 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Deep Representations of Radiology Reports in Survival Analysis for Predicting Heart Failure Patient Mortality
May 03, 2021
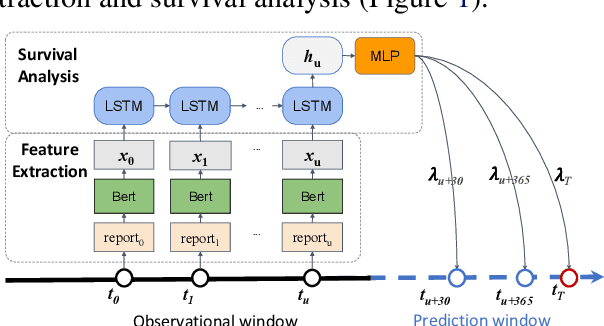
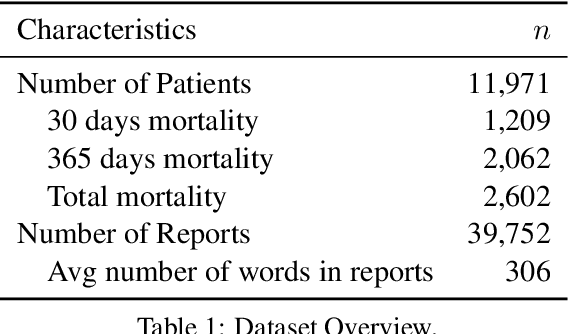
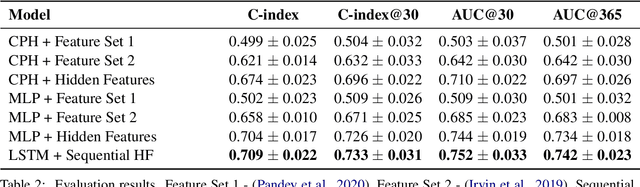
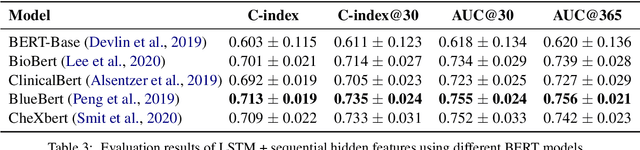
Utilizing clinical texts in survival analysis is difficult because they are largely unstructured. Current automatic extraction models fail to capture textual information comprehensively since their labels are limited in scope. Furthermore, they typically require a large amount of data and high-quality expert annotations for training. In this work, we present a novel method of using BERT-based hidden layer representations of clinical texts as covariates for proportional hazards models to predict patient survival outcomes. We show that hidden layers yield notably more accurate predictions than predefined features, outperforming the previous baseline model by 5.7% on average across C-index and time-dependent AUC. We make our work publicly available at https://github.com/bionlplab/heart_failure_mortality.
How to Decompose a Tensor with Group Structure
Jun 04, 2021In this work we study the orbit recovery problem, which is a natural abstraction for the problem of recovering a planted signal from noisy measurements under unknown group actions. Many important inverse problems in statistics, engineering and the sciences fit into this framework. Prior work has studied cases when the group is discrete and/or abelian. However fundamentally new techniques are needed in order to handle more complex group actions. Our main result is a quasi-polynomial time algorithm to solve orbit recovery over $SO(3)$ - i.e. the cryo-electron tomography problem which asks to recover the three-dimensional structure of a molecule from noisy measurements of randomly rotated copies of it. We analyze a variant of the frequency marching heuristic in the framework of smoothed analysis. Our approach exploits the layered structure of the invariant polynomials, and simultaneously yields a new class of tensor decomposition algorithms that work in settings when the tensor is not low-rank but rather where the factors are algebraically related to each other by a group action.
A Consistent Method for Learning OOMs from Asymptotically Stationary Time Series Data Containing Missing Values
Oct 19, 2018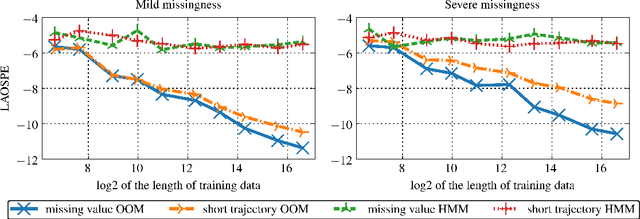
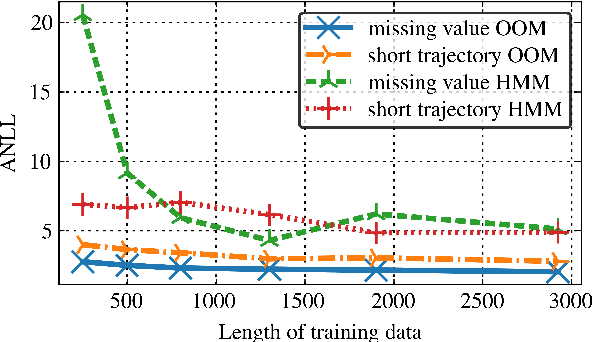
In the traditional framework of spectral learning of stochastic time series models, model parameters are estimated based on trajectories of fully recorded observations. However, real-world time series data often contain missing values, and worse, the distributions of missingness events over time are often not independent of the visible process. Recently, a spectral OOM learning algorithm for time series with missing data was introduced and proved to be consistent, albeit under quite strong conditions. Here we refine the algorithm and prove that the original strong conditions can be very much relaxed. We validate our theoretical findings by numerical experiments, showing that the algorithm can consistently handle missingness patterns whose dynamic interacts with the visible process.
Context-aware Ensemble of Multifaceted Factorization Models for Recommendation Prediction in Social Networks
May 03, 2021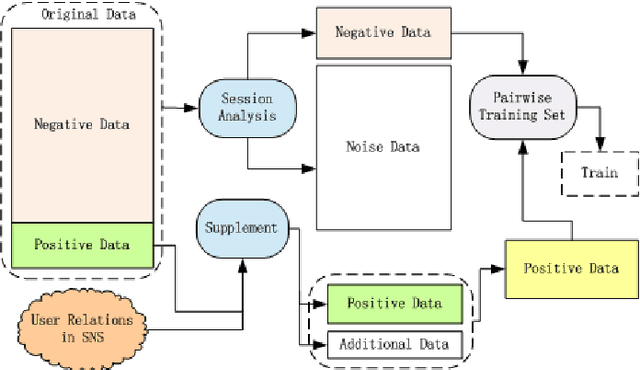
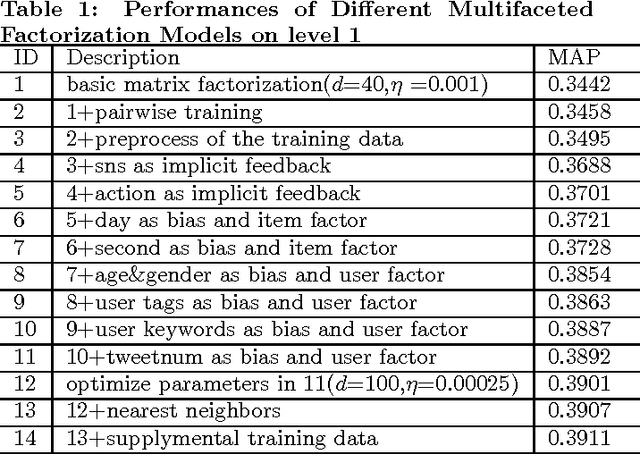
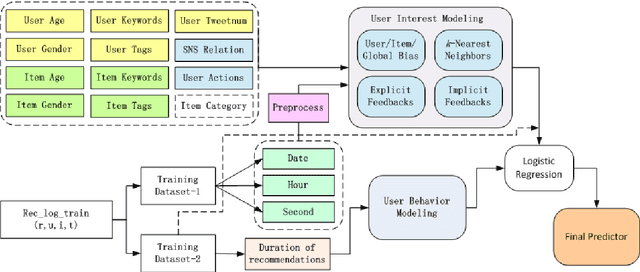

This paper describes the solution of Shanda Innovations team to Task 1 of KDD-Cup 2012. A novel approach called Multifaceted Factorization Models is proposed to incorporate a great variety of features in social networks. Social relationships and actions between users are integrated as implicit feedbacks to improve the recommendation accuracy. Keywords, tags, profiles, time and some other features are also utilized for modeling user interests. In addition, user behaviors are modeled from the durations of recommendation records. A context-aware ensemble framework is then applied to combine multiple predictors and produce final recommendation results. The proposed approach obtained 0.43959 (public score) / 0.41874 (private score) on the testing dataset, which achieved the 2nd place in the KDD-Cup competition.
EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets
Dec 31, 2020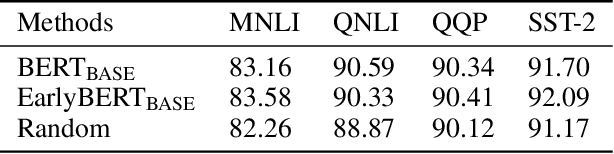
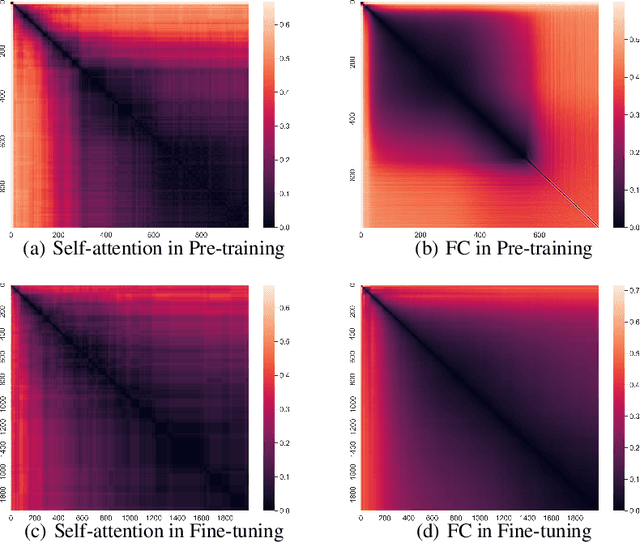
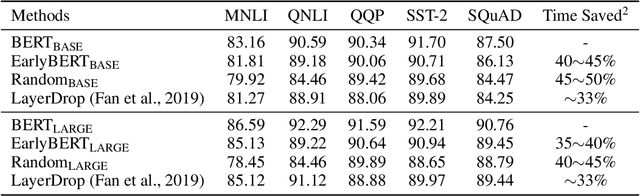
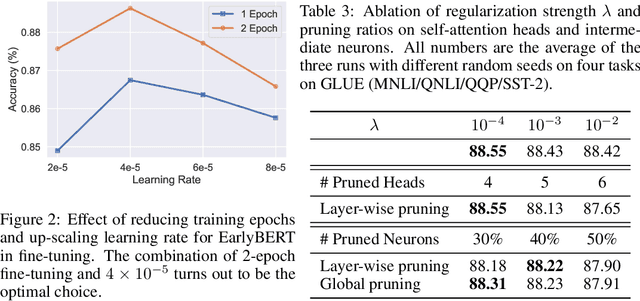
Deep, heavily overparameterized language models such as BERT, XLNet and T5 have achieved impressive success in many NLP tasks. However, their high model complexity requires enormous computation resources and extremely long training time for both pre-training and fine-tuning. Many works have studied model compression on large NLP models, but only focus on reducing inference cost/time, while still requiring expensive training process. Other works use extremely large batch sizes to shorten the pre-training time at the expense of high demand for computation resources. In this paper, inspired by the Early-Bird Lottery Tickets studied for computer vision tasks, we propose EarlyBERT, a general computationally-efficient training algorithm applicable to both pre-training and fine-tuning of large-scale language models. We are the first to identify structured winning tickets in the early stage of BERT training, and use them for efficient training. Comprehensive pre-training and fine-tuning experiments on GLUE and SQuAD downstream tasks show that EarlyBERT easily achieves comparable performance to standard BERT with 35~45% less training time.
A Survey on Deep Learning Methods for Semantic Image Segmentation in Real-Time
Sep 27, 2020
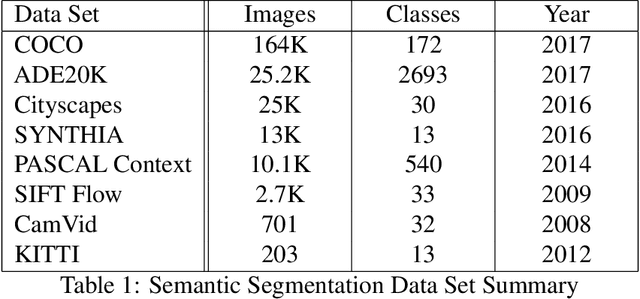
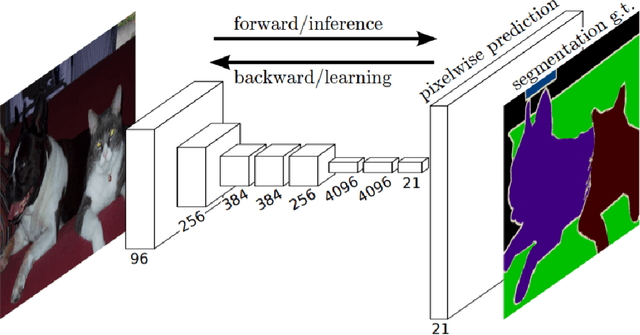
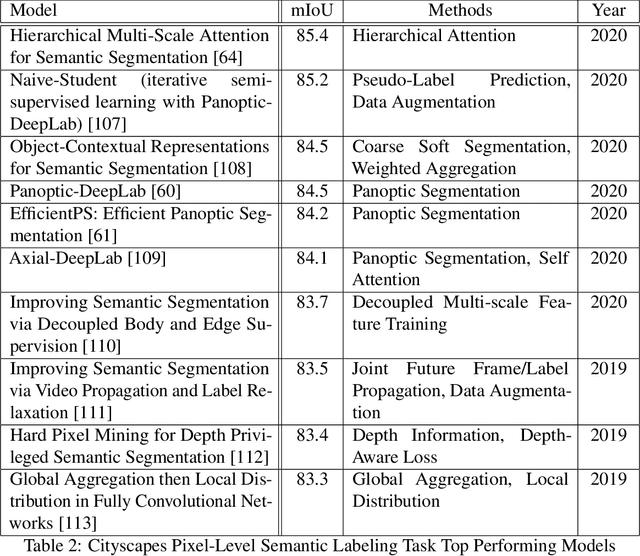
Semantic image segmentation is one of fastest growing areas in computer vision with a variety of applications. In many areas, such as robotics and autonomous vehicles, semantic image segmentation is crucial, since it provides the necessary context for actions to be taken based on a scene understanding at the pixel level. Moreover, the success of medical diagnosis and treatment relies on the extremely accurate understanding of the data under consideration and semantic image segmentation is one of the important tools in many cases. Recent developments in deep learning have provided a host of tools to tackle this problem efficiently and with increased accuracy. This work provides a comprehensive analysis of state-of-the-art deep learning architectures in image segmentation and, more importantly, an extensive list of techniques to achieve fast inference and computational efficiency. The origins of these techniques as well as their strengths and trade-offs are discussed with an in-depth analysis of their impact in the area. The best-performing architectures are summarized with a list of methods used to achieve these state-of-the-art results.
Signal Transformer: Complex-valued Attention and Meta-Learning for Signal Recognition
Jun 12, 2021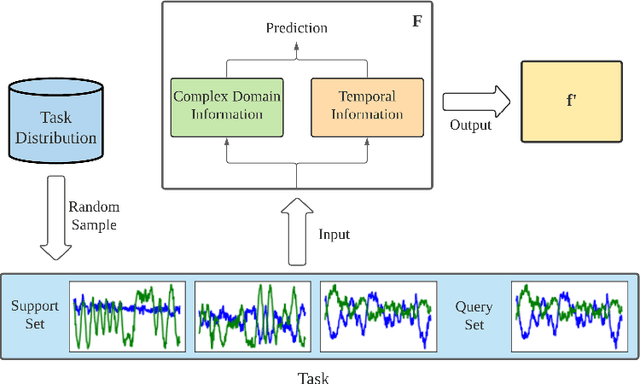
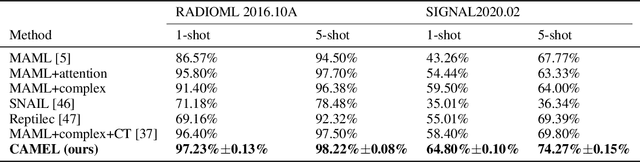

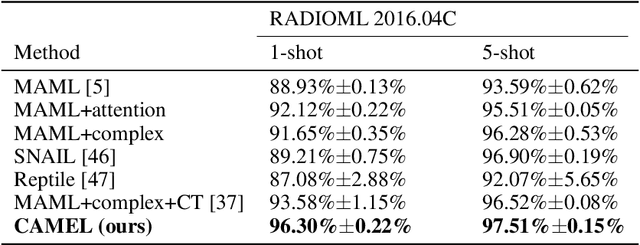
Deep neural networks have been shown as a class of useful tools for addressing signal recognition issues in recent years, especially for identifying the nonlinear feature structures of signals. However, this power of most deep learning techniques heavily relies on an abundant amount of training data, so the performance of classic neural nets decreases sharply when the number of training data samples is small or unseen data are presented in the testing phase. This calls for an advanced strategy, i.e., model-agnostic meta-learning (MAML), which is able to capture the invariant representation of the data samples or signals. In this paper, inspired by the special structure of the signal, i.e., real and imaginary parts consisted in practical time-series signals, we propose a Complex-valued Attentional MEta Learner (CAMEL) for the problem of few-shot signal recognition by leveraging attention and meta-learning in the complex domain. To the best of our knowledge, this is also the first complex-valued MAML that can find the first-order stationary points of general nonconvex problems with theoretical convergence guarantees. Extensive experiments results showcase the superiority of the proposed CAMEL compared with the state-of-the-art methods.
Hierarchical Object-oriented Spatio-Temporal Reasoning for Video Question Answering
Jun 25, 2021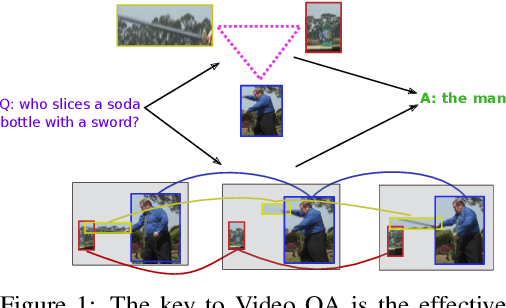
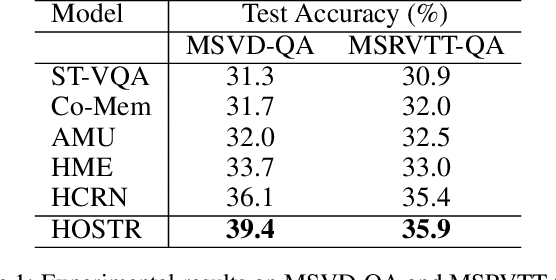
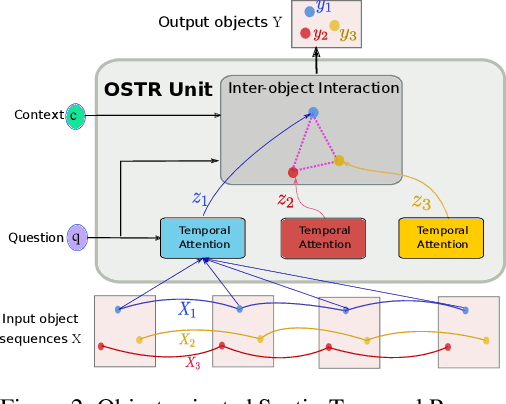
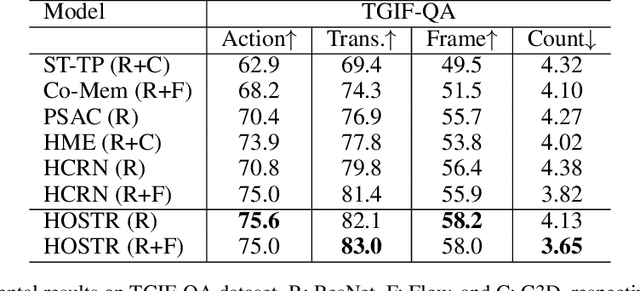
Video Question Answering (Video QA) is a powerful testbed to develop new AI capabilities. This task necessitates learning to reason about objects, relations, and events across visual and linguistic domains in space-time. High-level reasoning demands lifting from associative visual pattern recognition to symbol-like manipulation over objects, their behavior and interactions. Toward reaching this goal we propose an object-oriented reasoning approach in that video is abstracted as a dynamic stream of interacting objects. At each stage of the video event flow, these objects interact with each other, and their interactions are reasoned about with respect to the query and under the overall context of a video. This mechanism is materialized into a family of general-purpose neural units and their multi-level architecture called Hierarchical Object-oriented Spatio-Temporal Reasoning (HOSTR) networks. This neural model maintains the objects' consistent lifelines in the form of a hierarchically nested spatio-temporal graph. Within this graph, the dynamic interactive object-oriented representations are built up along the video sequence, hierarchically abstracted in a bottom-up manner, and converge toward the key information for the correct answer. The method is evaluated on multiple major Video QA datasets and establishes new state-of-the-arts in these tasks. Analysis into the model's behavior indicates that object-oriented reasoning is a reliable, interpretable and efficient approach to Video QA.
Modelling the COVID-19 virus evolution with Incremental Machine Learning
Apr 21, 2021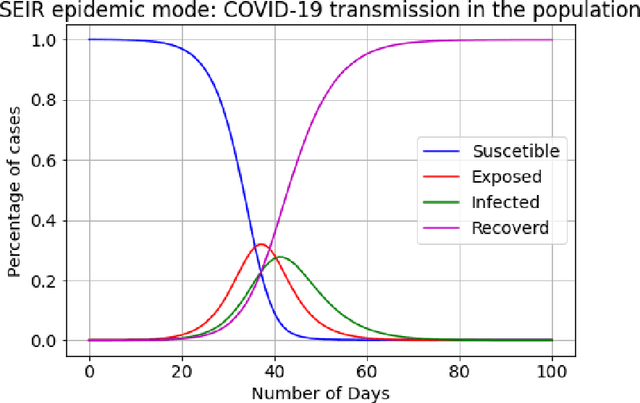
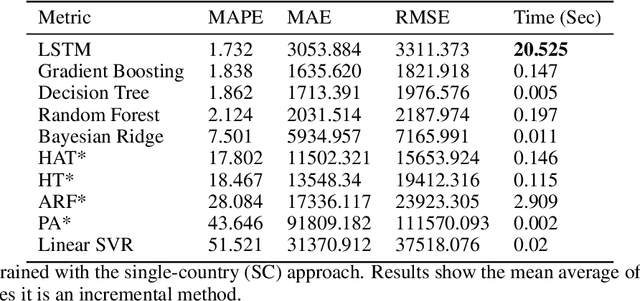
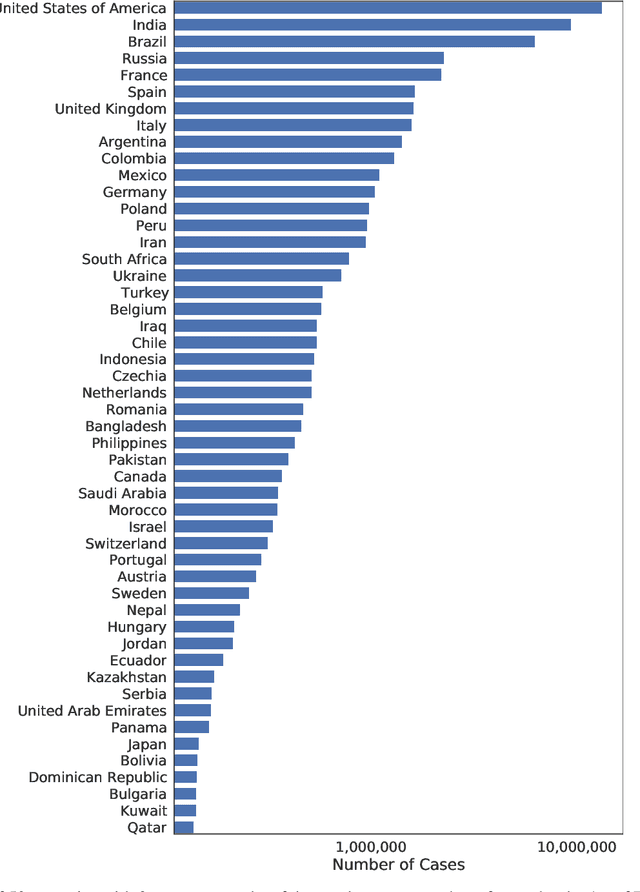
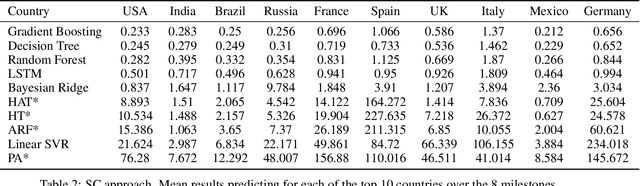
The investment of time and resources for better strategies and methodologies to tackle a potential pandemic is key to deal with potential outbreaks of new variants or other viruses in the future. In this work, we recreated the scene of a year ago, 2020, when the pandemic erupted across the world for the fifty countries with more COVID-19 cases reported. We performed some experiments in which we compare state-of-the-art machine learning algorithms, such as LSTM, against online incremental machine learning algorithms to adapt them to the daily changes in the spread of the disease and predict future COVID-19 cases. To compare the methods, we performed three experiments: In the first one, we trained the models using only data from the country we predicted. In the second one, we use data from all fifty countries to train and predict each of them. In the first and second experiment, we used a static hold-out approach for all methods. In the third experiment, we trained the incremental methods sequentially, using a prequential evaluation. This scheme is not suitable for most state-of-the-art machine learning algorithms because they need to be retrained from scratch for every batch of predictions, causing a computational burden. Results show that incremental methods are a promising approach to adapt to changes of the disease over time; they are always up to date with the last state of the data distribution, and they have a significantly lower computational cost than other techniques such as LSTMs.
Federated Graph Classification over Non-IID Graphs
Jun 25, 2021
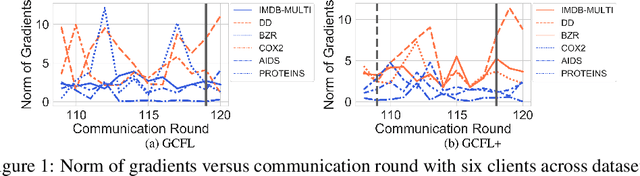

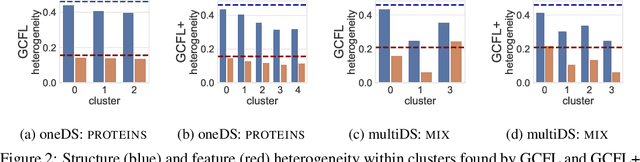
Federated learning has emerged as an important paradigm for training machine learning models in different domains. For graph-level tasks such as graph classification, graphs can also be regarded as a special type of data samples, which can be collected and stored in separate local systems. Similar to other domains, multiple local systems, each holding a small set of graphs, may benefit from collaboratively training a powerful graph mining model, such as the popular graph neural networks (GNNs). To provide more motivation towards such endeavors, we analyze real-world graphs from different domains to confirm that they indeed share certain graph properties that are statistically significant compared with random graphs. However, we also find that different sets of graphs, even from the same domain or same dataset, are non-IID regarding both graph structures and node features. To handle this, we propose a graph clustering federated learning (GCFL) framework that dynamically finds clusters of local systems based on the gradients of GNNs, and theoretically justify that such clusters can reduce the structure and feature heterogeneity among graphs owned by the local systems. Moreover, we observe the gradients of GNNs to be rather fluctuating in GCFL which impedes high-quality clustering, and design a gradient sequence-based clustering mechanism based on dynamic time warping (GCFL+). Extensive experimental results and in-depth analysis demonstrate the effectiveness of our proposed frameworks.