 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CarSNN: An Efficient Spiking Neural Network for Event-Based Autonomous Cars on the Loihi Neuromorphic Research Processor
Jul 01, 2021
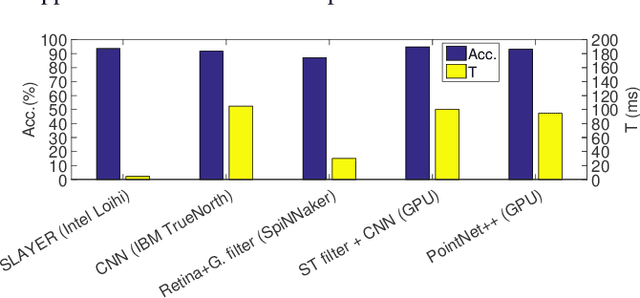

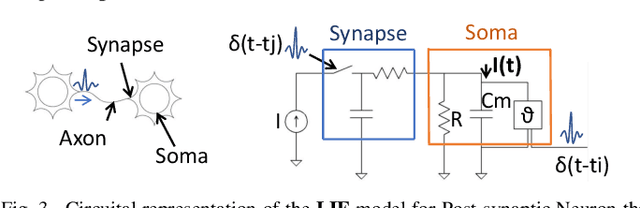
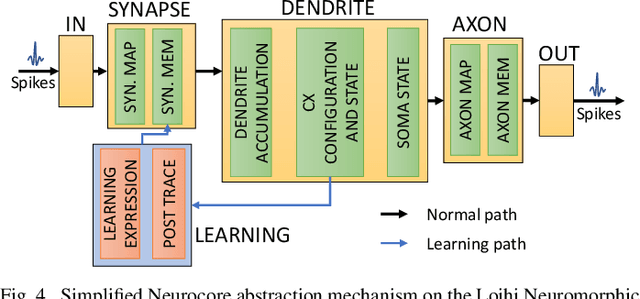
Autonomous Driving (AD) related features provide new forms of mobility that are also beneficial for other kind of intelligent and autonomous systems like robots, smart transportation, and smart industries. For these applications, the decisions need to be made fast and in real-time. Moreover, in the quest for electric mobility, this task must follow low power policy, without affecting much the autonomy of the mean of transport or the robot. These two challenges can be tackled using the emerging Spiking Neural Networks (SNNs). When deployed on a specialized neuromorphic hardware, SNNs can achieve high performance with low latency and low power consumption. In this paper, we use an SNN connected to an event-based camera for facing one of the key problems for AD, i.e., the classification between cars and other objects. To consume less power than traditional frame-based cameras, we use a Dynamic Vision Sensor (DVS). The experiments are made following an offline supervised learning rule, followed by mapping the learnt SNN model on the Intel Loihi Neuromorphic Research Chip. Our best experiment achieves an accuracy on offline implementation of 86%, that drops to 83% when it is ported onto the Loihi Chip. The Neuromorphic Hardware implementation has maximum 0.72 ms of latency for every sample, and consumes only 310 mW. To the best of our knowledge, this work is the first implementation of an event-based car classifier on a Neuromorphic Chip.
MAGI-X: Manifold-Constrained Gaussian Process Inference for Unknown System Dynamics
May 28, 2021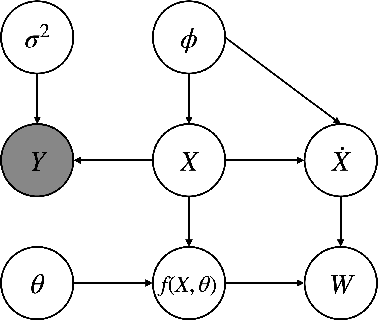
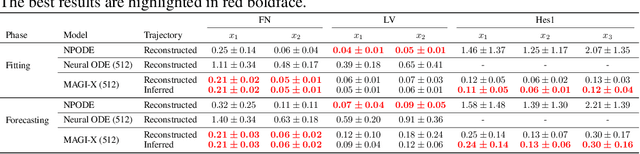
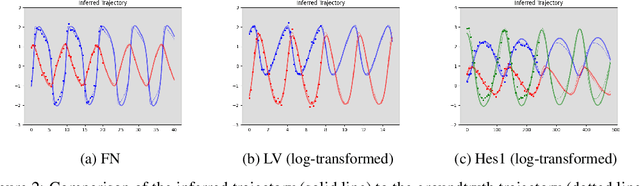

Ordinary differential equations (ODEs), commonly used to characterize the dynamic systems, are difficult to propose in closed-form for many complicated scientific applications, even with the help of domain expert. We propose a fast and accurate data-driven method, MAGI-X, to learn the unknown dynamic from the observation data in a non-parametric fashion, without the need of any domain knowledge. Unlike the existing methods that mainly rely on the costly numerical integration, MAGI-X utilizes the powerful functional approximator of neural network to learn the unknown nonlinear dynamic within the MAnifold-constrained Gaussian process Inference (MAGI) framework that completely circumvents the numerical integration. Comparing against the state-of-the-art methods on three realistic examples, MAGI-X achieves competitive accuracy in both fitting and forecasting while only taking a fraction of computational time. Moreover, MAGI-X provides practical solution for the inference of partial observed systems, which no previous method is able to handle.
eGHWT: The extended Generalized Haar-Walsh Transform
Jul 11, 2021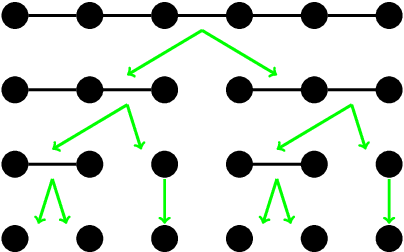
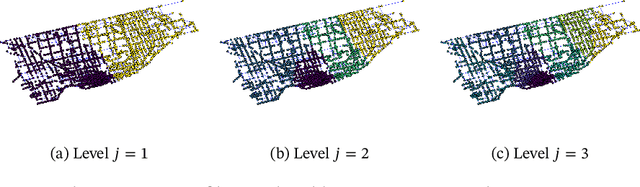
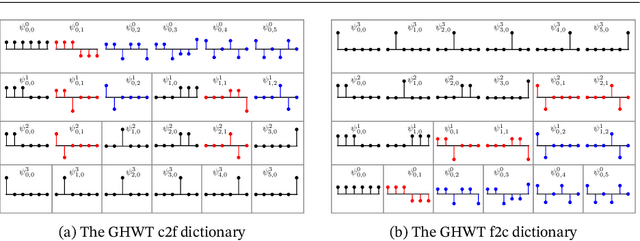

Extending computational harmonic analysis tools from the classical setting of regular lattices to the more general setting of graphs and networks is very important and much research has been done recently. The Generalized Haar-Walsh Transform (GHWT) developed by Irion and Saito (2014) is a multiscale transform for signals on graphs, which is a generalization of the classical Haar and Walsh-Hadamard Transforms. We propose the extended Generalized Haar-Walsh Transform (eGHWT), which is a generalization of the adapted time-frequency tilings of Thiele and Villemoes (1996). The eGHWT examines not only the efficiency of graph-domain partitions but also that of "sequency-domain" partitions simultaneously. Consequently, the eGHWT and its associated best-basis selection algorithm for graph signals significantly improve the performance of the previous GHWT with the similar computational cost, $O(N \log N)$, where $N$ is the number of nodes of an input graph. While the GHWT best-basis algorithm seeks the most suitable orthonormal basis for a given task among more than $(1.5)^N$ possible orthonormal bases in $\mathbb{R}^N$, the eGHWT best-basis algorithm can find a better one by searching through more than $0.618\cdot(1.84)^N$ possible orthonormal bases in $\mathbb{R}^N$. This article describes the details of the eGHWT best-basis algorithm and demonstrates its superiority using several examples including genuine graph signals as well as conventional digital images viewed as graph signals. Furthermore, we also show how the eGHWT can be extended to 2D signals and matrix-form data by viewing them as a tensor product of graphs generated from their columns and rows and demonstrate its effectiveness on applications such as image approximation.
Brain Signals to Rescue Aphasia, Apraxia and Dysarthria Speech Recognition
Feb 28, 2021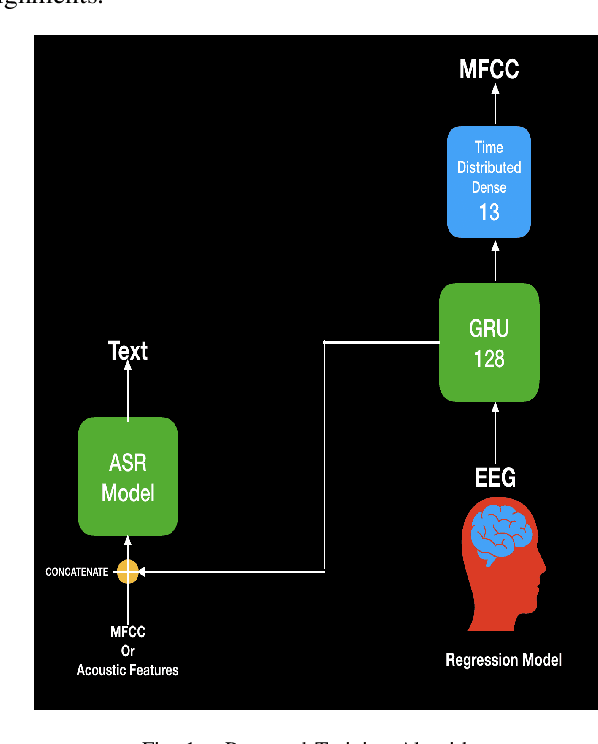
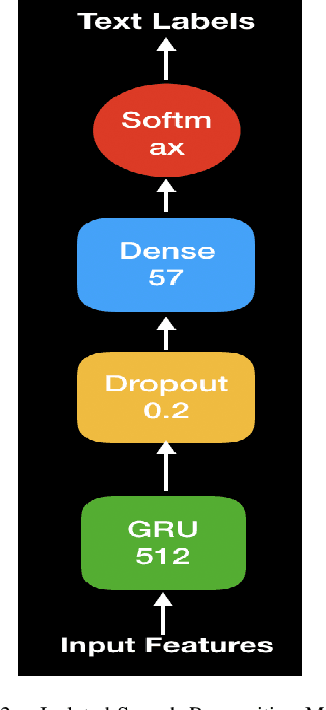
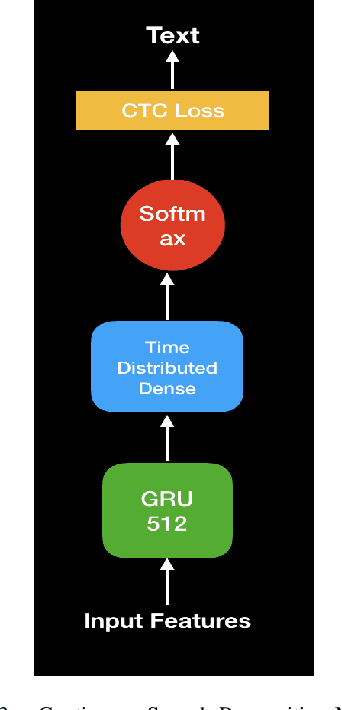
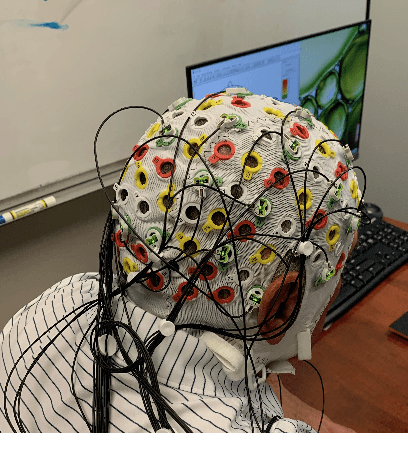
In this paper, we propose a deep learning-based algorithm to improve the performance of automatic speech recognition (ASR) systems for aphasia, apraxia, and dysarthria speech by utilizing electroencephalography (EEG) features recorded synchronously with aphasia, apraxia, and dysarthria speech. We demonstrate a significant decoding performance improvement by more than 50\% during test time for isolated speech recognition task and we also provide preliminary results indicating performance improvement for the more challenging continuous speech recognition task by utilizing EEG features. The results presented in this paper show the first step towards demonstrating the possibility of utilizing non-invasive neural signals to design a real-time robust speech prosthetic for stroke survivors recovering from aphasia, apraxia, and dysarthria. Our aphasia, apraxia, and dysarthria speech-EEG data set will be released to the public to help further advance this interesting and crucial research.
Streaming Social Event Detection and Evolution Discovery in Heterogeneous Information Networks
Apr 02, 2021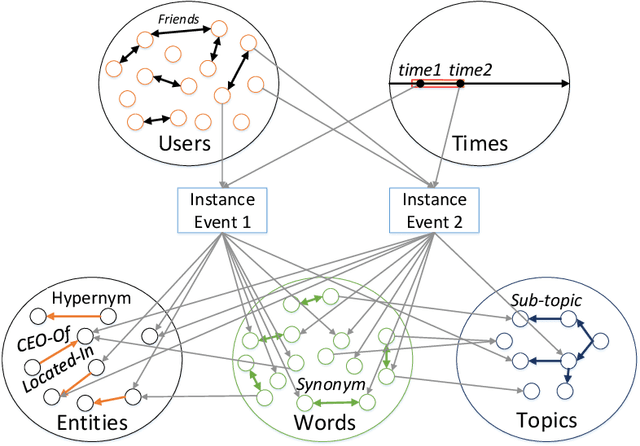
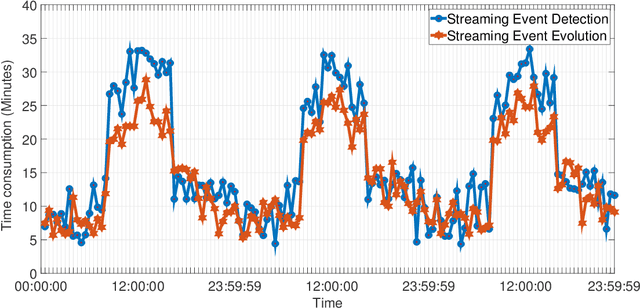
Events are happening in real-world and real-time, which can be planned and organized for occasions, such as social gatherings, festival celebrations, influential meetings or sports activities. Social media platforms generate a lot of real-time text information regarding public events with different topics. However, mining social events is challenging because events typically exhibit heterogeneous texture and metadata are often ambiguous. In this paper, we first design a novel event-based meta-schema to characterize the semantic relatedness of social events and then build an event-based heterogeneous information network (HIN) integrating information from external knowledge base. Second, we propose a novel Pairwise Popularity Graph Convolutional Network, named as PP-GCN, based on weighted meta-path instance similarity and textual semantic representation as inputs, to perform fine-grained social event categorization and learn the optimal weights of meta-paths in different tasks. Third, we propose a streaming social event detection and evolution discovery framework for HINs based on meta-path similarity search, historical information about meta-paths, and heterogeneous DBSCAN clustering method. Comprehensive experiments on real-world streaming social text data are conducted to compare various social event detection and evolution discovery algorithms. Experimental results demonstrate that our proposed framework outperforms other alternative social event detection and evolution discovery techniques.
Policy Transfer across Visual and Dynamics Domain Gaps via Iterative Grounding
Jul 01, 2021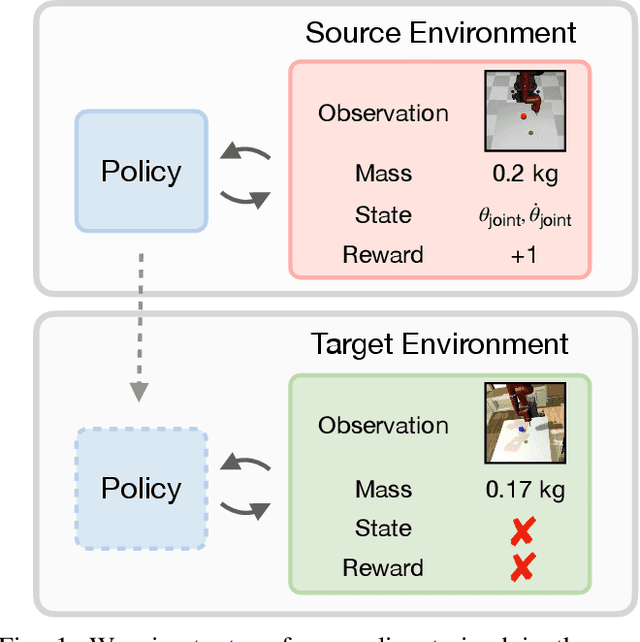
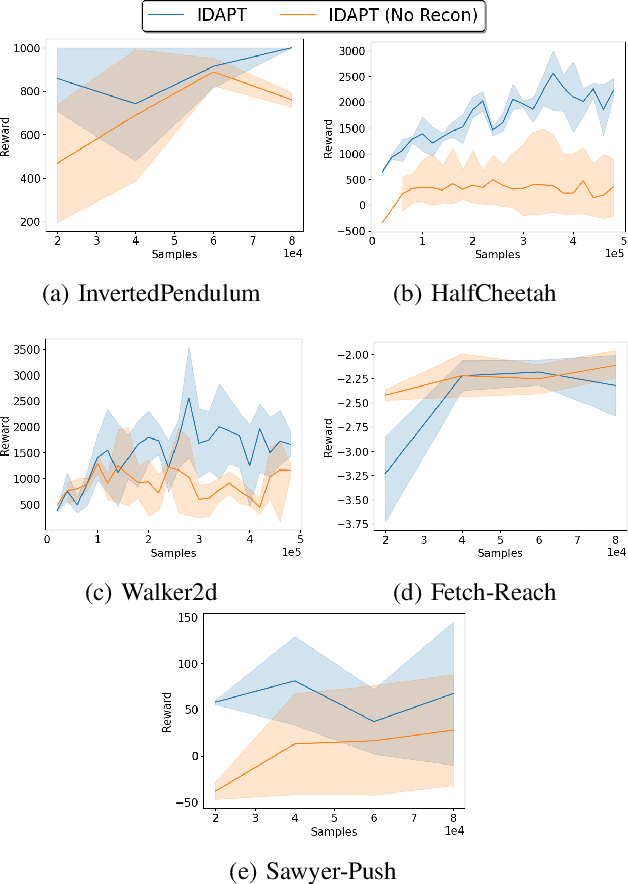
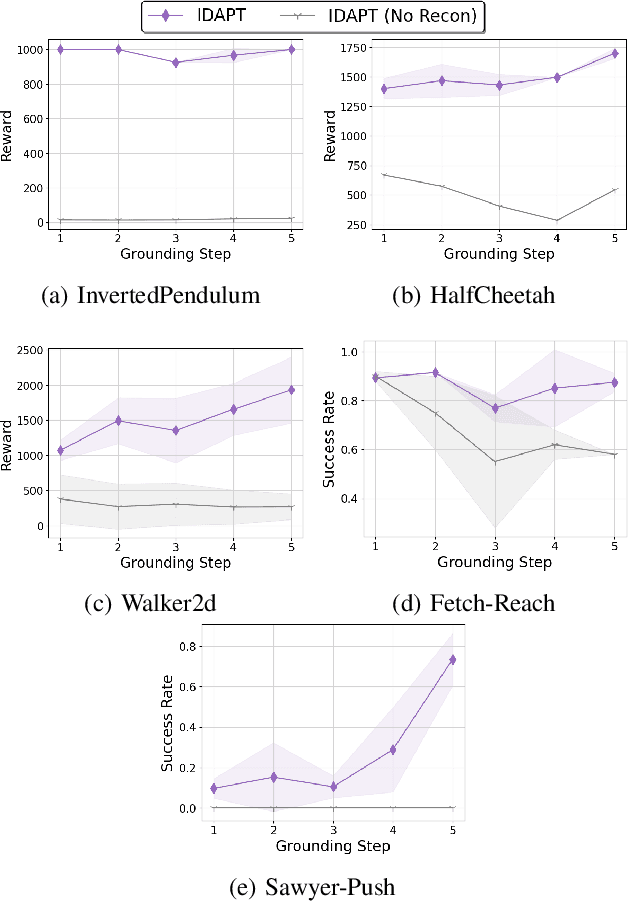
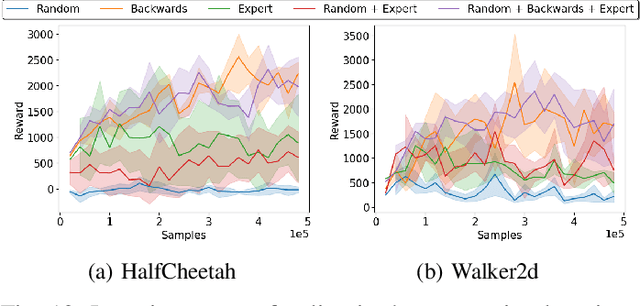
The ability to transfer a policy from one environment to another is a promising avenue for efficient robot learning in realistic settings where task supervision is not available. This can allow us to take advantage of environments well suited for training, such as simulators or laboratories, to learn a policy for a real robot in a home or office. To succeed, such policy transfer must overcome both the visual domain gap (e.g. different illumination or background) and the dynamics domain gap (e.g. different robot calibration or modelling error) between source and target environments. However, prior policy transfer approaches either cannot handle a large domain gap or can only address one type of domain gap at a time. In this paper, we propose a novel policy transfer method with iterative "environment grounding", IDAPT, that alternates between (1) directly minimizing both visual and dynamics domain gaps by grounding the source environment in the target environment domains, and (2) training a policy on the grounded source environment. This iterative training progressively aligns the domains between the two environments and adapts the policy to the target environment. Once trained, the policy can be directly executed on the target environment. The empirical results on locomotion and robotic manipulation tasks demonstrate that our approach can effectively transfer a policy across visual and dynamics domain gaps with minimal supervision and interaction with the target environment. Videos and code are available at https://clvrai.com/idapt .
Move Beyond Trajectories: Distribution Space Coupling for Crowd Navigation
Jun 25, 2021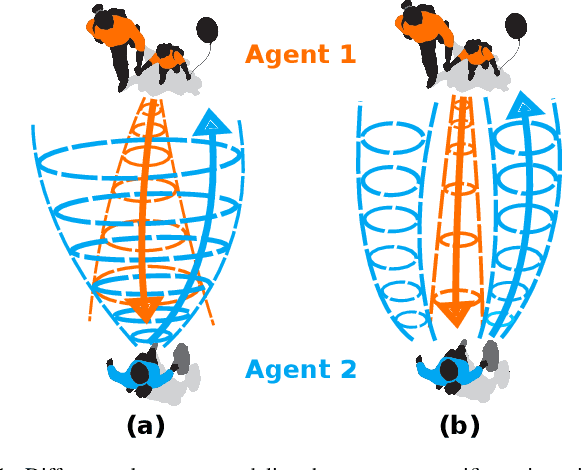
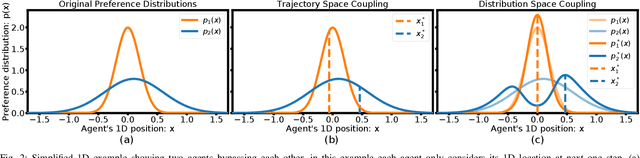
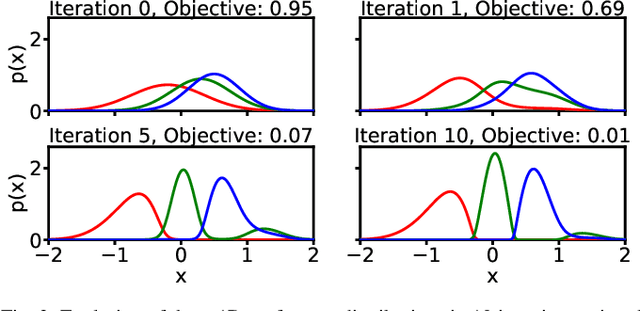
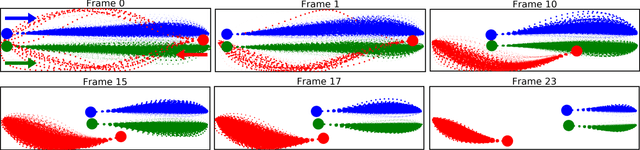
Cooperatively avoiding collision is a critical functionality for robots navigating in dense human crowds, failure of which could lead to either overaggressive or overcautious behavior. A necessary condition for cooperative collision avoidance is to couple the prediction of the agents' trajectories with the planning of the robot's trajectory. However, it is unclear that trajectory based cooperative collision avoidance captures the correct agent attributes. In this work we migrate from trajectory based coupling to a formalism that couples agent preference distributions. In particular, we show that preference distributions (probability density functions representing agents' intentions) can capture higher order statistics of agent behaviors, such as willingness to cooperate. Thus, coupling in distribution space exploits more information about inter-agent cooperation than coupling in trajectory space. We thus introduce a general objective for coupled prediction and planning in distribution space, and propose an iterative best response optimization method based on variational analysis with guaranteed sufficient decrease. Based on this analysis, we develop a sampling-based motion planning framework called DistNav that runs in real time on a laptop CPU. We evaluate our approach on challenging scenarios from both real world datasets and simulation environments, and benchmark against a wide variety of model based and machine learning based approaches. The safety and efficiency statistics of our approach outperform all other models. Finally, we find that DistNav is competitive with human safety and efficiency performance.
* 12 pages
Automatic Product Ontology Extraction from Textual Reviews
May 23, 2021
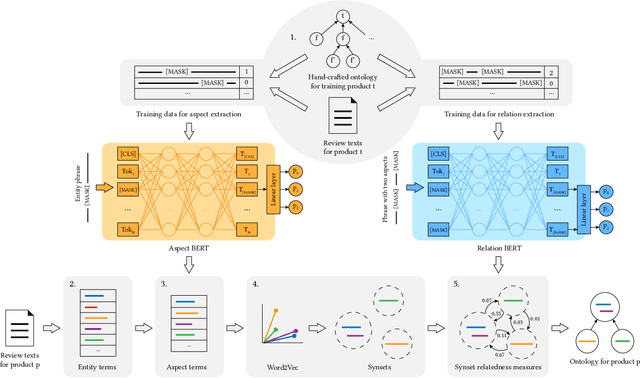
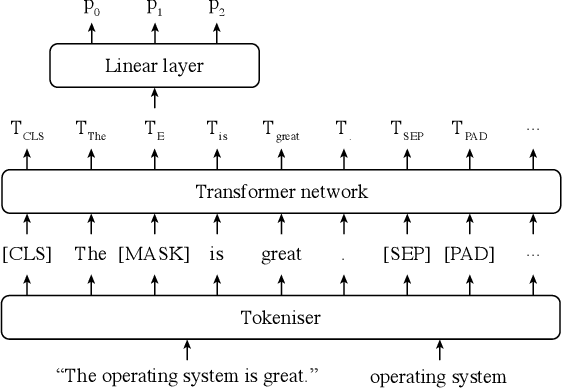
Ontologies have proven beneficial in different settings that make use of textual reviews. However, manually constructing ontologies is a laborious and time-consuming process in need of automation. We propose a novel methodology for automatically extracting ontologies, in the form of meronomies, from product reviews, using a very limited amount of hand-annotated training data. We show that the ontologies generated by our method outperform hand-crafted ontologies (WordNet) and ontologies extracted by existing methods (Text2Onto and COMET) in several, diverse settings. Specifically, our generated ontologies outperform the others when evaluated by human annotators as well as on an existing Q&A dataset from Amazon. Moreover, our method is better able to generalise, in capturing knowledge about unseen products. Finally, we consider a real-world setting, showing that our method is better able to determine recommended products based on their reviews, in alternative to using Amazon's standard score aggregations.
Decreasing scaling transition from adaptive gradient descent to stochastic gradient descent
Jun 12, 2021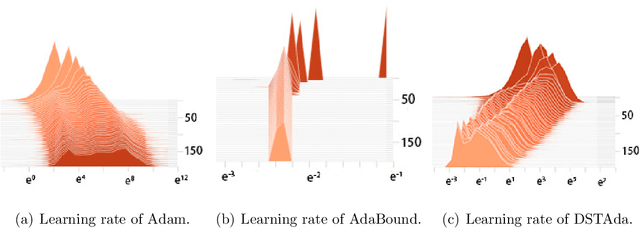

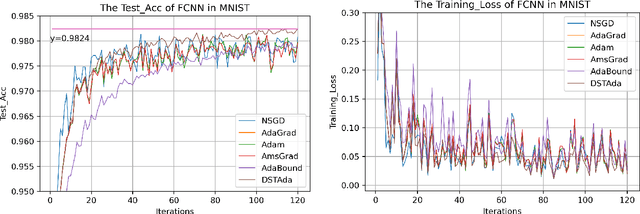

Currently, researchers have proposed the adaptive gradient descent algorithm and its variants, such as AdaGrad, RMSProp, Adam, AmsGrad, etc. Although these algorithms have a faster speed in the early stage, the generalization ability in the later stage of training is often not as good as the stochastic gradient descent. Recently, some researchers have combined the adaptive gradient descent and stochastic gradient descent to obtain the advantages of both and achieved good results. Based on this research, we propose a decreasing scaling transition from adaptive gradient descent to stochastic gradient descent method(DSTAda). For the training stage of the stochastic gradient descent, we use a learning rate that decreases linearly with the number of iterations instead of a constant learning rate. We achieve a smooth and stable transition from adaptive gradient descent to stochastic gradient descent through scaling. At the same time, we give a theoretical proof of the convergence of DSTAda under the framework of online learning. Our experimental results show that the DSTAda algorithm has a faster convergence speed, higher accuracy, and better stability and robustness. Our implementation is available at: https://github.com/kunzeng/DSTAdam.
An Adiabatic Theorem for Policy Tracking with TD-learning
Oct 30, 2020We evaluate the ability of temporal difference learning to track the reward function of a policy as it changes over time. Our results apply a new adiabatic theorem that bounds the mixing time of time-inhomogeneous Markov chains. We derive finite-time bounds for tabular temporal difference learning and $Q$-learning when the policy used for training changes in time. To achieve this, we develop bounds for stochastic approximation under asynchronous adiabatic updates.