 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Guided Autoencoder Fusion for Insulator Defect Detection Using UAV Transmission-Line Imaging
Jun 03, 2026Automated defect detection in high-voltage transmission-line insulators remains challenging due to severe class imbalance, large scale variation, and the small spatial extent of defect instances in Unmanned Aerial Vehicle (UAV) imagery. To address these challenges, this paper proposes AE-YOLO, an Attention-Guided AutoEncoder-Enhanced YOLO framework for robust insulator defect detection. The architecture integrates lightweight bottleneck autoencoders within a Feature Pyramid Network-Path Aggregation Network (FPN-PAN) neck. This preserves anomaly-sensitive information during multi-scale feature fusion. Convolutional Block Attention Modules (CBAM) are used throughout the backbone, enhancing feature discrimination and suppressing background interference. The framework also introduces a variance-maximizing autoencoder regularization strategy, which encourages diverse, defect-discriminative latent representations. The network trains using a unified objective that combines focal loss, Complete IoU (CIoU) loss, and autoencoder regularization to address foreground-background imbalance and improve localization accuracy. During inference, Weighted Boxes Fusion (WBF) combines predictions from YOLOv8, YOLOv10, and YOLO11. An autoencoder-guided confidence boosting mechanism improves sensitivity to rare defect categories. Experiments on the Insulator-Defect Detection dataset show that AE-YOLO with an EfficientNetV2 backbone achieves 95.10 percent mAP at 0.5, 96.40 percent precision, and 93.80 percent recall. This performance surpasses the strongest YOLO-family baseline by 5.0 points in mAP at 0.5 and 6.7 points in recall. These results confirm the effectiveness and adaptability of the framework. The model is a practical and scalable solution for UAV-based transmission-line inspection and defect monitoring.
CAMO: A Class-Aware Minority-Optimized Ensemble for Robust Language Model Evaluation on Imbalanced Data
Apr 08, 2026Real-world categorization is severely hampered by class imbalance because traditional ensembles favor majority classes, which lowers minority performance and overall F1-score. We provide a unique ensemble technique for imbalanced problems called CAMO (Class-Aware Minority-Optimized).Through a hierarchical procedure that incorporates vote distributions, confidence calibration, and inter model uncertainty, CAMO dynamically boosts underrepresented classes while preserving and amplifying minority forecasts. We verify CAMO on two highly unbalanced, domain-specific benchmarks: the DIAR-AI/Emotion dataset and the ternary BEA 2025 dataset. We benchmark against seven proven ensemble algorithms using eight different language models (three LLMs and five SLMs) under zero-shot and fine-tuned settings .With refined models, CAMO consistently earns the greatest strict macro F1-score, setting a new benchmark. Its benefit works in concert with model adaptation, showing that the best ensemble choice depends on model properties .This proves that CAMO is a reliable, domain-neutral framework for unbalanced categorization.
Enhancing Mental Health Classification with Layer-Attentive Residuals and Contrastive Feature Learning
Mar 14, 2026The classification of mental health is challenging for a variety of reasons. For one, there is overlap between the mental health issues. In addition, the signs of mental health issues depend on the context of the situation, making classification difficult. Although fine-tuning transformers has improved the performance for mental health classification, standard cross-entropy training tends to create entangled feature spaces and fails to utilize all the information the transformers contain. We present a new framework that focuses on representations to improve mental health classification. This is done using two methods. First, \textbf{layer-attentive residual aggregation} which works on residual connections to to weigh and fuse representations from all transformer layers while maintaining high-level semantics. Second, \textbf{supervised contrastive feature learning} uses temperature-scaled supervised contrastive learning with progressive weighting to increase the geometric margin between confusable mental health problems and decrease class overlap by restructuring the feature space. With a score of \textbf{74.36\%}, the proposed method is the best performing on the SWMH benchmark and outperforms models that are domain-specialized, such as \textit{MentalBERT} and \textit{MentalRoBERTa} by margins of (3.25\% - 2.2\%) and 2.41 recall points over the highest achieving model. These findings show that domain-adaptive pretraining for mental health text classification can be surpassed by carefully designed representation geometry and layer-aware residual integration, which also provide enhanced interpretability through learnt layer importance.
CMHL: Contrastive Multi-Head Learning for Emotionally Consistent Text Classification
Mar 14, 2026Textual Emotion Classification (TEC) is one of the most difficult NLP tasks. State of the art approaches rely on Large language models (LLMs) and multi-model ensembles. In this study, we challenge the assumption that larger scale or more complex models are necessary for improved performance. In order to improve logical consistency, We introduce CMHL, a novel single-model architecture that explicitly models the logical structure of emotions through three key innovations: (1) multi-task learning that jointly predicts primary emotions, valence, and intensity, (2) psychologically-grounded auxiliary supervision derived from Russell's circumplex model, and (3) a novel contrastive contradiction loss that enforces emotional consistency by penalizing mutually incompatible predictions (e.g., simultaneous high confidence in joy and anger). With just 125M parameters, our model outperforms 56x larger LLMs and sLM ensembles with a new state-of-the-art F1 score of 93.75\% compared to (86.13\%-93.2\%) on the dair-ai Emotion dataset. We further show cross domain generalization on the Reddit Suicide Watch and Mental Health Collection dataset (SWMH), outperforming domain-specific models like MentalBERT and MentalRoBERTa with an F1 score of 72.50\% compared to (68.16\%-72.16\%) + a 73.30\% recall compared to (67.05\%-70.89\%) that translates to enhanced sensitivity for detecting mental health distress. Our work establishes that architectural intelligence (not parameter count) drives progress in TEC. By embedding psychological priors and explicit consistency constraints, a well-designed single model can outperform both massive LLMs and complex ensembles, offering a efficient, interpretable, and clinically-relevant paradigm for affective computing.
Weather-Aware Transformer for Real-Time Route Optimization in Drone-as-a-Service Operations
Jan 06, 2026This paper presents a novel framework to accelerate route prediction in Drone-as-a-Service operations through weather-aware deep learning models. While classical path-planning algorithms, such as A* and Dijkstra, provide optimal solutions, their computational complexity limits real-time applicability in dynamic environments. We address this limitation by training machine learning and deep learning models on synthetic datasets generated from classical algorithm simulations. Our approach incorporates transformer-based and attention-based architectures that utilize weather heuristics to predict optimal next-node selections while accounting for meteorological conditions affecting drone operations. The attention mechanisms dynamically weight environmental factors including wind patterns, wind bearing, and temperature to enhance routing decisions under adverse weather conditions. Experimental results demonstrate that our weather-aware models achieve significant computational speedup over traditional algorithms while maintaining route optimization performance, with transformer-based architectures showing superior adaptation to dynamic environmental constraints. The proposed framework enables real-time, weather-responsive route optimization for large-scale DaaS operations, representing a substantial advancement in the efficiency and safety of autonomous drone systems.
MultiFuzz: A Dense Retrieval-based Multi-Agent System for Network Protocol Fuzzing
Aug 19, 2025



Traditional protocol fuzzing techniques, such as those employed by AFL-based systems, often lack effectiveness due to a limited semantic understanding of complex protocol grammars and rigid seed mutation strategies. Recent works, such as ChatAFL, have integrated Large Language Models (LLMs) to guide protocol fuzzing and address these limitations, pushing protocol fuzzers to wider exploration of the protocol state space. But ChatAFL still faces issues like unreliable output, LLM hallucinations, and assumptions of LLM knowledge about protocol specifications. This paper introduces MultiFuzz, a novel dense retrieval-based multi-agent system designed to overcome these limitations by integrating semantic-aware context retrieval, specialized agents, and structured tool-assisted reasoning. MultiFuzz utilizes agentic chunks of protocol documentation (RFC Documents) to build embeddings in a vector database for a retrieval-augmented generation (RAG) pipeline, enabling agents to generate more reliable and structured outputs, enhancing the fuzzer in mutating protocol messages with enhanced state coverage and adherence to syntactic constraints. The framework decomposes the fuzzing process into modular groups of agents that collaborate through chain-of-thought reasoning to dynamically adapt fuzzing strategies based on the retrieved contextual knowledge. Experimental evaluations on the Real-Time Streaming Protocol (RTSP) demonstrate that MultiFuzz significantly improves branch coverage and explores deeper protocol states and transitions over state-of-the-art (SOTA) fuzzers such as NSFuzz, AFLNet, and ChatAFL. By combining dense retrieval, agentic coordination, and language model reasoning, MultiFuzz establishes a new paradigm in autonomous protocol fuzzing, offering a scalable and extensible foundation for future research in intelligent agentic-based fuzzing systems.
Two-Stage Quranic QA via Ensemble Retrieval and Instruction-Tuned Answer Extraction
Aug 09, 2025Quranic Question Answering presents unique challenges due to the linguistic complexity of Classical Arabic and the semantic richness of religious texts. In this paper, we propose a novel two-stage framework that addresses both passage retrieval and answer extraction. For passage retrieval, we ensemble fine-tuned Arabic language models to achieve superior ranking performance. For answer extraction, we employ instruction-tuned large language models with few-shot prompting to overcome the limitations of fine-tuning on small datasets. Our approach achieves state-of-the-art results on the Quran QA 2023 Shared Task, with a MAP@10 of 0.3128 and MRR@10 of 0.5763 for retrieval, and a pAP@10 of 0.669 for extraction, substantially outperforming previous methods. These results demonstrate that combining model ensembling and instruction-tuned language models effectively addresses the challenges of low-resource question answering in specialized domains.
ASEM: Enhancing Empathy in Chatbot through Attention-based Sentiment and Emotion Modeling
Feb 25, 2024



Effective feature representations play a critical role in enhancing the performance of text generation models that rely on deep neural networks. However, current approaches suffer from several drawbacks, such as the inability to capture the deep semantics of language and sensitivity to minor input variations, resulting in significant changes in the generated text. In this paper, we present a novel solution to these challenges by employing a mixture of experts, multiple encoders, to offer distinct perspectives on the emotional state of the user's utterance while simultaneously enhancing performance. We propose an end-to-end model architecture called ASEM that performs emotion analysis on top of sentiment analysis for open-domain chatbots, enabling the generation of empathetic responses that are fluent and relevant. In contrast to traditional attention mechanisms, the proposed model employs a specialized attention strategy that uniquely zeroes in on sentiment and emotion nuances within the user's utterance. This ensures the generation of context-rich representations tailored to the underlying emotional tone and sentiment intricacies of the text. Our approach outperforms existing methods for generating empathetic embeddings, providing empathetic and diverse responses. The performance of our proposed model significantly exceeds that of existing models, enhancing emotion detection accuracy by 6.2% and lexical diversity by 1.4%.
MARL: Multimodal Attentional Representation Learning for Disease Prediction
May 01, 2021
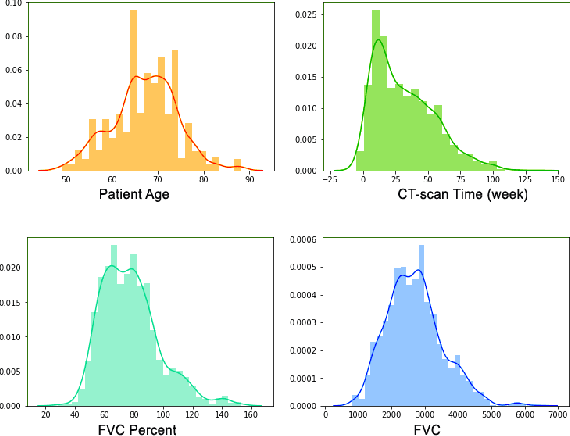

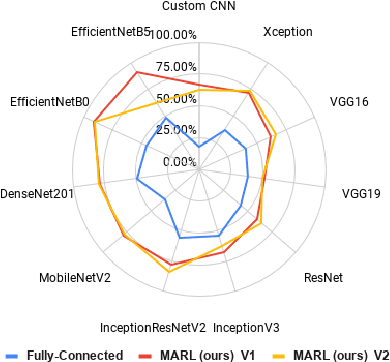
Existing learning models often utilise CT-scan images to predict lung diseases. These models are posed by high uncertainties that affect lung segmentation and visual feature learning. We introduce MARL, a novel Multimodal Attentional Representation Learning model architecture that learns useful features from multimodal data under uncertainty. We feed the proposed model with both the lung CT-scan images and their perspective historical patients' biological records collected over times. Such rich data offers to analyse both spatial and temporal aspects of the disease. MARL employs Fuzzy-based image spatial segmentation to overcome uncertainties in CT-scan images. We then utilise a pre-trained Convolutional Neural Network (CNN) to learn visual representation vectors from images. We augment patients' data with statistical features from the segmented images. We develop a Long Short-Term Memory (LSTM) network to represent the augmented data and learn sequential patterns of disease progressions. Finally, we inject both CNN and LSTM feature vectors to an attention layer to help focus on the best learning features. We evaluated MARL on regression of lung disease progression and status classification. MARL outperforms state-of-the-art CNN architectures, such as EfficientNet and DenseNet, and baseline prediction models. It achieves a 91% R^2 score, which is higher than the other models by a range of 8% to 27%. Also, MARL achieves 97% and 92% accuracy for binary and multi-class classification, respectively. MARL improves the accuracy of state-of-the-art CNN models with a range of 19% to 57%. The results show that combining spatial and sequential temporal features produces better discriminative feature.
Spatiotemporal Data Mining: A Survey on Challenges and Open Problems
Mar 31, 2021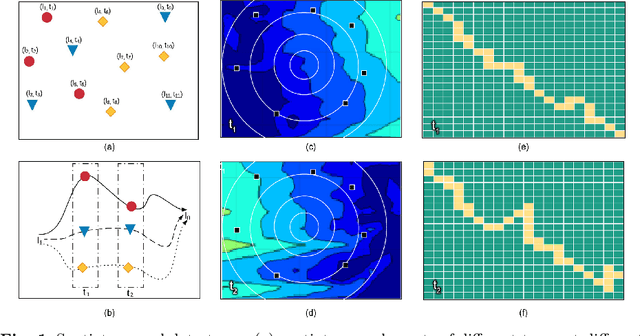
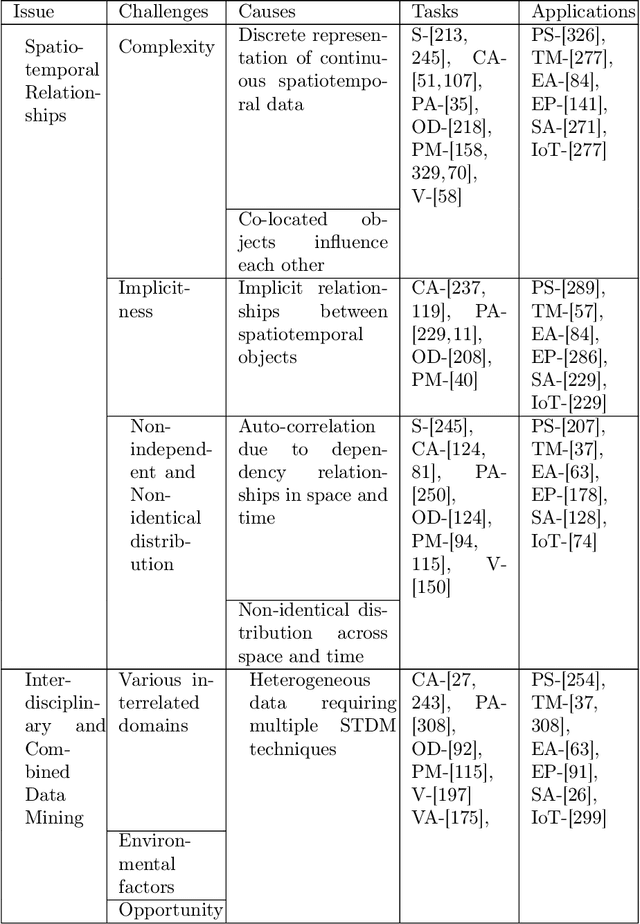
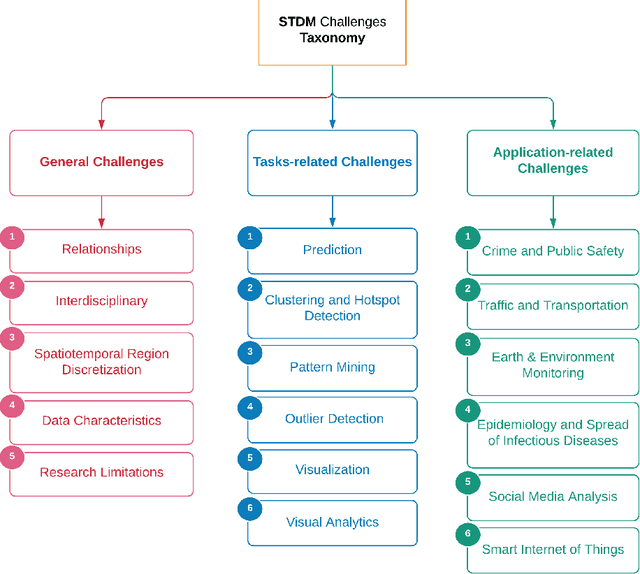
Spatiotemporal data mining (STDM) discovers useful patterns from the dynamic interplay between space and time. Several available surveys capture STDM advances and report a wealth of important progress in this field. However, STDM challenges and problems are not thoroughly discussed and presented in articles of their own. We attempt to fill this gap by providing a comprehensive literature survey on state-of-the-art advances in STDM. We describe the challenging issues and their causes and open gaps of multiple STDM directions and aspects. Specifically, we investigate the challenging issues in regards to spatiotemporal relationships, interdisciplinarity, discretisation, and data characteristics. Moreover, we discuss the limitations in the literature and open research problems related to spatiotemporal data representations, modelling and visualisation, and comprehensiveness of approaches. We explain issues related to STDM tasks of classification, clustering, hotspot detection, association and pattern mining, outlier detection, visualisation, visual analytics, and computer vision tasks. We also highlight STDM issues related to multiple applications including crime and public safety, traffic and transportation, earth and environment monitoring, epidemiology, social media, and Internet of Things.