 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatiotemporal Data Mining: A Survey on Challenges and Open Problems
Mar 31, 2021
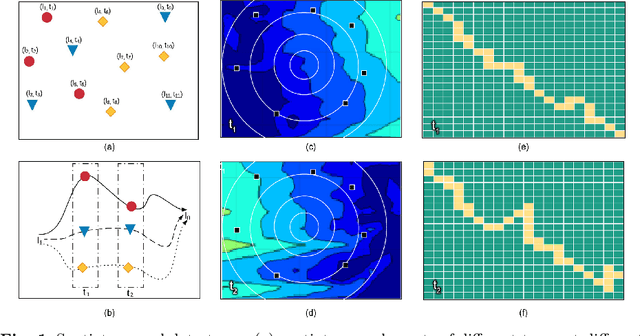
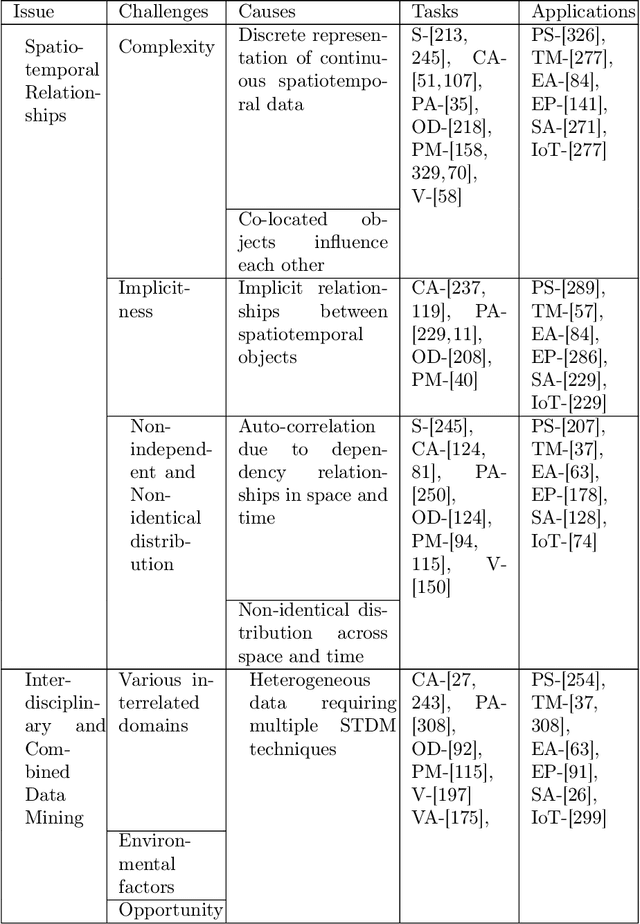
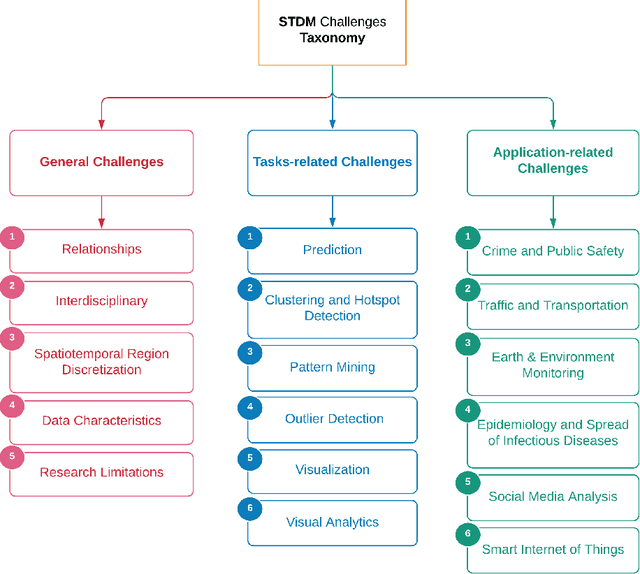
Spatiotemporal data mining (STDM) discovers useful patterns from the dynamic interplay between space and time. Several available surveys capture STDM advances and report a wealth of important progress in this field. However, STDM challenges and problems are not thoroughly discussed and presented in articles of their own. We attempt to fill this gap by providing a comprehensive literature survey on state-of-the-art advances in STDM. We describe the challenging issues and their causes and open gaps of multiple STDM directions and aspects. Specifically, we investigate the challenging issues in regards to spatiotemporal relationships, interdisciplinarity, discretisation, and data characteristics. Moreover, we discuss the limitations in the literature and open research problems related to spatiotemporal data representations, modelling and visualisation, and comprehensiveness of approaches. We explain issues related to STDM tasks of classification, clustering, hotspot detection, association and pattern mining, outlier detection, visualisation, visual analytics, and computer vision tasks. We also highlight STDM issues related to multiple applications including crime and public safety, traffic and transportation, earth and environment monitoring, epidemiology, social media, and Internet of Things.
Fast Regression of the Tritium Breeding Ratio in Fusion Reactors
Apr 08, 2021
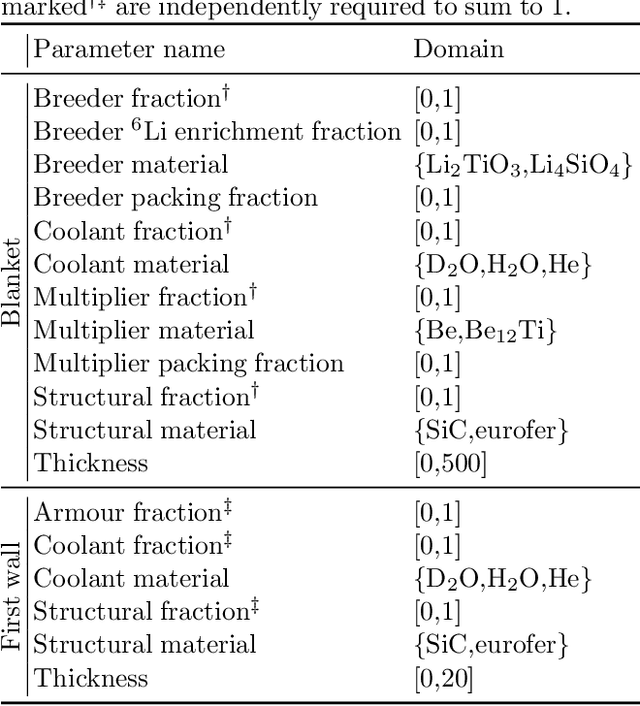
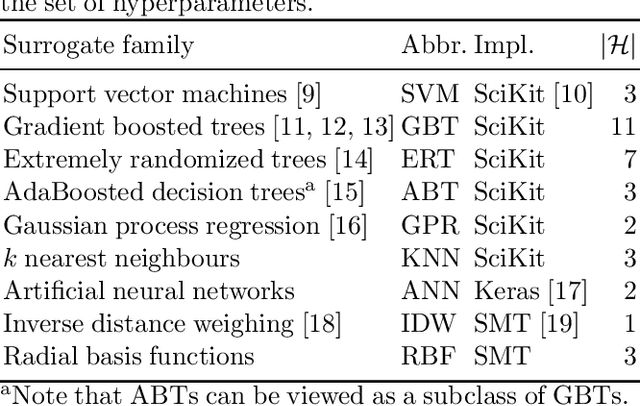
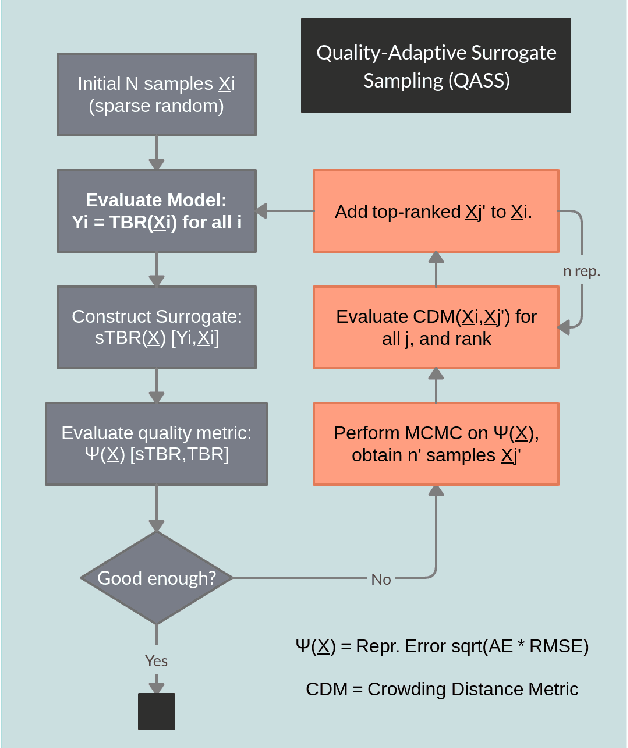
The tritium breeding ratio (TBR) is an essential quantity for the design of modern and next-generation D-T fueled nuclear fusion reactors. Representing the ratio between tritium fuel generated in breeding blankets and fuel consumed during reactor runtime, the TBR depends on reactor geometry and material properties in a complex manner. In this work, we explored the training of surrogate models to produce a cheap but high-quality approximation for a Monte Carlo TBR model in use at the UK Atomic Energy Authority. We investigated possibilities for dimensional reduction of its feature space, reviewed 9 families of surrogate models for potential applicability, and performed hyperparameter optimisation. Here we present the performance and scaling properties of these models, the fastest of which, an artificial neural network, demonstrated $R^2=0.985$ and a mean prediction time of $0.898\ \mu\mathrm{s}$, representing a relative speedup of $8\cdot 10^6$ with respect to the expensive MC model. We further present a novel adaptive sampling algorithm, Quality-Adaptive Surrogate Sampling, capable of interfacing with any of the individually studied surrogates. Our preliminary testing on a toy TBR theory has demonstrated the efficacy of this algorithm for accelerating the surrogate modelling process.
Spectral Unions of Partial Deformable 3D Shapes
Mar 31, 2021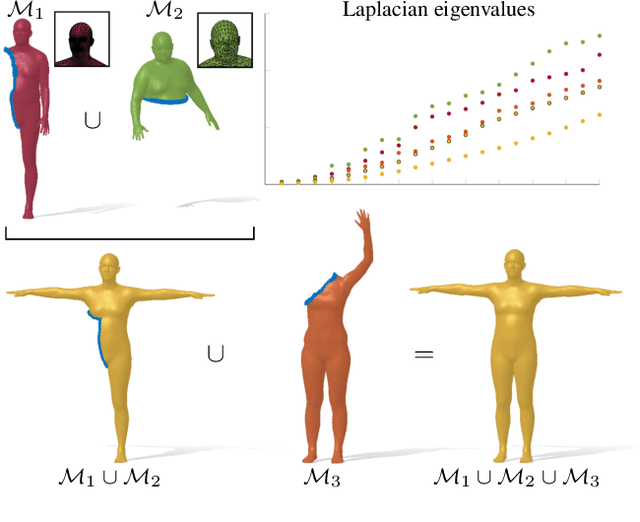

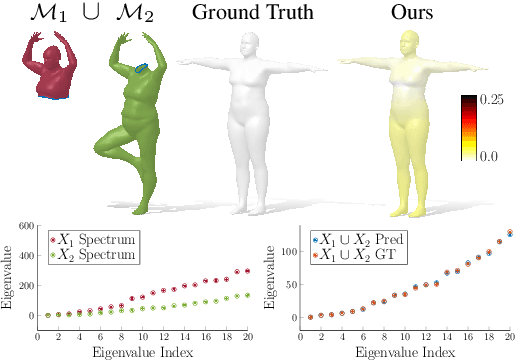
Spectral geometric methods have brought revolutionary changes to the field of geometry processing -- however, when the data to be processed exhibits severe partiality, such methods fail to generalize. As a result, there exists a big performance gap between methods dealing with complete shapes, and methods that address missing geometry. In this paper, we propose a possible way to fill this gap. We introduce the first method to compute compositions of non-rigidly deforming shapes, without requiring to solve first for a dense correspondence between the given partial shapes. We do so by operating in a purely spectral domain, where we define a union operation between short sequences of eigenvalues. Working with eigenvalues allows to deal with unknown correspondence, different sampling, and different discretization (point clouds and meshes alike), making this operation especially robust and general. Our approach is data-driven, and can generalize to isometric and non-isometric deformations of the surface, as long as these stay within the same semantic class (e.g., human bodies), as well as to partiality artifacts not seen at training time.
Mixed Policy Gradient
Feb 23, 2021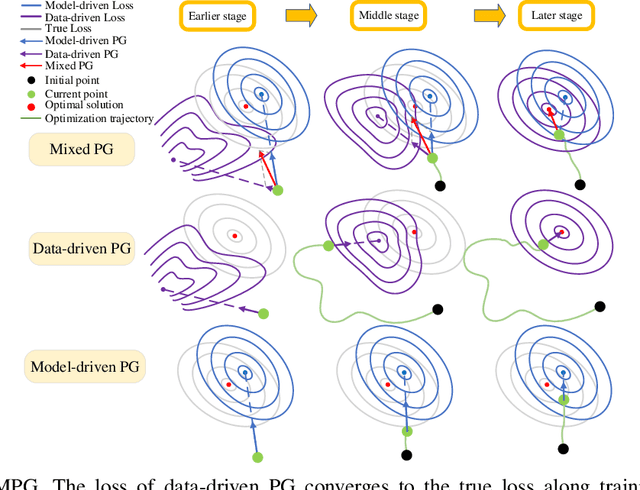
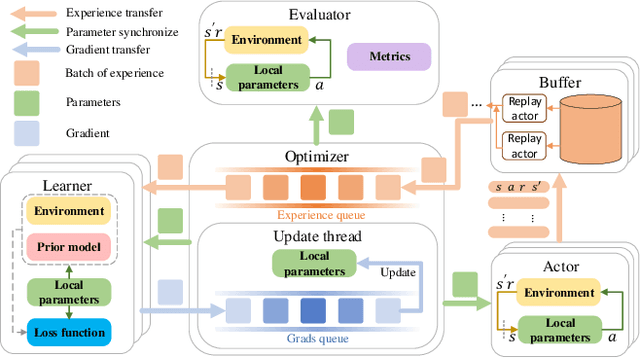
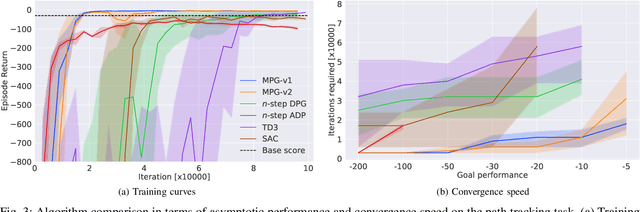
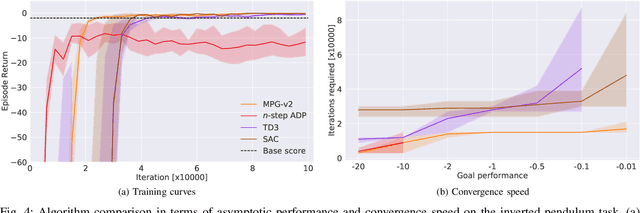
Reinforcement learning (RL) has great potential in sequential decision-making. At present, the mainstream RL algorithms are data-driven, relying on millions of iterations and a large number of empirical data to learn a policy. Although data-driven RL may have excellent asymptotic performance, it usually yields slow convergence speed. As a comparison, model-driven RL employs a differentiable transition model to improve convergence speed, in which the policy gradient (PG) is calculated by using the backpropagation through time (BPTT) technique. However, such methods suffer from numerical instability, model error sensitivity and low computing efficiency, which may lead to poor policies. In this paper, a mixed policy gradient (MPG) method is proposed, which uses both empirical data and the transition model to construct the PG, so as to accelerate the convergence speed without losing the optimality guarantee. MPG contains two types of PG: 1) data-driven PG, which is obtained by directly calculating the derivative of the learned Q-value function with respect to actions, and 2) model-driven PG, which is calculated using BPTT based on the model-predictive return. We unify them by revealing the correlation between the upper bound of the unified PG error and the predictive horizon, where the data-driven PG is regraded as 0-step model-predictive return. Relying on that, MPG employs a rule-based method to adaptively adjust the weights of data-driven and model-driven PGs. In particular, to get a more accurate PG, the weight of the data-driven PG is designed to grow along the learning process while the other to decrease. Besides, an asynchronous learning framework is proposed to reduce the wall-clock time needed for each update iteration. Simulation results show that the MPG method achieves the best asymptotic performance and convergence speed compared with other baseline algorithms.
Safe Exploration in Markov Decision Processes with Time-Variant Safety using Spatio-Temporal Gaussian Process
Sep 12, 2018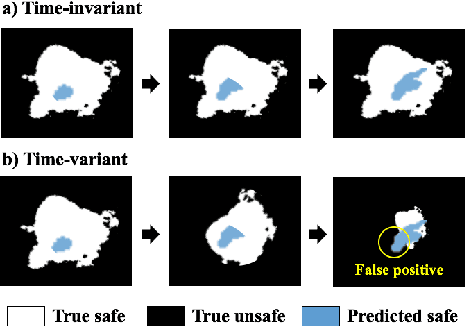

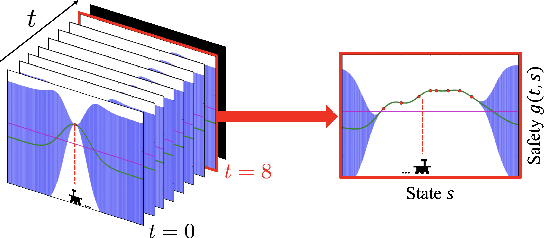

In many real-world applications (e.g., planetary exploration, robot navigation), an autonomous agent must be able to explore a space with guaranteed safety. Most safe exploration algorithms in the field of reinforcement learning and robotics have been based on the assumption that the safety features are a priori known and time-invariant. This paper presents a learning algorithm called ST-SafeMDP for exploring Markov decision processes (MDPs) that is based on the assumption that the safety features are a priori unknown and time-variant. In this setting, the agent explores MDPs while constraining the probability of entering unsafe states defined by a safety function being below a threshold. The unknown and time-variant safety values are modeled using a spatio-temporal Gaussian process. However, there remains an issue that an agent may have no viable action in a shrinking true safe space. To address this issue, we formulate a problem maximizing the cumulative number of safe states in the worst case scenario with respect to future observations. The effectiveness of this approach was demonstrated in two simulation settings, including one using real lunar terrain data.
Second-Order Stochastic Optimization for Machine Learning in Linear Time
Nov 30, 2017
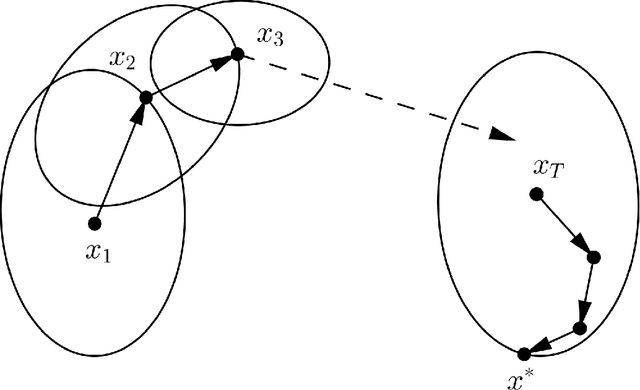
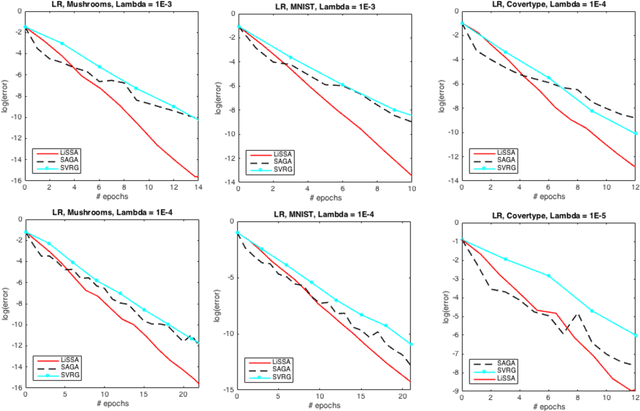

First-order stochastic methods are the state-of-the-art in large-scale machine learning optimization owing to efficient per-iteration complexity. Second-order methods, while able to provide faster convergence, have been much less explored due to the high cost of computing the second-order information. In this paper we develop second-order stochastic methods for optimization problems in machine learning that match the per-iteration cost of gradient based methods, and in certain settings improve upon the overall running time over popular first-order methods. Furthermore, our algorithm has the desirable property of being implementable in time linear in the sparsity of the input data.
Reinforcement Learning Control of a Biomechanical Model of the Upper Extremity
Nov 13, 2020
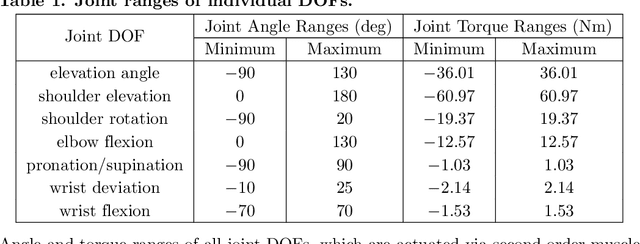
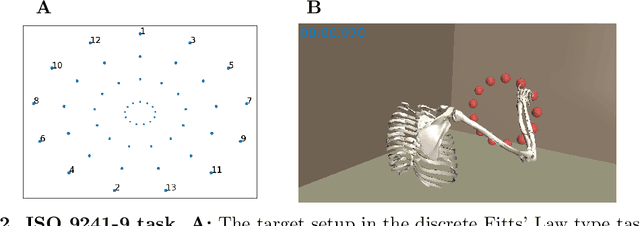
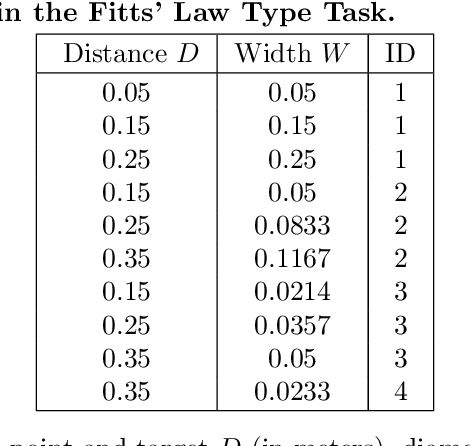
We address the question whether the assumptions of signal-dependent and constant motor noise in a full skeletal model of the human upper extremity, together with the objective of movement time minimization, can predict reaching movements. We learn a control policy using a motor babbling approach based on reinforcement learning, using aimed movements of the tip of the right index finger towards randomly placed 3D targets of varying size. The reward signal is the negative time to reach the target, implying movement time minimization. Our biomechanical model of the upper extremity uses the skeletal structure of the Upper Extremity Dynamic Model, including thorax, right shoulder, arm, and hand. The model has 7 actuated degrees of freedom, including shoulder rotation, elevation and elevation plane, elbow flexion, forearm rotation, and wrist flexion and deviation. To deal with the curse of dimensionality, we use a simplified second-order muscle model acting at each joint instead of individual muscles. We address the lack of gradient provided by the simple reward function through an adaptive learning curriculum. Our results demonstrate that the assumptions of signal-dependent and constant motor noise, together with the objective of movement time minimization, are sufficient for a state-of-the-art skeletal model of the human upper extremity to reproduce complex phenomena of human movement such as Fitts' Law and the 2/3 Power Law. This result supports the idea that the control of the complex human biomechanical system is plausible to be determined by a set of simple assumptions and can be easily learned.
Parallelized Instantaneous Velocity and Heading Estimation of Objects using Single Imaging Radar
Dec 23, 2020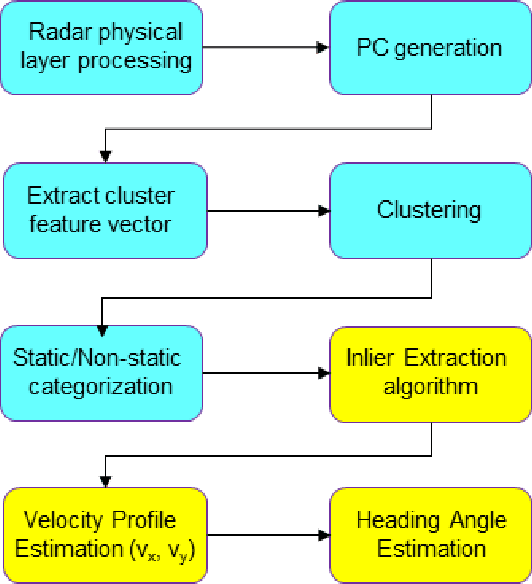

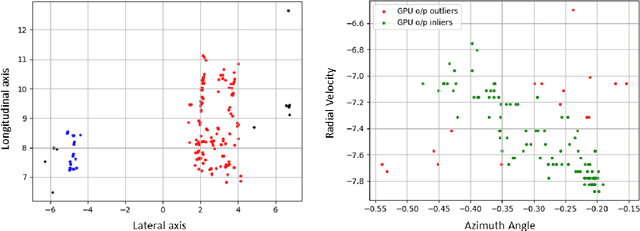

The development of high-resolution imaging radars introduce a plethora of useful applications, particularly in the automotive sector. With increasing attention on active transport safety and autonomous driving, these imaging radars are set to form the core of an autonomous engine. One of the most important tasks of such high-resolution radars is to estimate the instantaneous velocities and heading angles of the detected objects (vehicles, pedestrians, etc.). Feasible estimation methods should be fast enough in real-time scenarios, bias-free and robust against micro-Dopplers, noise and other systemic variations. This work proposes a parallel-computing scheme that achieves a real-time and accurate implementation of vector velocity determination using frequency modulated continuous wave (FMCW) radars. The proposed scheme is tested against traffic data collected using an FMCW radar at a center frequency of 78.6 GHz and a bandwidth of 4 GHz. Experiments show that the parallel algorithm presented performs much faster than its conventional counterparts without any loss in precision.
Channel Estimation via Successive Denoising in MIMO OFDM Systems: A Reinforcement Learning Approach
Jan 27, 2021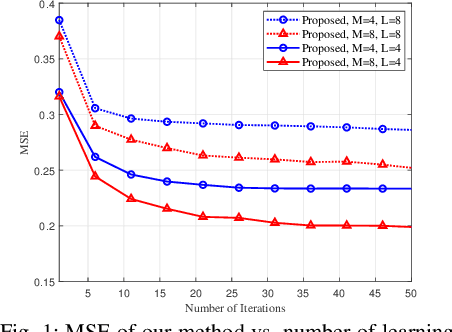
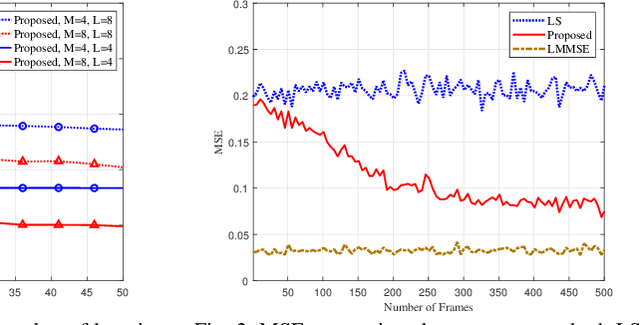
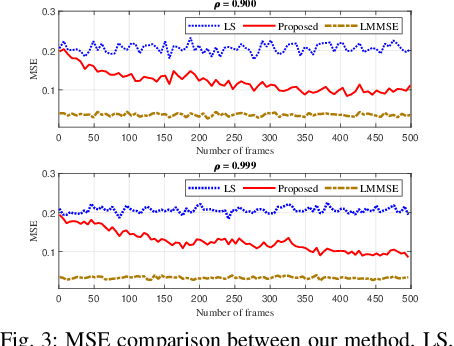
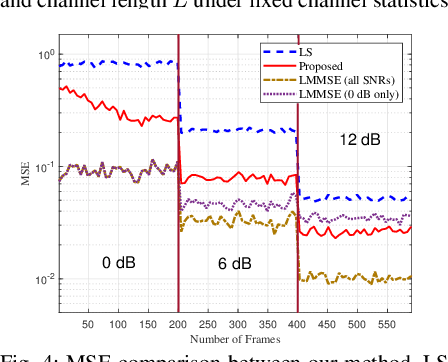
Reliable communication through multiple-input multiple-output (MIMO) orthogonal frequency division multiplexing (OFDM) requires accurate channel estimation. Existing literature largely focuses on denoising methods for channel estimation that are dependent on either (i) channel analysis in the time-domain, and/or (ii) supervised learning techniques, requiring large pre-labeled datasets for training. To address these limitations, we present a frequency-domain denoising method based on the application of a reinforcement learning framework that does not need a priori channel knowledge and pre-labeled data. Our methodology includes a new successive channel denoising process based on channel curvature computation, for which we obtain a channel curvature magnitude threshold to identify unreliable channel estimates. Based on this process, we formulate the denoising mechanism as a Markov decision process, where we define the actions through a geometry-based channel estimation update, and the reward function based on a policy that reduces the MSE. We then resort to Q-learning to update the channel estimates over the time instances. Numerical results verify that our denoising algorithm can successfully mitigate noise in channel estimates. In particular, our algorithm provides a significant improvement over the practical least squares (LS) channel estimation method and provides performance that approaches that of the ideal linear minimum mean square error (LMMSE) with perfect knowledge of channel statistics.
UPANets: Learning from the Universal Pixel Attention Networks
Mar 22, 2021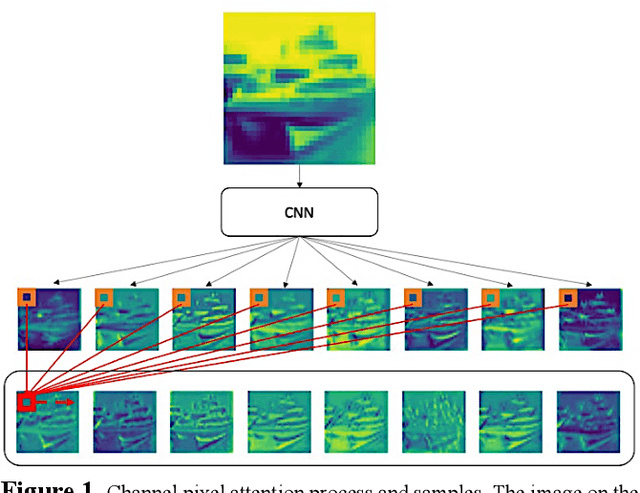
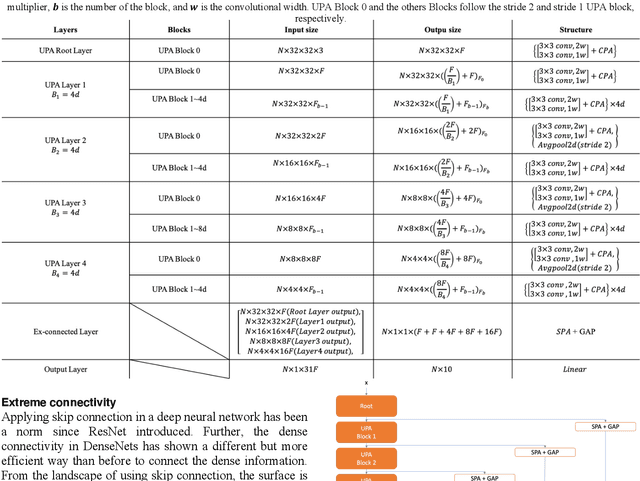
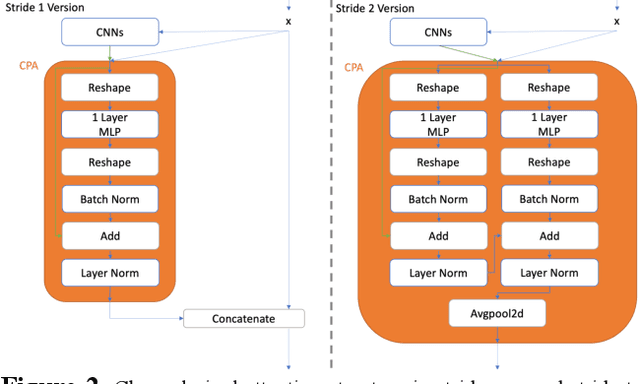
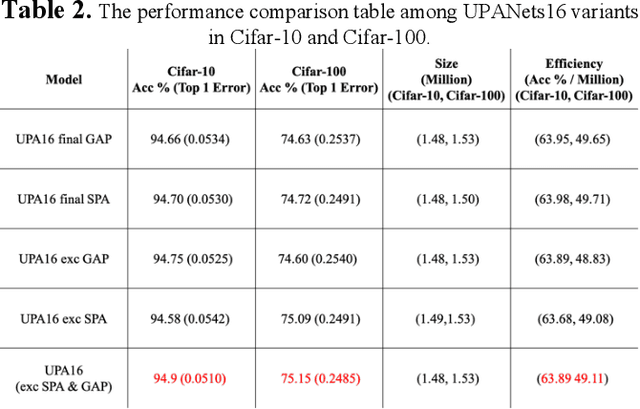
Among image classification, skip and densely-connection-based networks have dominated most leaderboards. Recently, from the successful development of multi-head attention in natural language processing, it is sure that now is a time of either using a Transformer-like model or hybrid CNNs with attention. However, the former need a tremendous resource to train, and the latter is in the perfect balance in this direction. In this work, to make CNNs handle global and local information, we proposed UPANets, which equips channel-wise attention with a hybrid skip-densely-connection structure. Also, the extreme-connection structure makes UPANets robust with a smoother loss landscape. In experiments, UPANets surpassed most well-known and widely-used SOTAs with an accuracy of 96.47% in Cifar-10, 80.29% in Cifar-100, and 67.67% in Tiny Imagenet. Most importantly, these performances have high parameters efficiency and only trained in one customer-based GPU. We share implementing code of UPANets in https://github.com/hanktseng131415go/UPANets.