 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tool for Generating Exceptional Behavior Tests With Large Language Models
May 28, 2025Exceptional behavior tests (EBTs) are crucial in software development for verifying that code correctly handles unwanted events and throws appropriate exceptions. However, prior research has shown that developers often prioritize testing "happy paths", e.g., paths without unwanted events over exceptional scenarios. We present exLong, a framework that automatically generates EBTs to address this gap. exLong leverages a large language model (LLM) fine-tuned from CodeLlama and incorporates reasoning about exception-throwing traces, conditional expressions that guard throw statements, and non-exceptional behavior tests that execute similar traces. Our demonstration video illustrates how exLong can effectively assist developers in creating comprehensive EBTs for their project (available at https://youtu.be/Jro8kMgplZk).
Hierarchical Neural Program Synthesis
Mar 09, 2023



Program synthesis aims to automatically construct human-readable programs that satisfy given task specifications, such as input/output pairs or demonstrations. Recent works have demonstrated encouraging results in a variety of domains, such as string transformation, tensor manipulation, and describing behaviors of embodied agents. Most existing program synthesis methods are designed to synthesize programs from scratch, generating a program token by token, line by line. This fundamentally prevents these methods from scaling up to synthesize programs that are longer or more complex. In this work, we present a scalable program synthesis framework that instead synthesizes a program by hierarchically composing programs. Specifically, we first learn a task embedding space and a program decoder that can decode a task embedding into a program. Then, we train a high-level module to comprehend the task specification (e.g., input/output pairs or demonstrations) from long programs and produce a sequence of task embeddings, which are then decoded by the program decoder and composed to yield the synthesized program. We extensively evaluate our proposed framework in a string transformation domain with input/output pairs. The experimental results demonstrate that the proposed framework can synthesize programs that are significantly longer and more complex than the programs considered in prior program synthesis works. Website at https://thoughtp0lice.github.io/hnps_web/
Policy Transfer across Visual and Dynamics Domain Gaps via Iterative Grounding
Jul 01, 2021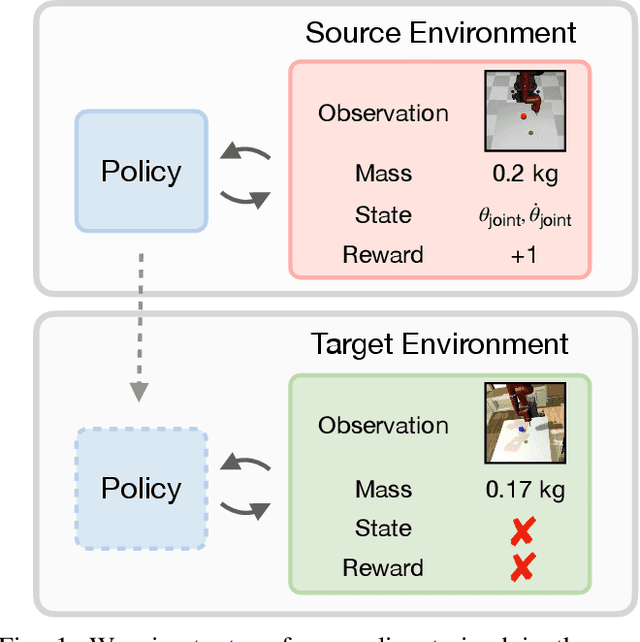
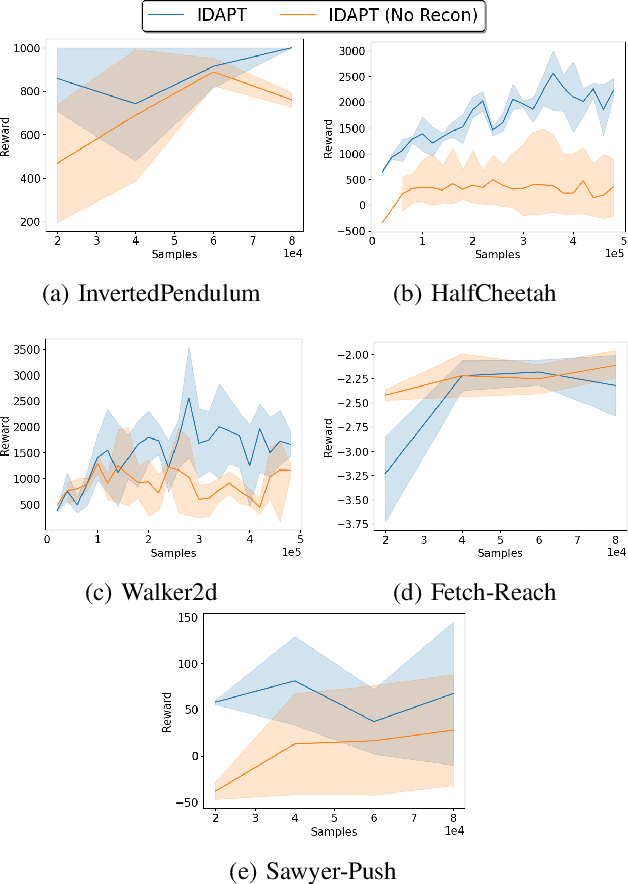
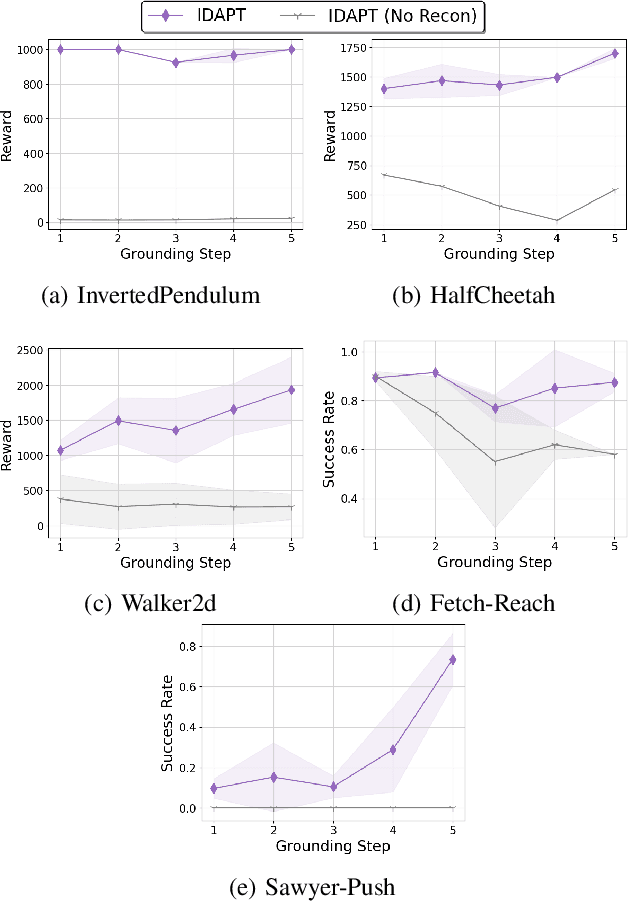
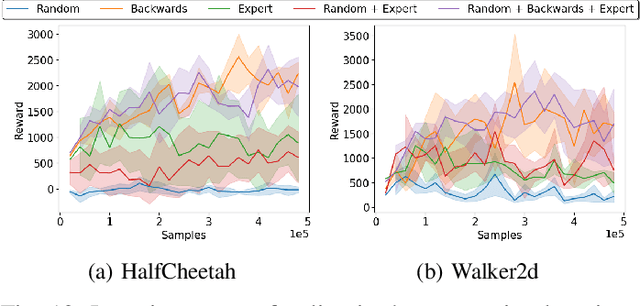
The ability to transfer a policy from one environment to another is a promising avenue for efficient robot learning in realistic settings where task supervision is not available. This can allow us to take advantage of environments well suited for training, such as simulators or laboratories, to learn a policy for a real robot in a home or office. To succeed, such policy transfer must overcome both the visual domain gap (e.g. different illumination or background) and the dynamics domain gap (e.g. different robot calibration or modelling error) between source and target environments. However, prior policy transfer approaches either cannot handle a large domain gap or can only address one type of domain gap at a time. In this paper, we propose a novel policy transfer method with iterative "environment grounding", IDAPT, that alternates between (1) directly minimizing both visual and dynamics domain gaps by grounding the source environment in the target environment domains, and (2) training a policy on the grounded source environment. This iterative training progressively aligns the domains between the two environments and adapts the policy to the target environment. Once trained, the policy can be directly executed on the target environment. The empirical results on locomotion and robotic manipulation tasks demonstrate that our approach can effectively transfer a policy across visual and dynamics domain gaps with minimal supervision and interaction with the target environment. Videos and code are available at https://clvrai.com/idapt .