 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Biologically inspired alternatives to backpropagation through time for learning in recurrent neural nets
Jan 25, 2019
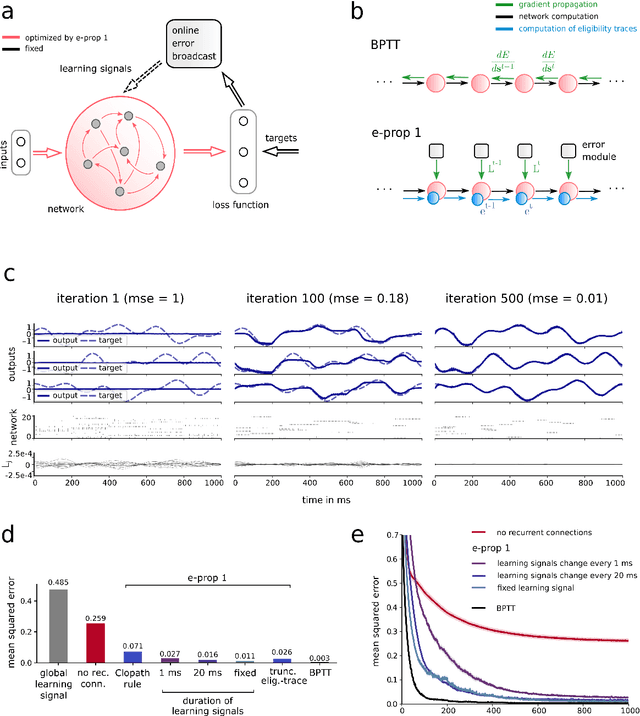
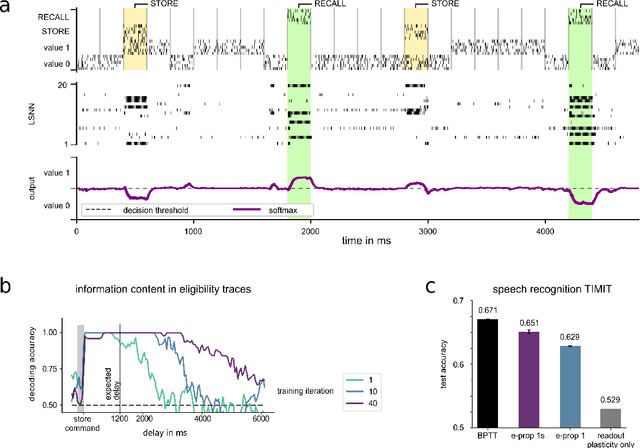
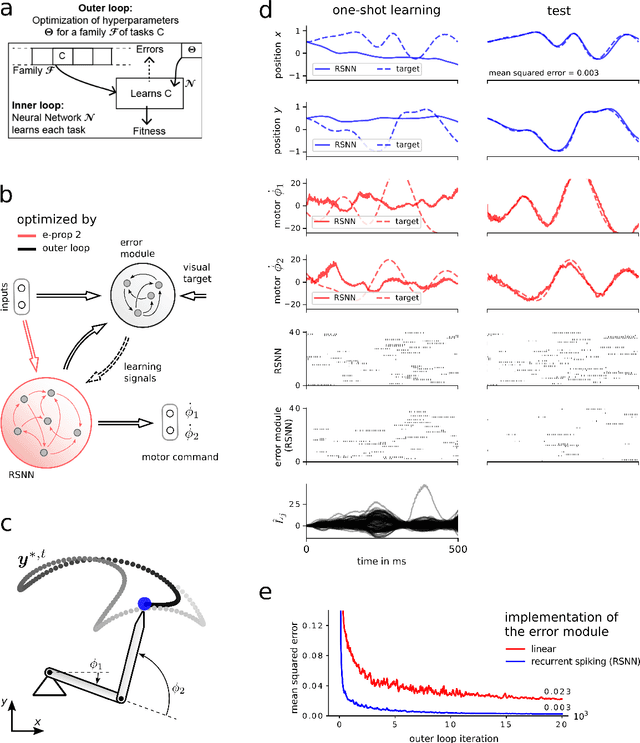
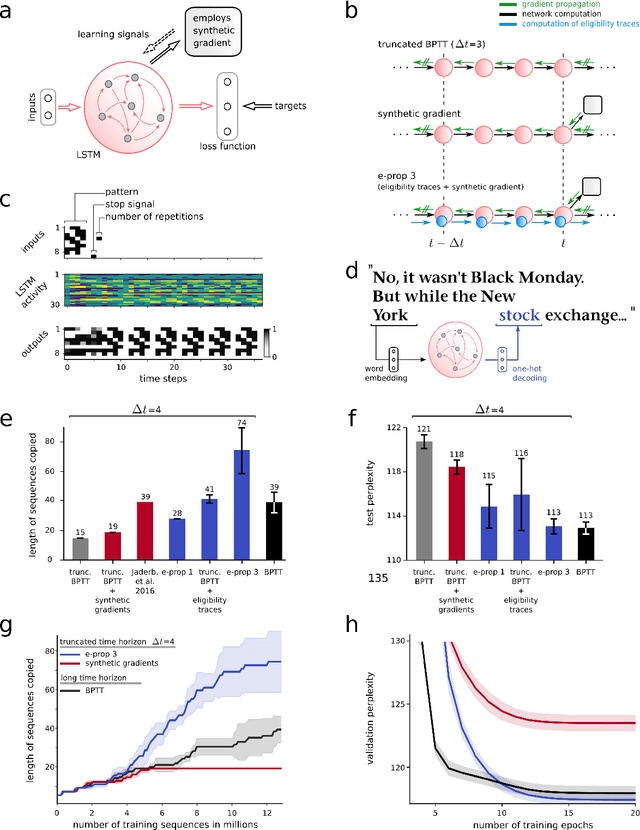
The way how recurrently connected networks of spiking neurons in the brain acquire powerful information processing capabilities through learning has remained a mystery. This lack of understanding is linked to a lack of learning algorithms for recurrent networks of spiking neurons (RSNNs) that are both functionally powerful and can be implemented by known biological mechanisms. Since RSNNs are simultaneously a primary target for implementations of brain-inspired circuits in neuromorphic hardware, this lack of algorithmic insight also hinders technological progress in that area. The gold standard for learning in recurrent neural networks in machine learning is back-propagation through time (BPTT), which implements stochastic gradient descent with regard to a given loss function. But BPTT is unrealistic from a biological perspective, since it requires a transmission of error signals backwards in time and in space, i.e., from post- to presynaptic neurons. We show that an online merging of locally available information during a computation with suitable top-down learning signals in real-time provides highly capable approximations to BPTT. For tasks where information on errors arises only late during a network computation, we enrich locally available information through feedforward eligibility traces of synapses that can easily be computed in an online manner. The resulting new generation of learning algorithms for recurrent neural networks provides a new understanding of network learning in the brain that can be tested experimentally. In addition, these algorithms provide efficient methods for on-chip training of RSNNs in neuromorphic hardware.
JPGNet: Joint Predictive Filtering and Generative Network for Image Inpainting
Jul 09, 2021

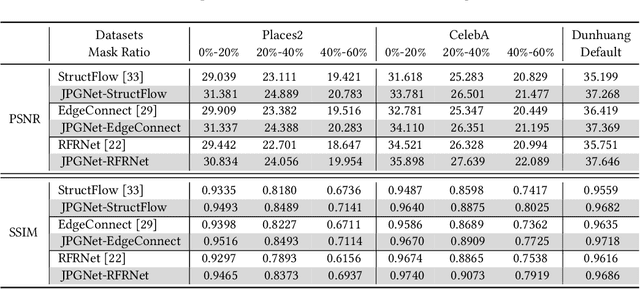
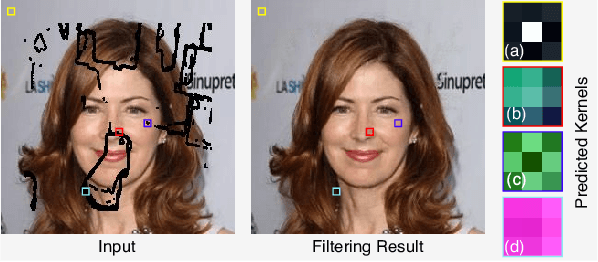
Image inpainting aims to restore the missing regions and make the recovery results identical to the originally complete image, which is different from the common generative task emphasizing the naturalness of generated images. Nevertheless, existing works usually regard it as a pure generation problem and employ cutting-edge generative techniques to address it. The generative networks fill the main missing parts with realistic contents but usually distort the local structures. In this paper, we formulate image inpainting as a mix of two problems, i.e., predictive filtering and deep generation. Predictive filtering is good at preserving local structures and removing artifacts but falls short to complete the large missing regions. The deep generative network can fill the numerous missing pixels based on the understanding of the whole scene but hardly restores the details identical to the original ones. To make use of their respective advantages, we propose the joint predictive filtering and generative network (JPGNet) that contains three branches: predictive filtering & uncertainty network (PFUNet), deep generative network, and uncertainty-aware fusion network (UAFNet). The PFUNet can adaptively predict pixel-wise kernels for filtering-based inpainting according to the input image and output an uncertainty map. This map indicates the pixels should be processed by filtering or generative networks, which is further fed to the UAFNet for a smart combination between filtering and generative results. Note that, our method as a novel framework for the image inpainting problem can benefit any existing generation-based methods. We validate our method on three public datasets, i.e., Dunhuang, Places2, and CelebA, and demonstrate that our method can enhance three state-of-the-art generative methods (i.e., StructFlow, EdgeConnect, and RFRNet) significantly with the slightly extra time cost.
Arithmetic-Intensity-Guided Fault Tolerance for Neural Network Inference on GPUs
Apr 19, 2021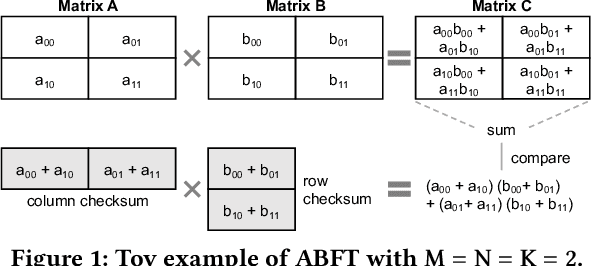
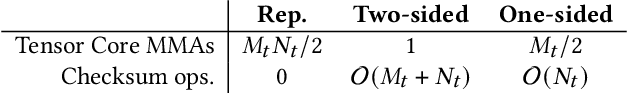
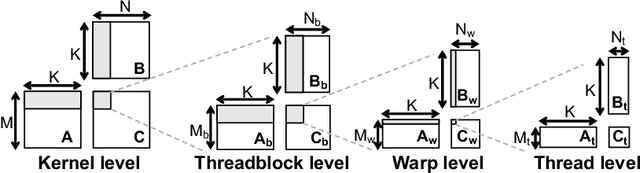
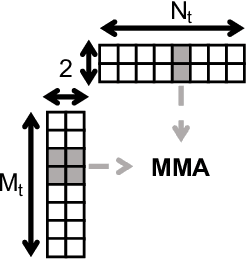
Neural networks (NNs) are increasingly employed in domains that require high reliability, such as scientific computing and safety-critical systems, as well as in environments more prone to unreliability (e.g., soft errors), such as on spacecraft. As recent work has shown that faults in NN inference can lead to mispredictions and safety hazards, it is critical to impart fault tolerance to NN inference. Algorithm-based fault tolerance (ABFT) is emerging as an appealing approach for efficient fault tolerance in NNs. In this work, we identify new, unexploited opportunities for low-overhead ABFT for NN inference: current inference-optimized GPUs have high compute-to-memory-bandwidth ratios, while many layers of current and emerging NNs have low arithmetic intensity. This leaves many convolutional and fully-connected layers in NNs memory-bandwidth-bound. These layers thus exhibit stalls in computation that could be filled by redundant execution, but that current approaches to ABFT for NN inference cannot exploit. To reduce execution-time overhead for such memory-bandwidth-bound layers, we first investigate thread-level ABFT schemes for inference-optimized GPUs that exploit this fine-grained compute underutilization. We then propose intensity-guided ABFT, an adaptive, arithmetic-intensity-guided approach to ABFT that selects the best ABFT scheme for each individual layer between traditional approaches to ABFT, which are suitable for compute-bound layers, and thread-level ABFT, which is suitable for memory-bandwidth-bound layers. Through this adaptive approach, intensity-guided ABFT reduces execution-time overhead by 1.09--5.3$\times$ across a variety of NNs, lowering the cost of fault tolerance for current and future NN inference workloads.
Convolutional Sparse Coding Fast Approximation with Application to Seismic Reflectivity Estimation
Jun 29, 2021
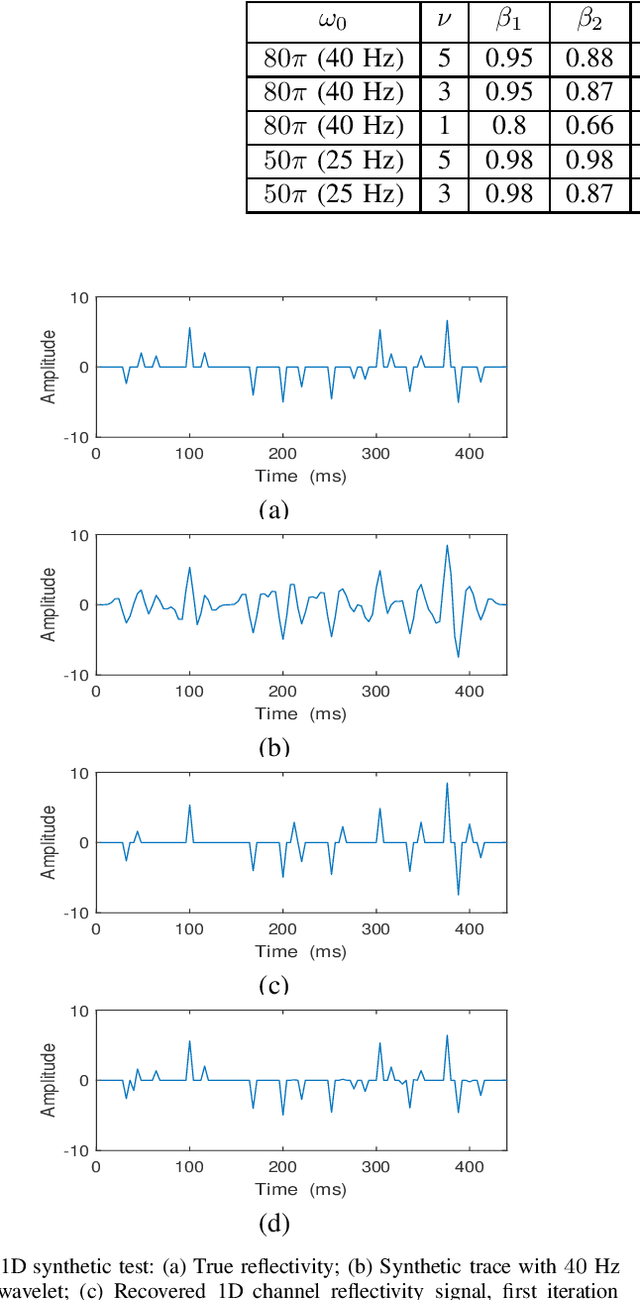
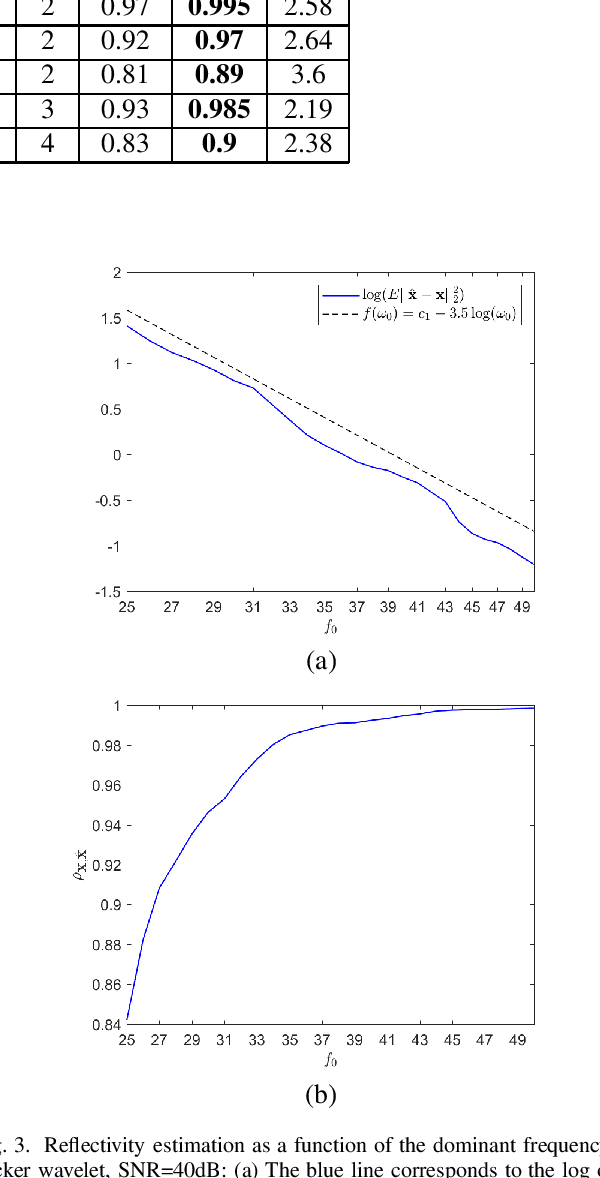
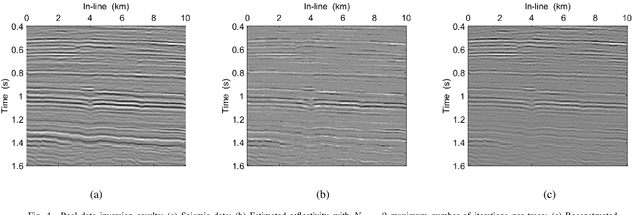
In sparse coding, we attempt to extract features of input vectors, assuming that the data is inherently structured as a sparse superposition of basic building blocks. Similarly, neural networks perform a given task by learning features of the training data set. Recently both data-driven and model-driven feature extracting methods have become extremely popular and have achieved remarkable results. Nevertheless, practical implementations are often too slow to be employed in real-life scenarios, especially for real-time applications. We propose a speed-up upgraded version of the classic iterative thresholding algorithm, that produces a good approximation of the convolutional sparse code within 2-5 iterations. The speed advantage is gained mostly from the observation that most solvers are slowed down by inefficient global thresholding. The main idea is to normalize each data point by the local receptive field energy, before applying a threshold. This way, the natural inclination towards strong feature expressions is suppressed, so that one can rely on a global threshold that can be easily approximated, or learned during training. The proposed algorithm can be employed with a known predetermined dictionary, or with a trained dictionary. The trained version is implemented as a neural net designed as the unfolding of the proposed solver. The performance of the proposed solution is demonstrated via the seismic inversion problem in both synthetic and real data scenarios. We also provide theoretical guarantees for a stable support recovery. Namely, we prove that under certain conditions the true support is perfectly recovered within the first iteration.
DSTP-RNN: a dual-stage two-phase attention-based recurrent neural networks for long-term and multivariate time series prediction
Apr 16, 2019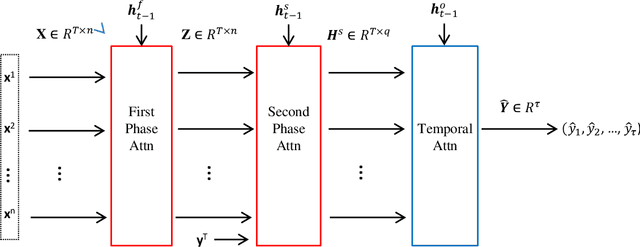
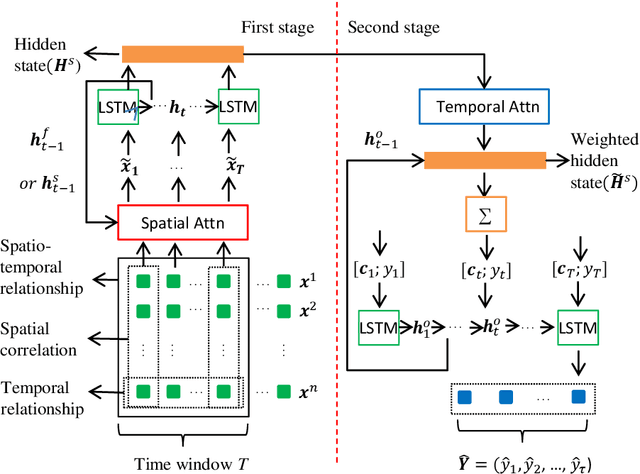
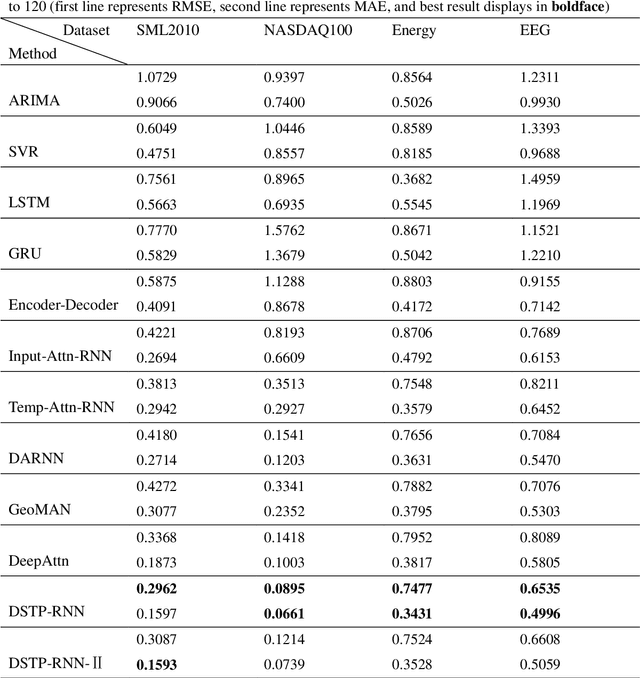
Long-term prediction of multivariate time series is still an important but challenging problem. The key to solve this problem is to capture the spatial correlations at the same time, the spatio-temporal relationships at different times and the long-term dependence of the temporal relationships between different series. Attention-based recurrent neural networks (RNN) can effectively represent the dynamic spatio-temporal relationships between exogenous series and target series, but it only performs well in one-step time prediction and short-term time prediction. In this paper, inspired by human attention mechanism including the dual-stage two-phase (DSTP) model and the influence mechanism of target information and non-target information, we propose DSTP-based RNN (DSTP-RNN) and DSTP-RNN-2 respectively for long-term time series prediction. Specifically, we first propose the DSTP-based structure to enhance the spatial correlations between exogenous series. The first phase produces violent but decentralized response weight, while the second phase leads to stationary and concentrated response weight. Secondly, we employ multiple attentions on target series to boost the long-term dependence. Finally, we study the performance of deep spatial attention mechanism and provide experiment and interpretation. Our methods outperform nine baseline methods on four datasets in the fields of energy, finance, environment and medicine, respectively.
Medical Image Analysis on Left Atrial LGE MRI for Atrial Fibrillation Studies: A Review
Jun 18, 2021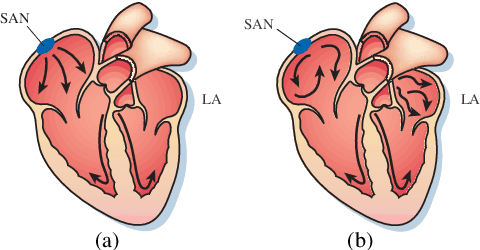
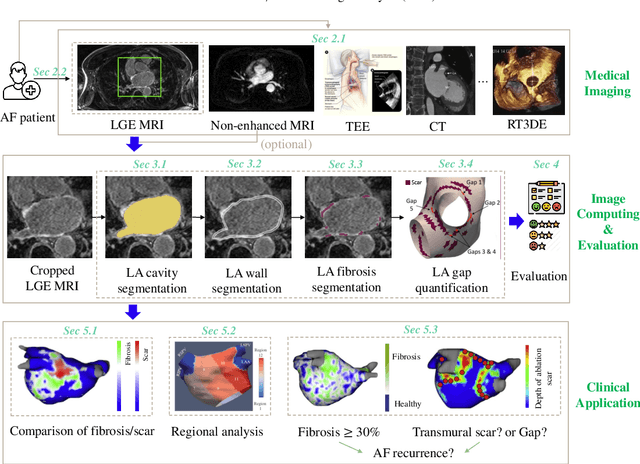

Late gadolinium enhancement magnetic resonance imaging (LGE MRI) is commonly used to visualize and quantify left atrial (LA) scars. The position and extent of scars provide important information of the pathophysiology and progression of atrial fibrillation (AF). Hence, LA scar segmentation and quantification from LGE MRI can be useful in computer-assisted diagnosis and treatment stratification of AF patients. Since manual delineation can be time-consuming and subject to intra- and inter-expert variability, automating this computing is highly desired, which nevertheless is still challenging and under-researched. This paper aims to provide a systematic review on computing methods for LA cavity, wall, scar and ablation gap segmentation and quantification from LGE MRI, and the related literature for AF studies. Specifically, we first summarize AF-related imaging techniques, particularly LGE MRI. Then, we review the methodologies of the four computing tasks in detail, and summarize the validation strategies applied in each task. Finally, the possible future developments are outlined, with a brief survey on the potential clinical applications of the aforementioned methods. The review shows that the research into this topic is still in early stages. Although several methods have been proposed, especially for LA segmentation, there is still large scope for further algorithmic developments due to performance issues related to the high variability of enhancement appearance and differences in image acquisition.
Automated Generation of Robotic Planning Domains from Observations
May 28, 2021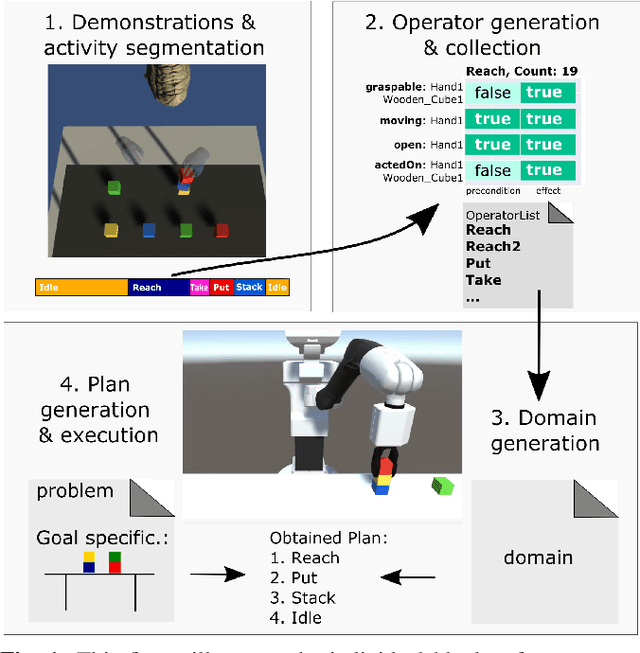
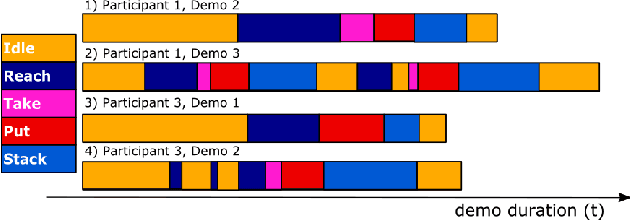
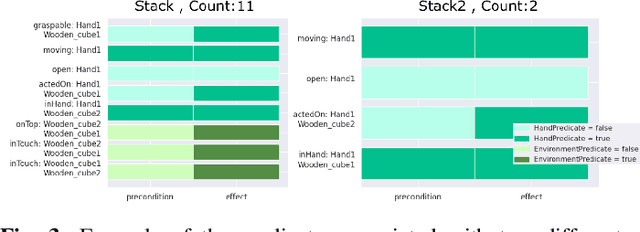
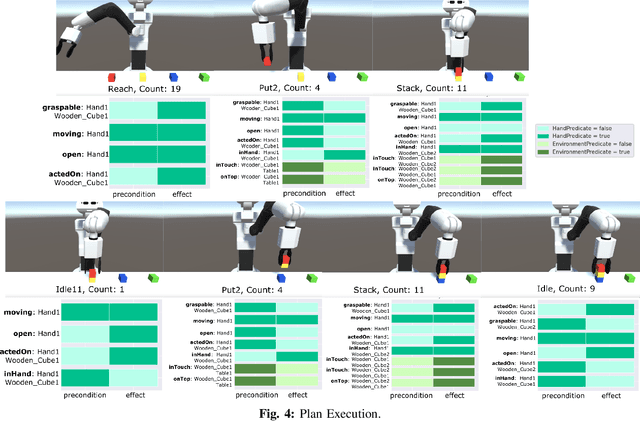
Automated planning enables robots to find plans to achieve complex, long-horizon tasks, given a planning domain. This planning domain consists of a list of actions, with their associated preconditions and effects, and is usually manually defined by a human expert, which is very time-consuming or even infeasible. In this paper, we introduce a novel method for generating this domain automatically from human demonstrations. First, we automatically segment and recognize the different observed actions from human demonstrations. From these demonstrations, the relevant preconditions and effects are obtained, and the associated planning operators are generated. Finally, a sequence of actions that satisfies a user-defined goal can be planned using a symbolic planner. The generated plan is executed in a simulated environment by the TIAGo robot. We tested our method on a dataset of 12 demonstrations collected from three different participants. The results show that our method is able to generate executable plans from using one single demonstration with a 92% success rate, and 100% when the information from all demonstrations are included, even for previously unknown stacking goals.
DDGC: Generative Deep Dexterous Grasping in Clutter
Mar 08, 2021
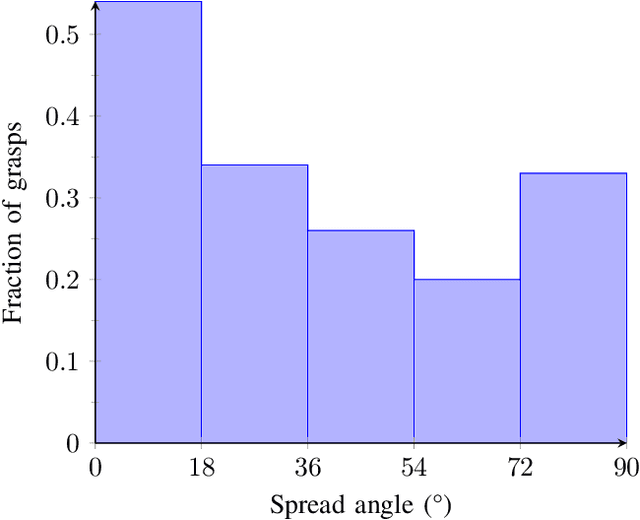
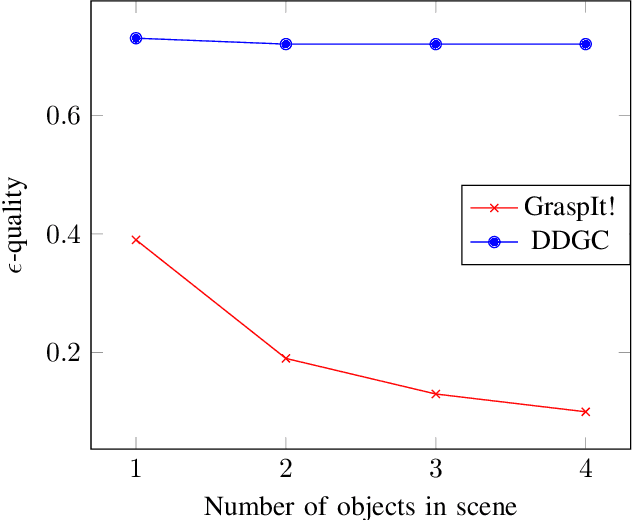

Recent advances in multi-fingered robotic grasping have enabled fast 6-Degrees-Of-Freedom (DOF) single object grasping. Multi-finger grasping in cluttered scenes, on the other hand, remains mostly unexplored due to the added difficulty of reasoning over obstacles which greatly increases the computational time to generate high-quality collision-free grasps. In this work we address such limitations by introducing DDGC, a fast generative multi-finger grasp sampling method that can generate high quality grasps in cluttered scenes from a single RGB-D image. DDGC is built as a network that encodes scene information to produce coarse-to-fine collision-free grasp poses and configurations. We experimentally benchmark DDGC against the simulated-annealing planner in GraspIt! on 1200 simulated cluttered scenes and 7 real world scenes. The results show that DDGC outperforms the baseline on synthesizing high-quality grasps and removing clutter while being 5 times faster. This, in turn, opens up the door for using multi-finger grasps in practical applications which has so far been limited due to the excessive computation time needed by other methods.
A Framework for Knowledge Integrated Evolutionary Algorithms
Mar 31, 2021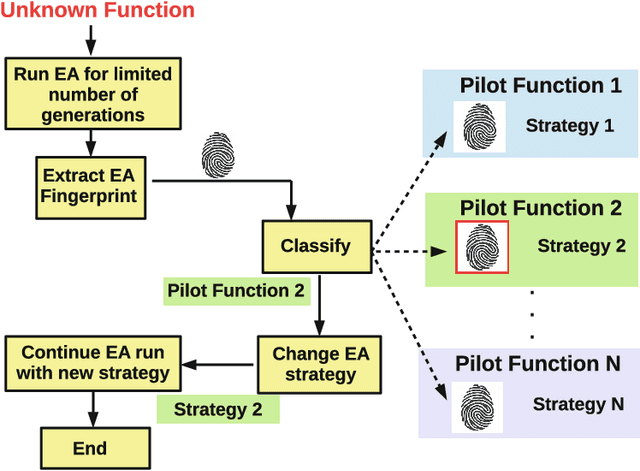

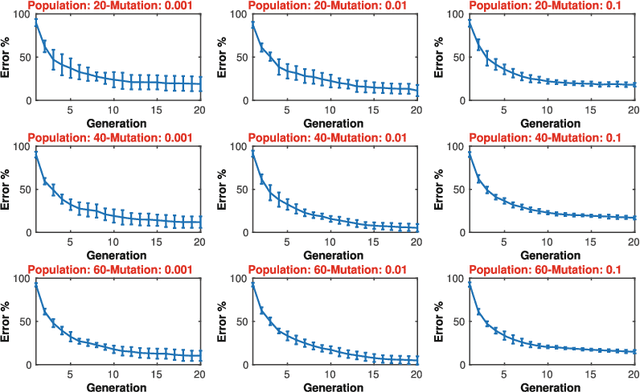
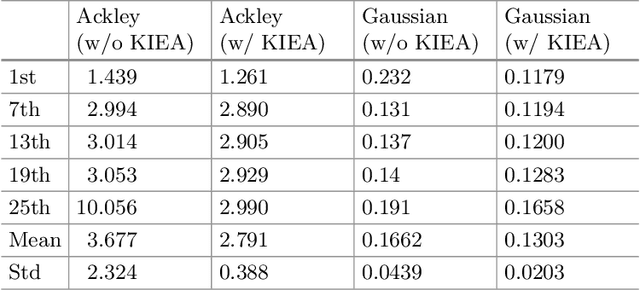
One of the main reasons for the success of Evolutionary Algorithms (EAs) is their general-purposeness, i.e., the fact that they can be applied straightforwardly to a broad range of optimization problems, without any specific prior knowledge. On the other hand, it has been shown that incorporating a priori knowledge, such as expert knowledge or empirical findings, can significantly improve the performance of an EA. However, integrating knowledge in EAs poses numerous challenges. It is often the case that the features of the search space are unknown, hence any knowledge associated with the search space properties can be hardly used. In addition, a priori knowledge is typically problem-specific and hard to generalize. In this paper, we propose a framework, called Knowledge Integrated Evolutionary Algorithm (KIEA), which facilitates the integration of existing knowledge into EAs. Notably, the KIEA framework is EA-agnostic (i.e., it works with any evolutionary algorithm), problem-independent (i.e., it is not dedicated to a specific type of problems), expandable (i.e., its knowledge base can grow over time). Furthermore, the framework integrates knowledge while the EA is running, thus optimizing the use of the needed computational power. In the preliminary experiments shown here, we observe that the KIEA framework produces in the worst case an 80% improvement on the converge time, w.r.t. the corresponding "knowledge-free" EA counterpart.
Superiorities of Deep Extreme Learning Machines against Convolutional Neural Networks
Jan 21, 2021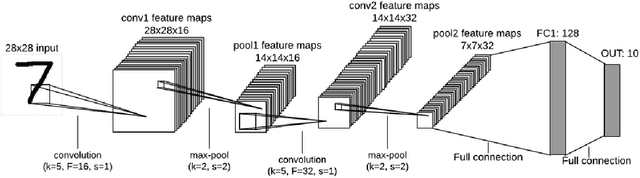
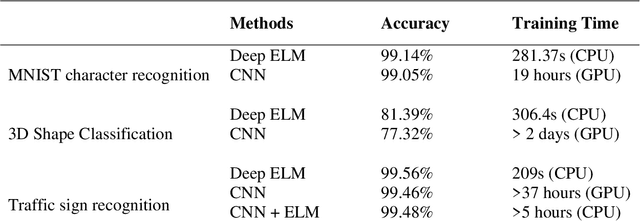
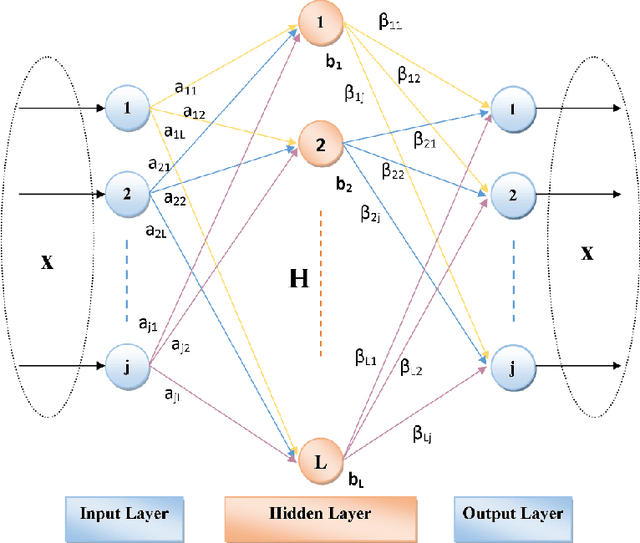
Deep Learning (DL) is a machine learning procedure for artificial intelligence that analyzes the input data in detail by increasing neuron sizes and number of the hidden layers. DL has a popularity with the common improvements on the graphical processing unit capabilities. Increasing number of the neuron sizes at each layer and hidden layers is directly related to the computation time and training speed of the classifier models. The classification parameters including neuron weights, output weights, and biases need to be optimized for obtaining an optimum model. Most of the popular DL algorithms require long training times for optimization of the parameters with feature learning progresses and back-propagated training procedures. Reducing the training time and providing a real-time decision system are the basic focus points of the novel approaches. Deep Extreme Learning machines (Deep ELM) classifier model is one of the fastest and effective way to meet fast classification problems. In this study, Deep ELM model, its superiorities and weaknesses are discussed, the problems that are more suitable for the classifiers against Convolutional neural network based DL algorithms.
* 7 pages, 2 figures, Natural and Engineering Sciences