 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank, Head-Channel Non-Identifiability, and Symmetry Breaking: A Precise Analysis of Representational Collapse in Transformers
Apr 26, 2026A widely cited result by Dong et al. (2021) showed that Transformers built from self-attention alone, without skip connections or feed-forward layers, suffer from rapid rank collapse: all token representations converge to a single direction. The proposed remedy was the MLP. We show that this picture, while correct in the regime studied by Dong, is incomplete in ways that matter for architectural understanding. Three results are established. First, layer normalisation is precisely affine-rank-neutral: it preserves the affine rank of the token representation set exactly. The widespread claim that LN "plays no role" is imprecise; the correct statement is sharper. Second, residual connections generically obstruct rank collapse in real Transformers such as BERT-base, in a measure-theoretic sense, without contribution from the MLP. The MLP's irreplaceable function is different: generating feature directions outside the linear span of the original token embeddings, which no stack of attention layers can produce. Third, a phenomenon distinct from rank collapse is identified: head-channel non-identifiability. After multi-head attention sums per-head outputs through the output projection, individual contributions cannot be canonically attributed to a specific head; n(H-1)d_k degrees of freedom per layer remain ambiguous when recovering a single head from the mixed signal. The MLP cannot remedy this because it acts on the post-summation signal. A constructive partial remedy is proposed: a position-gated output projection (PG-OP) at parameter overhead below 1.6% of the standard output projection. The four collapse phenomena identified in the literature -- rank collapse in depth, in width, head-channel non-identifiability, and entropy collapse -- are unified under a symmetry-breaking framework, each corresponding to a distinct symmetry of the Transformer's forward pass.
INCRT: An Incremental Transformer That Determines Its Own Architecture
Apr 12, 2026Transformer architectures are designed by trial and error: the number of attention heads, the depth, and the head size are fixed before training begins, with no mathematical principle to guide the choice. The result is systematic structural redundancy -- between half and four-fifths of all heads in a trained model can be removed without measurable loss -- because the architecture allocates capacity without reference to the actual requirements of the task.This paper introduces INCRT (Incremental Transformer), an architecture that determines its own structure during training. Starting from a single head, INCRT adds one attention head at a time whenever its current configuration is provably insufficient, and prunes heads that have become redundant. Each growth decision is driven by a single, online-computable geometric quantity derived from the task's directional structure, requiring no separate validation phase and no hand-tuned schedule. Two theorems form the theoretical backbone. The first (homeostatic convergence) establishes that the system always reaches a finite stopping configuration that is simultaneously minimal (no redundant heads) and sufficient (no uncaptured directional energy above the threshold). The second (compressed-sensing analogy) provides a geometric upper bound on the number of heads that this configuration can contain, as a function of the spectral complexity of the task. Experiments on SARS-CoV-2 variant classification and SST-2 sentiment analysis confirm both results: the predicted and observed head counts agree within 12% across all benchmarks, and the final architectures match or exceed BERT-base on distribution-specific tasks while using between three and seven times fewer parameters and no pre-training.
Hierarchical Kernel Transformer: Multi-Scale Attention with an Information-Theoretic Approximation Analysis
Apr 10, 2026The Hierarchical Kernel Transformer (HKT) is a multi-scale attention mechanism that processes sequences at L resolution levels via trainable causal downsampling, combining level-specific score matrices through learned convex weights. The total computational cost is bounded by 4/3 times that of standard attention, reaching 1.3125x for L = 3. Four theoretical results are established. (i) The hierarchical score matrix defines a positive semidefinite kernel under a sufficient condition on the symmetrised bilinear form (Proposition 3.1). (ii) The asymmetric score matrix decomposes uniquely into a symmetric part controlling reciprocal attention and an antisymmetric part controlling directional attention; HKT provides L independent such pairs across scales, one per resolution level (Propositions 3.5-3.6). (iii) The approximation error decomposes into three interpretable components with an explicit non-Gaussian correction and a geometric decay bound in L (Theorem 4.3, Proposition 4.4). (iv) HKT strictly subsumes single-head standard attention and causal convolution (Proposition 3.4). Experiments over 3 random seeds show consistent gains over retrained standard attention baselines: +4.77pp on synthetic ListOps (55.10+-0.29% vs 50.33+-0.12%, T = 512), +1.44pp on sequential CIFAR-10 (35.45+-0.09% vs 34.01+-0.19%, T = 1,024), and +7.47pp on IMDB character-level sentiment (70.19+-0.57% vs 62.72+-0.40%, T = 1,024), all at 1.31x overhead.
On the Geometry of Positional Encodings in Transformers
Apr 06, 2026Neural language models process sequences of words, but the mathematical operations inside them are insensitive to the order in which words appear. Positional encodings are the component added to remedy this. Despite their importance, positional encodings have been designed largely by trial and error, without a mathematical theory of what they ought to do. This paper develops such a theory. Four results are established. First, any Transformer without a positional signal cannot solve any task sensitive to word order (Necessity Theorem). Second, training assigns distinct vector representations to distinct sequence positions at every global minimiser, under mild and verifiable conditions (Positional Separation Theorem). Third, the best achievable approximation to an information-optimal encoding is constructed via classical multidimensional scaling (MDS) on the Hellinger distance between positional distributions; the quality of any encoding is measured by a single number, the stress (Proposition 5, Algorithm 1). Fourth, the optimal encoding has effective rank r = rank(B) <= n-1 and can be represented with r(n+d) parameters instead of nd (minimal parametrisation result). Appendix A develops a proof of the Monotonicity Conjecture within the Neural Tangent Kernel (NTK) regime for masked language modelling (MLM) losses, sequence classification losses, and general losses satisfying a positional sufficiency condition, through five lemmas. Experiments on SST-2 and IMDB with BERT-base confirm the theoretical predictions and reveal that Attention with Linear Biases (ALiBi) achieves much lower stress than the sinusoidal encoding and Rotary Position Embedding (RoPE), consistent with a rank-1 interpretation of the MDS encoding under approximate shift-equivariance.
Collapse-Free Prototype Readout Layer for Transformer Encoders
Apr 04, 2026DDCL-Attention is a prototype-based readout layer for transformer encoders that replaces simple pooling methods, such as mean pooling or class tokens, with a learned compression mechanism. It uses a small set of global prototype vectors and assigns tokens to them through soft probabilistic matching, producing compact token summaries at linear complexity in sequence length. The method offers three main advantages. First, it avoids prototype collapse through an exact decomposition of the training loss into a reconstruction term and a diversity term, ensuring that prototypes remain distinct. Second, its joint training with the encoder is shown to be stable under a practical timescale condition, using Tikhonov's singular perturbation theory and explicit learning-rate constraints. Third, the same framework supports three uses: a final readout layer, a differentiable codebook extending VQ-VAE, and a hierarchical document compressor. Experiments on four datasets confirm the theoretical predictions: the loss decomposition holds exactly, prototype separation grows as expected when the stability condition is met, and the codebook reaches full utilization, outperforming standard hard vector quantization. An additional study on orbital debris classification shows that the method also applies beyond standard NLP and vision tasks, including scientific tabular data.
DDCL: Deep Dual Competitive Learning: A Differentiable End-to-End Framework for Unsupervised Prototype-Based Representation Learning
Apr 02, 2026A persistent structural weakness in deep clustering is the disconnect between feature learning and cluster assignment. Most architectures invoke an external clustering step, typically k-means, to produce pseudo-labels that guide training, preventing the backbone from directly optimising for cluster quality. This paper introduces Deep Dual Competitive Learning (DDCL), the first fully differentiable end-to-end framework for unsupervised prototype-based representation learning. The core contribution is architectural: the external k-means is replaced by an internal Dual Competitive Layer (DCL) that generates prototypes as native differentiable outputs of the network. This single inversion makes the complete pipeline, from backbone feature extraction through prototype generation to soft cluster assignment, trainable by backpropagation through a single unified loss, with no Lloyd iterations, no pseudo-label discretisation, and no external clustering step. To ground the framework theoretically, the paper derives an exact algebraic decomposition of the soft quantisation loss into a simplex-constrained reconstruction error and a non-negative weighted prototype variance term. This identity reveals a self-regulating mechanism built into the loss geometry: the gradient of the variance term acts as an implicit separation force that resists prototype collapse without any auxiliary objective, and leads to a global Lyapunov stability theorem for the reduced frozen-encoder system. Six blocks of controlled experiments validate each structural prediction. The decomposition identity holds with zero violations across more than one hundred thousand training epochs; the negative feedback cycle is confirmed with Pearson -0.98; with a jointly trained backbone, DDCL outperforms its non-differentiable ablation by 65% in clustering accuracy and DeepCluster end-to-end by 122%.
DDCL-INCRT: A Self-Organising Transformer with Hierarchical Prototype Structure (Theoretical Foundations)
Apr 02, 2026Modern neural networks of the transformer family require the practitioner to decide, before training begins, how many attention heads to use, how deep the network should be, and how wide each component should be. These decisions are made without knowledge of the task, producing architectures that are systematically larger than necessary: empirical studies find that a substantial fraction of heads and layers can be removed after training without performance loss. This paper introduces DDCL-INCRT, an architecture that determines its own structure during training. Two complementary ideas are combined. The first, DDCL (Deep Dual Competitive Learning), replaces the feedforward block with a dictionary of learned prototype vectors representing the most informative directions in the data. The prototypes spread apart automatically, driven by the training objective, without explicit regularisation. The second, INCRT (Incremental Transformer), controls the number of heads: starting from one, it adds a new head only when the directional information uncaptured by existing heads exceeds a threshold. The main theoretical finding is that these two mechanisms reinforce each other: each new head amplifies prototype separation, which in turn raises the signal triggering the next addition. At convergence, the network self-organises into a hierarchy of heads ordered by representational granularity. This hierarchical structure is proved to be unique and minimal, the smallest architecture sufficient for the task, under the stated conditions. Formal guarantees of stability, convergence, and pruning safety are established throughout. The architecture is not something one designs. It is something one derives.
The geometry of BERT
Feb 17, 2025Transformer neural networks, particularly Bidirectional Encoder Representations from Transformers (BERT), have shown remarkable performance across various tasks such as classification, text summarization, and question answering. However, their internal mechanisms remain mathematically obscure, highlighting the need for greater explainability and interpretability. In this direction, this paper investigates the internal mechanisms of BERT proposing a novel perspective on the attention mechanism of BERT from a theoretical perspective. The analysis encompasses both local and global network behavior. At the local level, the concept of directionality of subspace selection as well as a comprehensive study of the patterns emerging from the self-attention matrix are presented. Additionally, this work explores the semantic content of the information stream through data distribution analysis and global statistical measures including the novel concept of cone index. A case study on the classification of SARS-CoV-2 variants using RNA which resulted in a very high accuracy has been selected in order to observe these concepts in an application. The insights gained from this analysis contribute to a deeper understanding of BERT's classification process, offering potential avenues for future architectural improvements in Transformer models and further analysis in the training process.
Vision Transformers for femur fracture classification
Aug 07, 2021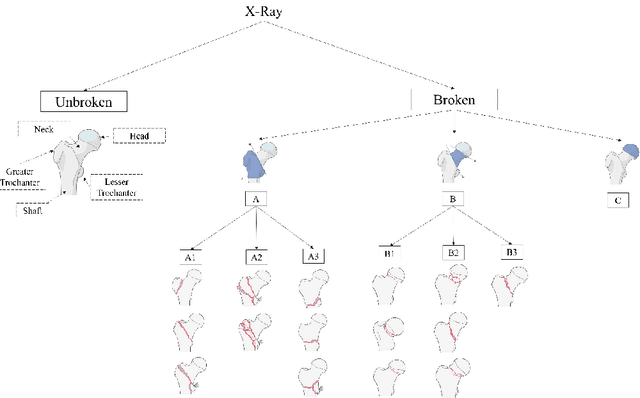

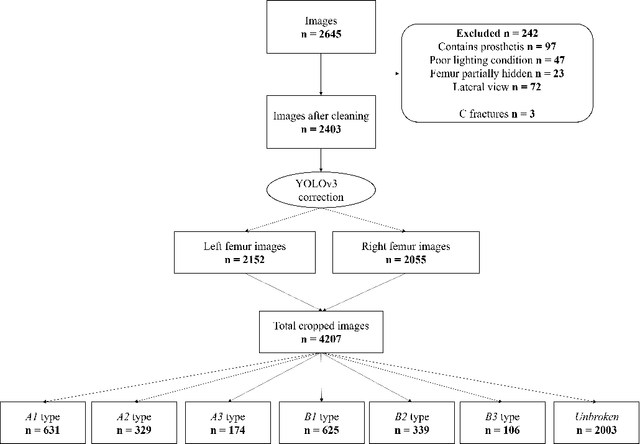
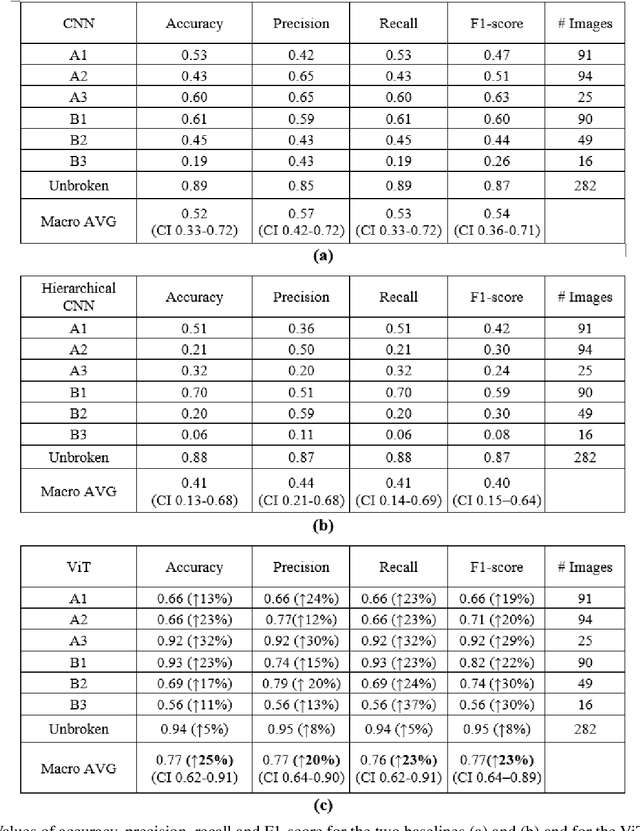
Objectives: In recent years, the scientific community has focused on the development of Computer-Aided Diagnosis (CAD) tools that could improve bone fractures' classification. However, the results of the classification of fractures in subtypes with the proposed datasets were far from optimal. This paper proposes a very recent and outperforming deep learning technique, the Vision Transformer (ViT), in order to improve the fracture classification, by exploiting its self-attention mechanism. Methods: 4207 manually annotated images were used and distributed, by following the AO/OTA classification, in different fracture types, the largest labeled dataset of proximal femur fractures used in literature. The ViT architecture was used and compared with a classic Convolutional Neural Network (CNN) and a multistage architecture composed by successive CNNs in cascade. To demonstrate the reliability of this approach, 1) the attention maps were used to visualize the most relevant areas of the images, 2) the performance of a generic CNN and ViT was also compared through unsupervised learning techniques, and 3) 11 specialists were asked to evaluate and classify 150 proximal femur fractures' images with and without the help of the ViT. Results: The ViT was able to correctly predict 83% of the test images. Precision, recall and F1-score were 0.77 (CI 0.64-0.90), 0.76 (CI 0.62-0.91) and 0.77 (CI 0.64-0.89), respectively. The average specialists' diagnostic improvement was 29%. Conclusions: This paper showed the potential of Transformers in bone fracture classification. For the first time, good results were obtained in sub-fractures with the largest and richest dataset ever.
Gradient-based Competitive Learning: Theory
Sep 06, 2020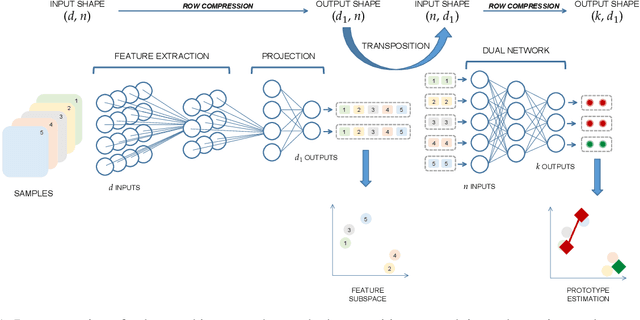
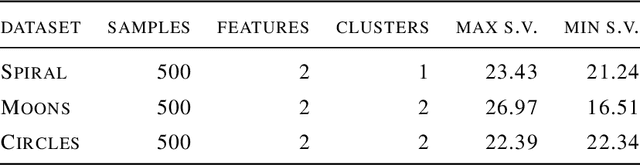

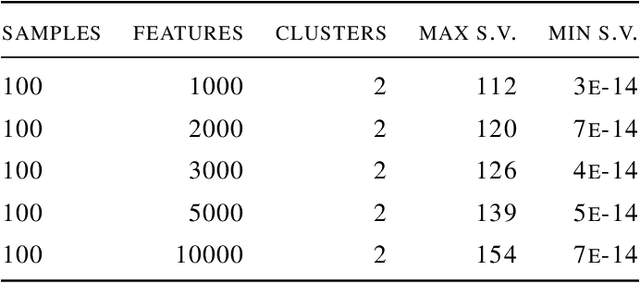
Deep learning has been widely used for supervised learning and classification/regression problems. Recently, a novel area of research has applied this paradigm to unsupervised tasks; indeed, a gradient-based approach extracts, efficiently and autonomously, the relevant features for handling input data. However, state-of-the-art techniques focus mostly on algorithmic efficiency and accuracy rather than mimic the input manifold. On the contrary, competitive learning is a powerful tool for replicating the input distribution topology. This paper introduces a novel perspective in this area by combining these two techniques: unsupervised gradient-based and competitive learning. The theory is based on the intuition that neural networks are able to learn topological structures by working directly on the transpose of the input matrix. At this purpose, the vanilla competitive layer and its dual are presented. The former is just an adaptation of a standard competitive layer for deep clustering, while the latter is trained on the transposed matrix. Their equivalence is extensively proven both theoretically and experimentally. However, the dual layer is better suited for handling very high-dimensional datasets. The proposed approach has a great potential as it can be generalized to a vast selection of topological learning tasks, such as non-stationary and hierarchical clustering; furthermore, it can also be integrated within more complex architectures such as autoencoders and generative adversarial networks.