 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scatter Correction in X-ray CT by Physics-Inspired Deep Learning
Mar 21, 2021
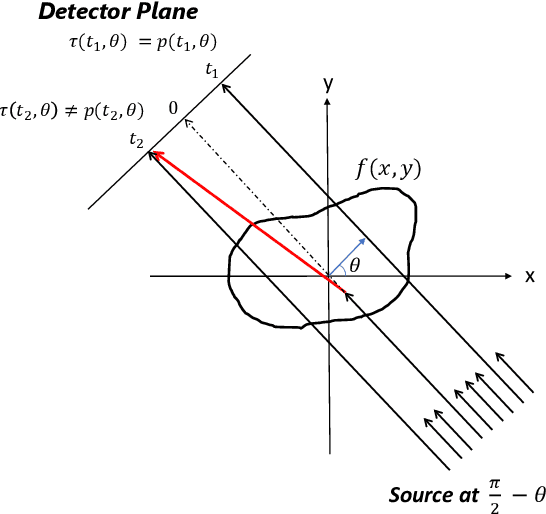
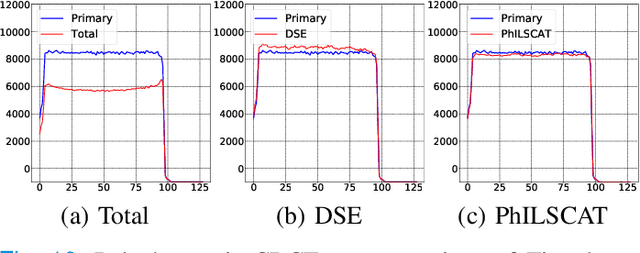

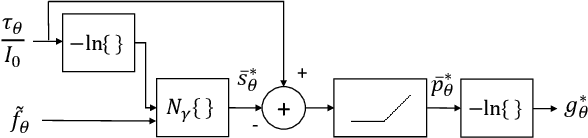
A fundamental problem in X-ray Computed Tomography (CT) is the scatter due to interaction of photons with the imaged object. Unless corrected, scatter manifests itself as degradations in the reconstructions in the form of various artifacts. Scatter correction is therefore critical for reconstruction quality. Scatter correction methods can be divided into two categories: hardware-based; and software-based. Despite success in specific settings, hardware-based methods require modification in the hardware, or increase in the scan time or dose. This makes software-based methods attractive. In this context, Monte-Carlo based scatter estimation, analytical-numerical, and kernel-based methods were developed. Furthermore, data-driven approaches to tackle this problem were recently demonstrated. In this work, two novel physics-inspired deep-learning-based methods, PhILSCAT and OV-PhILSCAT, are proposed. The methods estimate and correct for the scatter in the acquired projection measurements. They incorporate both an initial reconstruction of the object of interest and the scatter-corrupted measurements related to it. They use a common deep neural network architecture and cost function, both tailored to the problem. Numerical experiments with data obtained by Monte-Carlo simulations of the imaging of phantoms reveal significant improvement over a recent purely projection-domain deep neural network scatter correction method.
Robust Feedback Motion Policy Design Using Reinforcement Learning on a 3D Digit Bipedal Robot
Mar 29, 2021
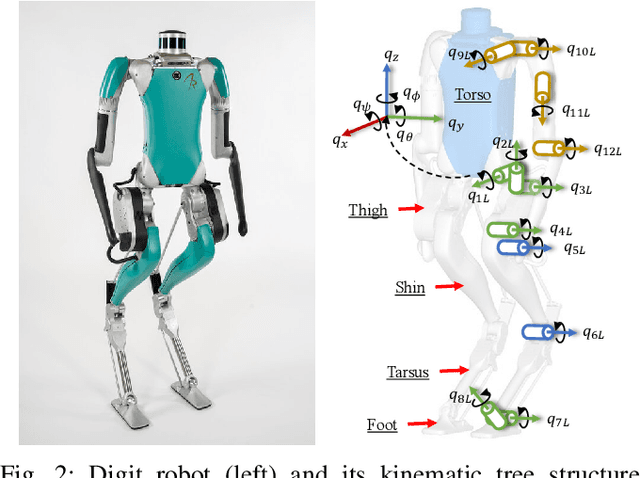
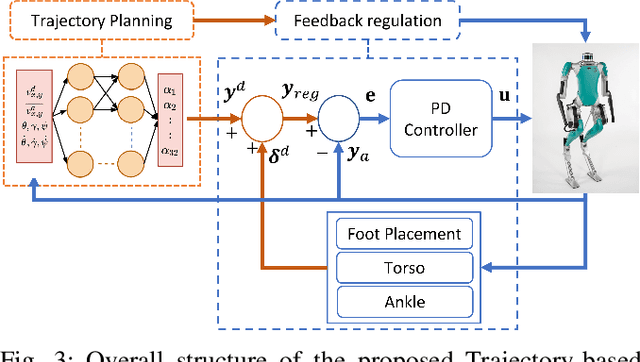
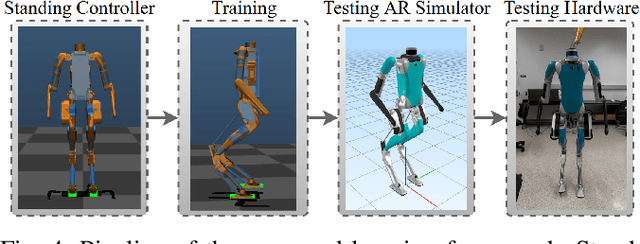
In this paper, a hierarchical and robust framework for learning bipedal locomotion is presented and successfully implemented on the 3D biped robot Digit built by Agility Robotics. We propose a cascade-structure controller that combines the learning process with intuitive feedback regulations. This design allows the framework to realize robust and stable walking with a reduced-dimension state and action spaces of the policy, significantly simplifying the design and reducing the sampling efficiency of the learning method. The inclusion of feedback regulation into the framework improves the robustness of the learned walking gait and ensures the success of the sim-to-real transfer of the proposed controller with minimal tuning. We specifically present a learning pipeline that considers hardware-feasible initial poses of the robot within the learning process to ensure the initial state of the learning is replicated as close as possible to the initial state of the robot in hardware experiments. Finally, we demonstrate the feasibility of our method by successfully transferring the learned policy in simulation to the Digit robot hardware, realizing sustained walking gaits under external force disturbances and challenging terrains not included during the training process. To the best of our knowledge, this is the first time a learning-based policy is transferred successfully to the Digit robot in hardware experiments without using dynamic randomization or curriculum learning.
PyTorch-Direct: Enabling GPU Centric Data Access for Very Large Graph Neural Network Training with Irregular Accesses
Jan 20, 2021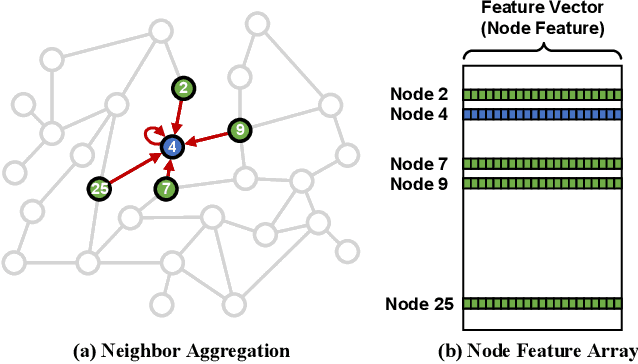

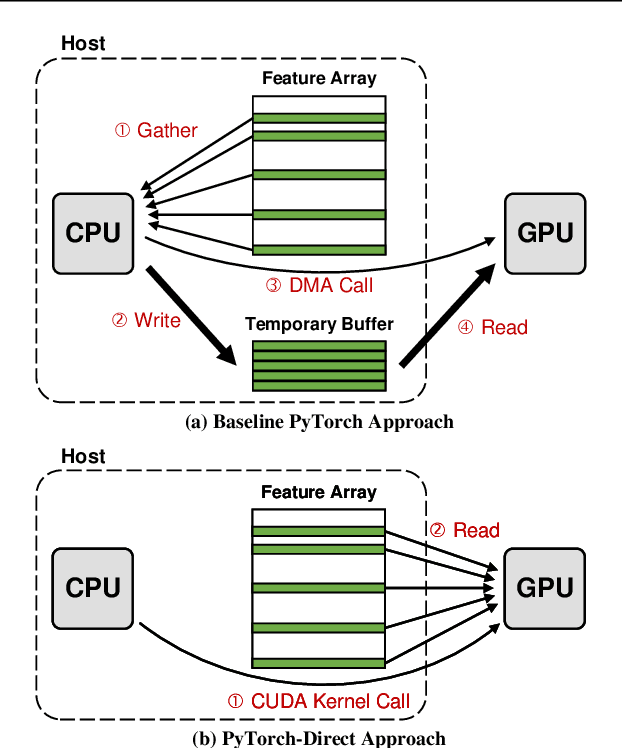

With the increasing adoption of graph neural networks (GNNs) in the machine learning community, GPUs have become an essential tool to accelerate GNN training. However, training GNNs on very large graphs that do not fit in GPU memory is still a challenging task. Unlike conventional neural networks, mini-batching input samples in GNNs requires complicated tasks such as traversing neighboring nodes and gathering their feature values. While this process accounts for a significant portion of the training time, we find existing GNN implementations using popular deep neural network (DNN) libraries such as PyTorch are limited to a CPU-centric approach for the entire data preparation step. This "all-in-CPU" approach has negative impact on the overall GNN training performance as it over-utilizes CPU resources and hinders GPU acceleration of GNN training. To overcome such limitations, we introduce PyTorch-Direct, which enables a GPU-centric data accessing paradigm for GNN training. In PyTorch-Direct, GPUs are capable of efficiently accessing complicated data structures in host memory directly without CPU intervention. Our microbenchmark and end-to-end GNN training results show that PyTorch-Direct reduces data transfer time by 47.1% on average and speeds up GNN training by up to 1.6x. Furthermore, by reducing CPU utilization, PyTorch-Direct also saves system power by 12.4% to 17.5% during training. To minimize programmer effort, we introduce a new "unified tensor" type along with necessary changes to the PyTorch memory allocator, dispatch logic, and placement rules. As a result, users need to change at most two lines of their PyTorch GNN training code for each tensor object to take advantage of PyTorch-Direct.
RuSemShift: a dataset of historical lexical semantic change in Russian
Oct 13, 2020


We present RuSemShift, a large-scale manually annotated test set for the task of semantic change modeling in Russian for two long-term time period pairs: from the pre-Soviet through the Soviet times and from the Soviet through the post-Soviet times. Target words were annotated by multiple crowd-source workers. The annotation process was organized following the DURel framework and was based on sentence contexts extracted from the Russian National Corpus. Additionally, we report the performance of several distributional approaches on RuSemShift, achieving promising results, which at the same time leave room for other researchers to improve.
HI-Net: Hyperdense Inception 3D UNet for Brain Tumor Segmentation
Dec 12, 2020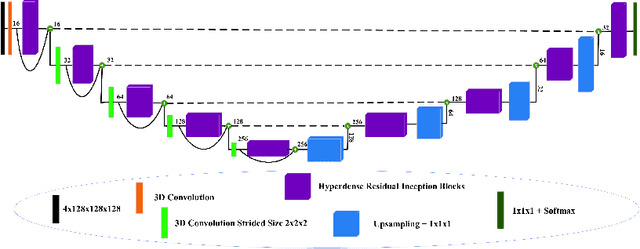
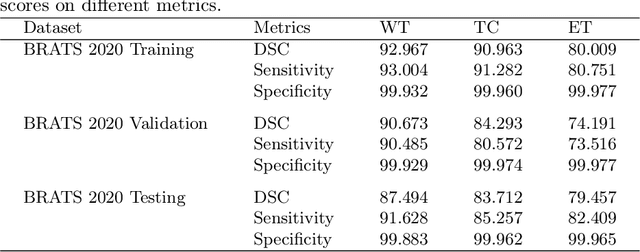
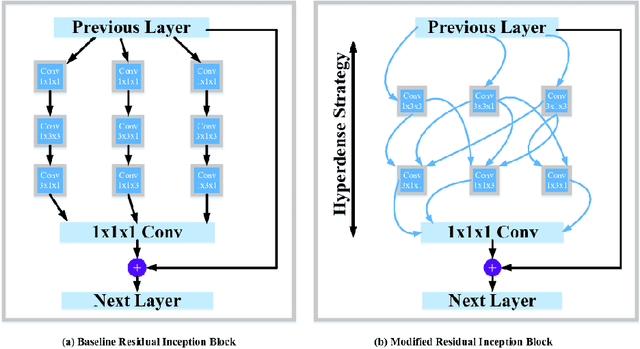

The brain tumor segmentation task aims to classify tissue into the whole tumor (WT), tumor core (TC), and enhancing tumor (ET) classes using multimodel MRI images. Quantitative analysis of brain tumors is critical for clinical decision making. While manual segmentation is tedious, time-consuming, and subjective, this task is at the same time very challenging to automatic segmentation methods. Thanks to the powerful learning ability, convolutional neural networks (CNNs), mainly fully convolutional networks, have shown promising brain tumor segmentation. This paper further boosts the performance of brain tumor segmentation by proposing hyperdense inception 3D UNet (HI-Net), which captures multi-scale information by stacking factorization of 3D weighted convolutional layers in the residual inception block. We use hyper dense connections among factorized convolutional layers to extract more contexual information, with the help of features reusability. We use a dice loss function to cope with class imbalances. We validate the proposed architecture on the multi-modal brain tumor segmentation challenges (BRATS) 2020 testing dataset. Preliminary results on the BRATS 2020 testing set show that achieved by our proposed approach, the dice (DSC) scores of ET, WT, and TC are 0.79457, 0.87494, and 0.83712, respectively.
Automatic quality control of brain T1-weighted magnetic resonance images for a clinical data warehouse
Apr 16, 2021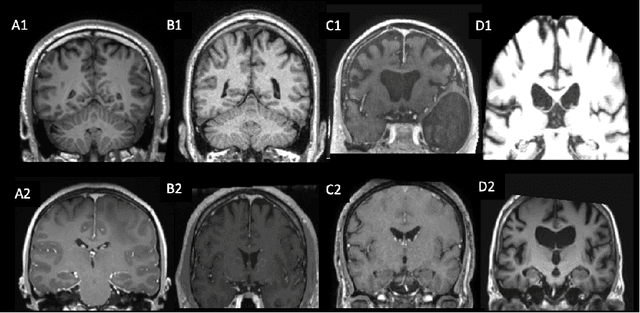
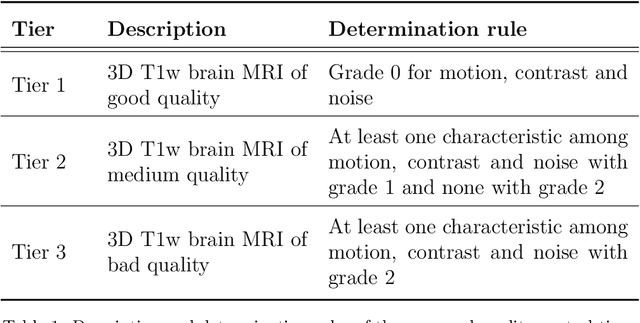
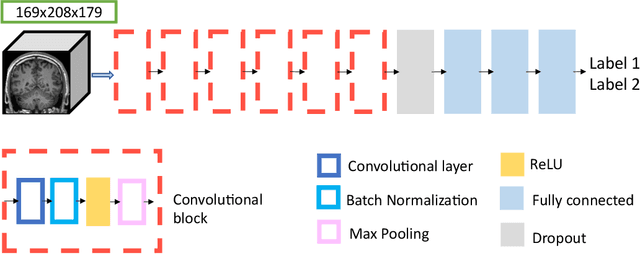
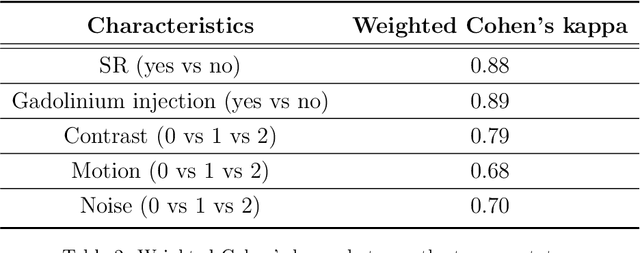
Many studies on machine learning (ML) for computer-aided diagnosis have so far been mostly restricted to high-quality research data. Clinical data warehouses, gathering routine examinations from hospitals, offer great promises for training and validation of ML models in a realistic setting. However, the use of such clinical data warehouses requires quality control (QC) tools. Visual QC by experts is time-consuming and does not scale to large datasets. In this paper, we propose a convolutional neural network (CNN) for the automatic QC of 3D T1-weighted brain MRI for a large heterogeneous clinical data warehouse. To that purpose, we used the data warehouse of the hospitals of the Greater Paris area (Assistance Publique-H\^opitaux de Paris [AP-HP]). Specifically, the objectives were: 1) to identify images which are not proper T1-weighted brain MRIs; 2) to identify acquisitions for which gadolinium was injected; 3) to rate the overall image quality. We used 5000 images for training and validation and a separate set of 500 images for testing. In order to train/validate the CNN, the data were annotated by two trained raters according to a visual QC protocol that we specifically designed for application in the setting of a data warehouse. For objectives 1 and 2, our approach achieved excellent accuracy (balanced accuracy and F1-score \textgreater 90\%), similar to the human raters. For objective 3, the performance was good but substantially lower than that of human raters. Nevertheless, the automatic approach accurately identified (balanced accuracy and F1-score \textgreater 80\%) low quality images, which would typically need to be excluded. Overall, our approach shall be useful for exploiting hospital data warehouses in medical image computing.
Fast Data-Driven Learning of MRI Sampling Pattern for Large Scale Problems
Nov 04, 2020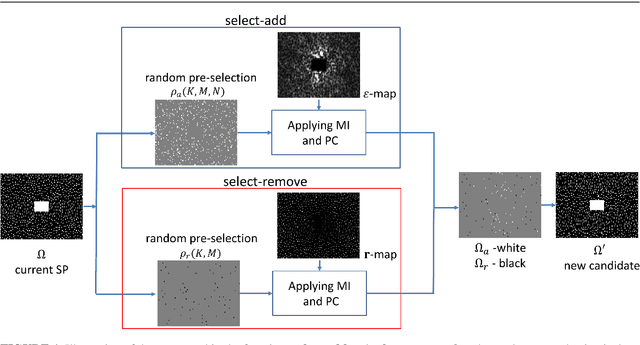
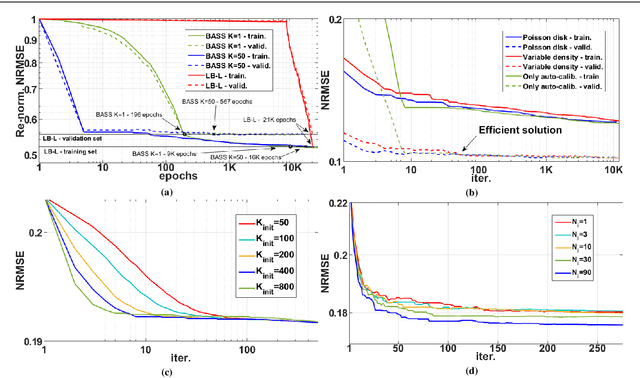

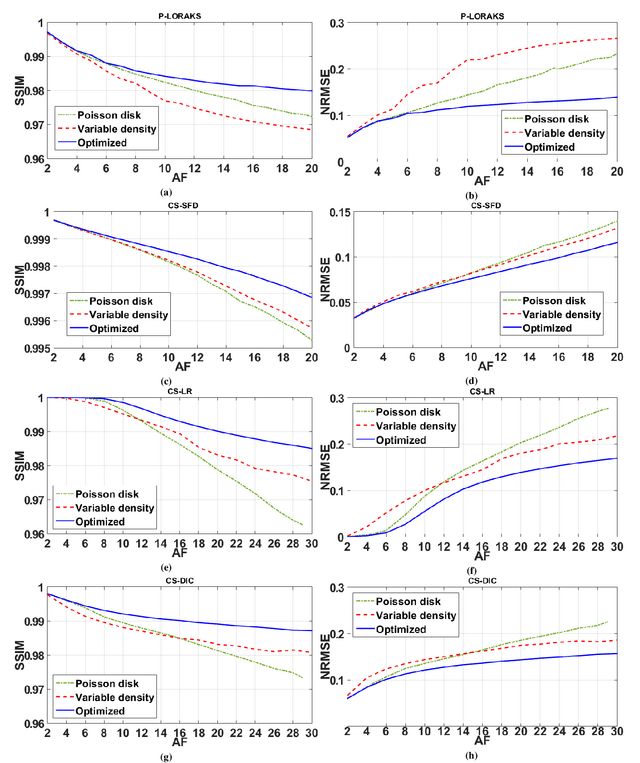
Purpose: A fast data-driven optimization approach, named bias-accelerated subset selection (BASS), is proposed for learning efficacious sampling patterns (SPs) with the purpose of reducing scan time in large-dimensional parallel MRI. Methods: BASS is applicable when Cartesian fully-sampled k-space data of specific anatomy is available for training and the reconstruction method is specified, learning which k-space points are more relevant for the specific anatomy and reconstruction in recovering the non-sampled points. BASS was tested with four reconstruction methods for parallel MRI based on low-rankness and sparsity that allow a free choice of the SP. Two datasets were tested, one of the brain images for high-resolution imaging and another of knee images for quantitative mapping of the cartilage. Results: BASS, with its low computational cost and fast convergence, obtained SPs 100 times faster than the current best greedy approaches. Reconstruction quality increased up to 45\% with our learned SP over that provided by variable density and Poisson disk SPs, considering the same scan time. Optionally, the scan time can be nearly halved without loss of reconstruction quality. Conclusion: Compared with current approaches, BASS can be used to rapidly learn effective SPs for various reconstruction methods, using larger SP and larger datasets. This enables a better selection of efficacious sampling-reconstruction pairs for specific MRI problems.
Constructing Segmented Differentiable Quadratics to Determine Algorithmic Run Times and Model Non-Polynomial Functions
Dec 03, 2020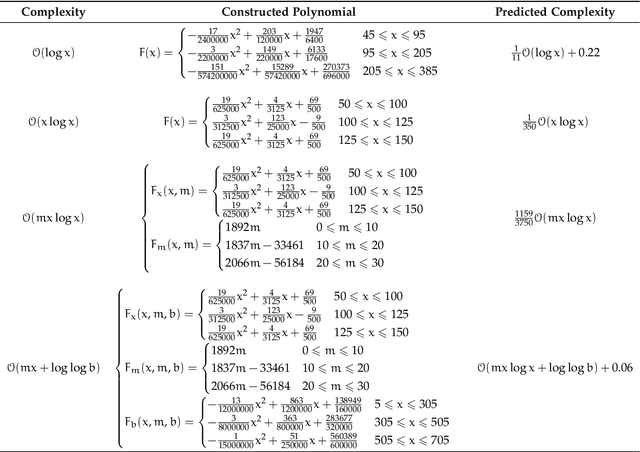
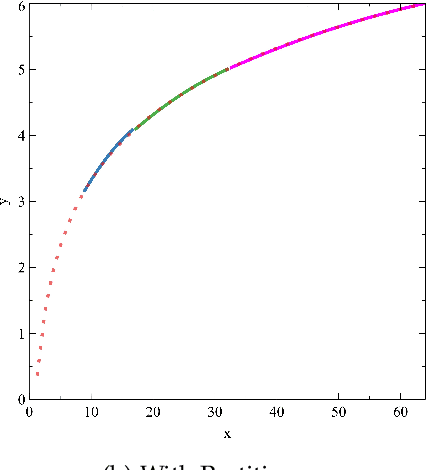
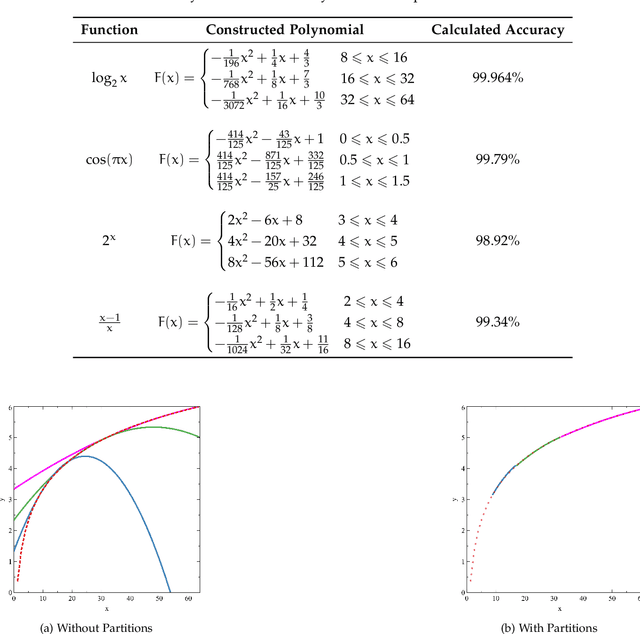
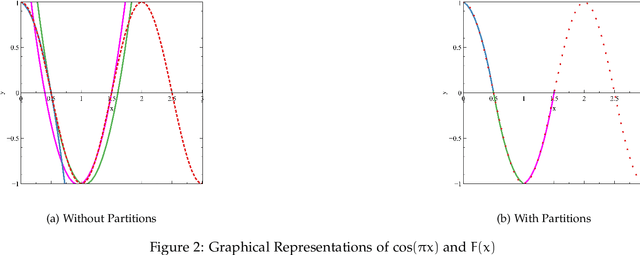
We propose an approach to determine the continual progression of algorithmic efficiency, as an alternative to standard calculations of time complexity, likely, but not exclusively, when dealing with data structures with unknown maximum indexes and with algorithms that are dependent on multiple variables apart from just input size. The proposed method can effectively determine the run time behavior $F$ at any given index $x$ , as well as $\frac{\partial F}{\partial x}$, as a function of only one or multiple arguments, by combining $\frac{n}{2}$ quadratic segments, based upon the principles of Lagrangian Polynomials and their respective secant lines. Although the approach used is designed for analyzing the efficacy of computational algorithms, the proposed method can be used within the pure mathematical field as a novel way to construct non-polynomial functions, such as $\log_2{n}$ or $\frac{n+1}{n-2}$, as a series of segmented differentiable quadratics to model functional behavior and reoccurring natural patterns. After testing, our method had an average accuracy of above of 99\% with regard to functional resemblance.
Recent Advances in Adversarial Training for Adversarial Robustness
Feb 02, 2021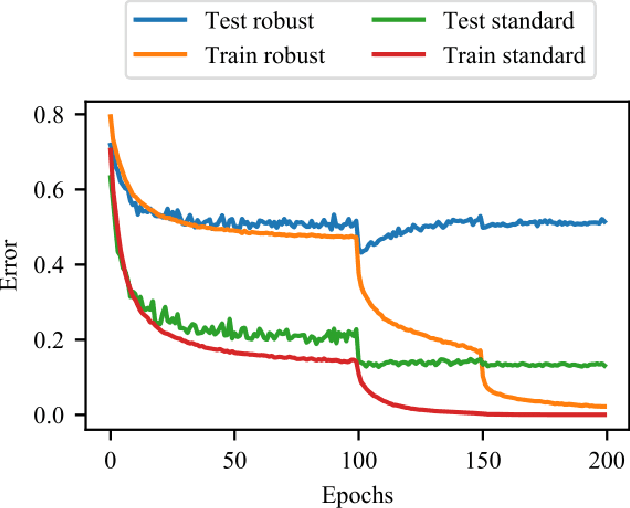
Adversarial examples for fooling deep learning models have been studied for several years and are still a hot topic. Adversarial training also receives enormous attention because of its effectiveness in defending adversarial examples. However, adversarial training is not perfect, many questions of which remain to solve. During the last few years, researchers in this community have studied and discussed adversarial training from various aspects. Many new theories and understandings of adversarial training have been proposed. In this survey, we systematically review the recent progress on adversarial training for the first time, categorized by different improvements. Then we discuss the generalization problems in adversarial training from three perspectives. Finally, we highlight the challenges which are not fully solved and present potential future directions.
District Wise Price Forecasting of Wheat in Pakistan using Deep Learning
Mar 05, 2021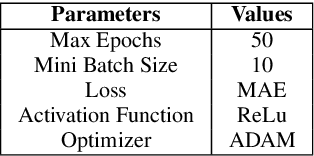
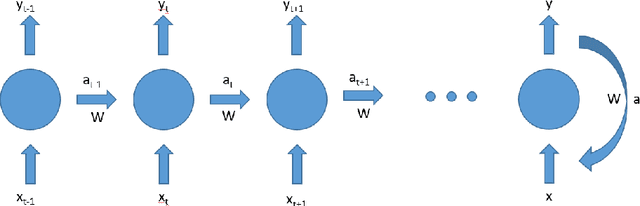
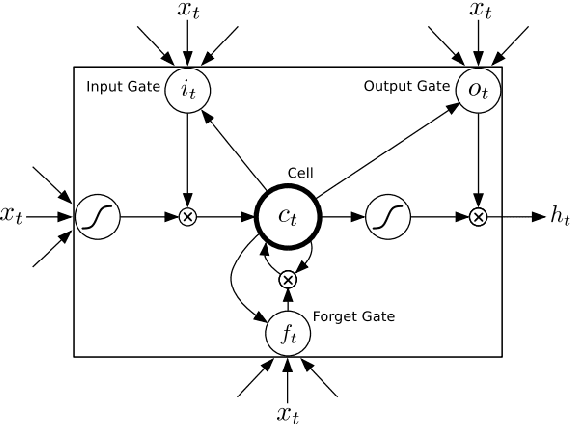
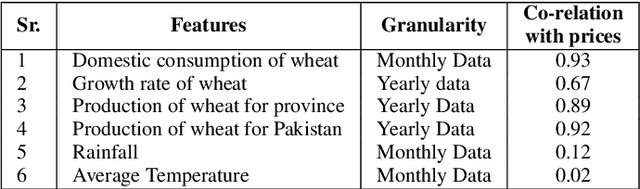
Wheat is the main agricultural crop of Pakistan and is a staple food requirement of almost every Pakistani household making it the main strategic commodity of the country whose availability and affordability is the government's main priority. Wheat food availability can be vastly affected by multiple factors included but not limited to the production, consumption, financial crisis, inflation, or volatile market. The government ensures food security by particular policy and monitory arrangements, which keeps up purchase parity for the poor. Such arrangements can be made more effective if a dynamic analysis is carried out to estimate the future yield based on certain current factors. Future planning of commodity pricing is achievable by forecasting their future price anticipated by the current circumstances. This paper presents a wheat price forecasting methodology, which uses the price, weather, production, and consumption trends for wheat prices taken over the past few years and analyzes them with the help of advance neural networks architecture Long Short Term Memory (LSTM) networks. The proposed methodology presented significantly improved results versus other conventional machine learning and statistical time series analysis methods.