 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scheduling Plans of Tasks
Feb 06, 2021
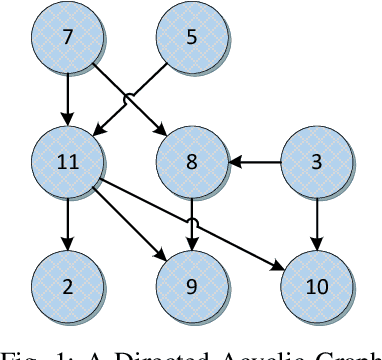
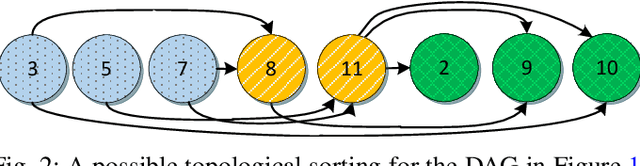
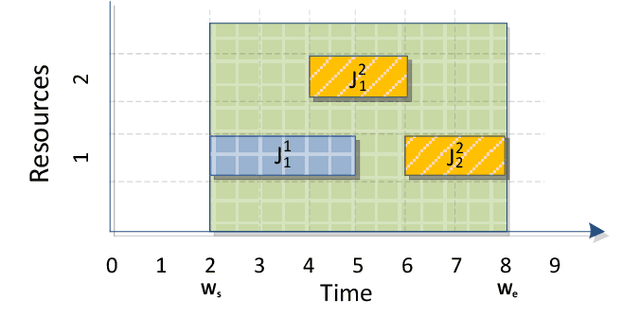
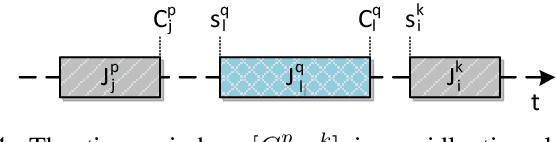
We present a heuristic algorithm for solving the problem of scheduling plans of tasks. The plans are ordered vectors of tasks, and tasks are basic operations carried out by resources. Plans are tied by temporal, precedence and resource constraints that makes the scheduling problem hard to solve in polynomial time. The proposed heuristic, that has a polynomial worst-case time complexity, searches for a feasible schedule that maximize the number of plans scheduled, along a fixed time window, with respect to temporal, precedence and resource constraints.
Deep learning for surrogate modelling of 2D mantle convection
Aug 23, 2021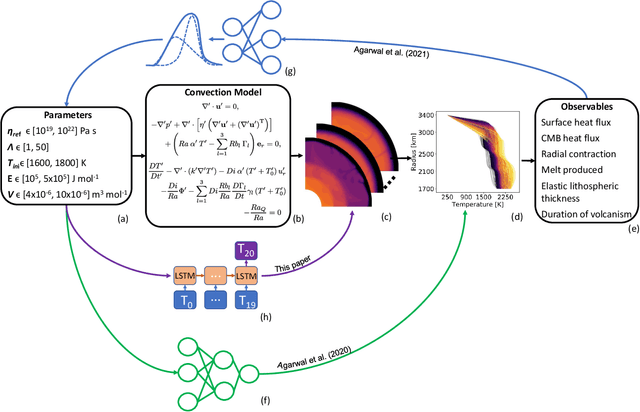
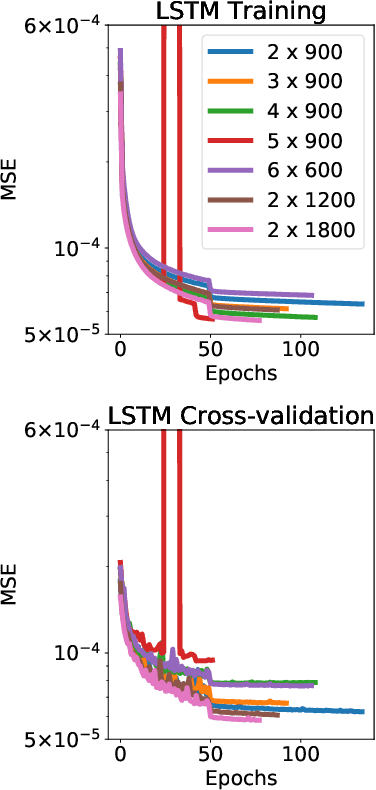
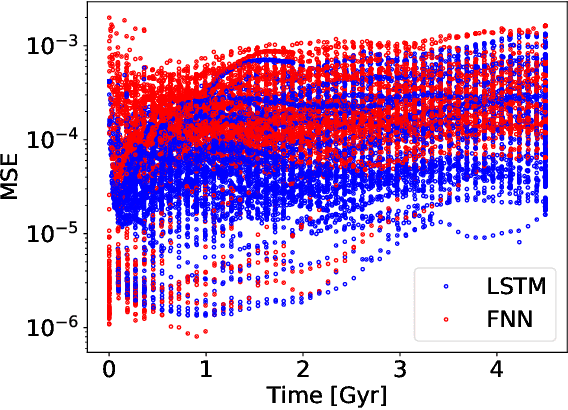
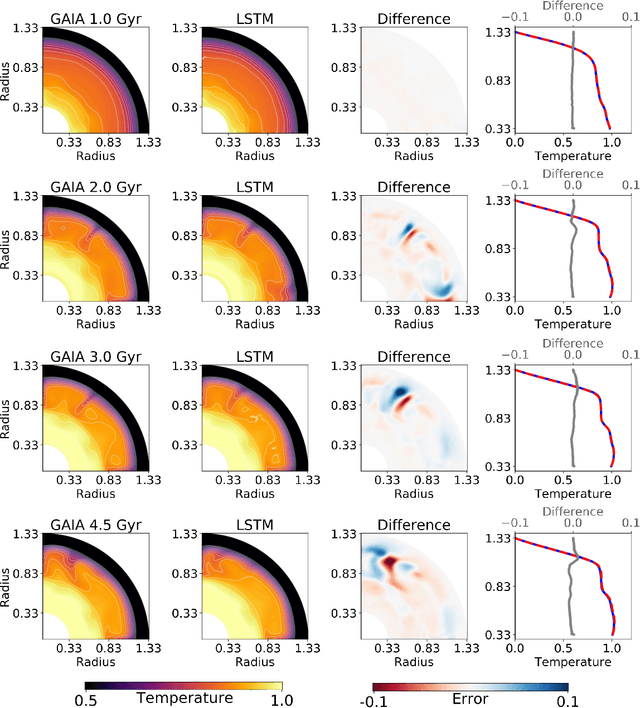
Traditionally, 1D models based on scaling laws have been used to parameterized convective heat transfer rocks in the interior of terrestrial planets like Earth, Mars, Mercury and Venus to tackle the computational bottleneck of high-fidelity forward runs in 2D or 3D. However, these are limited in the amount of physics they can model (e.g. depth dependent material properties) and predict only mean quantities such as the mean mantle temperature. We recently showed that feedforward neural networks (FNN) trained using a large number of 2D simulations can overcome this limitation and reliably predict the evolution of entire 1D laterally-averaged temperature profile in time for complex models [Agarwal et al. 2020]. We now extend that approach to predict the full 2D temperature field, which contains more information in the form of convection structures such as hot plumes and cold downwellings. Using a dataset of 10,525 two-dimensional simulations of the thermal evolution of the mantle of a Mars-like planet, we show that deep learning techniques can produce reliable parameterized surrogates (i.e. surrogates that predict state variables such as temperature based only on parameters) of the underlying partial differential equations. We first use convolutional autoencoders to compress the temperature fields by a factor of 142 and then use FNN and long-short term memory networks (LSTM) to predict the compressed fields. On average, the FNN predictions are 99.30% and the LSTM predictions are 99.22% accurate with respect to unseen simulations. Proper orthogonal decomposition (POD) of the LSTM and FNN predictions shows that despite a lower mean absolute relative accuracy, LSTMs capture the flow dynamics better than FNNs. When summed, the POD coefficients from FNN predictions and from LSTM predictions amount to 96.51% and 97.66% relative to the coefficients of the original simulations, respectively.
COHORTNEY: Deep Clustering for Heterogeneous Event Sequences
Apr 03, 2021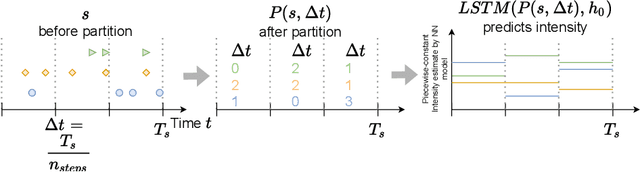
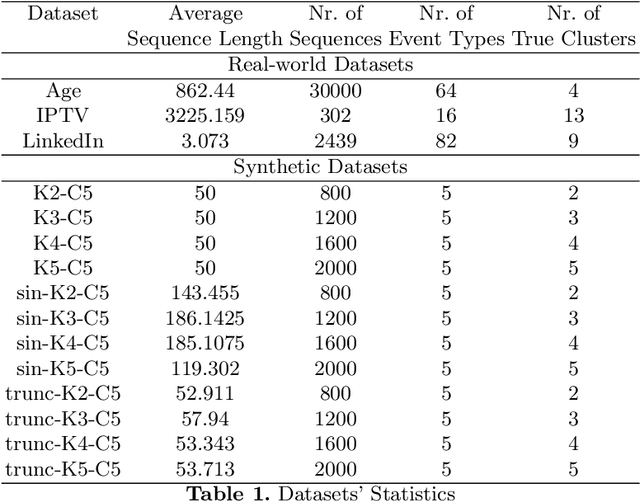
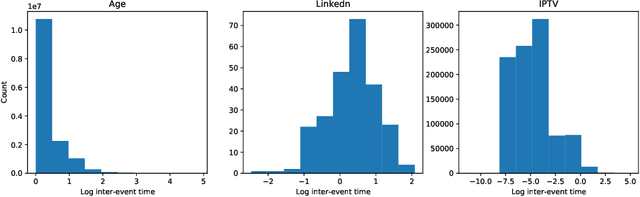
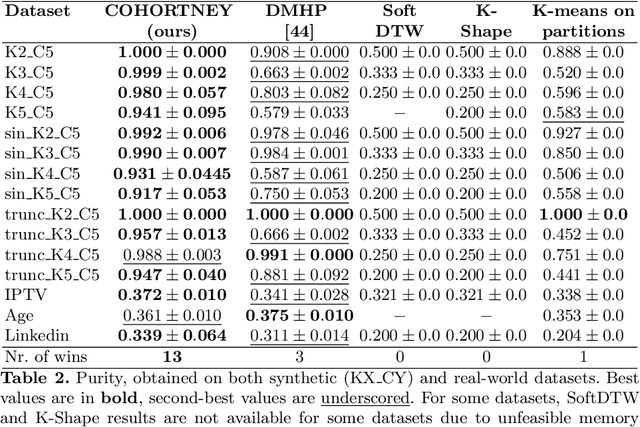
There is emerging attention towards working with event sequences. In particular, clustering of event sequences is widely applicable in domains such as healthcare, marketing, and finance. Use cases include analysis of visitors to websites, hospitals, or bank transactions. Unlike traditional time series, event sequences tend to be sparse and not equally spaced in time. As a result, they exhibit different properties, which are essential to account for when developing state-of-the-art methods. The community has paid little attention to the specifics of heterogeneous event sequences. Existing research in clustering primarily focuses on classic times series data. It is unclear if proposed methods in the literature generalize well to event sequences. Here we propose COHORTNEY as a novel deep learning method for clustering heterogeneous event sequences. Our contributions include (i) a novel method using a combination of LSTM and the EM algorithm and code implementation; (ii) a comparison of this method to previous research on time series and event sequence clustering; (iii) a performance benchmark of different approaches on a new dataset from the finance industry and fourteen additional datasets. Our results show that COHORTNEY vastly outperforms in speed and cluster quality the state-of-the-art algorithm for clustering event sequences.
A Numerical Study of the Time of Extinction in a Class of Systems of Spiking Neurons
Nov 06, 2019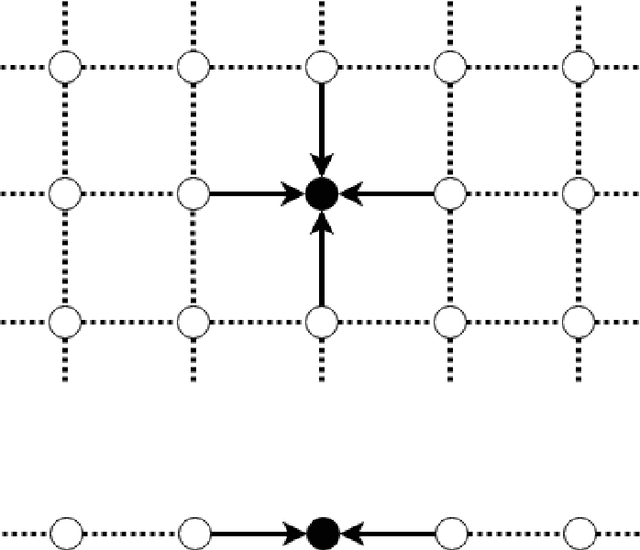
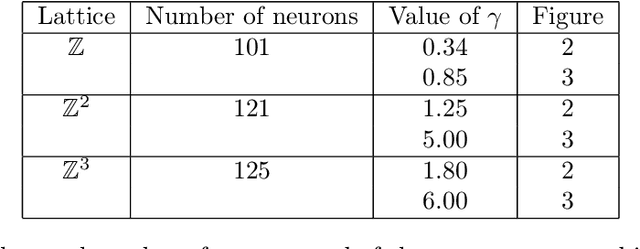
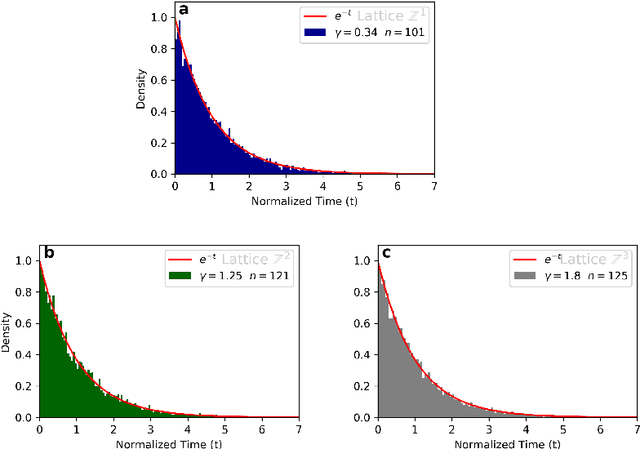
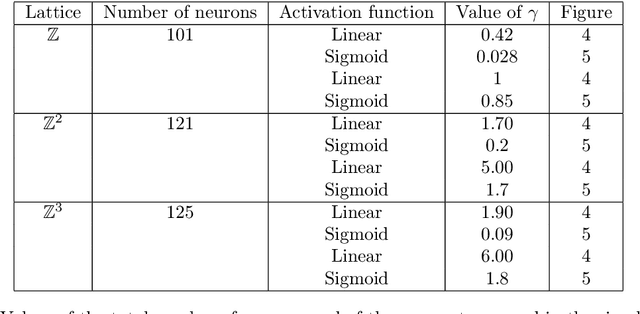
In this paper we present a numerical study of a mathematical model of spiking neurons introduced by Ferrari et al. in an article entitled Phase transition forinfinite systems of spiking neurons. In this model we have a countable number of neurons linked together in a network, each of them having a membrane potential taking value in the integers, and each of them spiking over time at a rate which depends on the membrane potential through some rate function $\phi$. Beside being affected by a spike each neuron can also be affected by leaking. At each of these leak times, which occurs for a given neuron at a fixed rate $\gamma$, the membrane potential of the neuron concerned is spontaneously reset to $0$. A wide variety of versions of this model can be considered by choosing different graph structures for the network and different activation functions. It was rigorously shown that when the graph structure of the network is the one-dimensional lattice with a hard threshold for the activation function, this model presents a phase transition with respect to $\gamma$, and that it also presents a metastable behavior. By the latter we mean that in the sub-critical regime the re-normalized time of extinction converges to an exponential random variable of mean 1. It has also been proven that in the super-critical regime the renormalized time of extinction converges in probability to 1. Here, we investigate numerically a richer class of graph structures and activation functions. Namely we investigate the case of the two dimensional and the three dimensional lattices, as well as the case of a linear function and a sigmoid function for the activation function. We present numerical evidence that the result of metastability in the sub-critical regime holds for these graphs and activation functions as well as the convergence in probability to $1$ in the super-critical regime.
Internet-Augmented Dialogue Generation
Jul 15, 2021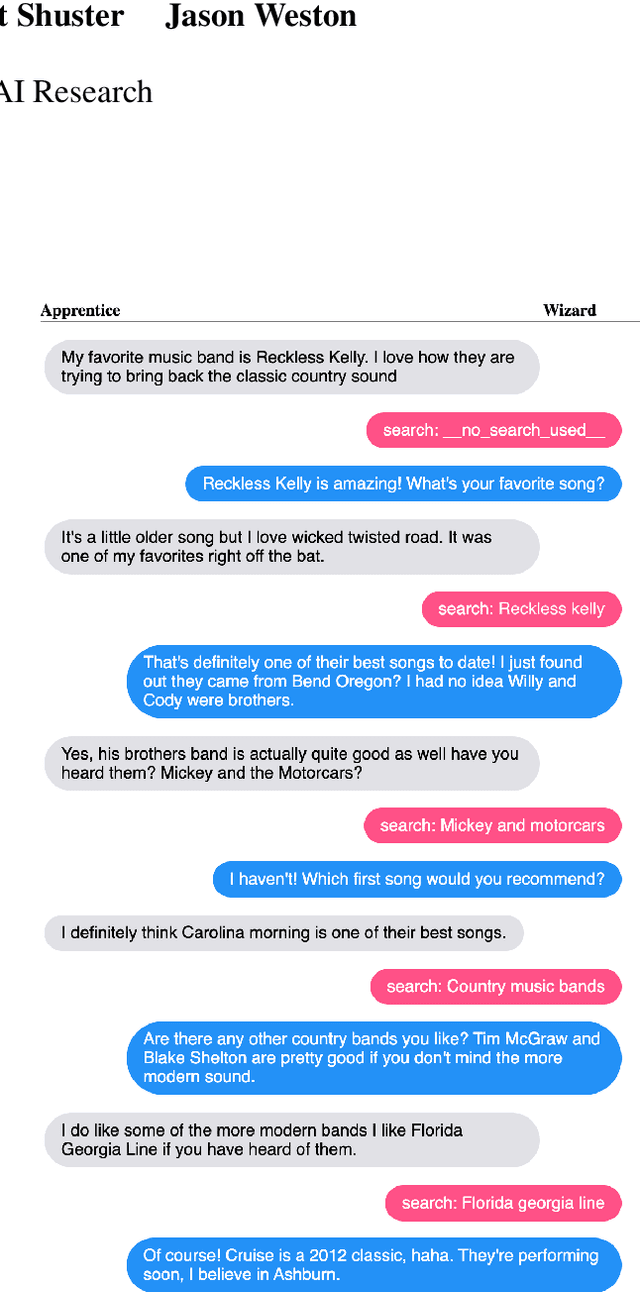
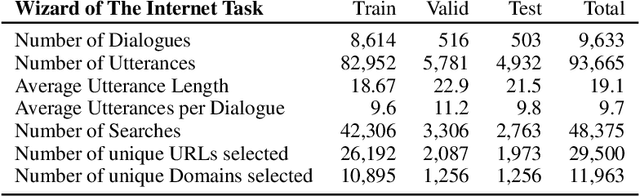
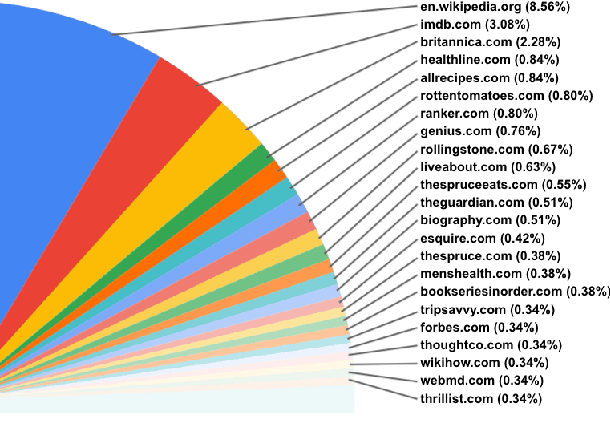
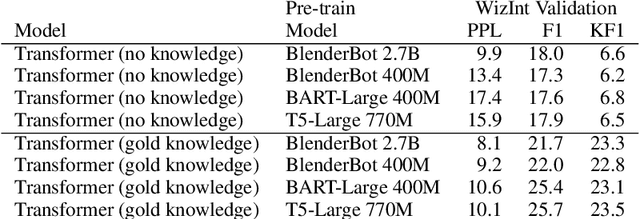
The largest store of continually updating knowledge on our planet can be accessed via internet search. In this work we study giving access to this information to conversational agents. Large language models, even though they store an impressive amount of knowledge within their weights, are known to hallucinate facts when generating dialogue (Shuster et al., 2021); moreover, those facts are frozen in time at the point of model training. In contrast, we propose an approach that learns to generate an internet search query based on the context, and then conditions on the search results to finally generate a response, a method that can employ up-to-the-minute relevant information. We train and evaluate such models on a newly collected dataset of human-human conversations whereby one of the speakers is given access to internet search during knowledgedriven discussions in order to ground their responses. We find that search-query based access of the internet in conversation provides superior performance compared to existing approaches that either use no augmentation or FAISS-based retrieval (Lewis et al., 2020).
Distilling the Knowledge from Normalizing Flows
Jun 25, 2021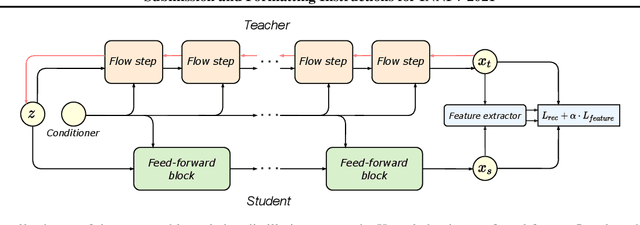
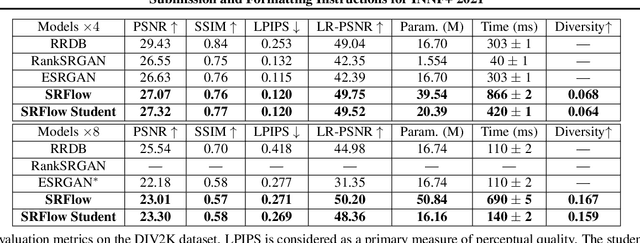
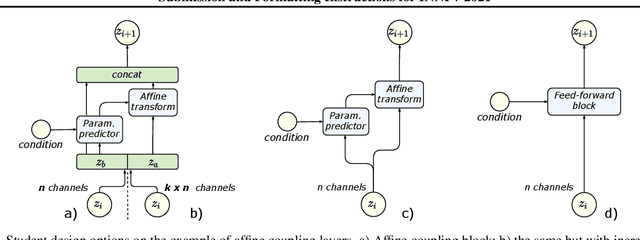
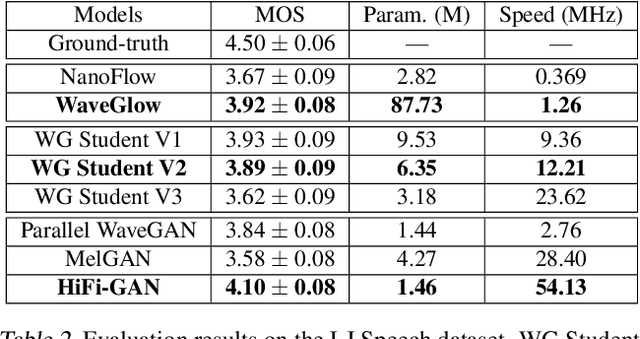
Normalizing flows are a powerful class of generative models demonstrating strong performance in several speech and vision problems. In contrast to other generative models, normalizing flows are latent variable models with tractable likelihoods and allow for stable training. However, they have to be carefully designed to represent invertible functions with efficient Jacobian determinant calculation. In practice, these requirements lead to overparameterized and sophisticated architectures that are inferior to alternative feed-forward models in terms of inference time and memory consumption. In this work, we investigate whether one can distill flow-based models into more efficient alternatives. We provide a positive answer to this question by proposing a simple distillation approach and demonstrating its effectiveness on state-of-the-art conditional flow-based models for image super-resolution and speech synthesis.
Improving Sound Event Classification by Increasing Shift Invariance in Convolutional Neural Networks
Jul 22, 2021
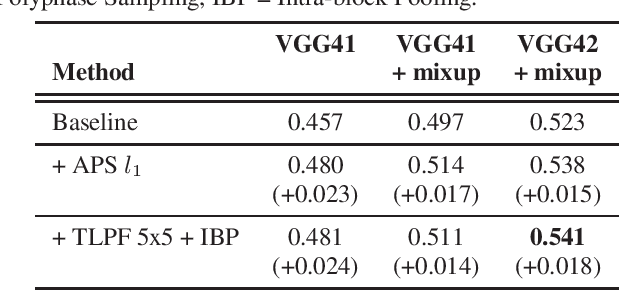

Recent studies have put into question the commonly assumed shift invariance property of convolutional networks, showing that small shifts in the input can affect the output predictions substantially. In this paper, we analyze the benefits of addressing lack of shift invariance in CNN-based sound event classification. Specifically, we evaluate two pooling methods to improve shift invariance in CNNs, based on low-pass filtering and adaptive sampling of incoming feature maps. These methods are implemented via small architectural modifications inserted into the pooling layers of CNNs. We evaluate the effect of these architectural changes on the FSD50K dataset using models of different capacity and in presence of strong regularization. We show that these modifications consistently improve sound event classification in all cases considered. We also demonstrate empirically that the proposed pooling methods increase shift invariance in the network, making it more robust against time/frequency shifts in input spectrograms. This is achieved by adding a negligible amount of trainable parameters, which makes these methods an appealing alternative to conventional pooling layers. The outcome is a new state-of-the-art mAP of 0.541 on the FSD50K classification benchmark.
Hybrid Memoised Wake-Sleep: Approximate Inference at the Discrete-Continuous Interface
Jul 04, 2021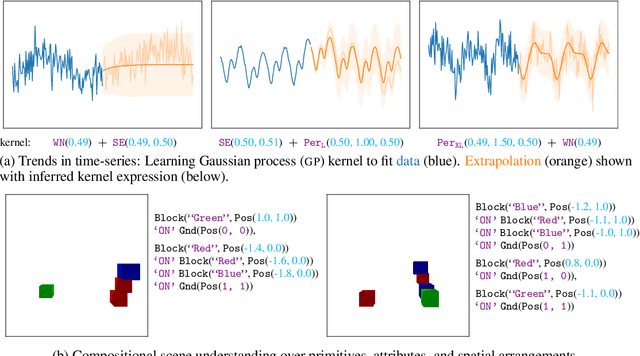
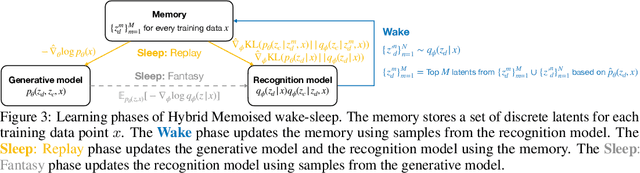
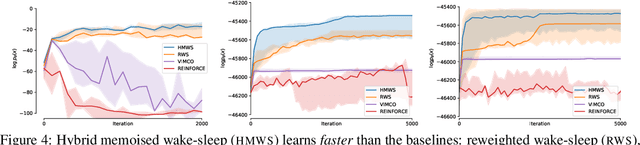
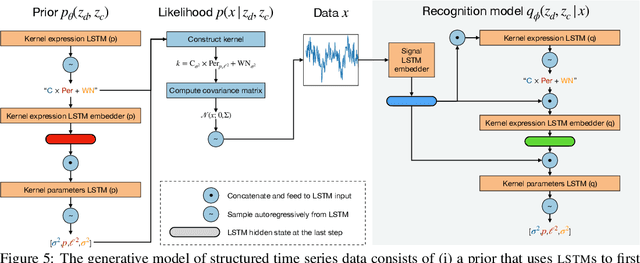
Modeling complex phenomena typically involves the use of both discrete and continuous variables. Such a setting applies across a wide range of problems, from identifying trends in time-series data to performing effective compositional scene understanding in images. Here, we propose Hybrid Memoised Wake-Sleep (HMWS), an algorithm for effective inference in such hybrid discrete-continuous models. Prior approaches to learning suffer as they need to perform repeated expensive inner-loop discrete inference. We build on a recent approach, Memoised Wake-Sleep (MWS), which alleviates part of the problem by memoising discrete variables, and extend it to allow for a principled and effective way to handle continuous variables by learning a separate recognition model used for importance-sampling based approximate inference and marginalization. We evaluate HMWS in the GP-kernel learning and 3D scene understanding domains, and show that it outperforms current state-of-the-art inference methods.
High-level Decisions from a Safe Maneuver Catalog with Reinforcement Learning for Safe and Cooperative Automated Merging
Jul 15, 2021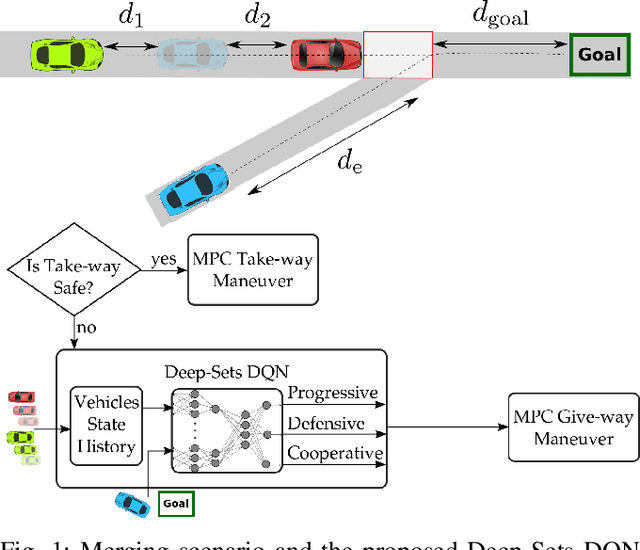
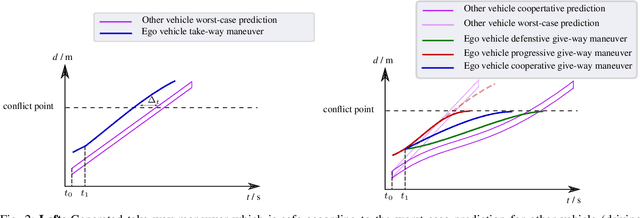
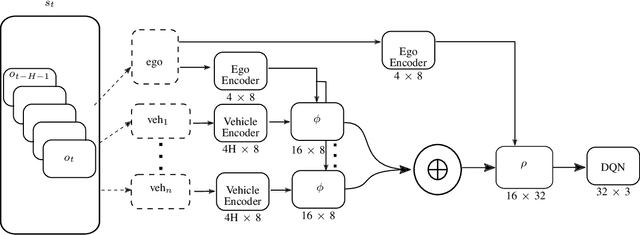
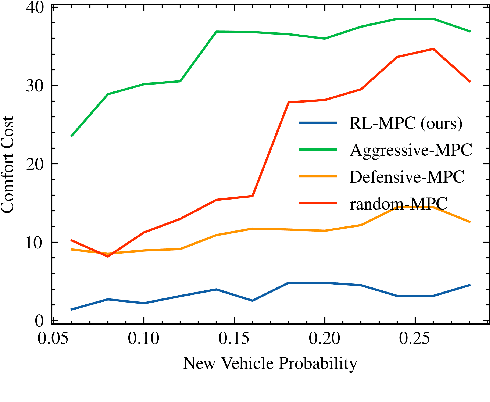
Reinforcement learning (RL) has recently been used for solving challenging decision-making problems in the context of automated driving. However, one of the main drawbacks of the presented RL-based policies is the lack of safety guarantees, since they strive to reduce the expected number of collisions but still tolerate them. In this paper, we propose an efficient RL-based decision-making pipeline for safe and cooperative automated driving in merging scenarios. The RL agent is able to predict the current situation and provide high-level decisions, specifying the operation mode of the low level planner which is responsible for safety. In order to learn a more generic policy, we propose a scalable RL architecture for the merging scenario that is not sensitive to changes in the environment configurations. According to our experiments, the proposed RL agent can efficiently identify cooperative drivers from their vehicle state history and generate interactive maneuvers, resulting in faster and more comfortable automated driving. At the same time, thanks to the safety constraints inside the planner, all of the maneuvers are collision free and safe.
Subgraph Federated Learning with Missing Neighbor Generation
Jul 22, 2021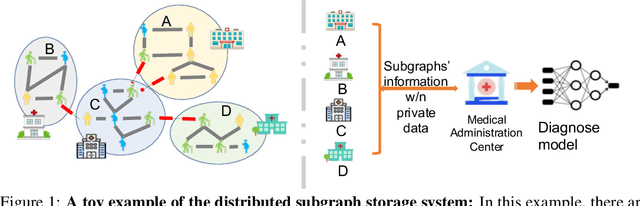
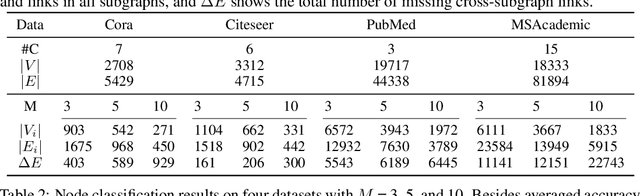
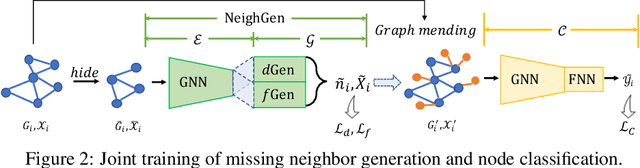
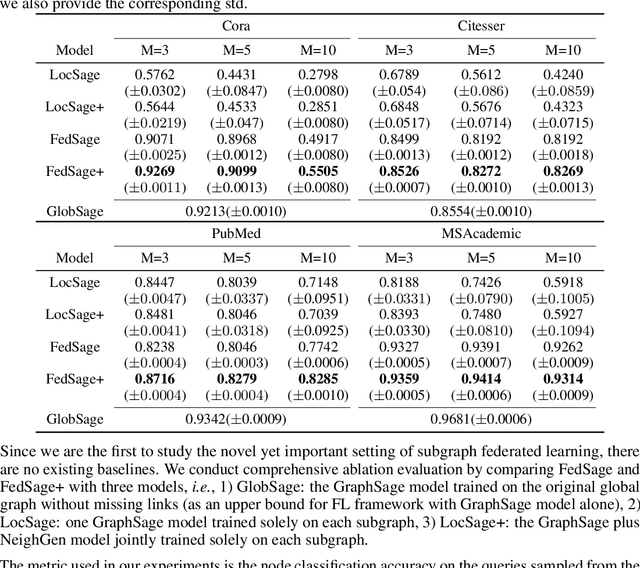
Graphs have been widely used in data mining and machine learning due to their unique representation of real-world objects and their interactions. As graphs are getting bigger and bigger nowadays, it is common to see their subgraphs separately collected and stored in multiple local systems. Therefore, it is natural to consider the subgraph federated learning setting, where each local system holding a small subgraph that may be biased from the distribution of the whole graph. Hence, the subgraph federated learning aims to collaboratively train a powerful and generalizable graph mining model without directly sharing their graph data. In this work, towards the novel yet realistic setting of subgraph federated learning, we propose two major techniques: (1) FedSage, which trains a GraphSage model based on FedAvg to integrate node features, link structures, and task labels on multiple local subgraphs; (2) FedSage+, which trains a missing neighbor generator along FedSage to deal with missing links across local subgraphs. Empirical results on four real-world graph datasets with synthesized subgraph federated learning settings demonstrate the effectiveness and efficiency of our proposed techniques. At the same time, consistent theoretical implications are made towards their generalization ability on the global graphs.