 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantic Segmentation with Generative Models: Semi-Supervised Learning and Strong Out-of-Domain Generalization
Apr 12, 2021




Training deep networks with limited labeled data while achieving a strong generalization ability is key in the quest to reduce human annotation efforts. This is the goal of semi-supervised learning, which exploits more widely available unlabeled data to complement small labeled data sets. In this paper, we propose a novel framework for discriminative pixel-level tasks using a generative model of both images and labels. Concretely, we learn a generative adversarial network that captures the joint image-label distribution and is trained efficiently using a large set of unlabeled images supplemented with only few labeled ones. We build our architecture on top of StyleGAN2, augmented with a label synthesis branch. Image labeling at test time is achieved by first embedding the target image into the joint latent space via an encoder network and test-time optimization, and then generating the label from the inferred embedding. We evaluate our approach in two important domains: medical image segmentation and part-based face segmentation. We demonstrate strong in-domain performance compared to several baselines, and are the first to showcase extreme out-of-domain generalization, such as transferring from CT to MRI in medical imaging, and photographs of real faces to paintings, sculptures, and even cartoons and animal faces. Project Page: \url{https://nv-tlabs.github.io/semanticGAN/}
Internet of Things (IoT) Based Video Analytics: a use case of Smart Doorbell
May 13, 2021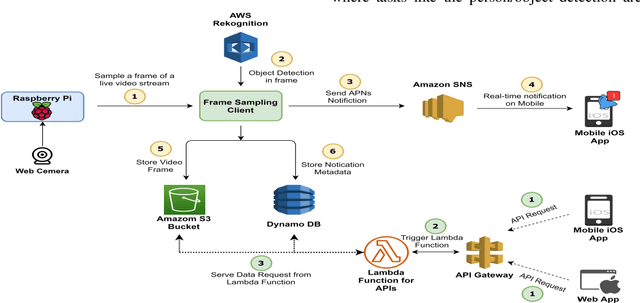

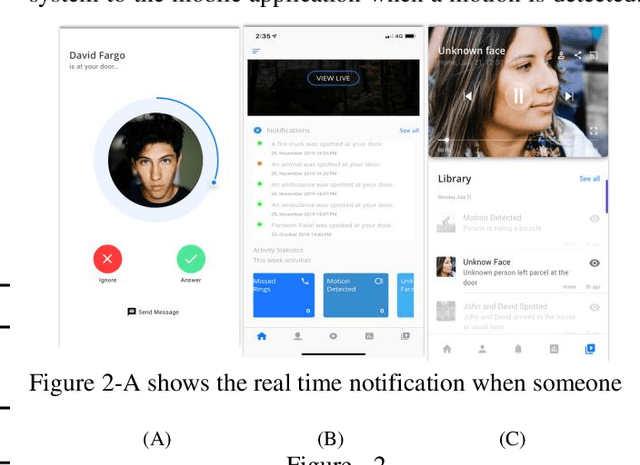
The vision of the internet of things (IoT) is a reality now. IoT devices are getting cheaper, smaller. They are becoming more and more computationally and energy-efficient. The global market of IoT-based video analytics has seen significant growth in recent years and it is expected to be a growing market segment. For any IoT-based video analytics application, few key points required, such as cost-effectiveness, widespread use, flexible design, accurate scene detection, reusability of the framework. Video-based smart doorbell system is one such application domain for video analytics where many commercial offerings are available in the consumer market. However, such existing offerings are costly, monolithic, and proprietary. Also, there will be a trade-off between accuracy and portability. To address the foreseen problems, I'm proposing a distributed framework for video analytics with a use case of a smart doorbell system. The proposed framework uses AWS cloud services as a base platform and to meet the price affordability constraint, the system was implemented on affordable Raspberry Pi. The smart doorbell will be able to recognize the known/unknown person with at most accuracy. The smart doorbell system is also having additional detection functionalities such as harmful weapon detection, noteworthy vehicle detection, animal/pet detection. An iOS application is specifically developed for this implementation which can receive the notification from the smart doorbell in real-time. Finally, the paper also mentions the classical approaches for video analytics, their feasibility in implementing with this use-case, and comparative analysis in terms of accuracy and time required to detect an object in the frame is carried out. Results conclude that AWS cloud-based approach is worthy for this smart doorbell use case.
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Jul 05, 2021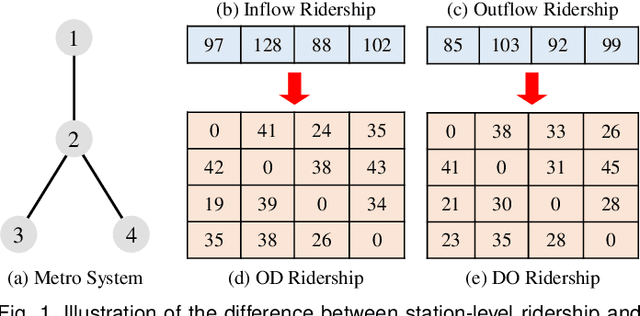
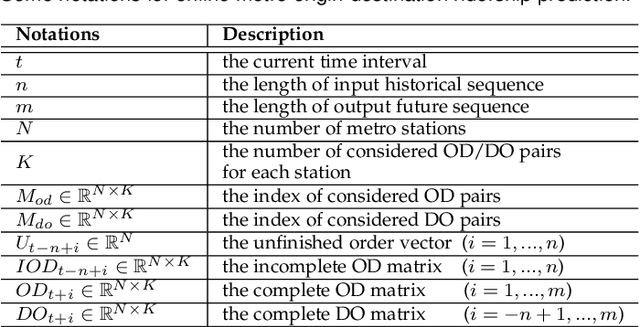
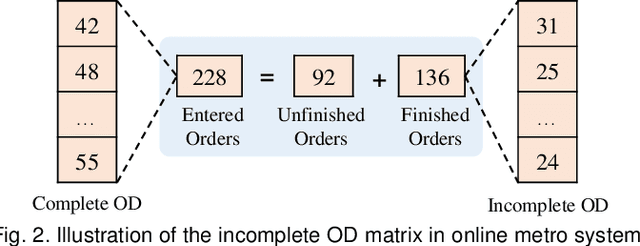
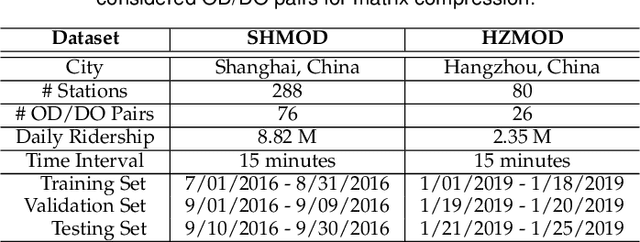
Metro origin-destination prediction is a crucial yet challenging task for intelligent transportation management, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.
PatentMiner: Patent Vacancy Mining via Context-enhanced and Knowledge-guided Graph Attention
Jul 10, 2021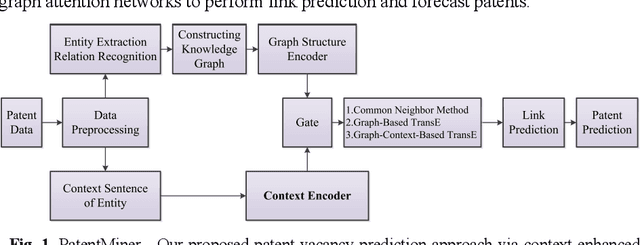
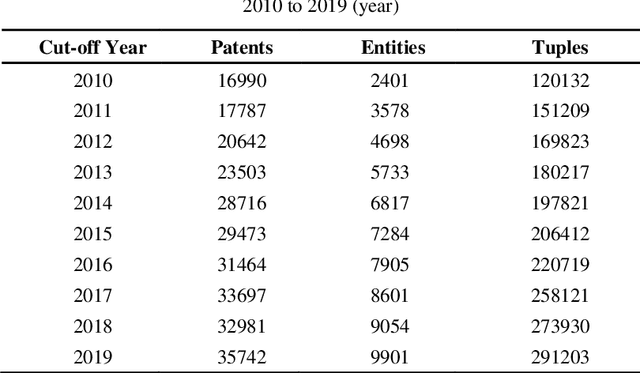
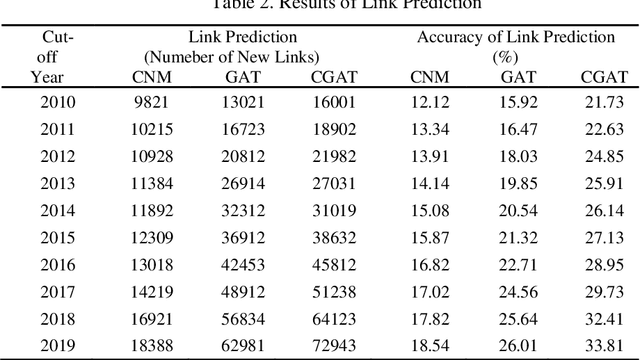
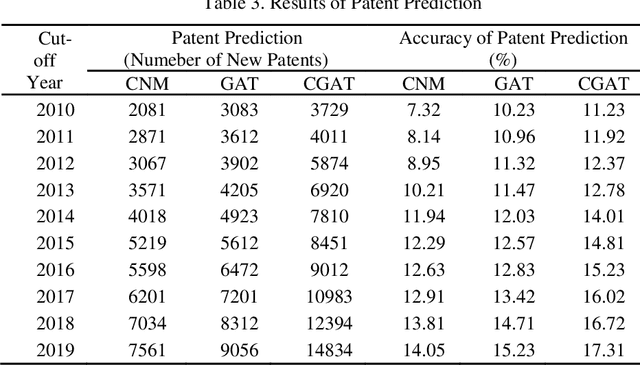
Although there are a small number of work to conduct patent research by building knowledge graph, but without constructing patent knowledge graph using patent documents and combining latest natural language processing methods to mine hidden rich semantic relationships in existing patents and predict new possible patents. In this paper, we propose a new patent vacancy prediction approach named PatentMiner to mine rich semantic knowledge and predict new potential patents based on knowledge graph (KG) and graph attention mechanism. Firstly, patent knowledge graph over time (e.g. year) is constructed by carrying out named entity recognition and relation extrac-tion from patent documents. Secondly, Common Neighbor Method (CNM), Graph Attention Networks (GAT) and Context-enhanced Graph Attention Networks (CGAT) are proposed to perform link prediction in the constructed knowledge graph to dig out the potential triples. Finally, patents are defined on the knowledge graph by means of co-occurrence relationship, that is, each patent is represented as a fully connected subgraph containing all its entities and co-occurrence relationships of the patent in the knowledge graph; Furthermore, we propose a new patent prediction task which predicts a fully connected subgraph with newly added prediction links as a new pa-tent. The experimental results demonstrate that our proposed patent predic-tion approach can correctly predict new patents and Context-enhanced Graph Attention Networks is much better than the baseline. Meanwhile, our proposed patent vacancy prediction task still has significant room to im-prove.
Automating Speedrun Routing: Overview and Vision
Jun 02, 2021Speedrunning in general means to play a video game fast, i.e. using all means at one's disposal to achieve a given goal in the least amount of time possible. To do so, a speedrun must be planned in advance, or routed, as it is referred to by the community. This paper focuses on discovering challenges and defining models needed when trying to approach the problem of routing algorithmically. It provides an overview of relevant speedrunning literature, extracting vital information and formulating criticism. Important categorizations are pointed out and a nomenclature is build to support professional discussion. Different concepts of graph representations are presented and their potential is discussed with regard to solving the speedrun routing optimization problem. Visions both for problem modeling as well as solving are presented and assessed regarding suitability and expected challenges. This results in a vision of potential solutions and what will be addressed in the future.
Localization and Tracking of User-Defined Points on Deformable Objects for Robotic Manipulation
May 19, 2021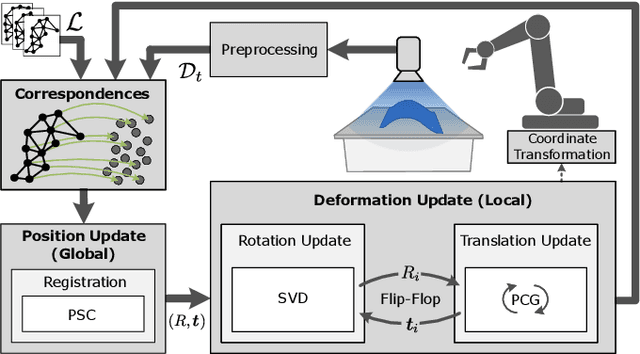
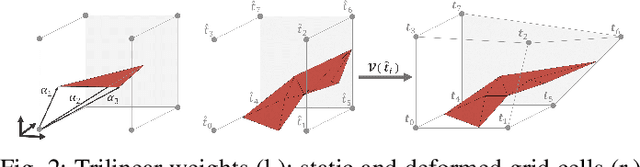
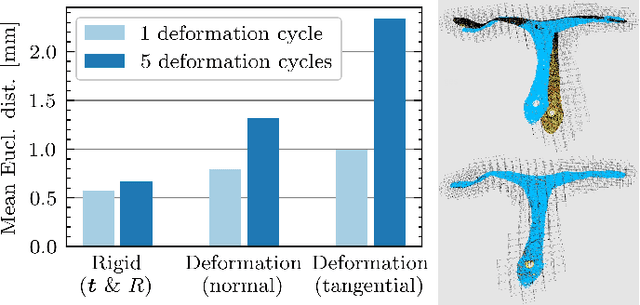

This paper introduces an efficient procedure to localize user-defined points on the surface of deformable objects and track their positions in 3D space over time. To cope with a deformable object's infinite number of DOF, we propose a discretized deformation field, which is estimated during runtime using a multi-step non-linear solver pipeline. The resulting high-dimensional energy minimization problem describes the deviation between an offline-defined reference model and a pre-processed camera image. An additional regularization term allows for assumptions about the object's hidden areas and increases the solver's numerical stability. Our approach is capable of solving the localization problem online in a data-parallel manner, making it ideally suitable for the perception of non-rigid objects in industrial manufacturing processes.
Face Age Progression With Attribute Manipulation
Jun 14, 2021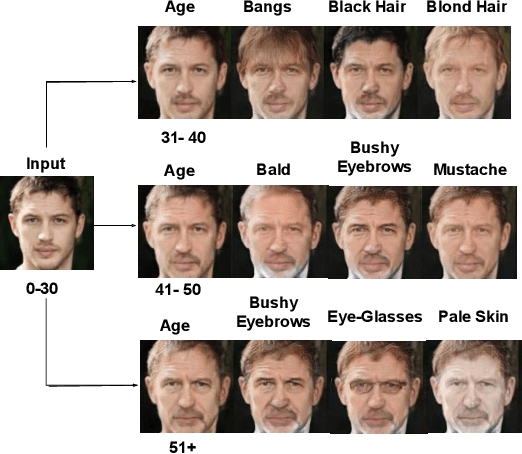
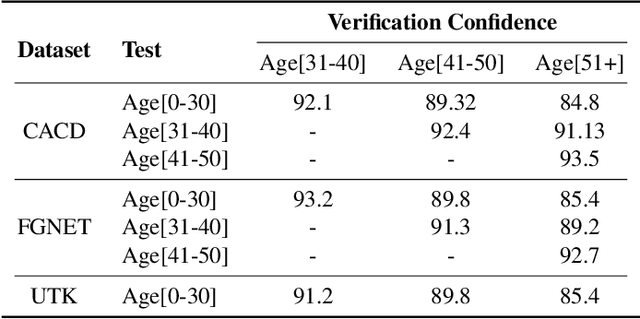
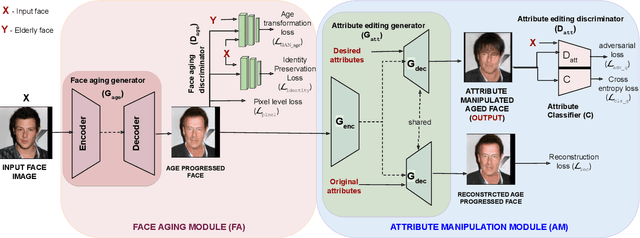
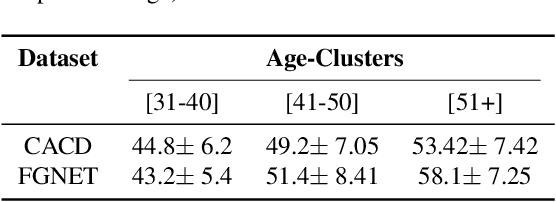
Face is one of the predominant means of person recognition. In the process of ageing, human face is prone to many factors such as time, attributes, weather and other subject specific variations. The impact of these factors were not well studied in the literature of face aging. In this paper, we propose a novel holistic model in this regard viz., ``Face Age progression With Attribute Manipulation (FAWAM)", i.e. generating face images at different ages while simultaneously varying attributes and other subject specific characteristics. We address the task in a bottom-up manner, as two submodules i.e. face age progression and face attribute manipulation. For face aging, we use an attribute-conscious face aging model with a pyramidal generative adversarial network that can model age-specific facial changes while maintaining intrinsic subject specific characteristics. For facial attribute manipulation, the age processed facial image is manipulated with desired attributes while preserving other details unchanged, leveraging an attribute generative adversarial network architecture. We conduct extensive analysis in standard large scale datasets and our model achieves significant performance both quantitatively and qualitatively.
Robust non-parametric mortality and fertility modelling and forecasting: Gaussian process regression approaches
Feb 18, 2021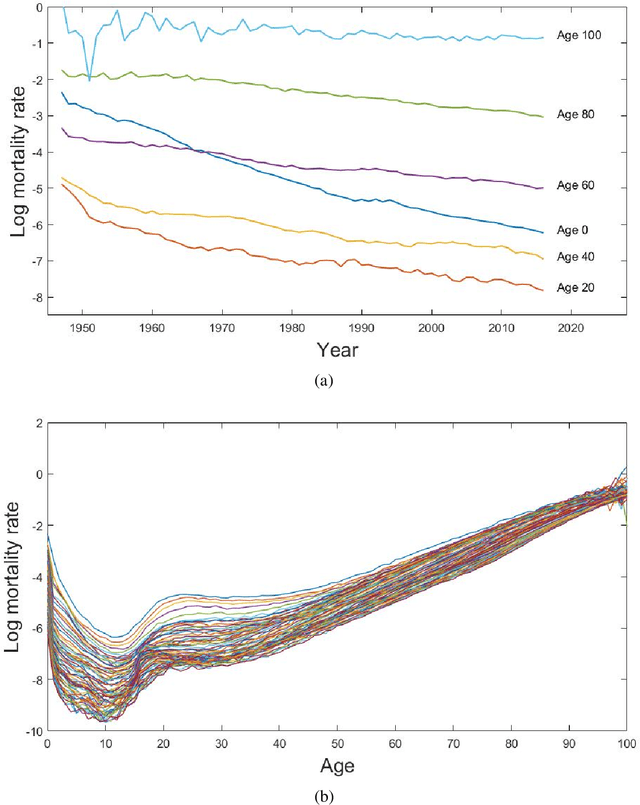
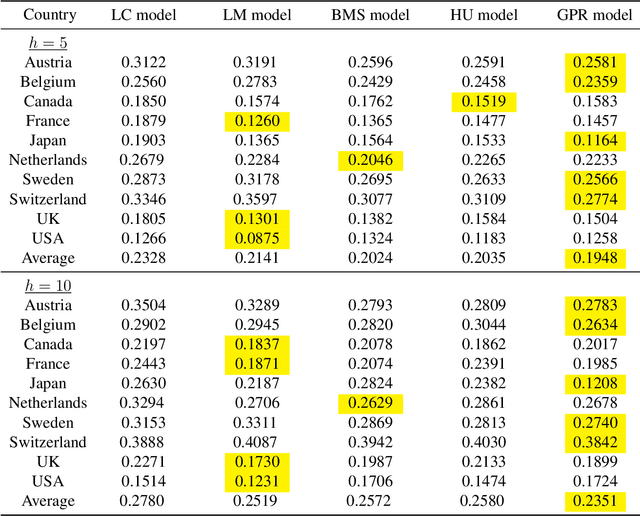
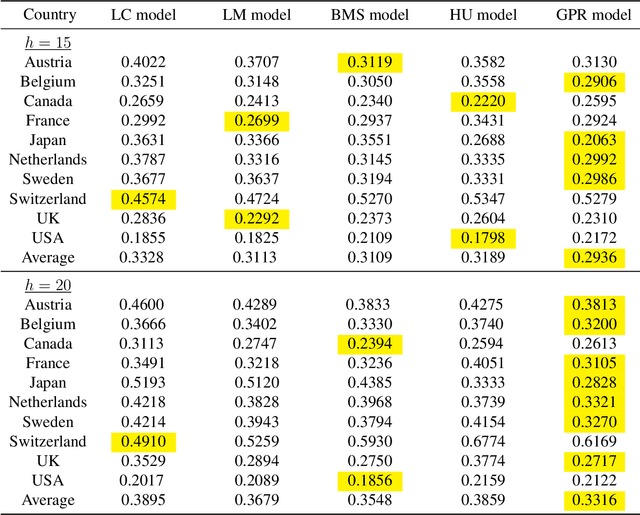
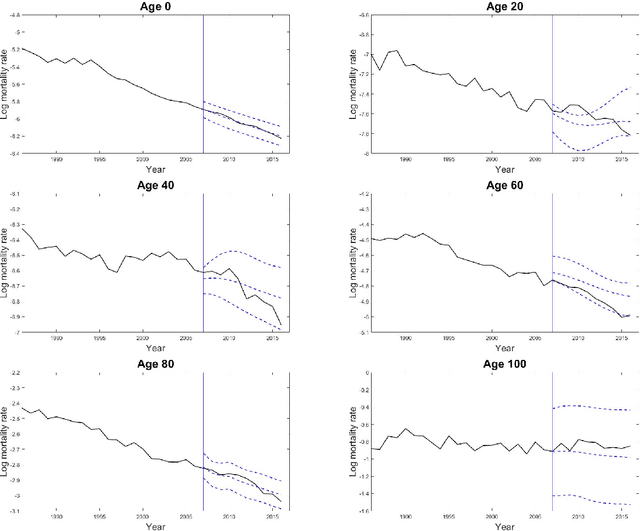
A rapid decline in mortality and fertility has become major issues in many developed countries over the past few decades. A precise model for forecasting demographic movements is important for decision making in social welfare policies and resource budgeting among the government and many industry sectors. This article introduces a novel non-parametric approach using Gaussian process regression with a natural cubic spline mean function and a spectral mixture covariance function for mortality and fertility modelling and forecasting. Unlike most of the existing approaches in demographic modelling literature, which rely on time parameters to decide the movements of the whole mortality or fertility curve shifting from one year to another over time, we consider the mortality and fertility curves from their components of all age-specific mortality and fertility rates and assume each of them following a Gaussian process over time to fit the whole curves in a discrete but intensive style. The proposed Gaussian process regression approach shows significant improvements in terms of preciseness and robustness compared to other mainstream demographic modelling approaches in the short-, mid- and long-term forecasting using the mortality and fertility data of several developed countries in our numerical experiments.
NeuralLog: Natural Language Inference with Joint Neural and Logical Reasoning
May 29, 2021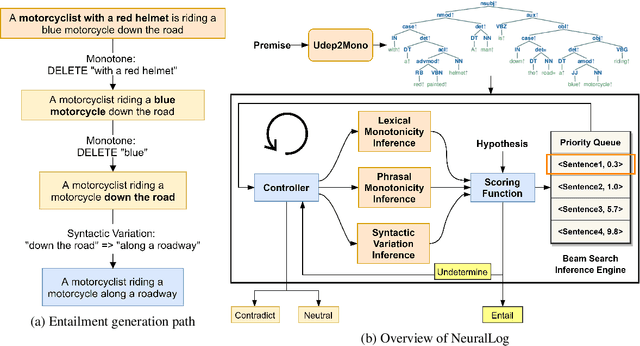
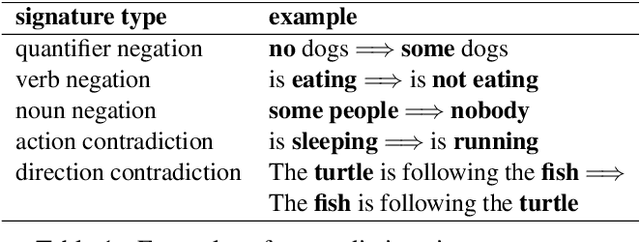
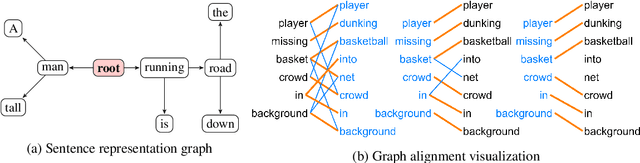

Deep learning (DL) based language models achieve high performance on various benchmarks for Natural Language Inference (NLI). And at this time, symbolic approaches to NLI are receiving less attention. Both approaches (symbolic and DL) have their advantages and weaknesses. However, currently, no method combines them in a system to solve the task of NLI. To merge symbolic and deep learning methods, we propose an inference framework called NeuralLog, which utilizes both a monotonicity-based logical inference engine and a neural network language model for phrase alignment. Our framework models the NLI task as a classic search problem and uses the beam search algorithm to search for optimal inference paths. Experiments show that our joint logic and neural inference system improves accuracy on the NLI task and can achieve state-of-art accuracy on the SICK and MED datasets.
Visual Camera Re-Localization Using Graph Neural Networks and Relative Pose Supervision
Apr 12, 2021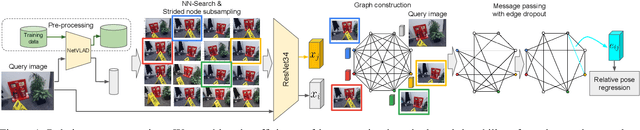
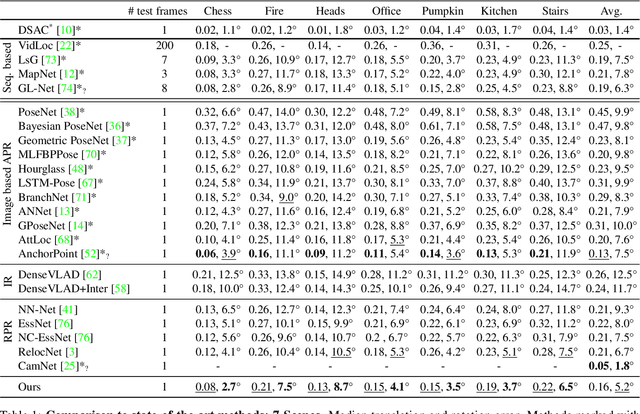
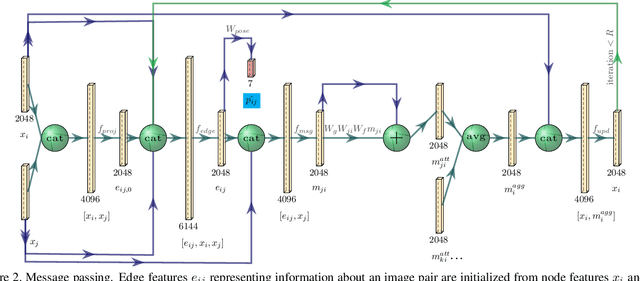

Visual re-localization means using a single image as input to estimate the camera's location and orientation relative to a pre-recorded environment. The highest-scoring methods are "structure based," and need the query camera's intrinsics as an input to the model, with careful geometric optimization. When intrinsics are absent, methods vie for accuracy by making various other assumptions. This yields fairly good localization scores, but the models are "narrow" in some way, eg., requiring costly test-time computations, or depth sensors, or multiple query frames. In contrast, our proposed method makes few special assumptions, and is fairly lightweight in training and testing. Our pose regression network learns from only relative poses of training scenes. For inference, it builds a graph connecting the query image to training counterparts and uses a graph neural network (GNN) with image representations on nodes and image-pair representations on edges. By efficiently passing messages between them, both representation types are refined to produce a consistent camera pose estimate. We validate the effectiveness of our approach on both standard indoor (7-Scenes) and outdoor (Cambridge Landmarks) camera re-localization benchmarks. Our relative pose regression method matches the accuracy of absolute pose regression networks, while retaining the relative-pose models' test-time speed and ability to generalize to non-training scenes.