 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Attention Bottlenecks for Multimodal Fusion
Jun 30, 2021
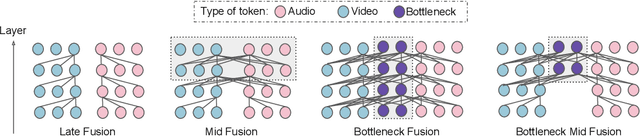
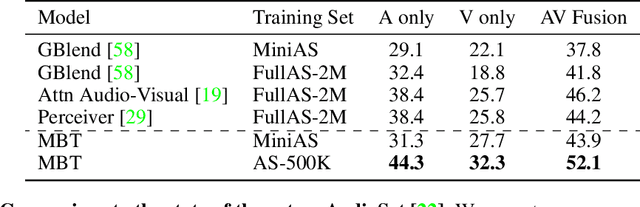
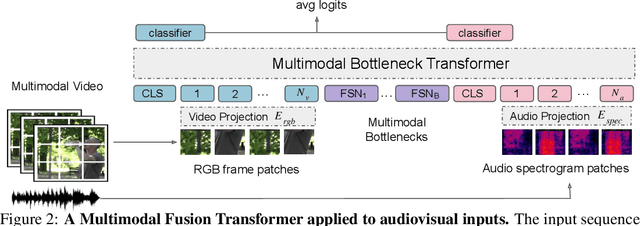
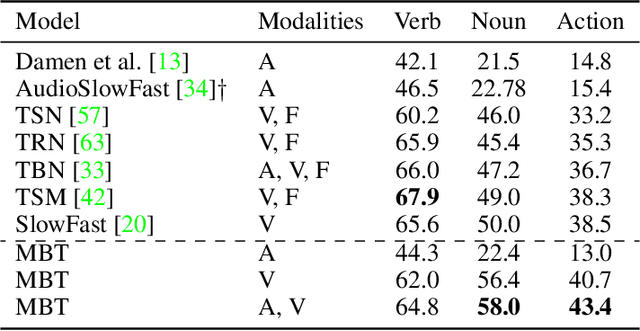
Humans perceive the world by concurrently processing and fusing high-dimensional inputs from multiple modalities such as vision and audio. Machine perception models, in stark contrast, are typically modality-specific and optimised for unimodal benchmarks, and hence late-stage fusion of final representations or predictions from each modality (`late-fusion') is still a dominant paradigm for multimodal video classification. Instead, we introduce a novel transformer based architecture that uses `fusion bottlenecks' for modality fusion at multiple layers. Compared to traditional pairwise self-attention, our model forces information between different modalities to pass through a small number of bottleneck latents, requiring the model to collate and condense the most relevant information in each modality and only share what is necessary. We find that such a strategy improves fusion performance, at the same time reducing computational cost. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple audio-visual classification benchmarks including Audioset, Epic-Kitchens and VGGSound. All code and models will be released.
Text is Text, No Matter What: Unifying Text Recognition using Knowledge Distillation
Jul 27, 2021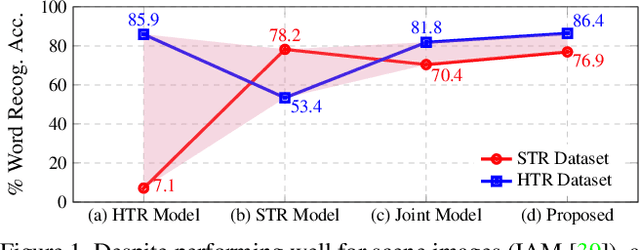

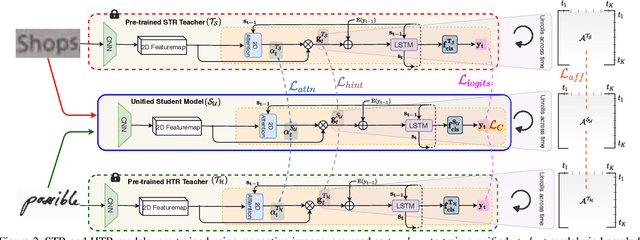
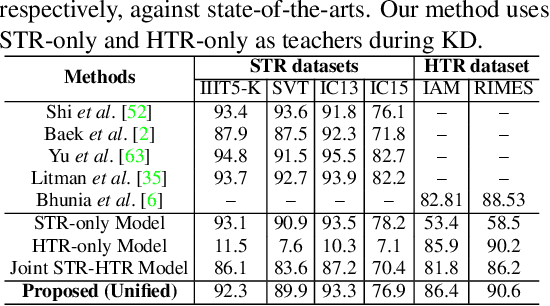
Text recognition remains a fundamental and extensively researched topic in computer vision, largely owing to its wide array of commercial applications. The challenging nature of the very problem however dictated a fragmentation of research efforts: Scene Text Recognition (STR) that deals with text in everyday scenes, and Handwriting Text Recognition (HTR) that tackles hand-written text. In this paper, for the first time, we argue for their unification -- we aim for a single model that can compete favourably with two separate state-of-the-art STR and HTR models. We first show that cross-utilisation of STR and HTR models trigger significant performance drops due to differences in their inherent challenges. We then tackle their union by introducing a knowledge distillation (KD) based framework. This is however non-trivial, largely due to the variable-length and sequential nature of text sequences, which renders off-the-shelf KD techniques that mostly works with global fixed-length data inadequate. For that, we propose three distillation losses all of which are specifically designed to cope with the aforementioned unique characteristics of text recognition. Empirical evidence suggests that our proposed unified model performs on par with individual models, even surpassing them in certain cases. Ablative studies demonstrate that naive baselines such as a two-stage framework, and domain adaption/generalisation alternatives do not work as well, further verifying the appropriateness of our design.
Parameter Selection: Why We Should Pay More Attention to It
Jul 08, 2021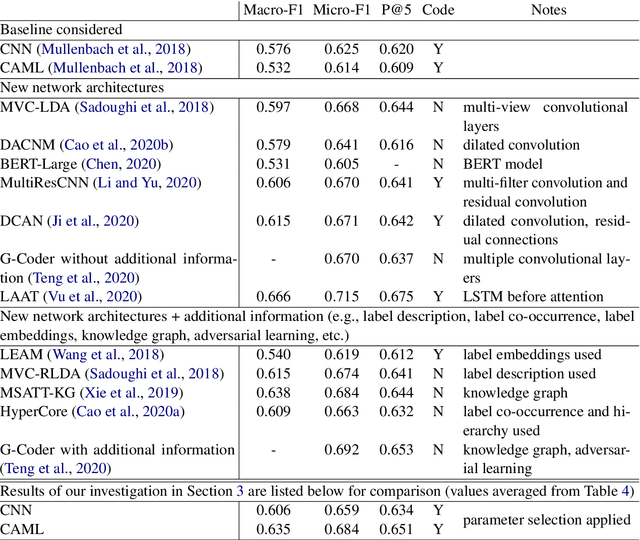
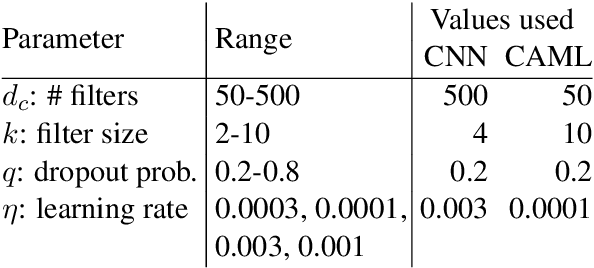
The importance of parameter selection in supervised learning is well known. However, due to the many parameter combinations, an incomplete or an insufficient procedure is often applied. This situation may cause misleading or confusing conclusions. In this opinion paper, through an intriguing example we point out that the seriousness goes beyond what is generally recognized. In the topic of multi-label classification for medical code prediction, one influential paper conducted a proper parameter selection on a set, but when moving to a subset of frequently occurring labels, the authors used the same parameters without a separate tuning. The set of frequent labels became a popular benchmark in subsequent studies, which kept pushing the state of the art. However, we discovered that most of the results in these studies cannot surpass the approach in the original paper if a parameter tuning had been conducted at the time. Thus it is unclear how much progress the subsequent developments have actually brought. The lesson clearly indicates that without enough attention on parameter selection, the research progress in our field can be uncertain or even illusive.
NASOA: Towards Faster Task-oriented Online Fine-tuning with a Zoo of Models
Aug 07, 2021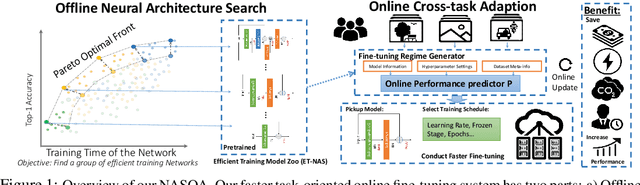

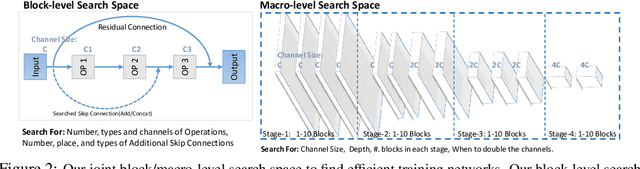
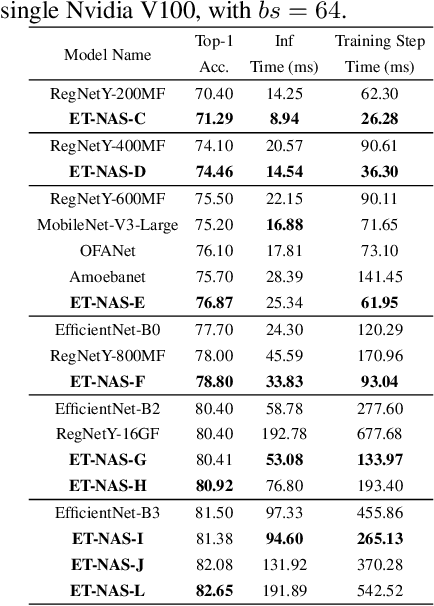
Fine-tuning from pre-trained ImageNet models has been a simple, effective, and popular approach for various computer vision tasks. The common practice of fine-tuning is to adopt a default hyperparameter setting with a fixed pre-trained model, while both of them are not optimized for specific tasks and time constraints. Moreover, in cloud computing or GPU clusters where the tasks arrive sequentially in a stream, faster online fine-tuning is a more desired and realistic strategy for saving money, energy consumption, and CO2 emission. In this paper, we propose a joint Neural Architecture Search and Online Adaption framework named NASOA towards a faster task-oriented fine-tuning upon the request of users. Specifically, NASOA first adopts an offline NAS to identify a group of training-efficient networks to form a pretrained model zoo. We propose a novel joint block and macro-level search space to enable a flexible and efficient search. Then, by estimating fine-tuning performance via an adaptive model by accumulating experience from the past tasks, an online schedule generator is proposed to pick up the most suitable model and generate a personalized training regime with respect to each desired task in a one-shot fashion. The resulting model zoo is more training efficient than SOTA models, e.g. 6x faster than RegNetY-16GF, and 1.7x faster than EfficientNetB3. Experiments on multiple datasets also show that NASOA achieves much better fine-tuning results, i.e. improving around 2.1% accuracy than the best performance in RegNet series under various constraints and tasks; 40x faster compared to the BOHB.
Learning Hamiltonian dynamics by reservoir computer
Apr 24, 2021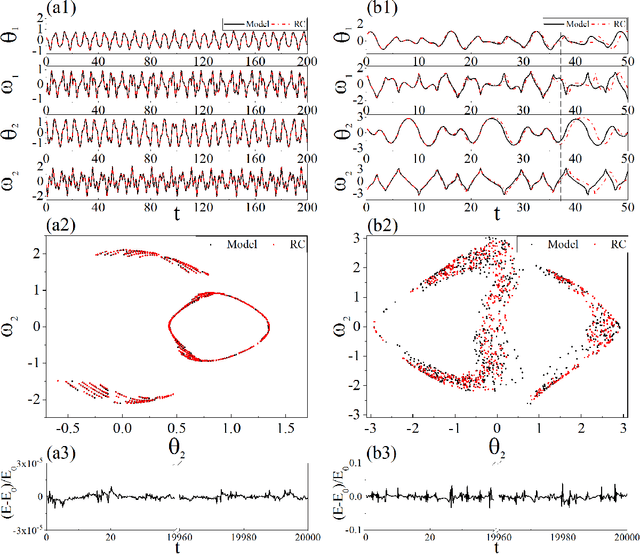
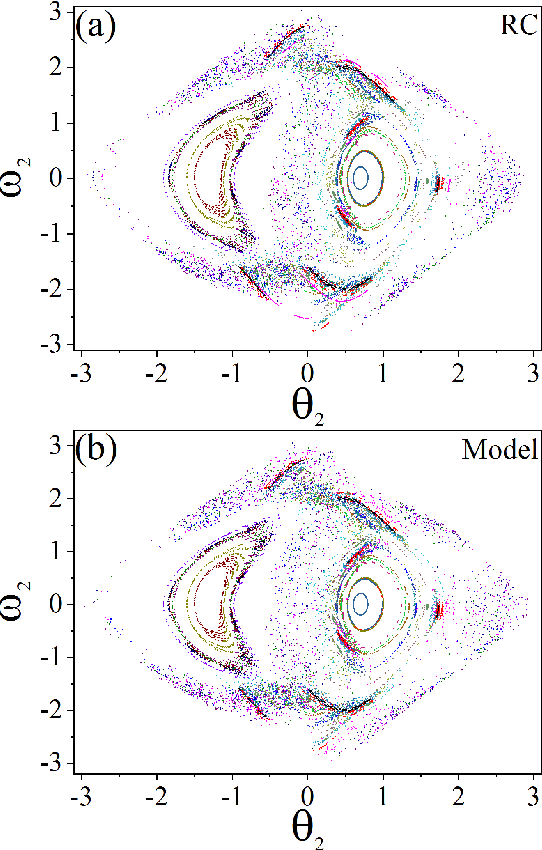
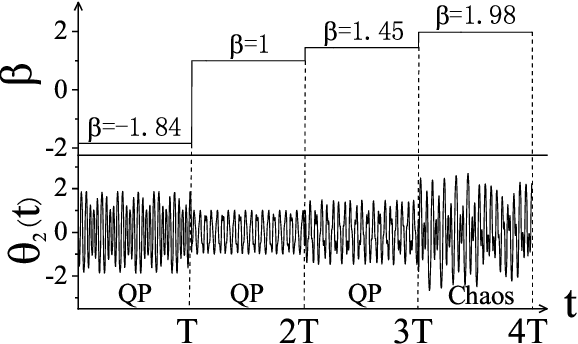
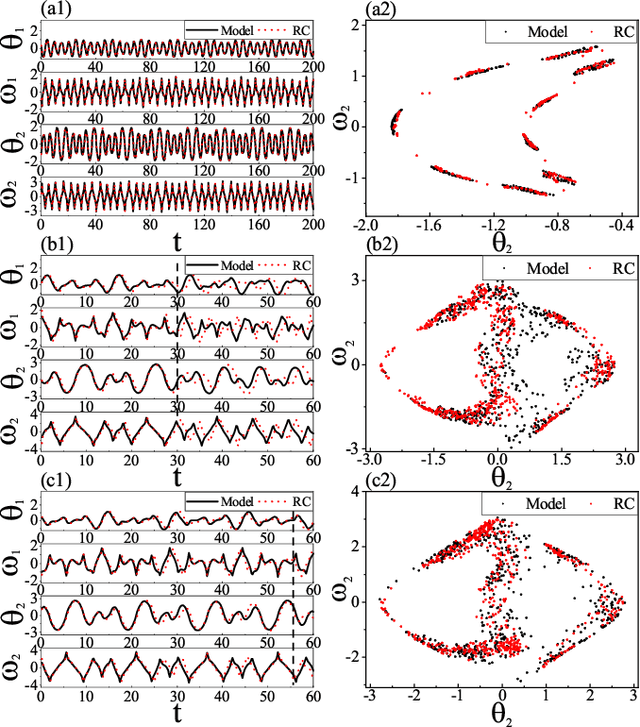
Reconstructing the KAM dynamics diagram of Hamiltonian system from the time series of a limited number of parameters is an outstanding question in nonlinear science, especially when the Hamiltonian governing the system dynamics are unknown. Here, we demonstrate that this question can be addressed by the machine learning approach knowing as reservoir computer (RC). Specifically, we show that without prior knowledge about the Hamilton's equations of motion, the trained RC is able to not only predict the short-term evolution of the system state, but also replicate the long-term ergodic properties of the system dynamics. Furthermore, by the architecture of parameter-aware RC, we also show that the RC trained by the time series acquired at a handful parameters is able to reconstruct the entire KAM dynamics diagram with a high precision by tuning a control parameter externally. The feasibility and efficiency of the learning techniques are demonstrated in two classical nonlinear Hamiltonian systems, namely the double-pendulum oscillator and the standard map. Our study indicates that, as a complex dynamical system, RC is able to learn from data the Hamiltonian.
Temporal Energy Analysis of Symbol Sequences for Fiber Nonlinear Interference Modelling via Energy Dispersion Index
Feb 24, 2021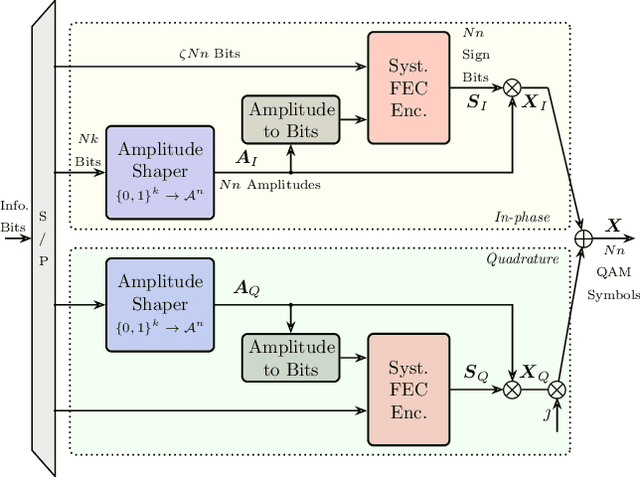
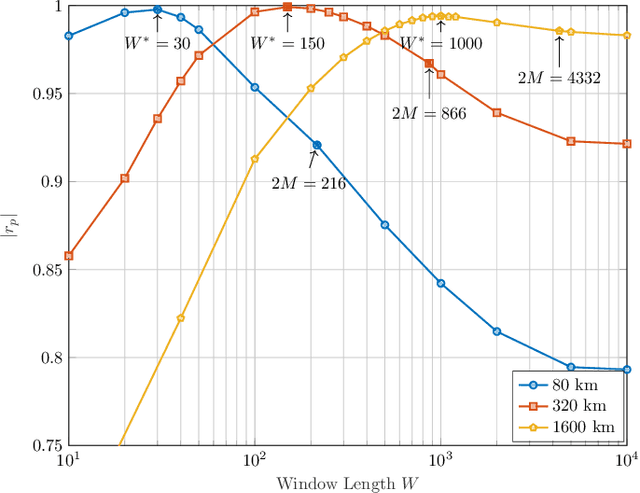
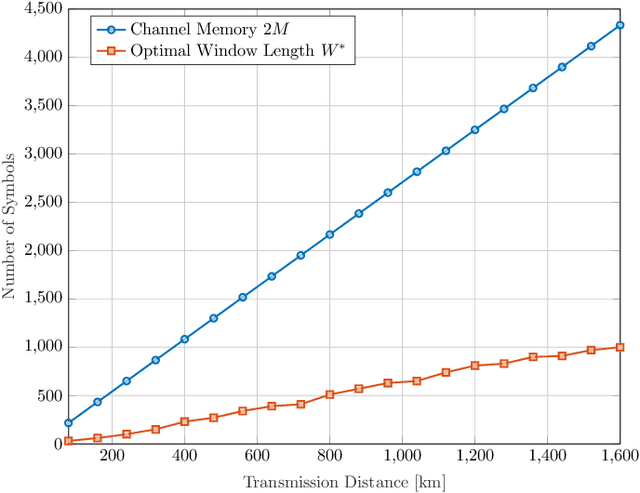
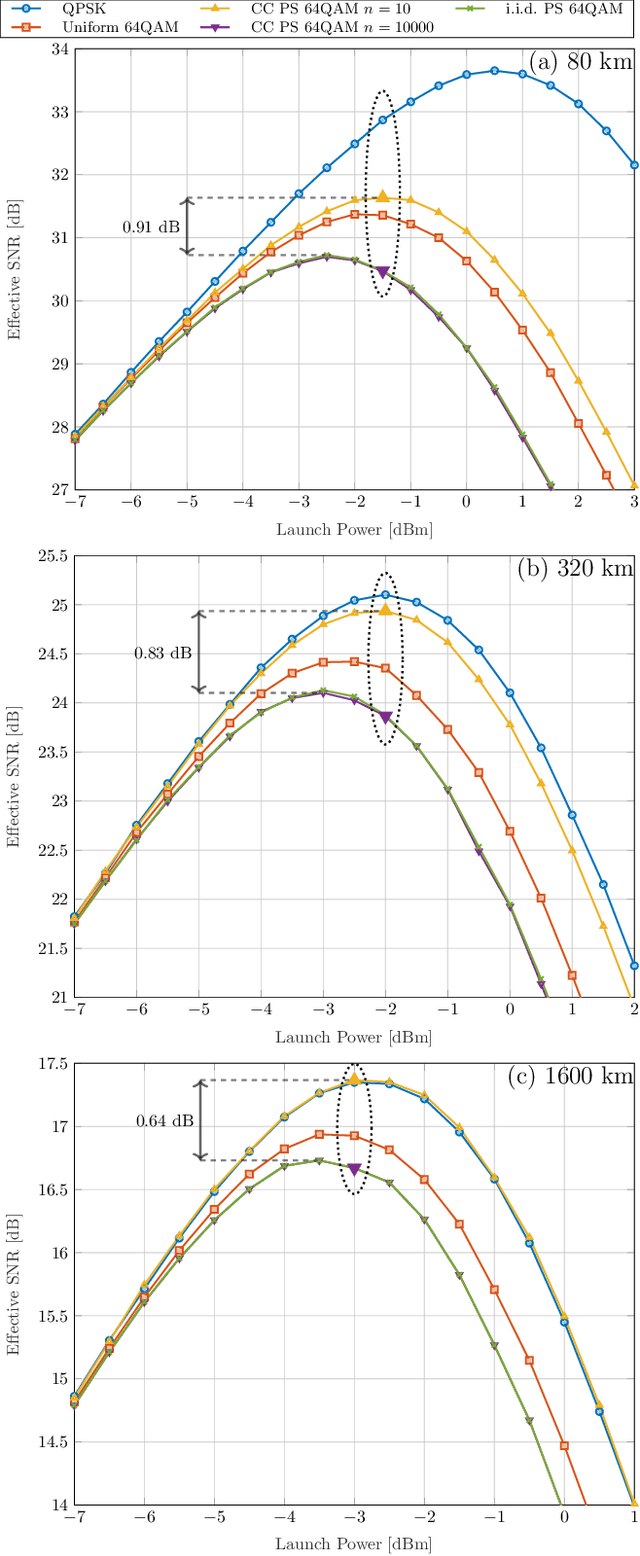
The stationary statistical properties of independent, identically distributed (i.i.d.) input symbols provide insights on the induced nonlinear interference (NLI) during fiber transmission. For example, kurtosis is known to predict the modulation format-dependent NLI. These statistical properties can be used in the design of probabilistic amplitude shaping (PAS), which is a popular scheme that relies on an amplitude shaper for increasing spectral efficiencies of fiber-optic systems. One property of certain shapers used in PAS -- including constant-composition distribution matchers -- that is often overlooked is that a time-dependency between amplitudes is introduced. This dependency results in symbols that are non-i.i.d., which have time-varying statistical properties. Somewhat surprisingly, the effective signal-to-noise ratio (SNR) in PAS has been shown to increase when the shaping blocklength decreases. This blocklength dependency of SNR has been attributed to time-varying statistical properties of the symbol sequences, in particular, to variation of the symbol energies. In this paper, we investigate the temporal energy behavior of symbol sequences, and introduce a new metric called energy dispersion index (EDI). EDI captures the time-varying statistical properties of symbol energies. Numerical results show strong correlations between EDI and effective SNR, with absolute correlation coefficients above 99% for different transmission distances.
Vision Transformers for femur fracture classification
Aug 07, 2021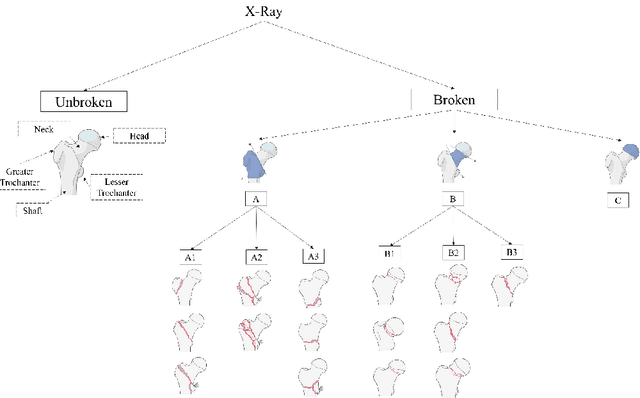

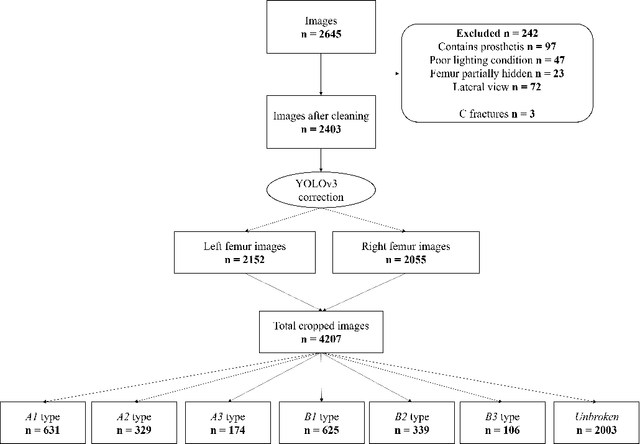
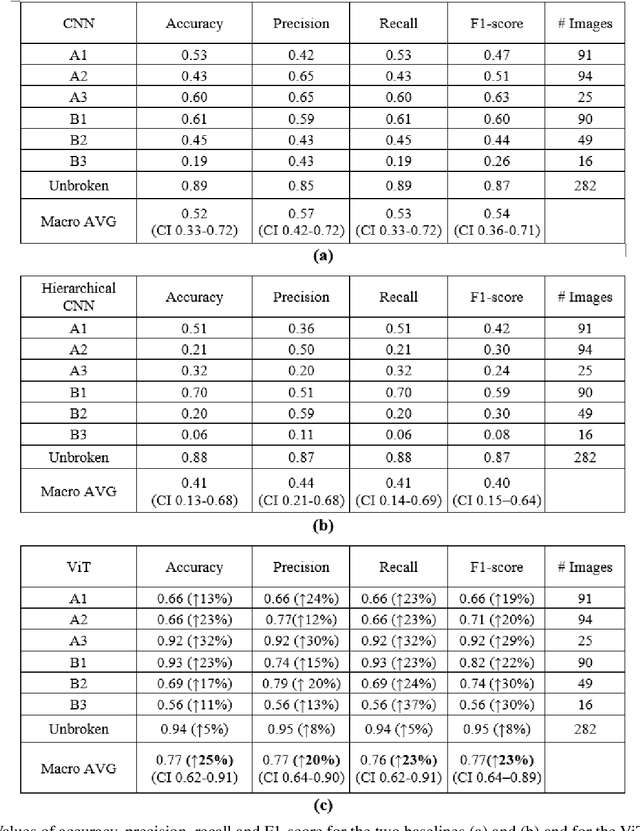
Objectives: In recent years, the scientific community has focused on the development of Computer-Aided Diagnosis (CAD) tools that could improve bone fractures' classification. However, the results of the classification of fractures in subtypes with the proposed datasets were far from optimal. This paper proposes a very recent and outperforming deep learning technique, the Vision Transformer (ViT), in order to improve the fracture classification, by exploiting its self-attention mechanism. Methods: 4207 manually annotated images were used and distributed, by following the AO/OTA classification, in different fracture types, the largest labeled dataset of proximal femur fractures used in literature. The ViT architecture was used and compared with a classic Convolutional Neural Network (CNN) and a multistage architecture composed by successive CNNs in cascade. To demonstrate the reliability of this approach, 1) the attention maps were used to visualize the most relevant areas of the images, 2) the performance of a generic CNN and ViT was also compared through unsupervised learning techniques, and 3) 11 specialists were asked to evaluate and classify 150 proximal femur fractures' images with and without the help of the ViT. Results: The ViT was able to correctly predict 83% of the test images. Precision, recall and F1-score were 0.77 (CI 0.64-0.90), 0.76 (CI 0.62-0.91) and 0.77 (CI 0.64-0.89), respectively. The average specialists' diagnostic improvement was 29%. Conclusions: This paper showed the potential of Transformers in bone fracture classification. For the first time, good results were obtained in sub-fractures with the largest and richest dataset ever.
Digitizing Handwriting with a Sensor Pen: A Writer-Independent Recognizer
Jul 08, 2021
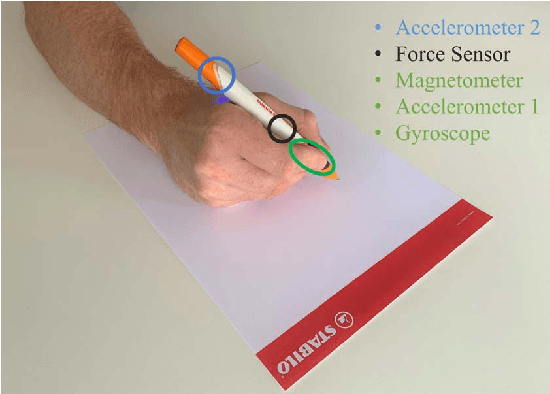

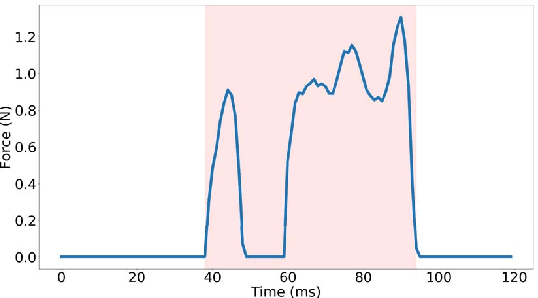
Online handwriting recognition has been studied for a long time with only few practicable results when writing on normal paper. Previous approaches using sensor-based devices encountered problems that limited the usage of the developed systems in real-world applications. This paper presents a writer-independent system that recognizes characters written on plain paper with the use of a sensor-equipped pen. This system is applicable in real-world applications and requires no user-specific training for recognition. The pen provides linear acceleration, angular velocity, magnetic field, and force applied by the user, and acts as a digitizer that transforms the analogue signals of the sensors into timeseries data while writing on regular paper. The dataset we collected with this pen consists of Latin lower-case and upper-case alphabets. We present the results of a convolutional neural network model for letter classification and show that this approach is practical and achieves promising results for writer-independent character recognition. This work aims at providing a realtime handwriting recognition system to be used for writing on normal paper.
RMQFMU: Bridging the Real World with Co-simulation Technical Report
Jul 08, 2021
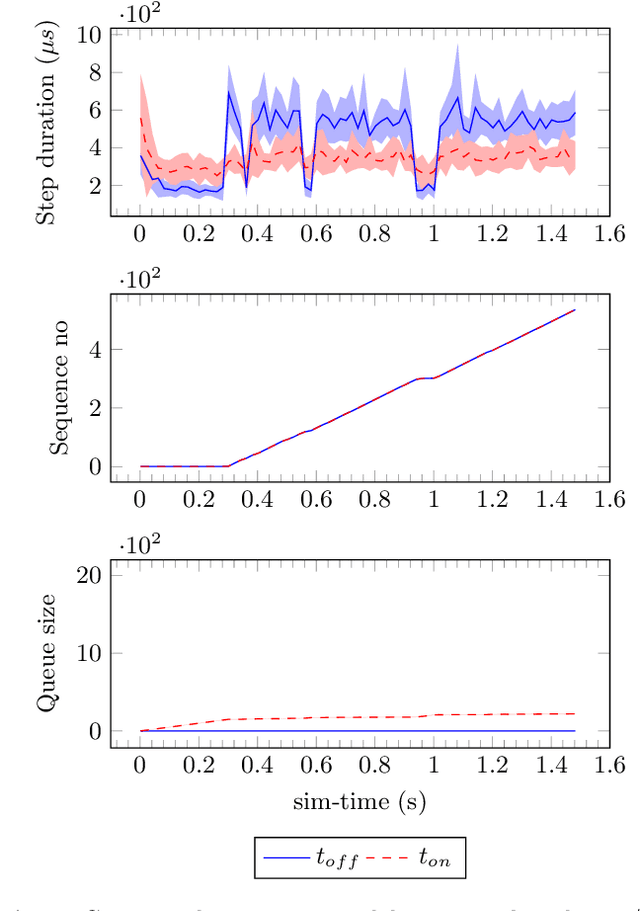
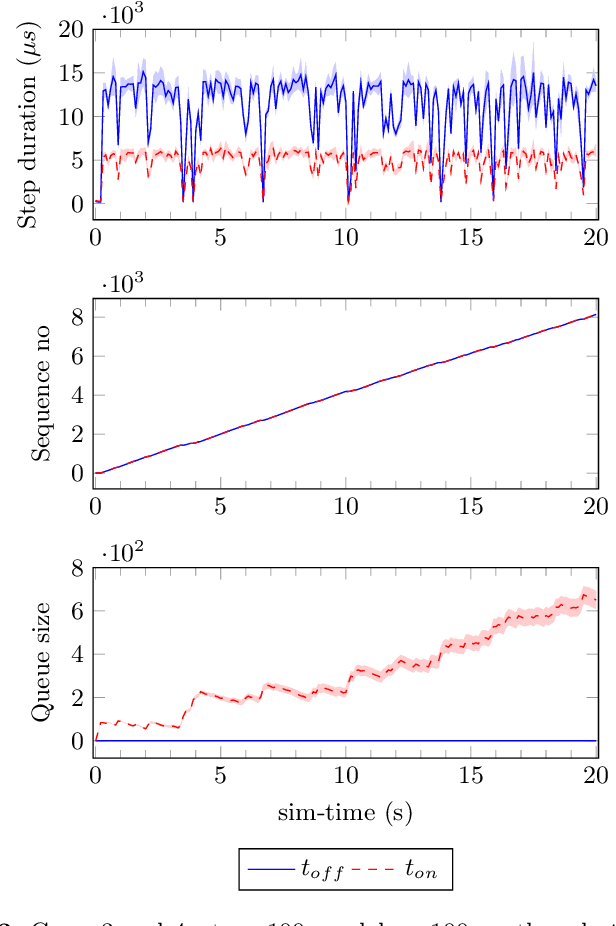
In this paper we present an experience report for the RMQFMU, a plug and play tool, that enables feeding data to/from an FMI2-based co-simulation environment based on the AMQP protocol. Bridging the co-simulation to an external environment allows on one side to feed historical data to the co-simulation, serving different purposes, such as visualisation and/or data analysis. On the other side, such a tool facilitates the realisation of the digital twin concept by coupling co-simulation and hardware/robots close to real-time. In the paper we present limitations of the initial version of the RMQFMU with respect to the capability of bridging co-simulation with the real world. To provide the desired functionality of the tool, we present in a step-by-step fashion how these limitations, and subsequent limitations, are alleviated. We perform various experiments in order to give reason to the modifications carried out. Finally, we report on two case-studies where we have adopted the RMQFMU, and provide guidelines meant to aid practitioners in its use.
No-frills Dynamic Planning using Static Planners
Jun 17, 2021

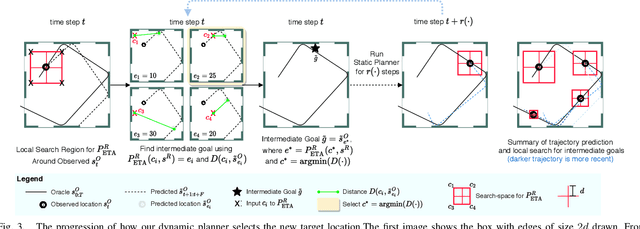
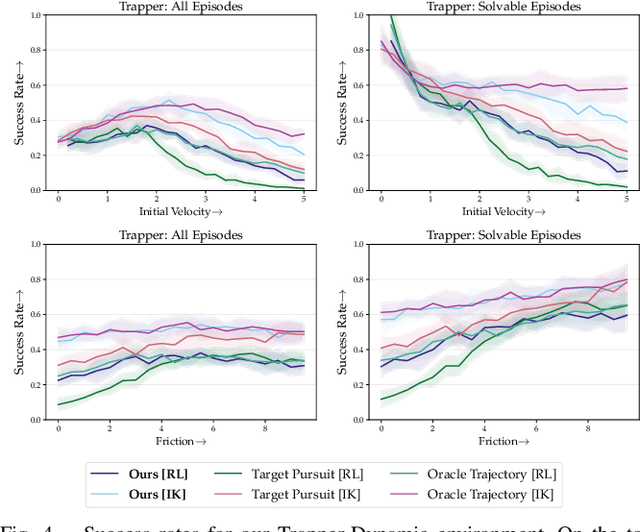
In this paper, we address the task of interacting with dynamic environments where the changes in the environment are independent of the agent. We study this through the context of trapping a moving ball with a UR5 robotic arm. Our key contribution is an approach to utilize a static planner for dynamic tasks using a Dynamic Planning add-on; that is, if we can successfully solve a task with a static target, then our approach can solve the same task when the target is moving. Our approach has three key components: an off-the-shelf static planner, a trajectory forecasting network, and a network to predict robot's estimated time of arrival at any location. We demonstrate the generalization of our approach across environments. More information and videos at https://mlevy2525.github.io/DynamicAddOn.