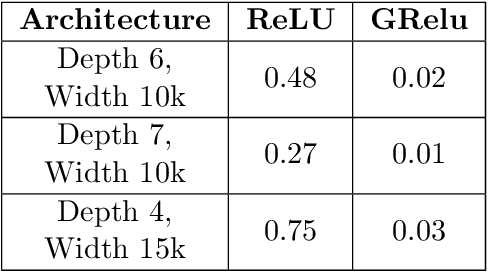
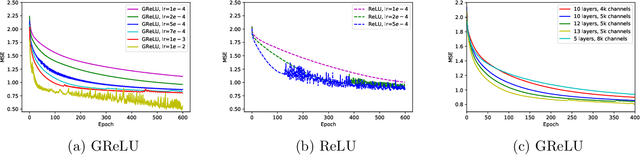
The remarkable ability of deep neural networks to perfectly fit training data when optimized by gradient-based algorithms is yet to be fully explained theoretically. Explanations by recent theoretical works rely on the networks to be wider by orders of magnitude than the ones used in practice. In this work, we take a step towards closing the gap between theory and practice. We show that a randomly initialized deep neural network with ReLU activation converges to a global minimum in a logarithmic number of gradient-descent iterations, under a considerably milder condition on its width. Our analysis is based on a novel technique of training a network with fixed activation patterns. We study the unique properties of the technique that allow an improved convergence, and can be transformed at any time to an equivalent ReLU network of a reasonable size. We derive a tight finite-width Neural Tangent Kernel (NTK) equivalence, suggesting that neural networks trained with our technique generalize well at least as good as its NTK, and it can be used to study generalization as well.
The Globally Optimal Reparameterization Algorithm: an Alternative to Fast Dynamic Time Warping for Action Recognition in Video Sequences
Jul 15, 2018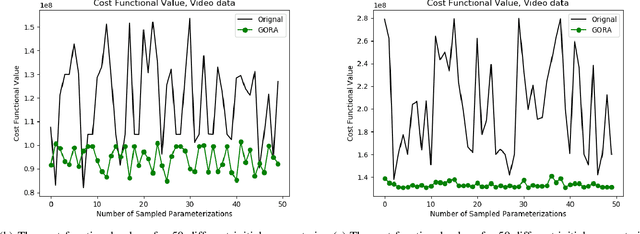
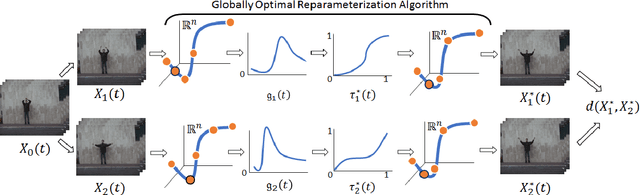
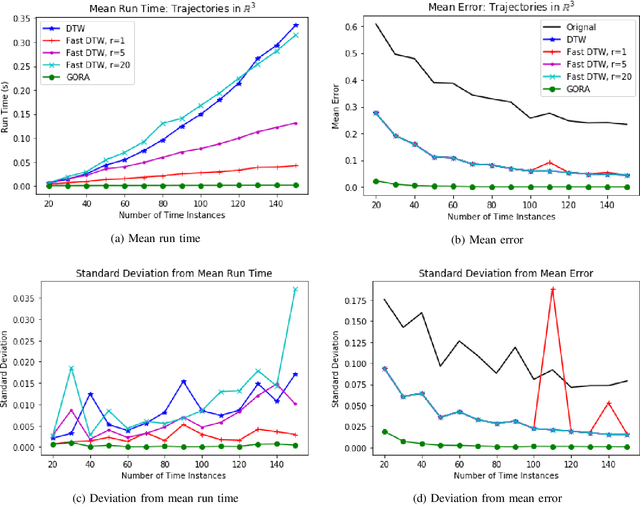
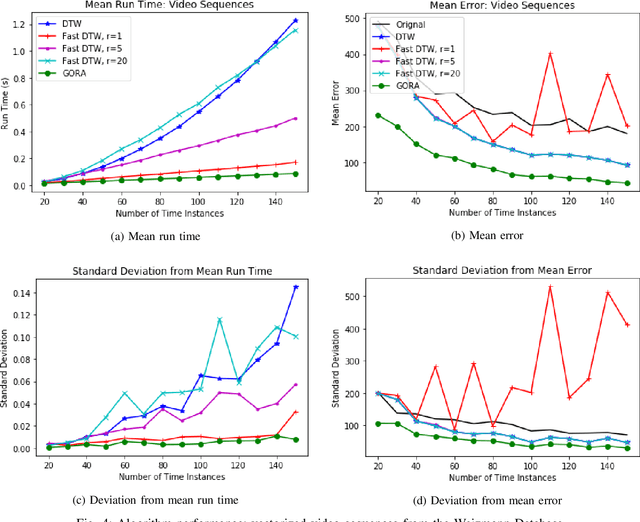
Signal alignment has become a popular problem in robotics due in part to its fundamental role in action recognition. Currently, the most successful algorithms for signal alignment are Dynamic Time Warping (DTW) and its variant 'Fast' Dynamic Time Warping (FastDTW). Here we introduce a new framework for signal alignment, namely the Globally Optimal Reparameterization Algorithm (GORA). We review the algorithm's mathematical foundation and provide a numerical verification of its theoretical basis. We compare the performance of GORA with that of the DTW and FastDTW algorithms, in terms of computational efficiency and accuracy in matching signals. Our results show a significant improvement in both speed and accuracy over the DTW and FastDTW algorithms and suggest that GORA has the potential to provide a highly effective framework for signal alignment and action recognition.
Triclustering in Big Data Setting
Oct 24, 2020
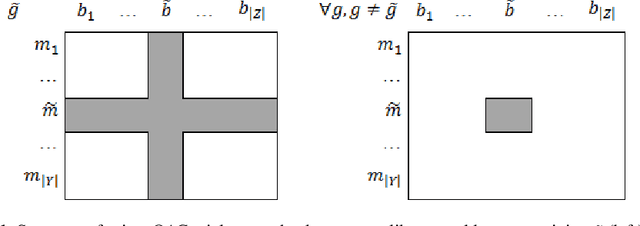
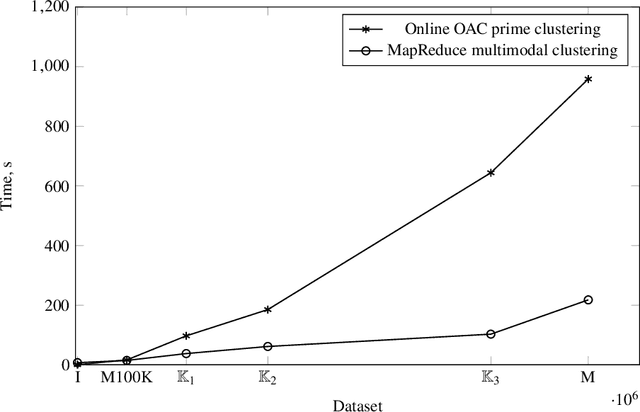
In this paper, we describe versions of triclustering algorithms adapted for efficient calculations in distributed environments with MapReduce model or parallelisation mechanism provided by modern programming languages. OAC-family of triclustering algorithms shows good parallelisation capabilities due to the independent processing of triples of a triadic formal context. We provide the time and space complexity of the algorithms and justify their relevance. We also compare performance gain from using a distributed system and scalability.
* The paper contains an extended version of the prior work presented at the workshop on FCA in the Big Data Era held on June 25, 2019 at Frankfurt University of Applied Sciences, Frankfurt, Germany