 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Language Difficulty in Dialogues with Linguistic Features
Sep 18, 2025Large language models (LLMs) have emerged as powerful tools for supporting second language acquisition, particularly in simulating interactive dialogues for speaking practice. However, adapting the language difficulty of LLM-generated responses to match learners' proficiency levels remains a challenge. This work addresses this issue by proposing a framework for controlling language proficiency in educational dialogue systems. Our approach leverages three categories of linguistic features, readability features (e.g., Flesch-Kincaid Grade Level), syntactic features (e.g., syntactic tree depth), and lexical features (e.g., simple word ratio), to quantify and regulate text complexity. We demonstrate that training LLMs on linguistically annotated dialogue data enables precise modulation of language proficiency, outperforming prompt-based methods in both flexibility and stability. To evaluate this, we introduce Dilaprix, a novel metric integrating the aforementioned features, which shows strong correlation with expert judgments of language difficulty. Empirical results reveal that our approach achieves superior controllability of language proficiency while maintaining high dialogue quality.
Point Cloud Video Anomaly Detection Based on Point Spatio-Temporal Auto-Encoder
Jun 04, 2023



Video anomaly detection has great potential in enhancing safety in the production and monitoring of crucial areas. Currently, most video anomaly detection methods are based on RGB modality, but its redundant semantic information may breach the privacy of residents or patients. The 3D data obtained by depth camera and LiDAR can accurately locate anomalous events in 3D space while preserving human posture and motion information. Identifying individuals through the point cloud is difficult due to its sparsity, which protects personal privacy. In this study, we propose Point Spatio-Temporal Auto-Encoder (PSTAE), an autoencoder framework that uses point cloud videos as input to detect anomalies in point cloud videos. We introduce PSTOp and PSTTransOp to maintain spatial geometric and temporal motion information in point cloud videos. To measure the reconstruction loss of the proposed autoencoder framework, we propose a reconstruction loss measurement strategy based on a shallow feature extractor. Experimental results on the TIMo dataset show that our method outperforms currently representative depth modality-based methods in terms of AUROC and has superior performance in detecting Medical Issue anomalies. These results suggest the potential of point cloud modality in video anomaly detection. Our method sets a new state-of-the-art (SOTA) on the TIMo dataset.
Context-aware Ensemble of Multifaceted Factorization Models for Recommendation Prediction in Social Networks
May 03, 2021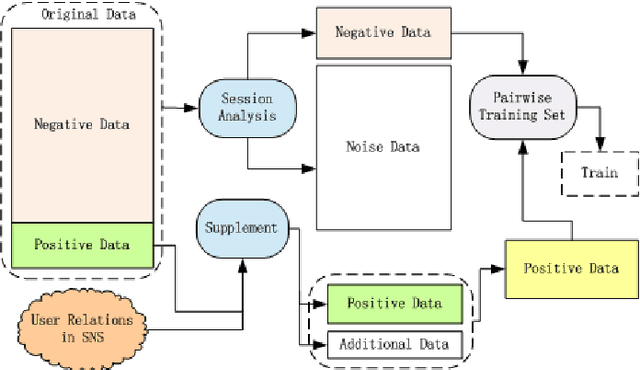
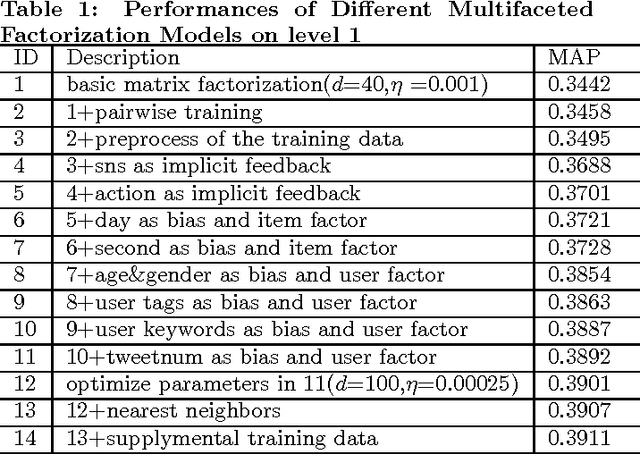
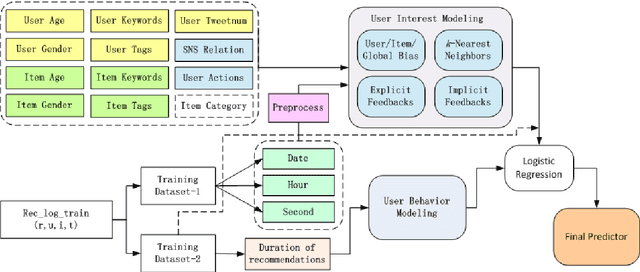

This paper describes the solution of Shanda Innovations team to Task 1 of KDD-Cup 2012. A novel approach called Multifaceted Factorization Models is proposed to incorporate a great variety of features in social networks. Social relationships and actions between users are integrated as implicit feedbacks to improve the recommendation accuracy. Keywords, tags, profiles, time and some other features are also utilized for modeling user interests. In addition, user behaviors are modeled from the durations of recommendation records. A context-aware ensemble framework is then applied to combine multiple predictors and produce final recommendation results. The proposed approach obtained 0.43959 (public score) / 0.41874 (private score) on the testing dataset, which achieved the 2nd place in the KDD-Cup competition.