 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetting for Sim-to-Real Performance Evaluation
Apr 27, 2026This paper studies the problem of robot performance evaluation, focusing on how to obtain accurate and efficient estimates of real-world behavior under severe constraints on physical experimentation. Such estimates are essential for benchmarking algorithms, comparing design alternatives, validating controllers, and supporting certification or regulatory decision-making, yet real-world testing with physical robots is often expensive, time-consuming, and safety-limited. To mitigate the scarcity of real-world trials, sim-to-real methodologies are commonly employed, using low-cost simulators to inform, supplement, or prioritize physical experiments. Departing from (and complementary to) existing approaches in variance reduction (e.g., importance-sampling variants) or bias-correction (e.g., through prediction-powered inference or learned control variates), we examine this performance-evaluation problem through the lens of betting. We establish theoretical conditions under which a betting mechanism can yield accurate and efficient estimates (provably outperforming the Monte Carlo estimator) and we characterize how such bets should be constructed. We further develop theoretically grounded yet practically implementable approximations of the ideal bet, and we provide concrete decision rules that diagnose when these approximate betting strategies are working as intended. We demonstrate the effectiveness of the proposed methods using both synthetic examples and cross-fidelity computational simulators. Notably, we also showcase an illustrative case in which a group of synthetic distributions are used to infer the real-world pick-and-place accuracy of a robotic manipulator, a seemingly unconventional sim-to-real transfer that becomes natural and feasible under the proposed betting perspective. Programs for reproducing empirical results are available at https://github.com/ISUSAIL/Bet4Sim2Real.
Aligning Microscopic Vehicle and Macroscopic Traffic Statistics: Reconstructing Driving Behavior from Partial Data
Jan 29, 2026A driving algorithm that aligns with good human driving practices, or at the very least collaborates effectively with human drivers, is crucial for developing safe and efficient autonomous vehicles. In practice, two main approaches are commonly adopted: (i) supervised or imitation learning, which requires comprehensive naturalistic driving data capturing all states that influence a vehicle's decisions and corresponding actions, and (ii) reinforcement learning (RL), where the simulated driving environment either matches or is intentionally more challenging than real-world conditions. Both methods depend on high-quality observations of real-world driving behavior, which are often difficult and costly to obtain. State-of-the-art sensors on individual vehicles can gather microscopic data, but they lack context about the surrounding conditions. Conversely, roadside sensors can capture traffic flow and other macroscopic characteristics, but they cannot associate this information with individual vehicles on a microscopic level. Motivated by this complementarity, we propose a framework that reconstructs unobserved microscopic states from macroscopic observations, using microscopic data to anchor observed vehicle behaviors, and learns a shared policy whose behavior is microscopically consistent with the partially observed trajectories and actions and macroscopically aligned with target traffic statistics when deployed population-wide. Such constrained and regularized policies promote realistic flow patterns and safe coordination with human drivers at scale.
Rethink Repeatable Measures of Robot Performance with Statistical Query
May 13, 2025For a general standardized testing algorithm designed to evaluate a specific aspect of a robot's performance, several key expectations are commonly imposed. Beyond accuracy (i.e., closeness to a typically unknown ground-truth reference) and efficiency (i.e., feasibility within acceptable testing costs and equipment constraints), one particularly important attribute is repeatability. Repeatability refers to the ability to consistently obtain the same testing outcome when similar testing algorithms are executed on the same subject robot by different stakeholders, across different times or locations. However, achieving repeatable testing has become increasingly challenging as the components involved grow more complex, intelligent, diverse, and, most importantly, stochastic. While related efforts have addressed repeatability at ethical, hardware, and procedural levels, this study focuses specifically on repeatable testing at the algorithmic level. Specifically, we target the well-adopted class of testing algorithms in standardized evaluation: statistical query (SQ) algorithms (i.e., algorithms that estimate the expected value of a bounded function over a distribution using sampled data). We propose a lightweight, parameterized, and adaptive modification applicable to any SQ routine, whether based on Monte Carlo sampling, importance sampling, or adaptive importance sampling, that makes it provably repeatable, with guaranteed bounds on both accuracy and efficiency. We demonstrate the effectiveness of the proposed approach across three representative scenarios: (i) established and widely adopted standardized testing of manipulators, (ii) emerging intelligent testing algorithms for operational risk assessment in automated vehicles, and (iii) developing use cases involving command tracking performance evaluation of humanoid robots in locomotion tasks.
Post-Convergence Sim-to-Real Policy Transfer: A Principled Alternative to Cherry-Picking
Apr 21, 2025



Learning-based approaches, particularly reinforcement learning (RL), have become widely used for developing control policies for autonomous agents, such as locomotion policies for legged robots. RL training typically maximizes a predefined reward (or minimizes a corresponding cost/loss) by iteratively optimizing policies within a simulator. Starting from a randomly initialized policy, the empirical expected reward follows a trajectory with an overall increasing trend. While some policies become temporarily stuck in local optima, a well-defined training process generally converges to a reward level with noisy oscillations. However, selecting a policy for real-world deployment is rarely an analytical decision (i.e., simply choosing the one with the highest reward) and is instead often performed through trial and error. To improve sim-to-real transfer, most research focuses on the pre-convergence stage, employing techniques such as domain randomization, multi-fidelity training, adversarial training, and architectural innovations. However, these methods do not eliminate the inevitable convergence trajectory and noisy oscillations of rewards, leading to heuristic policy selection or cherry-picking. This paper addresses the post-convergence sim-to-real transfer problem by introducing a worst-case performance transference optimization approach, formulated as a convex quadratic-constrained linear programming problem. Extensive experiments demonstrate its effectiveness in transferring RL-based locomotion policies from simulation to real-world laboratory tests.
Repeatable and Reliable Efforts of Accelerated Risk Assessment
May 30, 2024



Risk assessment of a robot in controlled environments, such as laboratories and proving grounds, is a common means to assess, certify, validate, verify, and characterize the robots' safety performance before, during, and even after their commercialization in the real-world. A standard testing program that acquires the risk estimate is expected to be (i) repeatable, such that it obtains similar risk assessments of the same testing subject among multiple trials or attempts with the similar testing effort by different stakeholders, and (ii) reliable against a variety of testing subjects produced by different vendors and manufacturers. Both repeatability and reliability are fundamental and crucial for a testing algorithm's validity, fairness, and practical feasibility, especially for standardization. However, these properties are rarely satisfied or ensured, especially as the subject robots become more complex, uncertain, and varied. This issue was present in traditional risk assessments through Monte-Carlo sampling, and remains a bottleneck for the recent accelerated risk assessment methods, primarily those using importance sampling. This study aims to enhance existing accelerated testing frameworks by proposing a new algorithm that provably integrates repeatability and reliability with the already established formality and efficiency. It also features demonstrations assessing the risk of instability from frontal impacts, initiated by push-over disturbances on a controlled inverted pendulum and a 7-DoF planar bipedal robot Rabbit managed by various control algorithms.
Template Model Inspired Task Space Learning for Robust Bipedal Locomotion
Sep 27, 2023



This work presents a hierarchical framework for bipedal locomotion that combines a Reinforcement Learning (RL)-based high-level (HL) planner policy for the online generation of task space commands with a model-based low-level (LL) controller to track the desired task space trajectories. Different from traditional end-to-end learning approaches, our HL policy takes insights from the angular momentum-based linear inverted pendulum (ALIP) to carefully design the observation and action spaces of the Markov Decision Process (MDP). This simple yet effective design creates an insightful mapping between a low-dimensional state that effectively captures the complex dynamics of bipedal locomotion and a set of task space outputs that shape the walking gait of the robot. The HL policy is agnostic to the task space LL controller, which increases the flexibility of the design and generalization of the framework to other bipedal robots. This hierarchical design results in a learning-based framework with improved performance, data efficiency, and robustness compared with the ALIP model-based approach and state-of-the-art learning-based frameworks for bipedal locomotion. The proposed hierarchical controller is tested in three different robots, Rabbit, a five-link underactuated planar biped; Walker2D, a seven-link fully-actuated planar biped; and Digit, a 3D humanoid robot with 20 actuated joints. The trained policy naturally learns human-like locomotion behaviors and is able to effectively track a wide range of walking speeds while preserving the robustness and stability of the walking gait even under adversarial conditions.
Data-Driven Latent Space Representation for Robust Bipedal Locomotion Learning
Sep 27, 2023



This paper presents a novel framework for learning robust bipedal walking by combining a data-driven state representation with a Reinforcement Learning (RL) based locomotion policy. The framework utilizes an autoencoder to learn a low-dimensional latent space that captures the complex dynamics of bipedal locomotion from existing locomotion data. This reduced dimensional state representation is then used as states for training a robust RL-based gait policy, eliminating the need for heuristic state selections or the use of template models for gait planning. The results demonstrate that the learned latent variables are disentangled and directly correspond to different gaits or speeds, such as moving forward, backward, or walking in place. Compared to traditional template model-based approaches, our framework exhibits superior performance and robustness in simulation. The trained policy effectively tracks a wide range of walking speeds and demonstrates good generalization capabilities to unseen scenarios.
Towards Standardized Disturbance Rejection Testing of Legged Robot Locomotion with Linear Impactor: A Preliminary Study, Observations, and Implications
Aug 28, 2023



Dynamic locomotion in legged robots is close to industrial collaboration, but a lack of standardized testing obstructs commercialization. The issues are not merely political, theoretical, or algorithmic but also physical, indicating limited studies and comprehension regarding standard testing infrastructure and equipment. For decades, the approaches we have been testing legged robots were rarely standardizable with hand-pushing, foot-kicking, rope-dragging, stick-poking, and ball-swinging. This paper aims to bridge the gap by proposing the use of the linear impactor, a well-established tool in other standardized testing disciplines, to serve as an adaptive, repeatable, and fair disturbance rejection testing equipment for legged robots. A pneumatic linear impactor is also adopted for the case study involving the humanoid robot Digit. Three locomotion controllers are examined, including a commercial one, using a walking-in-place task against frontal impacts. The statistically best controller was able to withstand the impact momentum (26.376 kg$\cdot$m/s) on par with a reported average effective momentum from straight punches by Olympic boxers (26.506 kg$\cdot$m/s). Moreover, the case study highlights other anti-intuitive observations, demonstrations, and implications that, to the best of the authors' knowledge, are first-of-its-kind revealed in real-world testing of legged robots.
A Diversity Analysis of Safety Metrics Comparing Vehicle Performance in the Lead-Vehicle Interaction Regime
Jun 26, 2023



Vehicle performance metrics analyze data sets consisting of subject vehicle's interactions with other road users in a nominal driving environment and provide certain performance measures as outputs. To the best of the authors' knowledge, the vehicle safety performance metrics research dates back to at least 1967. To date, there still does not exist a community-wide accepted metric or a set of metrics for vehicle safety performance assessment and justification. This issue gets further amplified with the evolving interest in Advanced Driver Assistance Systems and Automated Driving Systems. In this paper, the authors seek to perform a unified study that facilitates an improved community-wide understanding of vehicle performance metrics using the lead-vehicle interaction operational design domain as a common means of performance comparison. In particular, the authors study the diversity (including constructive formulation discrepancies and empirical performance differences) among 33 base metrics with up to 51 metric variants (with different choices of hyper-parameters) in the existing literature, published between 1967 and 2022. Two data sets are adopted for the empirical performance diversity analysis, including vehicle trajectories from normal highway driving environment and relatively high-risk incidents with collisions and near-miss cases. The analysis further implies that (i) the conceptual acceptance of a safety metric proposal can be problematic if the assumptions, conditions, and types of outcome assurance are not justified properly, and (ii) the empirical performance justification of an acceptable metric can also be problematic as a dominant consensus is not observed among metrics empirically.
Rethink the Adversarial Scenario-based Safety Testing of Robots: the Comparability and Optimal Aggressiveness
Sep 20, 2022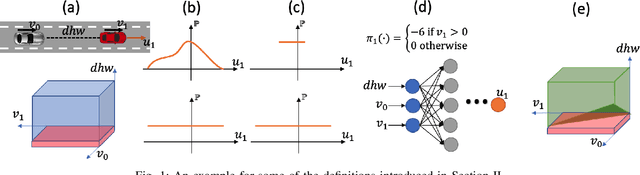
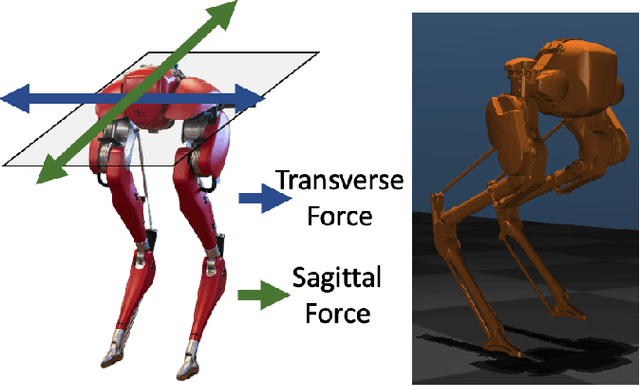
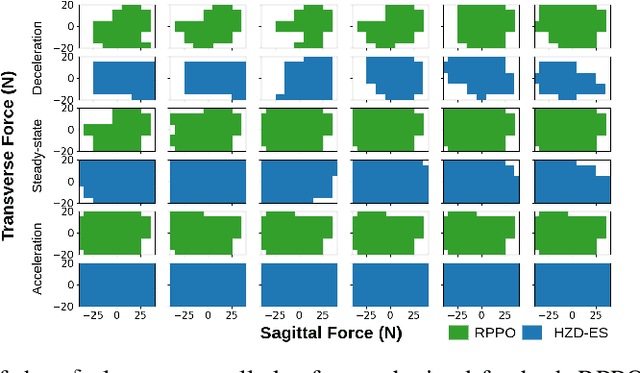
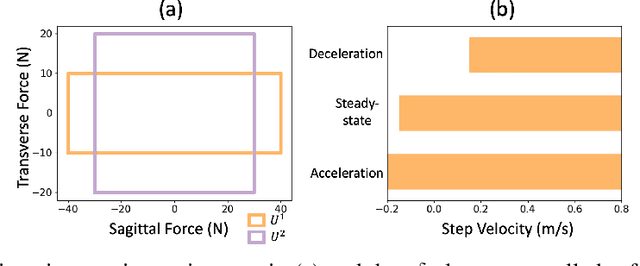
This paper studies the class of scenario-based safety testing algorithms in the black-box safety testing configuration. For algorithms sharing the same state-action set coverage with different sampling distributions, it is commonly believed that prioritizing the exploration of high-risk state-actions leads to a better sampling efficiency. Our proposal disputes the above intuition by introducing an impossibility theorem that provably shows all safety testing algorithms of the aforementioned difference perform equally well with the same expected sampling efficiency. Moreover, for testing algorithms covering different sets of state-actions, the sampling efficiency criterion is no longer applicable as different algorithms do not necessarily converge to the same termination condition. We then propose a testing aggressiveness definition based on the almost safe set concept along with an unbiased and efficient algorithm that compares the aggressiveness between testing algorithms. Empirical observations from the safety testing of bipedal locomotion controllers and vehicle decision-making modules are also presented to support the proposed theoretical implications and methodologies.