 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ambient PMU Data Based System Oscillation Analysis Using Multivariate Empirical Mode Decomposition
Jan 12, 2021

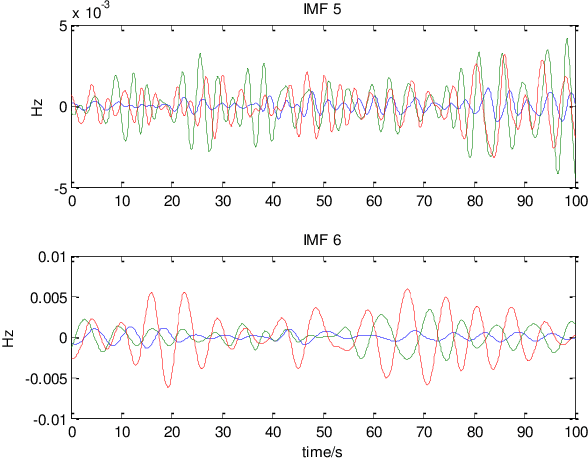
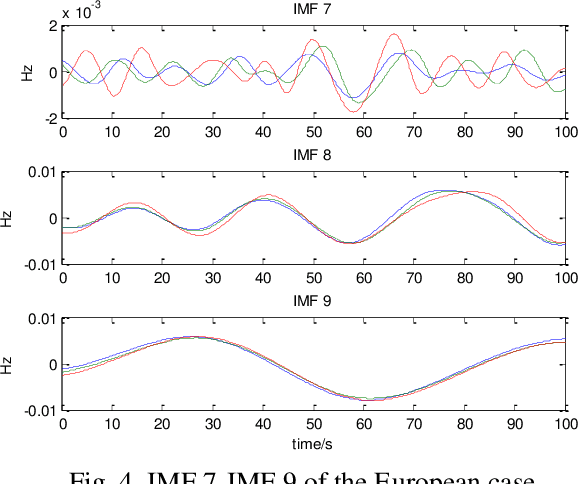
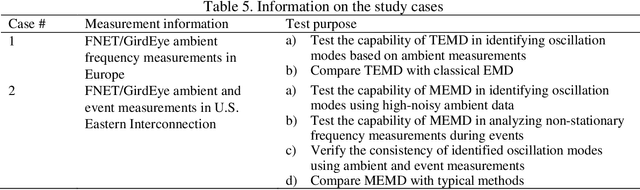
Wide-area synchrophasor ambient measurements provide a valuable data source for real-time oscillation mode monitoring and analysis. This paper introduces a novel method for identifying inter-area oscillation modes using wide-area ambient measurements. Based on multivariate empirical mode decomposition (MEMD), which can analyze multi-channel non-stationary and nonlinear signals, the proposed method is capable of detecting the common oscillation mode that exists in multiple synchrophasor measurements at low amplitudes. Test results based on two real-world datasets validate the effectiveness of the proposed method.
A comparison of three heart rate detection algorithms over ballistocardiogram signals
Jan 22, 2021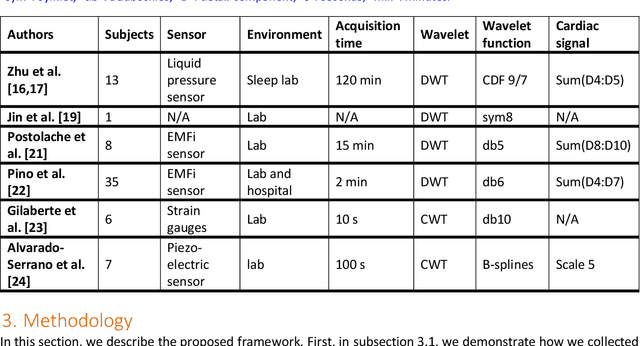
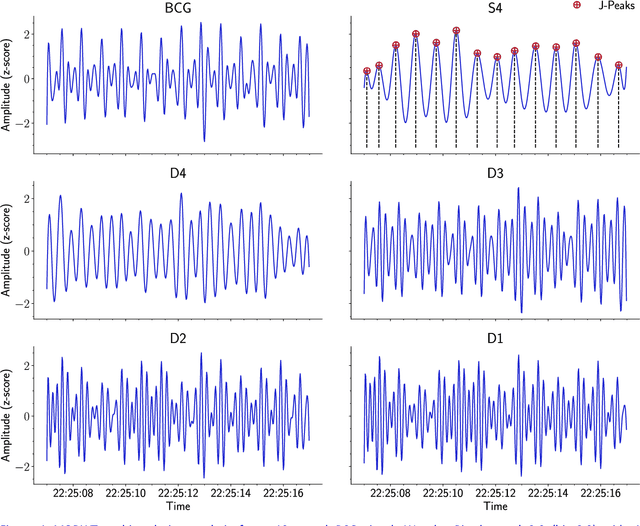
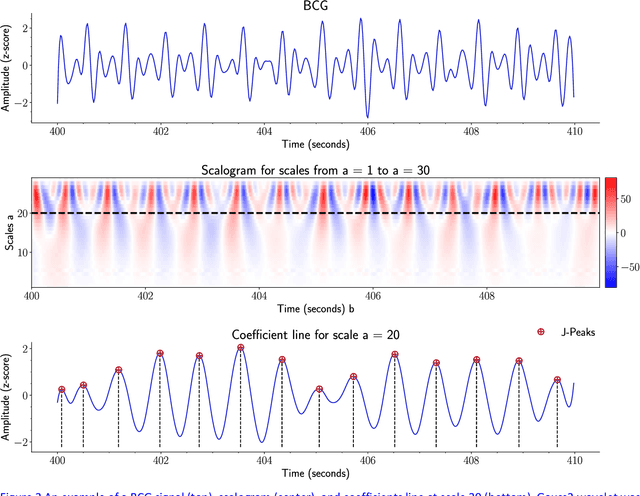

Heart rate (HR) detection from ballistocardiogram (BCG) signals is challenging for various reasons. For example, BCG signals' morphology can vary between and within-subjects. Also, it differs from one sensor to another. Hence, it is essential to evaluate HR detection algorithms across different datasets and under different experimental setups. This paper investigated the suitability of three algorithms (i.e., MODWT-MRA, CWT, and template matching) for HR detection across three independent BCG datasets. The first two datasets (Datset1 and DataSet2) were obtained using a microbend fiber optic (MFOS) sensor, while the last one (DataSet3) was obtained using a fiber Bragg grating (FBG) sensor. DataSet1 was collected from 10 OSA patients during an in-lab PSG study, Datset2 was obtained from 50 subjects in a sitting position, and DataSet3 was gathered from 10 subjects in a sleeping position. The CWT with derivative of Gaussian (Gaus2) provided superior results than the MODWT-MAR, CWT (frequency B-spline-Fbsp-2-1-1), and CWT (Shannon-Shan1.5-1.0) for DataSet1 and DataSet2. That said, a BCG template was constructed from DataSet1. Then, it was applied for HR detection across DataSet2. The template matching method achieved slightly superior results than CWT-Gaus2 for DataSet2. Furthermore, it has proved useful for HR detection across DataSet3 despite that BCG signals were obtained from a different sensor and under different conditions. Overall, the time required to analyze a 30-second BCG signal was in a millisecond resolution for the three proposed methods. The MODWT-MRA had the highest performance, with an average time of 4.92 ms.
Handling Missing Observations with an RNN-based Prediction-Update Cycle
Mar 22, 2021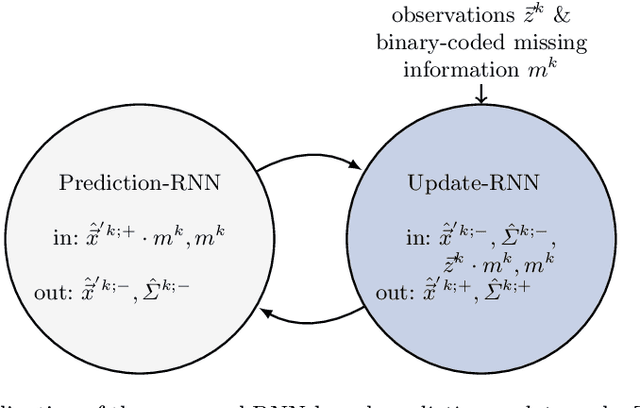
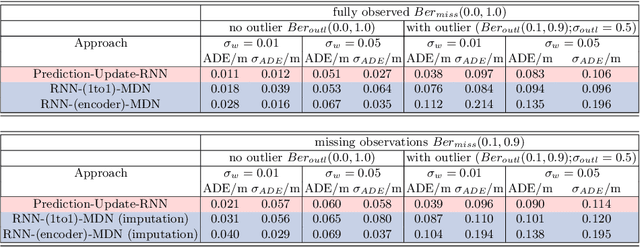
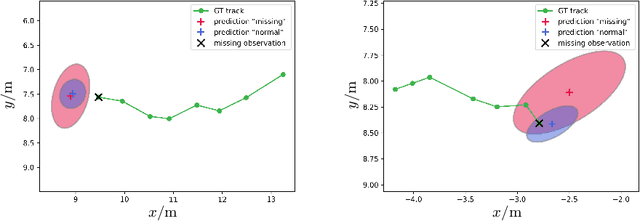
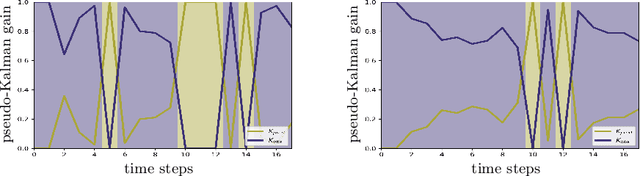
In tasks such as tracking, time-series data inevitably carry missing observations. While traditional tracking approaches can handle missing observations, recurrent neural networks (RNNs) are designed to receive input data in every step. Furthermore, current solutions for RNNs, like omitting the missing data or data imputation, are not sufficient to account for the resulting increased uncertainty. Towards this end, this paper introduces an RNN-based approach that provides a full temporal filtering cycle for motion state estimation. The Kalman filter inspired approach, enables to deal with missing observations and outliers. For providing a full temporal filtering cycle, a basic RNN is extended to take observations and the associated belief about its accuracy into account for updating the current state. An RNN prediction model, which generates a parametrized distribution to capture the predicted states, is combined with an RNN update model, which relies on the prediction model output and the current observation. By providing the model with masking information, binary-encoded missing events, the model can overcome limitations of standard techniques for dealing with missing input values. The model abilities are demonstrated on synthetic data reflecting prototypical pedestrian tracking scenarios.
EC-SAGINs: Edge Computing-enhanced Space-Air-Ground Integrated Networks for Internet of Vehicles
Jan 15, 2021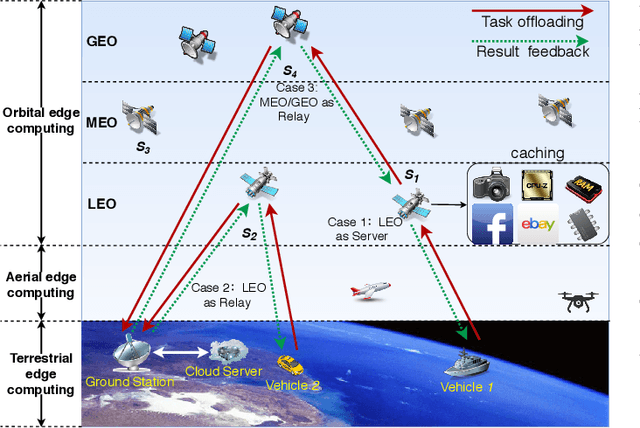
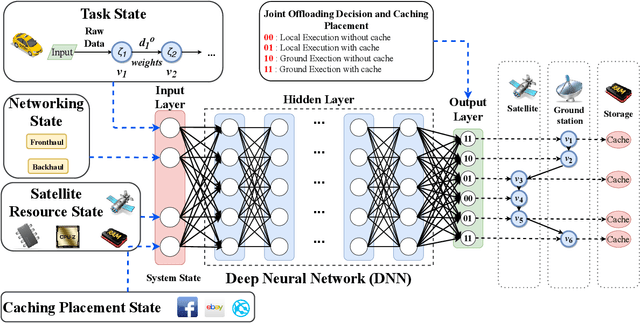
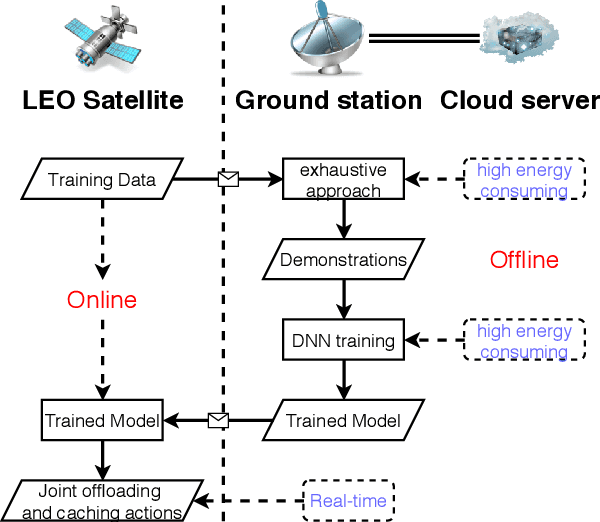
Edge computing-enhanced Internet of Vehicles (EC-IoV) enables ubiquitous data processing and content sharing among vehicles and terrestrial edge computing (TEC) infrastructures (e.g., 5G base stations and roadside units) with little or no human intervention, plays a key role in the intelligent transportation systems. However, EC-IoV is heavily dependent on the connections and interactions between vehicles and TEC infrastructures, thus will break down in some remote areas where TEC infrastructures are unavailable (e.g., desert, isolated islands and disaster-stricken areas). Driven by the ubiquitous connections and global-area coverage, space-air-ground integrated networks (SAGINs) efficiently support seamless coverage and efficient resource management, represent the next frontier for edge computing. In light of this, we first review the state-of-the-art edge computing research for SAGINs in this article. After discussing several existing orbital and aerial edge computing architectures, we propose a framework of edge computing-enabled space-air-ground integrated networks (EC-SAGINs) to support various IoV services for the vehicles in remote areas. The main objective of the framework is to minimize the task completion time and satellite resource usage. To this end, a pre-classification scheme is presented to reduce the size of action space, and a deep imitation learning (DIL) driven offloading and caching algorithm is proposed to achieve real-time decision making. Simulation results show the effectiveness of our proposed scheme. At last, we also discuss some technology challenges and future directions.
Tensor-Free Second-Order Differential Dynamic Programming
Mar 04, 2021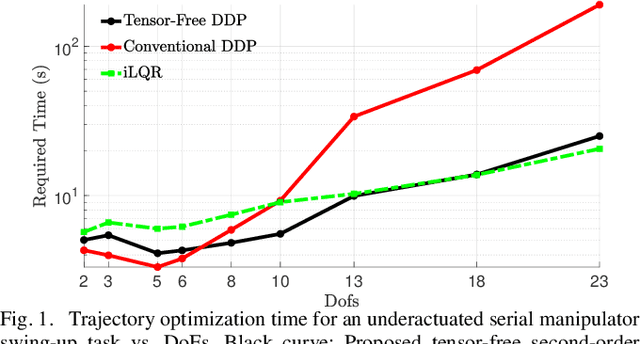
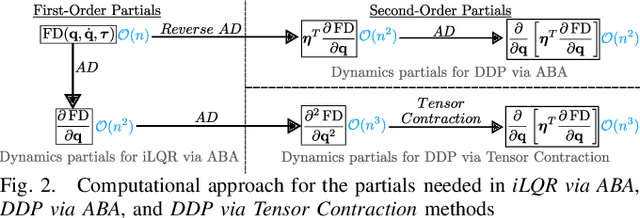
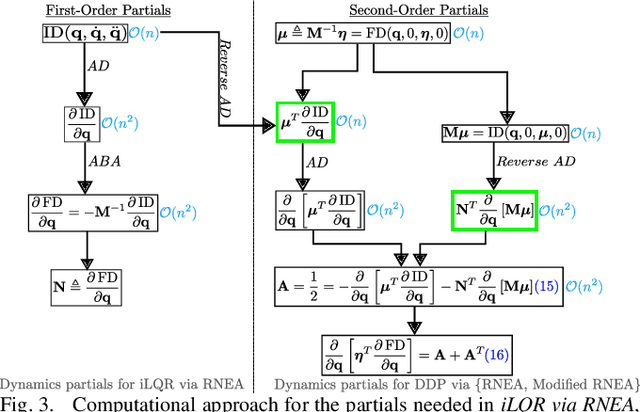
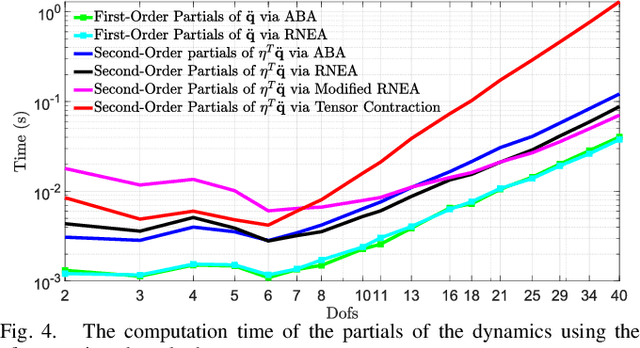
This paper presents a method to reduce the computational complexity of including second-order dynamics sensitivity information into the Differential Dynamic Programming (DDP) trajectory optimization algorithm. A tensor-free approach to DDP is developed where all the necessary derivatives are computed with the same complexity as in the iterative Linear Quadratic Regulator~(iLQR). Compared to linearized models used in iLQR, DDP more accurately represents the dynamics locally, but it is not often used since the second-order derivatives of the dynamics are tensorial and expensive to compute. This work shows how to avoid the need for computing the derivative tensor by instead leveraging reverse-mode accumulation of derivative information to compute a key vector-tensor product directly. We benchmark this approach for trajectory optimization with multi-link manipulators and show that the benefits of DDP can often be included without sacrificing evaluation time, and can be done in fewer iterations than iLQR.
Plot-guided Adversarial Example Construction for Evaluating Open-domain Story Generation
Apr 12, 2021
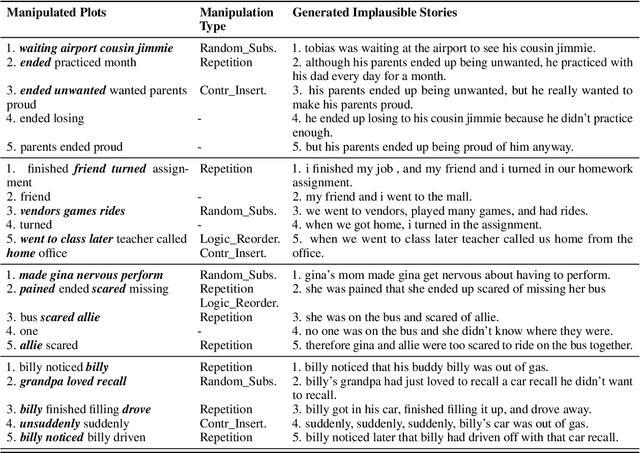
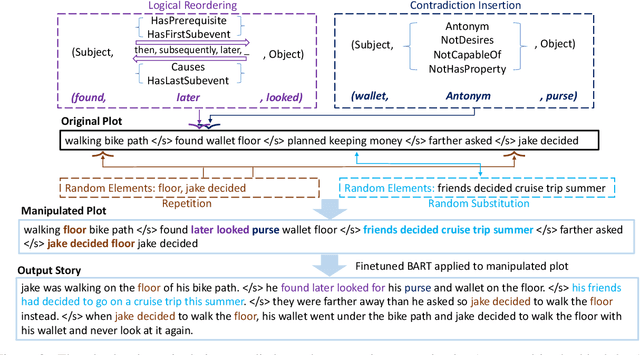
With the recent advances of open-domain story generation, the lack of reliable automatic evaluation metrics becomes an increasingly imperative issue that hinders the fast development of story generation. According to conducted researches in this regard, learnable evaluation metrics have promised more accurate assessments by having higher correlations with human judgments. A critical bottleneck of obtaining a reliable learnable evaluation metric is the lack of high-quality training data for classifiers to efficiently distinguish plausible and implausible machine-generated stories. Previous works relied on \textit{heuristically manipulated} plausible examples to mimic possible system drawbacks such as repetition, contradiction, or irrelevant content in the text level, which can be \textit{unnatural} and \textit{oversimplify} the characteristics of implausible machine-generated stories. We propose to tackle these issues by generating a more comprehensive set of implausible stories using {\em plots}, which are structured representations of controllable factors used to generate stories. Since these plots are compact and structured, it is easier to manipulate them to generate text with targeted undesirable properties, while at the same time maintain the grammatical correctness and naturalness of the generated sentences. To improve the quality of generated implausible stories, we further apply the adversarial filtering procedure presented by \citet{zellers2018swag} to select a more nuanced set of implausible texts. Experiments show that the evaluation metrics trained on our generated data result in more reliable automatic assessments that correlate remarkably better with human judgments compared to the baselines.
Fast and Robust Localization of Surgical Array using Kalman Filter
Dec 22, 2020
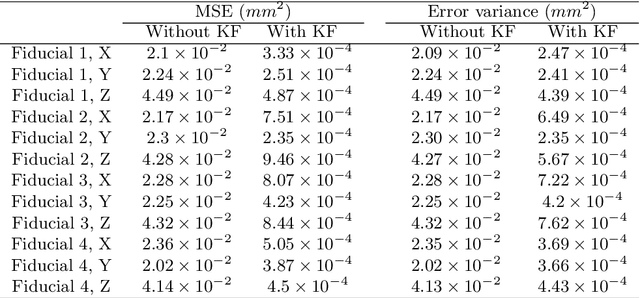
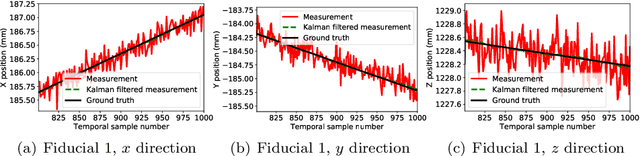
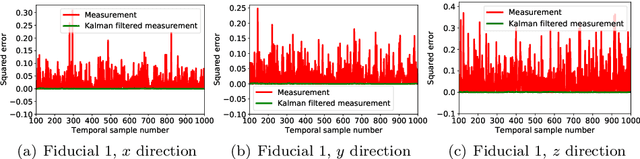
Intraoperative tracking of surgical instruments is an inevitable task of computer-assisted surgery. An optical tracking system often fails to precisely reconstruct the dynamic location and pose of a surgical tool due to the acquisition noise and measurement variance. Embedding a Kalman Filter (KF) or any of its extensions such as extended and unscented Kalman filters with the optical tracker resolves this issue by reducing the estimation variance and regularizing the temporal behavior. However, the current rigid-body KF implementations are computationally burdensome and hence, takes long execution time which hinders real-time surgical tracking. This paper introduces a fast and computationally efficient implementation of linear KF to improve the measurement accuracy of an optical tracking system with high temporal resolution. Instead of the surgical tool as a whole, our KF framework tracks each individual fiducial mounted on it using a Newtonian model. In addition to simulated dataset, we validate our technique against real data obtained from a high frame-rate commercial optical tracking system. The proposed KF framework substantially stabilizes the tracking behavior in all of our experiments and reduces the mean-squared error (MSE) from the order of $10^{-2}$ $mm^{2}$ to $10^{-4}$ $mm^{2}$.
Towards Extremely Compact RNNs for Video Recognition with Fully Decomposed Hierarchical Tucker Structure
Apr 12, 2021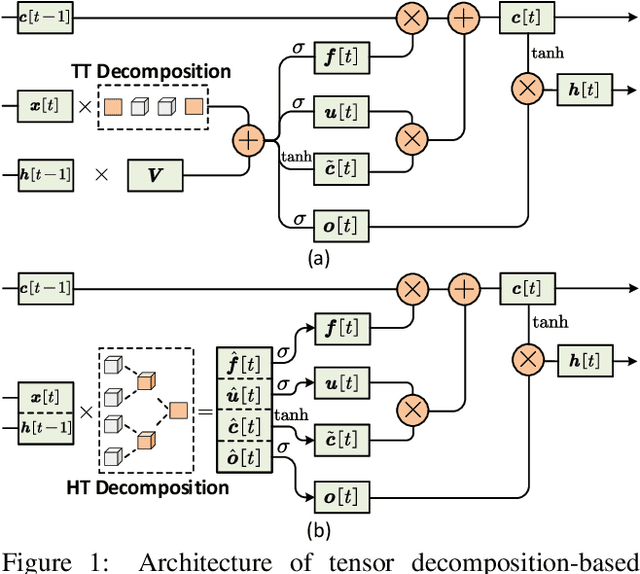
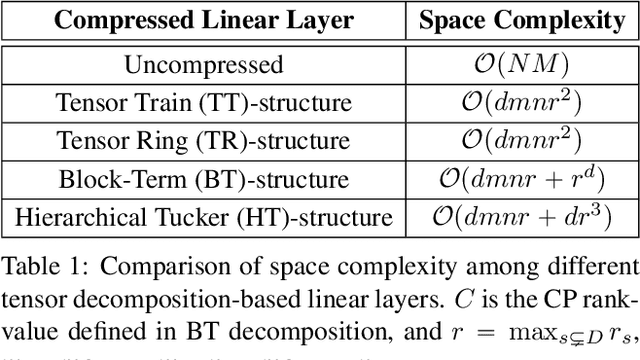
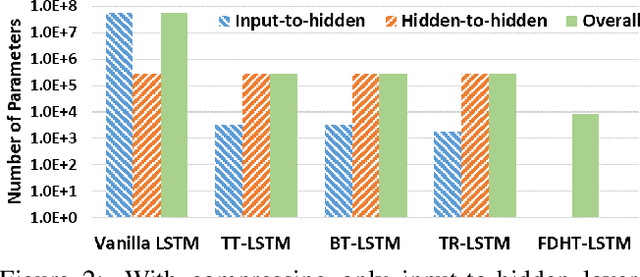
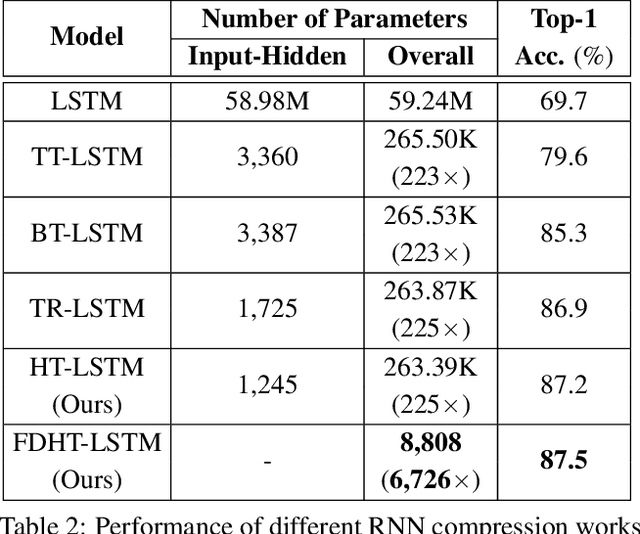
Recurrent Neural Networks (RNNs) have been widely used in sequence analysis and modeling. However, when processing high-dimensional data, RNNs typically require very large model sizes, thereby bringing a series of deployment challenges. Although various prior works have been proposed to reduce the RNN model sizes, executing RNN models in resource-restricted environments is still a very challenging problem. In this paper, we propose to develop extremely compact RNN models with fully decomposed hierarchical Tucker (FDHT) structure. The HT decomposition does not only provide much higher storage cost reduction than the other tensor decomposition approaches but also brings better accuracy performance improvement for the compact RNN models. Meanwhile, unlike the existing tensor decomposition-based methods that can only decompose the input-to-hidden layer of RNNs, our proposed fully decomposition approach enables the comprehensive compression for the entire RNN models with maintaining very high accuracy. Our experimental results on several popular video recognition datasets show that our proposed fully decomposed hierarchical tucker-based LSTM (FDHT-LSTM) is extremely compact and highly efficient. To the best of our knowledge, FDHT-LSTM, for the first time, consistently achieves very high accuracy with only few thousand parameters (3,132 to 8,808) on different datasets. Compared with the state-of-the-art compressed RNN models, such as TT-LSTM, TR-LSTM and BT-LSTM, our FDHT-LSTM simultaneously enjoys both order-of-magnitude (3,985x to 10,711x) fewer parameters and significant accuracy improvement (0.6% to 12.7%).
Efficient Spatialtemporal Context Modeling for Action Recognition
Apr 06, 2021
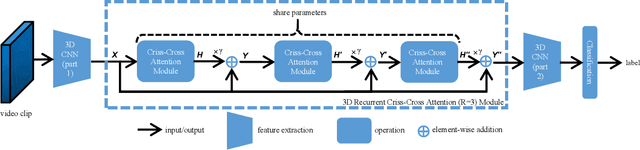
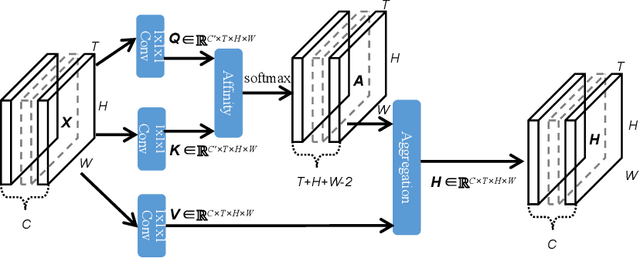
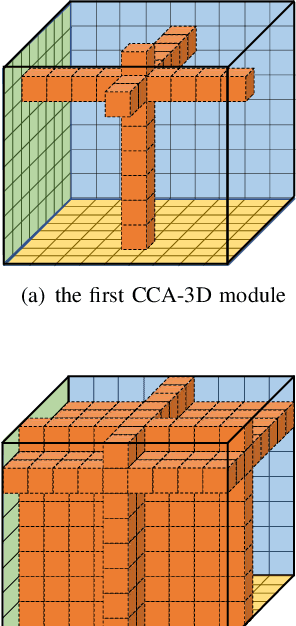
Contextual information plays an important role in action recognition. Local operations have difficulty to model the relation between two elements with a long-distance interval. However, directly modeling the contextual information between any two points brings huge cost in computation and memory, especially for action recognition, where there is an additional temporal dimension. Inspired from 2D criss-cross attention used in segmentation task, we propose a recurrent 3D criss-cross attention (RCCA-3D) module to model the dense long-range spatiotemporal contextual information in video for action recognition. The global context is factorized into sparse relation maps. We model the relationship between points in the same line along the direction of horizon, vertical and depth at each time, which forms a 3D criss-cross structure, and duplicate the same operation with recurrent mechanism to transmit the relation between points in a line to a plane finally to the whole spatiotemporal space. Compared with the non-local method, the proposed RCCA-3D module reduces the number of parameters and FLOPs by 25% and 30% for video context modeling. We evaluate the performance of RCCA-3D with two latest action recognition networks on three datasets and make a thorough analysis of the architecture, obtaining the optimal way to factorize and fuse the relation maps. Comparisons with other state-of-the-art methods demonstrate the effectiveness and efficiency of our model.
Real-time Cardiovascular MR with Spatio-temporal Artifact Suppression using Deep Learning - Proof of Concept in Congenital Heart Disease
Jun 14, 2018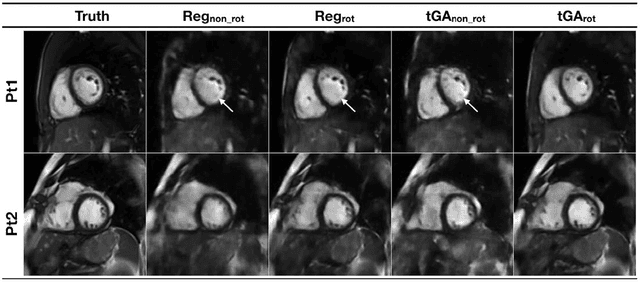
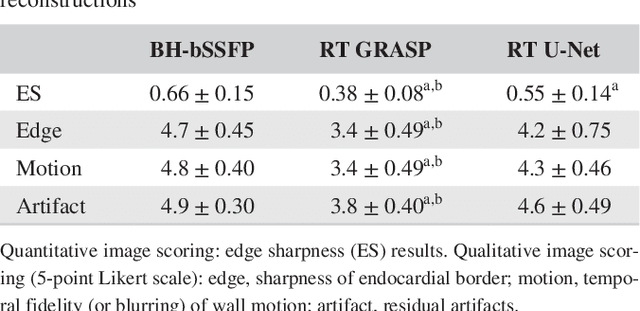
PURPOSE: Real-time assessment of ventricular volumes requires high acceleration factors. Residual convolutional neural networks (CNN) have shown potential for removing artifacts caused by data undersampling. In this study we investigated the effect of different radial sampling patterns on the accuracy of a CNN. We also acquired actual real-time undersampled radial data in patients with congenital heart disease (CHD), and compare CNN reconstruction to Compressed Sensing (CS). METHODS: A 3D (2D plus time) CNN architecture was developed, and trained using 2276 gold-standard paired 3D data sets, with 14x radial undersampling. Four sampling schemes were tested, using 169 previously unseen 3D 'synthetic' test data sets. Actual real-time tiny Golden Angle (tGA) radial SSFP data was acquired in 10 new patients (122 3D data sets), and reconstructed using the 3D CNN as well as a CS algorithm; GRASP. RESULTS: Sampling pattern was shown to be important for image quality, and accurate visualisation of cardiac structures. For actual real-time data, overall reconstruction time with CNN (including creation of aliased images) was shown to be more than 5x faster than GRASP. Additionally, CNN image quality and accuracy of biventricular volumes was observed to be superior to GRASP for the same raw data. CONCLUSION: This paper has demonstrated the potential for the use of a 3D CNN for deep de-aliasing of real-time radial data, within the clinical setting. Clinical measures of ventricular volumes using real-time data with CNN reconstruction are not statistically significantly different from the gold-standard, cardiac gated, BH techniques.