 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges Encountered in Turkish Natural Language Processing Studies
Jan 21, 2021Natural language processing is a branch of computer science that combines artificial intelligence with linguistics. It aims to analyze a language element such as writing or speaking with software and convert it into information. Considering that each language has its own grammatical rules and vocabulary diversity, the complexity of the studies in this field is somewhat understandable. For instance, Turkish is a very interesting language in many ways. Examples of this are agglutinative word structure, consonant/vowel harmony, a large number of productive derivational morphemes (practically infinite vocabulary), derivation and syntactic relations, a complex emphasis on vocabulary and phonological rules. In this study, the interesting features of Turkish in terms of natural language processing are mentioned. In addition, summary info about natural language processing techniques, systems and various sources developed for Turkish are given.
* 8 pages, Natural and Engineering Sciences
Effect of Window Size for Detection of Abnormalities in Respiratory Sounds
Jan 21, 2021
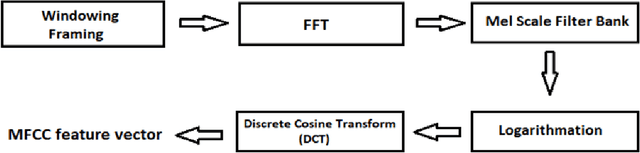
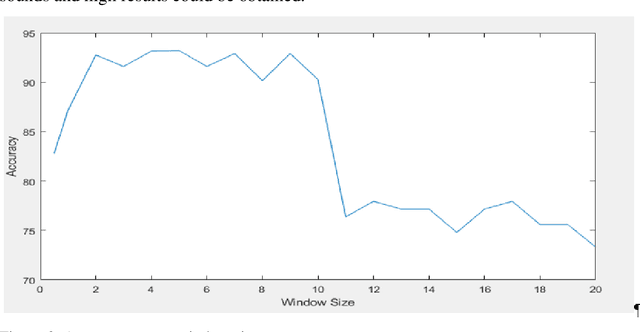
The recording of respiratory sounds was of significant benefit in the diagnosis of abnormalities in respiratory sounds. The duration of the sounds used in the diagnosis affects the speed of the diagnosis. In this study, the effect of window size on diagnosis of abnormalities in respiratory sounds and the most efficient recording time for diagnosis were analyzed. First, window size was applied to each sound in the data set consisting of normal and abnormal breathing sounds, 0.5 second and from 1 to 20 seconds Increased by 1 second. Then, the data applied to window size was inferred feature extraction with Mel Frequency Cepstral Coefficient (MFCC) and the performance of each window was calculated using the leave one-out classifier and the k-nearest neighbor (KNN) algorithm. As a result, it was determined that the data was significant with an average performance of 92.06% in the records between 2 and 10 seconds.
* 6 pages, 3 figures, Natural and Engineering Sciences
Superiorities of Deep Extreme Learning Machines against Convolutional Neural Networks
Jan 21, 2021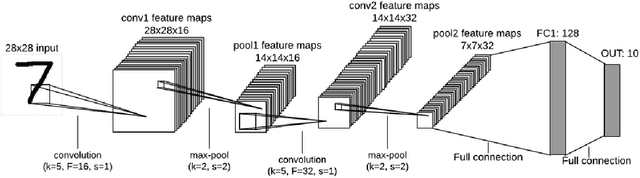
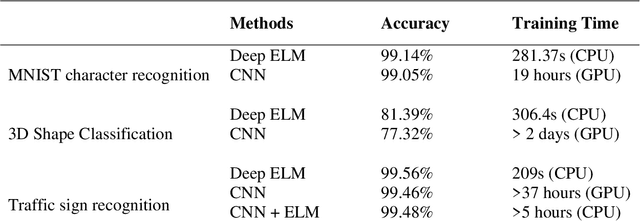
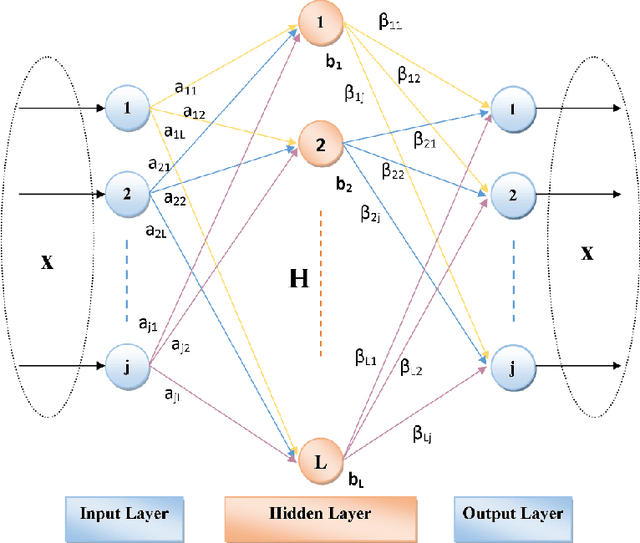
Deep Learning (DL) is a machine learning procedure for artificial intelligence that analyzes the input data in detail by increasing neuron sizes and number of the hidden layers. DL has a popularity with the common improvements on the graphical processing unit capabilities. Increasing number of the neuron sizes at each layer and hidden layers is directly related to the computation time and training speed of the classifier models. The classification parameters including neuron weights, output weights, and biases need to be optimized for obtaining an optimum model. Most of the popular DL algorithms require long training times for optimization of the parameters with feature learning progresses and back-propagated training procedures. Reducing the training time and providing a real-time decision system are the basic focus points of the novel approaches. Deep Extreme Learning machines (Deep ELM) classifier model is one of the fastest and effective way to meet fast classification problems. In this study, Deep ELM model, its superiorities and weaknesses are discussed, the problems that are more suitable for the classifiers against Convolutional neural network based DL algorithms.
* 7 pages, 2 figures, Natural and Engineering Sciences
Generative Autoencoder Kernels on Deep Learning for Brain Activity Analysis
Jan 21, 2021

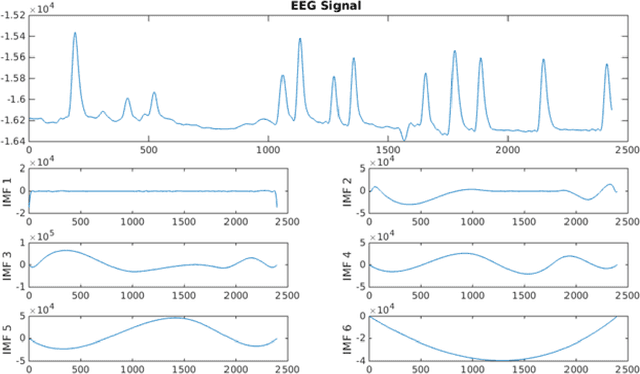
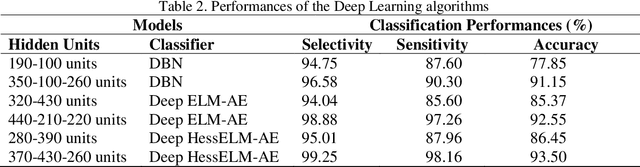
Deep Learning (DL) is a two-step classification model that consists feature learning, generating feature representations using unsupervised ways and the supervised learning stage at the last step of model using at least two hidden layers on the proposed structures by fully connected layers depending on of the artificial neural networks. The optimization of the predefined classification parameters for the supervised models eases reaching the global optimality with exact zero training error. The autoencoder (AE) models are the highly generalized ways of the unsupervised stages for the DL to define the output weights of the hidden neurons with various representations. As alternatively to the conventional Extreme Learning Machines (ELM) AE, Hessenberg decomposition-based ELM autoencoder (HessELM-AE) is a novel kernel to generate different presentations of the input data within the intended sizes of the models. The aim of the study is analyzing the performance of the novel Deep AE kernel for clinical availability on electroencephalogram (EEG) with stroke patients. The slow cortical potentials (SCP) training in stroke patients during eight neurofeedback sessions were analyzed using Hilbert-Huang Transform. The statistical features of different frequency modulations were fed into the Deep ELM model for generative AE kernels. The novel Deep ELM-AE kernels have discriminated the brain activity with high classification performances for positivity and negativity tasks in stroke patients.
* 12 pages, 2 figures, Natural and Engineering Sciences
Online LDA based brain-computer interface system to aid disabled people
Jan 21, 2021

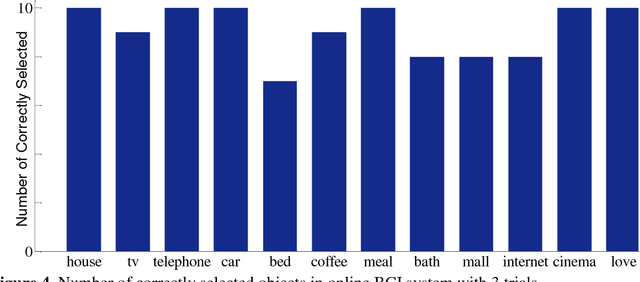
This paper aims to develop brain-computer interface system based on electroencephalography that can aid disabled people in daily life. The system relies on one of the most effective event-related potential wave, P300, which can be elicited by oddball paradigm. Developed application has a basic interaction tool that enables disabled people to convey their needs to other people selecting related objects. These objects pseudo-randomly flash in a visual interface on computer screen. The user must focus on related object to convey desired needs. The system can convey desired needs correctly by detecting P300 wave in acquired 14-channel EEG signal and classifying using linear discriminant analysis classifier just in 15 seconds. Experiments have been carried out on 19 volunteers to validate developed BCI system. As a result, accuracy rate of 90.83% is achieved in online performance
* 13 pages, 4 figures, Natural and Engineering Sciences
Multimedia Respiratory Database (RespiratoryDatabase@TR): Auscultation Sounds and Chest X-rays
Jan 21, 2021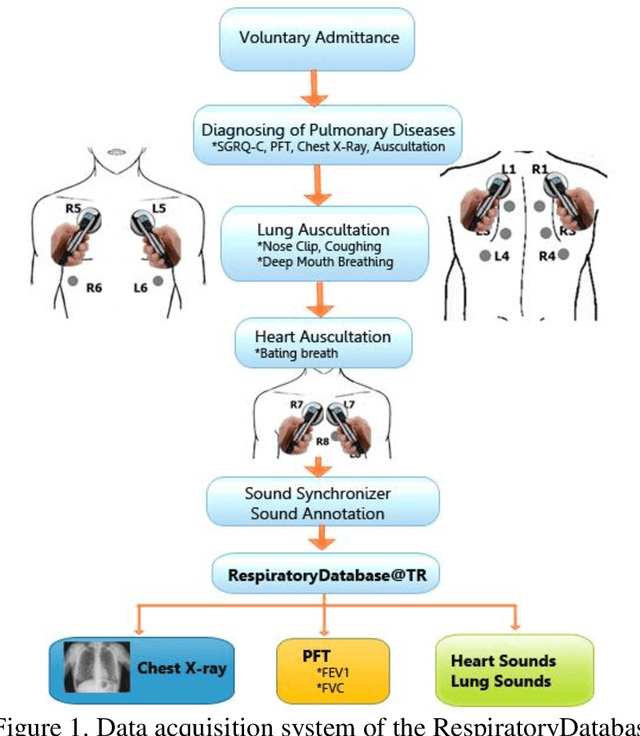
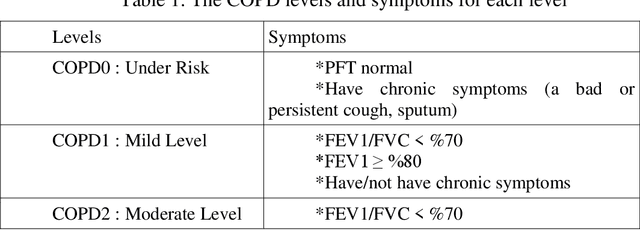
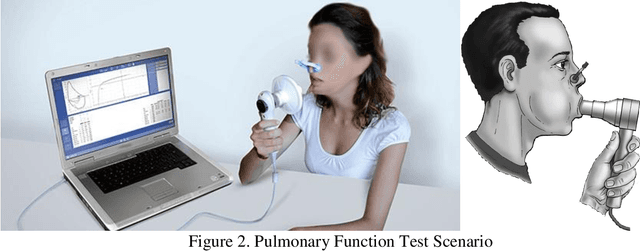
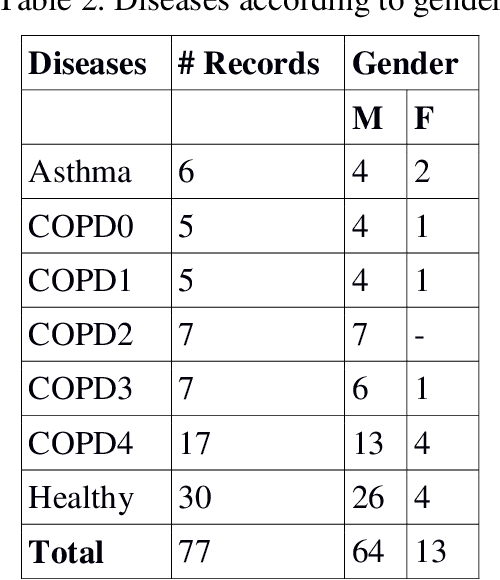
Auscultation is a method for diagnosis of especially internal medicine diseases such as cardiac, pulmonary and cardio-pulmonary by listening the internal sounds from the body parts. It is the simplest and the most common physical examination in the assessment processes of the clinical skills. In this study, the lung and heart sounds are recorded synchronously from left and right sides of posterior and anterior chest wall and back using two digital stethoscopes in Antakya State Hospital. The chest X-rays and the pulmonary function test variables and spirometric curves, the St. George respiratory questionnaire (SGRQ-C) are collected as multimedia and clinical functional analysis variables of the patients. The 4 channels of heart sounds are focused on aortic, pulmonary, tricuspid and mitral areas. The 12 channels of lung sounds are focused on upper lung, middle lung, lower lung and costophrenic angle areas of posterior and anterior sides of the chest. The recordings are validated and labelled by two pulmonologists evaluating the collected chest x-ray, PFT and auscultation sounds of the subjects. The database consists of 30 healthy subjects and 45 subjects with pulmonary diseases such as asthma, chronic obstructive pulmonary disease, bronchitis. The novelties of the database are the combination ability between auscultation sound results, chest X-ray and PFT; synchronously assessment capability of the lungs sounds; image processing based computerized analysis of the respiratory using chest X-ray and providing opportunity for improving analysis of both lung sounds and heart sounds on pulmonary and cardiac diseases.
* 14 pages, 7 figures, Natural and Engineering Sciences
Analysis of Relation between Motor Activity and Imaginary EEG Records
Jan 21, 2021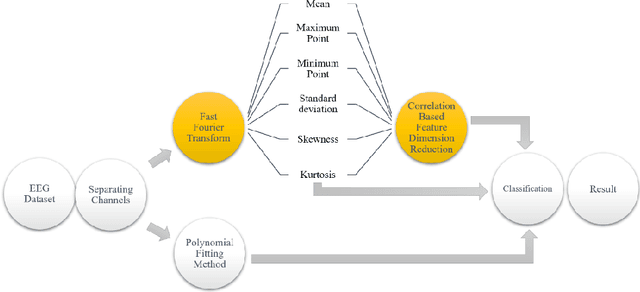
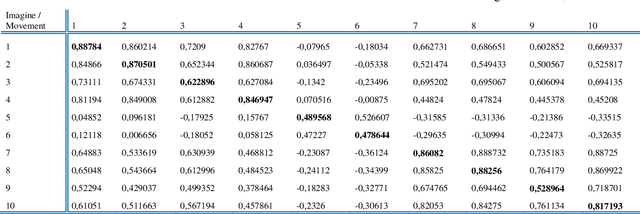
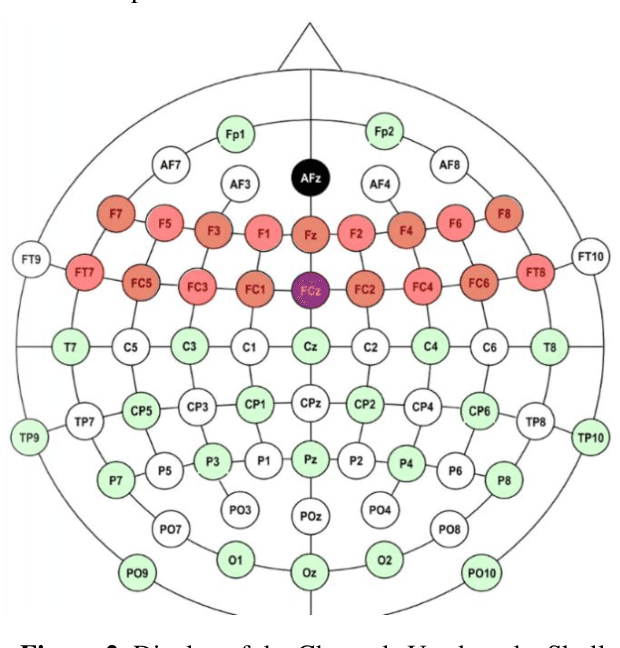
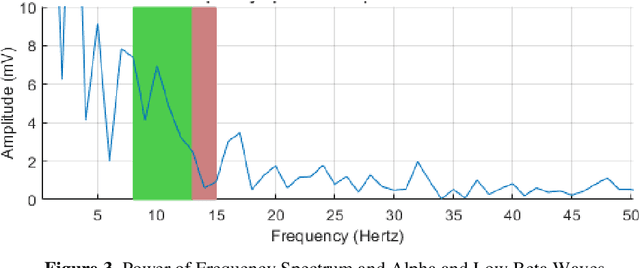
Electroencephalography (EEG) signals signals are often used to learn about brain structure and to learn what thinking. EEG signals can be easily affected by external factors. For this reason, they should be applied various pre-process during their analysis. In this study, it is used the EEG signals received from 109 subjects when opening and closing their right or left fists and performing hand and foot movements and imagining the same movements. The relationship between motor activities and imaginary of that motor activities were investigated. Algorithms with high performance rates have been used for feature extraction , selection and classification using the nearest neighbour algorithm.
* 6 pages, 4 figures, Journal of Artificial Intellicence with Application
Turkish Voice Commands based Chess Game using Gammatone Cepstral Coefficients
Jan 21, 2021This study was carried out to enable individuals with limited mobility skills to play chess in real time and to play games with the individuals around them without being under any social distress or stress. Voice recordings were taken from 50 people (23 men and 27 women). While recording the sound, 29 words from each person were used which are determined as necessary for playing the game. Mel Frequency Coefficients (MFCC) and Gammatone Cepstral Coefficients (GTCC) qualification methods were used. In addition, k-NN, Naive Bayes and Neural Network classification methods were used for classification. Two different classification procedures were applied, namely, person-based and general. While the performance rate in person-based classification ranged from 75% to 98%, a performance over 84% was achieved in general classification.
* 5 pages, Journal of Artificial Intelligence with Application
Effect of Deep Learning Feature Inference Techniques on Respiratory Sounds
Jan 21, 2021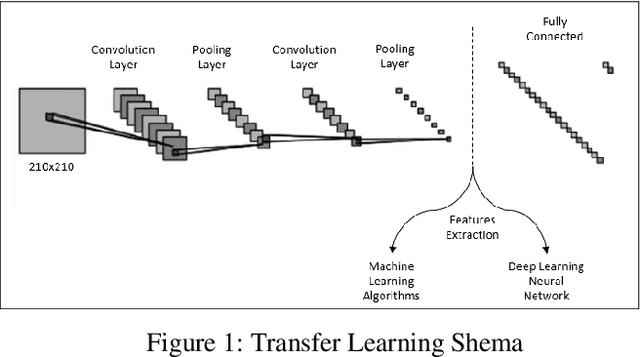
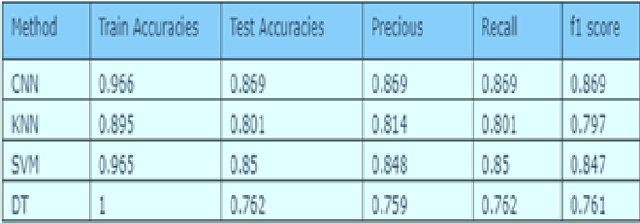
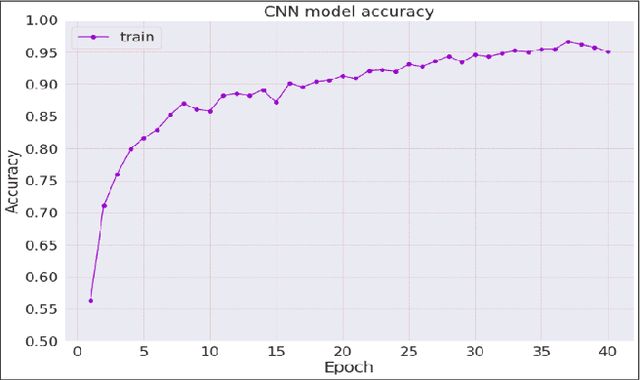
Analysis of respiratory sounds increases its importance every day. Many different methods are available in the analysis, and new techniques are continuing to be developed to further improve these methods. Features are extracted from audio signals and trained using different machine learning techniques. The use of deep learning, which is a different method and has increased in recent years, also shows its influence in this field. Deep learning techniques applied to the image of audio signals give good results and continue to be developed. In this study, image filters were applied to the values obtained from audio signals and the results of the features formed from this were examined in machine learning and deep learning techniques. Their results were compared with the results of methods that had previously achieved good results.
* 4 pages, journal of intelligent systems with applications
Android Controlled Mobile Robot Design with IP Camera
Jan 20, 2021In this study Arduino card based mobile robot design was realized. This robot can serve as a security robot, an auxiliary robot or a control robot. The designed robot has two operation modes. The first operating mode is autonomous mode. In this mode, the robot detects the surroundings with the help of ultrasonic sensors placed around it, and keeps track of the places it passes by using the encoder. It is able to navigate without hitting any place and passing from where it passes, and it transmits the patient's pulse and temperature condition to the user by other systems installed on it. Also the IP camera sends the scene on the screen. The emergency button to be placed next to the patient sends information to the user in emergency situations. If the abnormality is detected in the temperature and pulse again, the user gives a message. When the pre-recorded drug use times come, the system can alert the patient. The second mode is manual mode. In this mode, the user can move the desired direction of the robot with the Android operating system. In addition, all data received in autonomous mode can be sent to the user. Thus, the user can control the mobile robot with the camera image even if it is not in the vicinity of the robot.