 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Knowledge Distillation in Post-Training: When It Helps and When It Fails
Jun 22, 2026Large language models (LLMs) achieve strong performance across many tasks, but their high computational cost limits deployment in resource-constrained environments. Knowledge Distillation (KD) offers a practical solution by transferring knowledge from a teacher model of a larger size to a smaller student model. While prior work has mainly examined task-specific or small-scale settings, the post-training stage for building general instruction-following models has received limited attention. In this paper, we conduct a systematic study of KD in post-training using the large-scale Tulu 3 dataset. We find that KD outperforms supervised fine-tuning (SFT) in low-data regimes, but its advantage diminishes as more training data is added. Distilling from a stronger instruction-tuned teacher restores substantial gains even with abundant data, indicating that KD remains effective when the teacher provides knowledge that the student cannot easily acquire from the training data alone. We further study domain-specific, low-resource scenarios and propose a two-stage KD strategy that leverages synthetic teacher-labeled data followed by refinement on human annotations. This method consistently improves student performance, providing practical guidance for building compact models in data-scarce environments.
CM2: Reinforcement Learning with Checklist Rewards for Multi-Turn and Multi-Step Agentic Tool Use
Feb 12, 2026AI agents are increasingly used to solve real-world tasks by reasoning over multi-turn user interactions and invoking external tools. However, applying reinforcement learning to such settings remains difficult: realistic objectives often lack verifiable rewards and instead emphasize open-ended behaviors; moreover, RL for multi-turn, multi-step agentic tool use is still underexplored; and building and maintaining executable tool environments is costly, limiting scale and coverage. We propose CM2, an RL framework that replaces verifiable outcome rewards with checklist rewards. CM2 decomposes each turn's intended behavior into fine-grained binary criteria with explicit evidence grounding and structured metadata, turning open-ended judging into more stable classification-style decisions. To balance stability and informativeness, our method adopts a strategy of sparse reward assignment but dense evaluation criteria. Training is performed in a scalable LLM-simulated tool environment, avoiding heavy engineering for large tool sets. Experiments show that CM2 consistently improves over supervised fine-tuning. Starting from an 8B Base model and training on an 8k-example RL dataset, CM2 improves over the SFT counterpart by 8 points on tau^-Bench, by 10 points on BFCL-V4, and by 12 points on ToolSandbox. The results match or even outperform similarly sized open-source baselines, including the judging model. CM2 thus provides a scalable recipe for optimizing multi-turn, multi-step tool-using agents without relying on verifiable rewards. Code provided by the open-source community: https://github.com/namezhenzhang/CM2-RLCR-Tool-Agent.
Taming SQL Complexity: LLM-Based Equivalence Evaluation for Text-to-SQL
Jun 11, 2025The rise of Large Language Models (LLMs) has significantly advanced Text-to-SQL (NL2SQL) systems, yet evaluating the semantic equivalence of generated SQL remains a challenge, especially given ambiguous user queries and multiple valid SQL interpretations. This paper explores using LLMs to assess both semantic and a more practical "weak" semantic equivalence. We analyze common patterns of SQL equivalence and inequivalence, discuss challenges in LLM-based evaluation.
Inverse Probability of Treatment Weighting with Deep Sequence Models Enables Accurate treatment effect Estimation from Electronic Health Records
Jun 13, 2024



Observational data have been actively used to estimate treatment effect, driven by the growing availability of electronic health records (EHRs). However, EHRs typically consist of longitudinal records, often introducing time-dependent confoundings that hinder the unbiased estimation of treatment effect. Inverse probability of treatment weighting (IPTW) is a widely used propensity score method since it provides unbiased treatment effect estimation and its derivation is straightforward. In this study, we aim to utilize IPTW to estimate treatment effect in the presence of time-dependent confounding using claims records. Previous studies have utilized propensity score methods with features derived from claims records through feature processing, which generally requires domain knowledge and additional resources to extract information to accurately estimate propensity scores. Deep sequence models, particularly recurrent neural networks and self-attention-based architectures, have demonstrated good performance in modeling EHRs for various downstream tasks. We propose that these deep sequence models can provide accurate IPTW estimation of treatment effect by directly estimating the propensity scores from claims records without the need for feature processing. We empirically demonstrate this by conducting comprehensive evaluations using synthetic and semi-synthetic datasets.
Deep Attention Q-Network for Personalized Treatment Recommendation
Jul 04, 2023



Tailoring treatment for individual patients is crucial yet challenging in order to achieve optimal healthcare outcomes. Recent advances in reinforcement learning offer promising personalized treatment recommendations; however, they rely solely on current patient observations (vital signs, demographics) as the patient's state, which may not accurately represent the true health status of the patient. This limitation hampers policy learning and evaluation, ultimately limiting treatment effectiveness. In this study, we propose the Deep Attention Q-Network for personalized treatment recommendations, utilizing the Transformer architecture within a deep reinforcement learning framework to efficiently incorporate all past patient observations. We evaluated the model on real-world sepsis and acute hypotension cohorts, demonstrating its superiority to state-of-the-art models. The source code for our model is available at https://github.com/stevenmsm/RL-ICU-DAQN.
COVID-19 Hospitalizations Forecasts Using Internet Search Data
Feb 03, 2022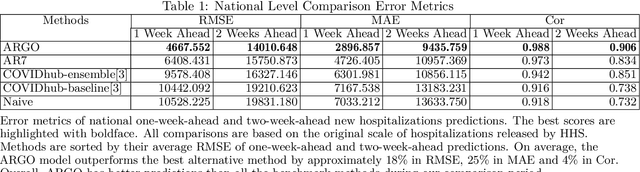
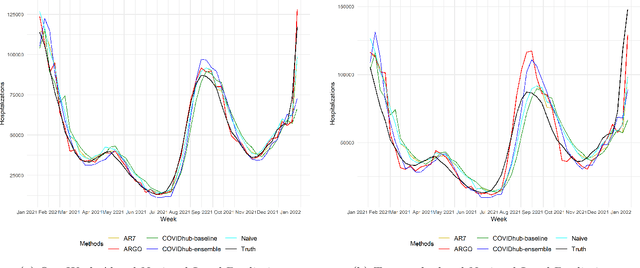
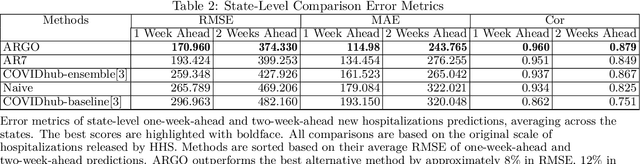
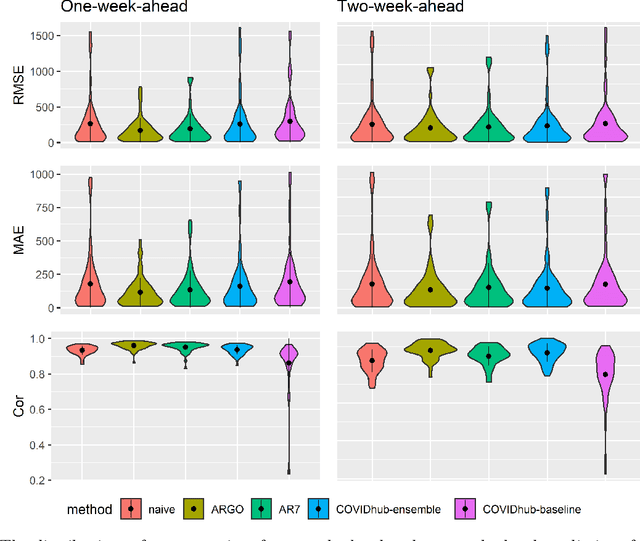
As the COVID-19 spread over the globe and new variants of COVID-19 keep occurring, reliable real-time forecasts of COVID-19 hospitalizations are critical for public health decision on medical resources allocations such as ICU beds, ventilators, and personnel to prepare for the surge of COVID-19 pandemics. Inspired by the strong association between public search behavior and hospitalization admission, we extended previously-proposed influenza tracking model, ARGO (AutoRegression with GOogle search data), to predict future 2-week national and state-level COVID-19 new hospital admissions. Leveraging the COVID-19 related time series information and Google search data, our method is able to robustly capture new COVID-19 variants' surges, and self-correct at both national and state level. Based on our retrospective out-of-sample evaluation over 12-month comparison period, our method achieves on average 15\% error reduction over the best alternative models collected from COVID-19 forecast hub. Overall, we showed that our method is flexible, self-correcting, robust, accurate, and interpretable, making it a potentially powerful tool to assist health-care officials and decision making for the current and future infectious disease outbreak.
MAGI-X: Manifold-Constrained Gaussian Process Inference for Unknown System Dynamics
May 28, 2021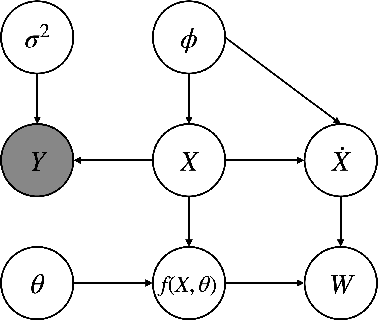
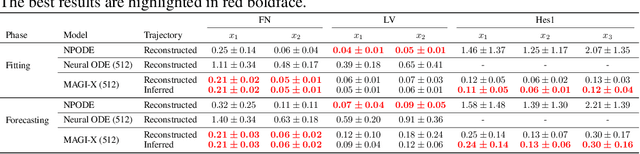
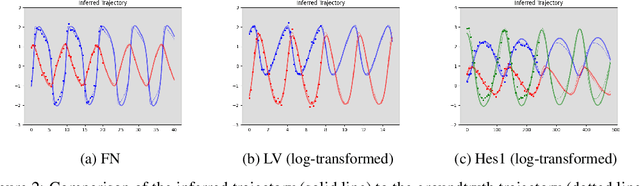

Ordinary differential equations (ODEs), commonly used to characterize the dynamic systems, are difficult to propose in closed-form for many complicated scientific applications, even with the help of domain expert. We propose a fast and accurate data-driven method, MAGI-X, to learn the unknown dynamic from the observation data in a non-parametric fashion, without the need of any domain knowledge. Unlike the existing methods that mainly rely on the costly numerical integration, MAGI-X utilizes the powerful functional approximator of neural network to learn the unknown nonlinear dynamic within the MAnifold-constrained Gaussian process Inference (MAGI) framework that completely circumvents the numerical integration. Comparing against the state-of-the-art methods on three realistic examples, MAGI-X achieves competitive accuracy in both fitting and forecasting while only taking a fraction of computational time. Moreover, MAGI-X provides practical solution for the inference of partial observed systems, which no previous method is able to handle.